H100 GPU架构
使用TSMC 4nm工艺定制800亿个晶体管,814mm²芯片面积。
NVIDIA Grace Hopper Superchip CPU+GPU架构
-
NVIDIA Grace CPU:利用ARM架构的灵活性,创建了从底层设计的CPU和服务器架构,用于加速计算。
-
H100:通过NVIDIA的超高速片间互连与Grace配对,能提供900GB/s的带宽,比PCIe Gen5快了7倍
目录
H100 GPU主要特征
基于H100的系统和板卡
H100 SXM5 GPU
H100 PCIe Gen 5 GPU
DGX H100 and DGX SuperPOD
HGX H100
H100 CNX Converged Accelerator
H100 GPU架构细节
组成
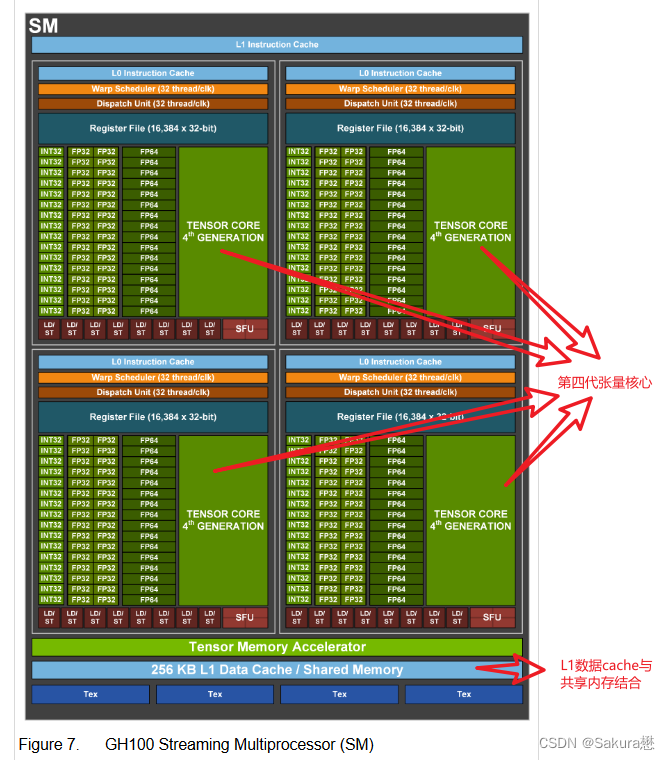
H100 SM架构
H100张量核心架构
FP8数据格式
用于加速动态规划(“Dynamic Programming”)的DPX指令
L1数据cache和共享内存结合
H100 GPU层次结构和异步性改进
线程块集群(Thread Block Clusters)
分布式共享内存(DSMEM)
异步执行
H100 HBM和L2 cache内存架构
H100 HBM3和HBM2e DRAM子系统
H100 L2 cache
内存子系统RAS特征
第二代安全MIG
Transformer引擎
第四代NVLink和NVLink网络
第三代NVSwitch
新的NVLink交换系统
PCIe Gen 5
安全性增强和保密计算
H100 video/IO特征
H100 GPU主要特征
-
新的流式多处理器(Streaming Multiprocessor, SM)
-
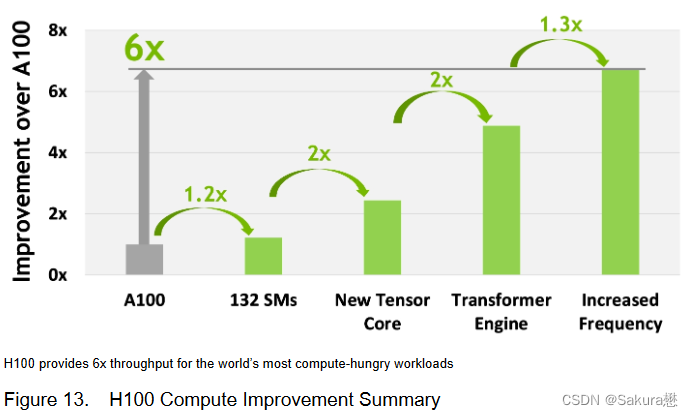
第四代张量核心:片间通信速率提高了6倍(包括单个SM加速、额外的SM数量、更高的时钟);在等效数据类型上提供了2倍的矩阵乘加(Matrix Multiply-Accumulate, MMA)计算速率,相比于之前的16位浮点运算,使用新的FP8数据类型使速率提高了4倍;稀疏性特征利用了深度学习网络中的细粒度结构化稀疏性,使标准张量核心性能翻倍。
-
新的DPX指令加速了动态规划算法达到7倍。
-
IEEE FP64和FP32的芯片到芯片处理速率提高了3倍(因为单个SM逐时钟(clock-for-clock)性能提高了2倍;额外的SM数量;更快的时钟)
-
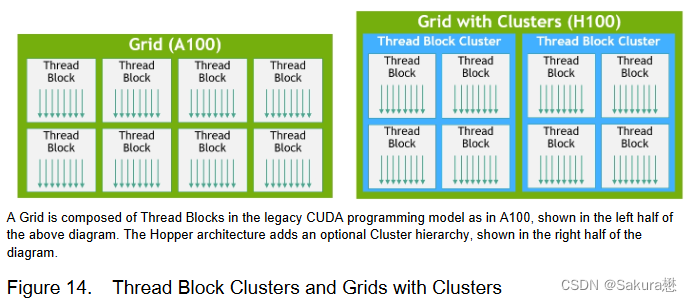
新的线程块集群特性(Thread Block Cluster feature)允许在更大的粒度上对局部性进行编程控制(相比于单个SM上的单线程块)。这扩展了CUDA编程模型,在编程层次结构中增加了另一个层次,包括线程(Thread)、线程块(Thread Blocks)、线程块集群(Thread Block Cluster)和网格(Grids)。集群允许多个线程块在多个SM上并发运行,以同步和协作的获取数据和交换数据。
-
新的异步执行特征包括一个新的张量存储加速(Tensor Memory Accelerator, TMA)单元,它可以在全局内存和共享内存之间非常有效的传输大块数据。TMA还支持集群中线程块之间的异步拷贝。还有一种新的异步事务屏障,用于进行原子数据的移动和同步。
-
-
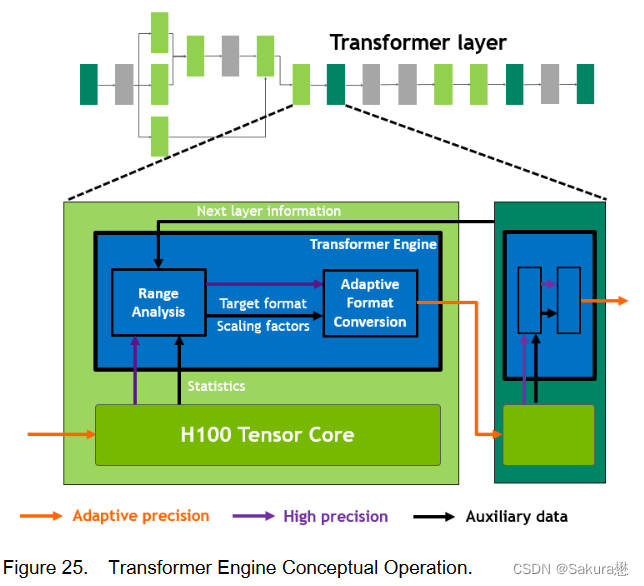
新的Transformer引擎采用专门设计的软件和自定义Hopper张量核心技术相结合的方式,加速了Transformer模型的训练和推理。Transformer引擎在FP8和16位计算之间进行智能管理和动态选择,在每一层中自动处理FP8和16位之间的重新选择和缩放,在大预言模型中达到9倍的AI训练速度和30倍的AI推理速度。
-
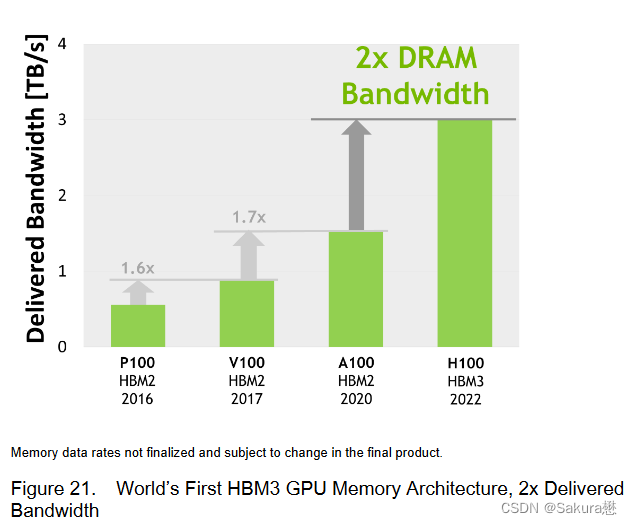
HBM3内存子系统提供近2倍的带宽提升。H100 SXM5 GPU是世界上第一款采用HBM3内存的GPU,其内存带宽达到3TB/sec。
-
50MB的L2 Cache架构缓存了大量的模型和数据以进行重复访问,减少了对HBM3的重复访问次数。
-
第二代多实例GPU(Multi-Instance GPU, MIG)技术为每个GPU实例提供约3倍的计算能量和近2倍的内存带宽。第一次支持机密计算,在7个GPU实例的虚拟化环境中支持多租户、多用户配置。(MIG的技术原理:作业可同时在不同的实例上运行,每个实例都有专用的计算、显存和显存带宽资源,从而实现可预测的性能,同时符合服务质量 (QoS) 并尽可能提升 GPU 利用率。)
-
新的机密计算支持保护用户数据,防御硬件和软件攻击,在虚拟化和MIG环境中更好的隔离和保护虚拟机。H100实现了世界上第一个国产的机密计算GPU,并以全PCIe线速扩展了CPU的可信执行环境。
-
第四代NVIDIA NVLink在全归约操作上提供了3倍的带宽提升,在7倍PCIe Gen 5带宽下,为多GPU IO提供了900GB/sec的总带宽,比上一代NVLink增加了50%的总带宽。
-
第三代NVSwitch技术包括驻留在节点内部和外部的交换机,用于连接服务器、集群和数据中心环境中的多个GPU。节点内部的每个NVSwitch提供64个第四代NVLink链路端口,以加速多GPU连接。交换机的总吞吐率从上一代的7.2Tbits/sec提高到13.6Tbits/sec。新的第三代NVSwitch技术也为多播和NVIDIA SHARP网络内精简的集群操作提供了硬件加速。
-
新的NVLink Switch系统互连技术和新的基于第三代NVSwitch技术的第二级NVLink交换机引入地址空间隔离和保护, 使得多达32个节点或256个GPU可以通过NVLink以2:1的锥形胖树拓扑连接。这些相连的节点能够提供57.6 TB / sec的全连接带宽,并且能够提供难以置信的一个exaFlop(百亿亿次浮点运算)的FP8稀疏AI计算。
-
PCIe Gen 5提供了128 GB / sec的总带宽( 各个方向上为64GB / s),而Gen 4 PCIe提供了64 GB / sec的总带宽( 各个方向上为32GB / sec)。PCIe Gen 5使H100可以与性能最高的x86 CPU和Smart NICs / DPU (数据处理单元)接口。
基于H100的系统和板卡
H100 SXM5 GPU
-
使用NVIDIA定制的SXM5板卡
-
内置H100 GPU和HMB3内存堆栈
-
提供第四代NVLink和PCIe Gen 5连接
-
提供最高的应用性能
-
-
这种配置非常适合在一个服务器和跨服务器的情况下将应用程序扩展到多个GPU上的客户,通过在HGX H100服务器板卡上配置4-GPU和8-GPU实现
-
4-GPU配置:包括GPU之间的点对点NVLink连接,并在服务器中提供更高的CPU - GPU比率;
-
8 - GPU配置:包括NVSwitch,以提供SHARP在网络中的缩减和任意对GPU之间900 GB / s的完整NVLink带宽。
-
-
H100 SXM5 GPU还被用于功能强大的新型DGX H100服务器和DGX SuperPOD系统中。
H100 PCIe Gen 5 GPU
-
以仅有350W的热设计功耗(Thermal Design Power, TDP),提供了H100 SXM5 GPU的全部能力
-
该配置可选择性地使用NVLink桥以600GB / s的带宽连接多达两个GPU,接近PCIe Gen5的5倍。
-
H100 PCIe非常适合主流加速服务器(使用标准的架构,提供更低服务器功耗),为同时扩展到1或2个GPU的应用提供了很好的性能,包括AI Inference和一些HPC应用。
-
在10个顶级数据分析、AI和HPC应用程序的数据集中,单个H100 PCIe GPU高效地提供了H100 SXM5 GPU的65 %的交付性能,同时仅消耗了50 %的功耗。
DGX H100 and DGX SuperPOD
-
NVIDIA DGX H100是一个通用的高性能人工智能系统,用于训练、推理和分析。
-
配置了Bluefield-3, NDR InfiniBand和第二代MIG技术
-
单个DGX H100系统提供了16 petaFLOPS(千万亿次浮点运算)(FP16稀疏AI计算性能)。通过将多个DGX H100系统连接组成集群(称为DGX PODs或DGX Super PODs),可以很容易地扩大这种性能。
-
DGX SuperPOD
-
从32个DGX H100系统开始,被称为"可扩展单元"
-
集成了256个H100 GPU,这些GPU通过基于第三代NVSwitch技术的新的二级NVLink交换机连接,提供了1 exaFLOP的FP8稀疏AI计算性能。
-
同时支持无线带宽(InifiniBand, IB)和NVLINK Switch网络选项。
HGX H100
-
通过NVLink和NVSwitch提供的高速互连,HGX H100将多个H100结合起来,使其能创建世界上最强大的可扩展服务器。
-
HGX H100可作为服务器构建模块,以集成底板的形式在4个或8个H100 GPU配置中使用。
H100 CNX Converged Accelerator
-
NVIDIA H100 CNX将NVIDIA H100 GPU的强大功能与NVIDIA ® ConnectX-7 SmartNIC的先进组网能力相结合,可提供高达400Gb / s的带宽
-
包括NVIDIA ASAP2 (加速交换和分组处理)等创新功能,以及用于TLS / IPsec / MACsec加密/解密的在线硬件加速。
-
这种独特的架构为GPU驱动的I / O密集型工作负载提供了前所未有的性能,如在企业数据中心进行分布式AI训练,或在边缘进行5G信号处理等。
H100 GPU架构细节
-
异步GPU
-
H100扩展了A100在所有地址空间的全局共享异步传输,并增加了对张量内存访问模式的支持。
-
它使应用程序能够构建端到端的异步管道,将数据移入和移出芯片,完全重叠和隐藏带有计算的数据移动。
-
-
CUDA线程
-
只需要少量的CUDA线程来管理H100的全部内存带宽
-
其他大多数CUDA线程可以专注于通用计算,例如新一代Tensor Cores的预处理和后处理数据。
-
扩展了层次结构,增加了一个称为线程块集群(Thread Block Cluster)的新模块,集群( Cluster )是一组线程块( Thread Block ),保证线程可以被并发调度,从而实现跨多个SM的线程之间的高效协作和数据共享。集群还能更有效地协同驱动异步单元,如张量内存加速器(Tensor Memory Accelerator)和张量核心
-
-
NVIDIA的异步事务屏障(“Asynchronous Transaction Barrier”)使集群中的通用CUDA线程和片上加速器能够有效地同步,即使它们驻留在单独的SM上。
-
所有这些新特性使得每个用户和应用程序都可以在任何时候充分利用它们的H100 GPU的所有单元,使得H100成为迄今为止功能最强大、可编程性最强、能效最高的GPU。
组成
-
多个GPU处理集群(GPU Processing Clusters, GPCs)
-
Texture Processing Clusters (TPCs)
-
流式多处理器(Streaming Multiprocessors, SM)
-
L2 Cache
-
HBM3内存控制器
-
GH100 GPU的完整实现
-
8 GPUs
-
9 TPCs/GPU(共72 TPCs)
-
2 SMs/TPC(共144 SMs)
-
128 FP32 CUDA核心/SM
-
4个第四代张量核心/SM
-
6 HBM3/HBM2e 堆栈,12个512位内存控制器
-
60MB L2 Cache
-
第四代NVLink和PCIe Gen 5
H100 SM架构
-
引入FP8
-
新的Transformer引擎
-
新的DPX指令
H100张量核心架构
-
专门用于矩阵乘和累加( MMA )数学运算的高性能计算核心,为AI和HPC应用提供了开创性的性能。
-
H100中新的第四代Tensor Core架构提供了每SM的原始稠密和稀疏矩阵数学吞吐量的两倍
-
支持FP8、FP16、BF16、TF32、FP64、INT8等MMA数据类型。
-
新的Tensor Cores还具有更高效的数据管理,节省了高达30 %的操作数交付能力。
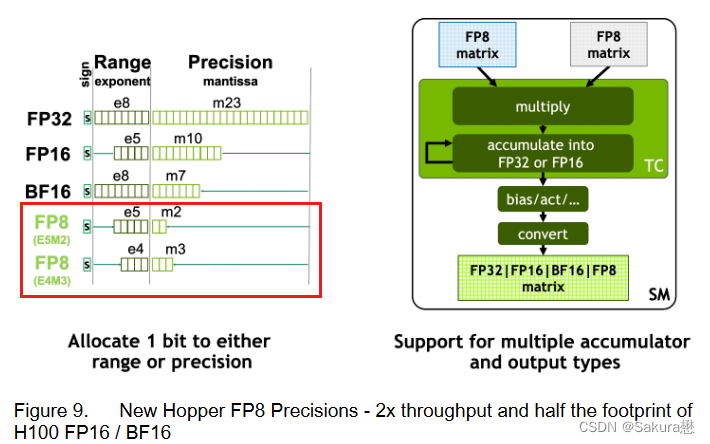
FP8数据格式
-
与FP16相比,FP8的数据存储需求减半,吞吐量提高一倍。
-
新的Transformer Engine (在下面的章节中进行阐述)同时使用FP8和FP16两种精度,以减少内存占用和提高性能,同时对大型语言和其他模型仍然保持精度。
用于加速动态规划(“Dynamic Programming”)的DPX指令
-
新引入的DPX指令为许多DP算法的内循环提供了高级融合操作数的支持,使得动态规划算法的性能相比于Ampere GPU最高提升了7倍。
L1数据cache和共享内存结合
-
将L1数据cache和共享内存功能合并到单个内存块中
-
简化了编程,减少了达到峰值或接近峰值应用性能所需的调优;为这两种类型的内存访问提供了最佳的综合性能。
H100 GPU层次结构和异步性改进
关键
-
数据局部性:将程序数据尽可能的靠近执行单元
-
异步执行:寻找独立的任务与内存传输和其他事物重叠。目标是使GPU中的所有单元都能得到充分利用。
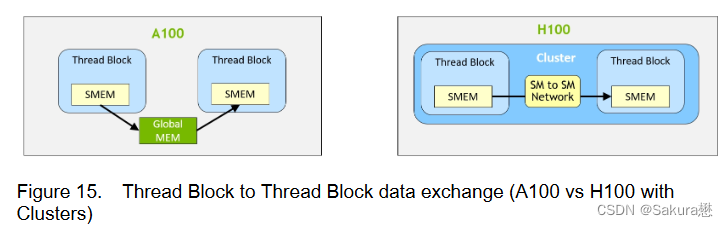
线程块集群(Thread Block Clusters)
提出背景:线程块包含多个线程并发运行在单个SM上,这些线程可以使用SM的共享内存与快速屏障同步并交换数据。然而,随着GPU规模超过100个SM,计算程序变得更加复杂,线程块作为编程模型中唯一表示的局部性单元不足以最大化执行效率。
Cluster是一组线程块,它们被保证并发调度到一组SM上,其目标是使跨多个SM的线程能够有效地协作。
GPC:GPU处理集群,是硬件层次结构中一组物理上总是紧密相连的子模块。
H100中的集群中的线程在一个GPC内跨SM同时运行。集群有硬件加速障碍和新的访存协作能力,在一个GPC中SM的一个专用SM-to-SM网络提供集群中线程之间快速的数据共享。
分布式共享内存(DSMEM)
通过集群,所有线程都可以直接访问其他SM的共享内存,并进行加载(load)、存储(store)和原子(atomic)操作。
-
专用SM-to-SM网络保证了对远程DSMEM的快速、低延迟访问。
-
在CUDA层面,集群中所有线程块的所有DSMEM段被映射到每个线程的通用地址空间中,使得所有DSMEM都可以通过简单的指针直接引用。
-
DSMEM传输也可以表示为与基于共享内存的障碍同步的异步复制操作,用于跟踪完成。
异步执行
-
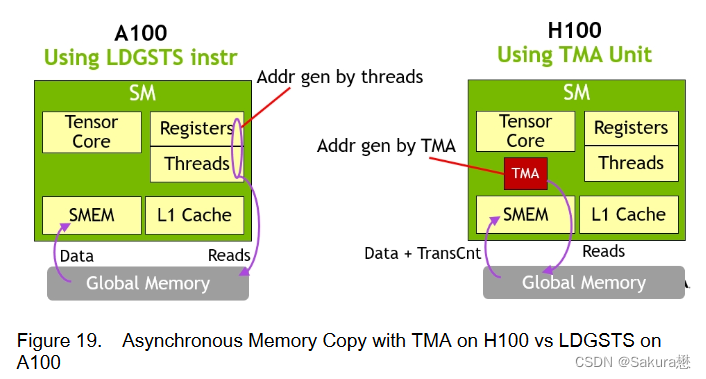
异步内存拷贝单元TMA(Tensor Memory Accelerator)
-
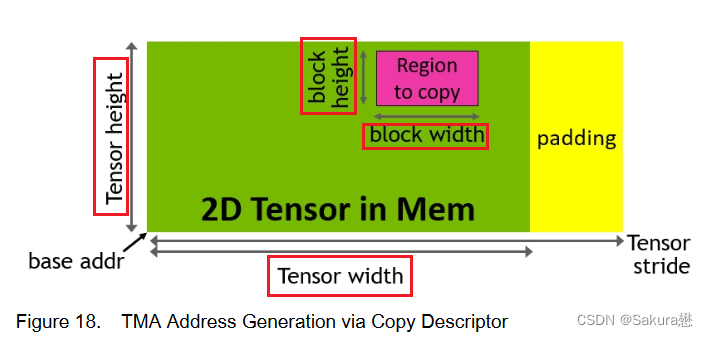
TMA可以将大块数据和多维张量从全局内存传输到共享内存,反义亦然。
-
使用一个copy descriptor,使用张量维度和块坐标来定义数据传输,而不是每个元素寻址。
-
TMA操作是异步的,利用了基于共享内存的异步屏障。
-
TMA编程模型是单线程的,选择一个经线程中的单个线程发出一个异步TMA操作( cuda::memcpy _ async )来复制一个张量,随后多个线程可以在一个cuda::barrier上等待完成数据传输。
-
H100 SM增加了硬件来加速这些异步屏障等待操作。
-
TMA的一个主要优点是它可以使线程自由地执行其他独立的工作。
-
在Hopper上,TMA包揽一切。单个线程在启动TMA之前创建一个副本描述符,从那时起地址生成和数据移动在硬件中处理。TMA提供了一个简单得多的编程模型,因为它在复制张量的片段时承担了计算步幅、偏移量和边界计算的任务。
-
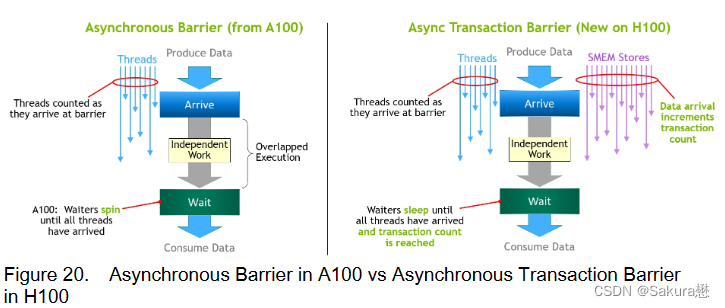
异步事务屏障(“Asynchronous Transaction Barrier”)
异步屏障: - 将同步过程分为两步。①线程在生成其共享数据的一部分时发出"到达"的信号。这个"到达"是非阻塞的,因此线程可以自由地执行其他独立的工作。②最终线程需要其他所有线程产生的数据。在这一点上,他们做一个"等待",直到每个线程都有"抵达"的信号。 - 优点是允许提前到达的线程在等待时执行独立的工作。 - 等待的线程会在共享内存中的屏障对象上自转(spin)(我理解的就是这些等待的线程在等待的时候无法执行其他工作)
-
也是一个分裂的屏障,但不仅对到达的线程计数,同时也对事务进行计数。
-
为写入共享内存引入一个新的命令,同时传递要写入的数据和事务计数。
-
事务计数本质上是对字节计数
-
异步事务屏障会在Wait命令处阻塞线程,直到所有生产者线程都执行了一个Arrive,所有事务计数之和达到期望值。
-
异步事务屏障是异步内存拷贝或数据交换的一种强有力的新原语。
-
集群可以进行线程块到线程块通信,进行隐含同步的数据交换,集群能力建立在异步事务屏障之上。
H100 HBM和L2 cache内存架构
HBM存储器由内存堆栈组成,位于与GPU相同的物理封装上,与传统的GDDR5/6内存相比,提供了可观的功耗和面积节省,允许更多的GPU被安装在系统中。
-
device memory:驻留在HBM内存空间的CUDA程序访问的全局和局部内存区域
-
constant cache:驻留在device memory内的不变内存空间
-
texture cache:驻留在device memory内的纹理和表面内存空间
-
L2 cache:对HBM内存进行读和写
-
services memory请求来源于GPU内的各种子系统
-
HBM和L2内存空间对所有SM和所有运行在GPU上的应用程序都是可访问的。
-
HBM3或HBM2e DRAM和L2缓存子系统都支持数据压缩和解压缩技术,以优化内存和缓存的使用和性能。
H100 HBM3和HBM2e DRAM子系统
带宽性能
H100 L2 cache
-
采用分区耦合结构(partitioned crossbar structure)
-
对与分区直接相连的GPC中的子模块的访存数据进行定位和高速缓存。
-
L2 cache驻留控制优化了容量利用率,允许程序员有选择地管理应该保留在缓存中或被驱逐的数据。
内存子系统RAS特征
RAS:Reliability, Available, Serviceability(可靠性,可获得性,服务性)
-
ECC存储弹性(Memory Resiliency)
-
H100 HBM3 / 2e存储子系统支持单纠错双检错( SECDED )纠错码( ECC )来保护数据。
-
H100的HBM3 / 2e存储器支持"边带ECC ",其中一个与主HBM存储器分开的小的存储区域用于ECC位
-
-
内存行重映射
-
H100 HBM3 / HBM2e子系统可以将产生错误ECC码的内存单元置为失效,并使用行重映射逻辑将其在启动时替换为保留的已知正确的行
-
每个HBM3 / HBM2e内存块中的若干内存行被预留为备用行,当需要替换被判定为坏的行时可以被激活。
第二代安全MIG
MIG技术允许将GPU划分为多达7个GPU事件(instance),以优化GPU利用率,并在不同客户端(例如VM、容器和进程等)之间提供一个被定义的QoS和隔离,在为客户端提供增强的安全性和保证GPU利用率之外,还确保一个客户端不受其他客户端的工作和调度的影响。
每个GPU实例在整个内存系统中都有单独的和孤立的路径- -片上的交叉开关端口、L2缓存库、内存控制器和DRAM地址总线都是唯一分配给单个实例的。这保证了单个用户的工作负载可以以可预测的吞吐量和延迟运行,具有相同的L2缓存分配和DRAM带宽,即使其他任务正在冲击自己的缓存或使其DRAM接口饱和。
H100 MIG改进:提供完全安全的、云原生的多租户、多用户的配置。
Transformer引擎
Transformer模型是当今从BERT到GPT - 3广泛使用的语言模型的支柱,需要巨大的计算资源。
第四代NVLink和NVLink网络
PCIe以其有限的带宽形成了一个瓶颈。为了构建最强大的端到端计算平台,需要更快速、更可扩展的NVLink互连。 NVLink是NVIDIA公司推出的高带宽、高能效、低延迟、无损的GPU - to - GPU互连,其中包括弹性特性,如链路级错误检测和数据包重放机制,以保证数据的成功传输。
-
新的NVLink为多GPU IO和共享内存访问提供了900 GB / s的总带宽,为PCIe Gen 5提供了7倍的带宽。
-
A100 GPU中的第三代NVLink在每个方向上使用4个差分对( 4个通道)来创建单条链路,在每个方向上提供25 GB / s的有效带宽,而第四代NVLink在每个方向上仅使用2个高速差分对来形成单条链路,在每个方向上也提供25 GB / s的有效带宽。
-
引入了新的NVLink网络互连,可以在多个计算节点上实现多达256个GPU之间的GPU - to - GPU通信。
-
与常规的NVLink(所有GPU共享一个共同的地址空间,请求直接使用GPU的物理地址进行路由)不同,NVLink网络引入了一个新的网络地址空间,由H100中新的地址转换硬件支持,以隔离所有GPU的地址空间和网络地址空间。这使得NVLink网络可以安全地扩展到更多的GPU上。
-
由于NVLink网络端点不共享一个公共的内存地址空间,NVLink网络连接在整个系统中并不是自动建立的。相反,与其他网络接口(如IB交换机)类似,用户软件应根据需要显式地建立端点之间的连接。
第三代NVSwitch
-
包括驻留在节点内部和外部的交换机,用于连接服务器、集群和数据中心环境中的多个GPU。
-
节点内部每一个新的第三代NVSwitch提供64个端口(of fourth-generation NVLink links)
-
交换机的总吞吐率从上一代的7.2 Tbits / sec提高到13.6 Tbits / sec。
-
还通过多播和NVIDIA SHARP网内精简提供了集群操作的硬件加速。加速集群操作包括写广播(all_gather)、reduce_scatter、广播原子。
-
组内多播和缩减能提供2倍的吞吐量增益,同时显著降低了小块大小集合的延迟。
-
集群的NVSwitch加速显著降低了用于集群通信的SM的负载。
新的NVLink交换系统
-
新的NVLINK网络技术和新的第三代NVSwitch相结合,使NVIDIA能够以前所未有的通信带宽构建大规模的NVLink交换系统网络。
-
NVLink交换系统支持多达256个GPU。连接的节点能够提供57.6 TB的全向带宽,并且能够提供1 exaFLOP 的FP8稀疏AI计算能力。
PCIe Gen 5
-
H100集成了PCI Express Gen 5 × 16通道接口,提供128 GB / sec的总带宽( 单方向上64GB / s),而A100包含的Gen 4 PCIe的总带宽为64 GB / sec( 单方向上为32GB / s)。
-
利用其PCIe Gen 5接口,H100可以与性能最高的x86 CPU和Smart NICs / DPUs (数据处理单元)接口。
-
H100增加了对本地PCIe原子操作的支持,如对32位和64位数据类型的原子CAS、原子交换和原子取指添加,加速了CPU和GPU之间的同步和原子操作
-
H100还支持Single Root Input/Output Virtualization (SR-IOV)(允许为多个进程或虚拟机共享和虚拟化单个PCIe连接的GPU)
-
H100还允许来自单个SR-IOV PCIe连接的GPU的虚拟函数或物理函数通过NVLink访问对等GPU
安全性增强和保密计算
-
数据保护和隔离
-
内容保护
-
物理损伤保护
H100 video/IO特征
参考
NVIDIA H100 Tensor Core GPU Architecture Overview
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-