
AI算力集群网络规模与集群算力发展分析




GPU集群网络、集群规模、集群算力
在过去十年中,60% 的创业公司在五年内失败。现在,成功的几率提高了 30%,达到 90%!加入我们的创业加速器,提升您成功的可能性。
一、引言
在生成式 AI 和大模型的时代,我们专注于 GPU 集群的总有效算力。单个 GPU 的有效算力约为峰值算力的 95%。例如,Nvidia A100 的峰值算力为 312 TFLOPS,有效算力约为 298 TFLOPS。
探索GPU集群的规划与网络配置,重点关注算力网络平面。
尽管熟悉单GPU卡和服务器,但GPU集群的规模和算力规划仍然处于探索阶段。本文探讨算力网络平面,这是集群中最重要的元素之一。存储和管理网络平面相对简单,因此本文不予讨论。
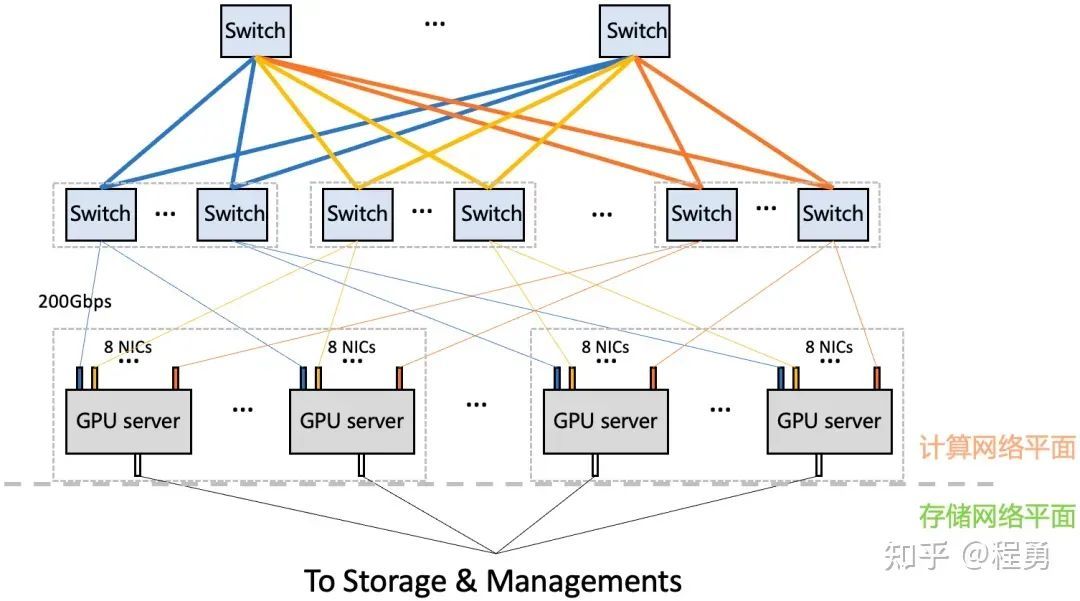
GPU集群网络架构示例(两层计算网络)[3]
二、GPU服务器网卡配置
GPU集群的性能很大程度上取决于网络配置。Nvidia推荐每块DGX A100 GPU配备200 Gbps网络连接,以实现最佳算力利用率。单台DGX A100服务器配备8块计算网络卡(如InfiniBand 200 Gbps),总有效算力高达1.6 Tbps。
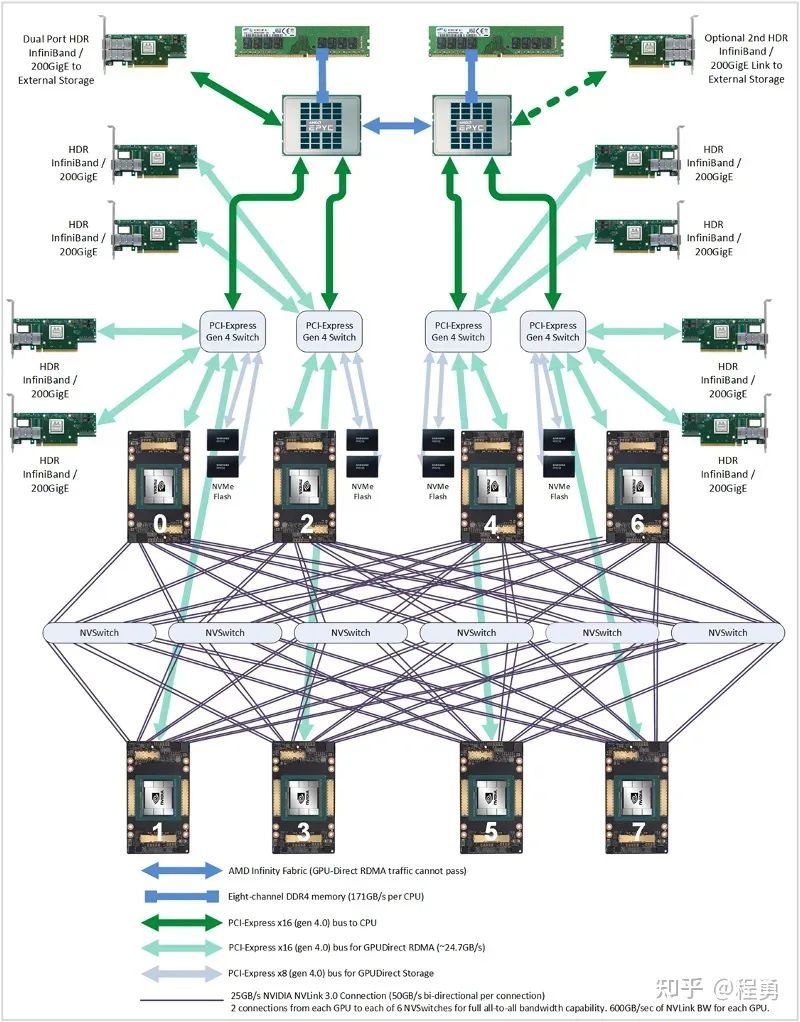
NVIDIA DGX A100系统,以其强大的DGX超级模块闻名,提供卓越的AI性能。其服务器块包含8个经过优化的高性能V100 Tensor Core GPU,总内存高达1TB,为AI工作负载提供无与伦比的计算能力。
那么GPU服务器之间的计算网络带宽是依据什么来确定的呢?
计算网络带宽由 GPU 卡支持的 PCIe 带宽决定。GPU 卡通过 PCIe 交换机连接至计算网络网卡,因此 PCIe 带宽会限制计算网络带宽。
举例而言,对于Nvidia DGX A100服务器,因为单张A100卡支持的是PCIe Gen4,双向带宽是64 GB/s,单向带宽是 32 GB/s,即 256 Gbps。所以,为单张A100卡配置 200 Gbps 的网卡就足够了。
所以,单看计算网络,Nvidia DGX A100服务器配置的是8张 Mellanox ConnectX-6 InfiniBand 网卡(注:也可以配置 Mellanox ConnectX-7,因为ConnectX-7也支持 200 Gbps)。如果是给A100卡配置 400 Gbps 的网卡,因为受到PCIe Gen4带宽限制,400 Gbps 的网卡作用是发挥不出来的(那么就浪费了很多网卡带宽)。
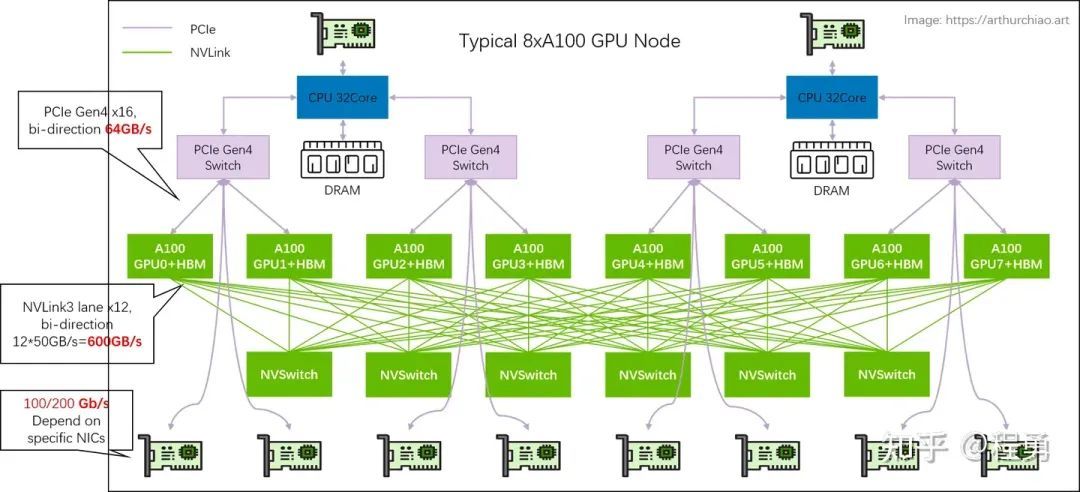
Nvidia DGX A100 system topology [4]
对于Nvidia DGX H100服务器,因为单张H100卡支持的是PCIe Gen5,双向带宽是128 GB/s,单向带宽是 64 GB/s,即 512 Gbps。
所以,为单张H100卡配置 400 Gbps 的计算网卡是Nvidia推荐的标准配置 [5]。单看计算网络,Nvidia DGX H100服务器配置的是8张 Mellanox ConnectX-7 InfiniBand 网卡,单个H100卡拥有 400 Gbps 对外网络连接 [5]。
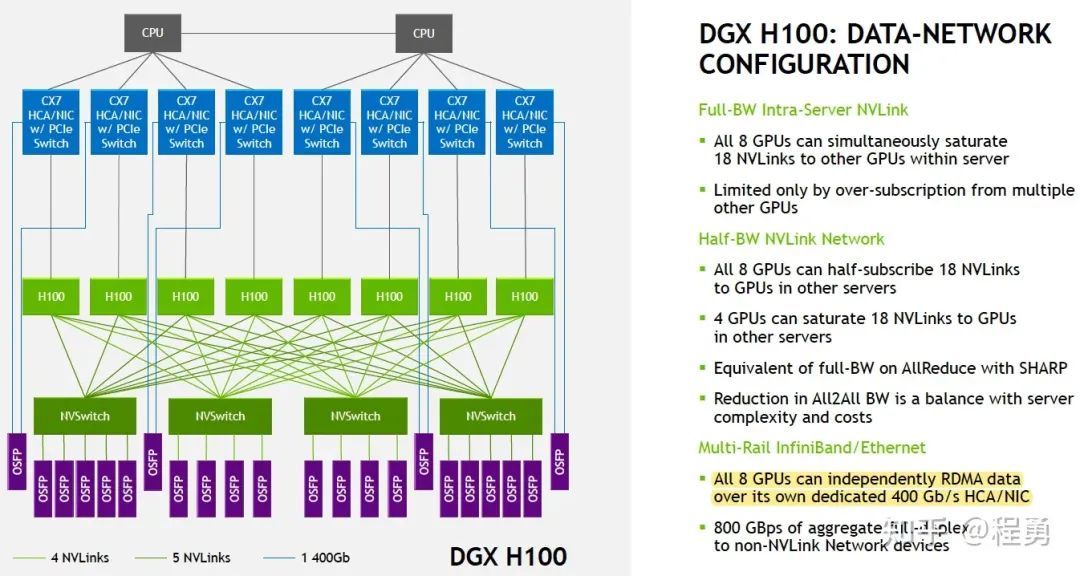
DGX H100 Configuration [5, 6]
需要说明的是,对于A800和H800服务器的计算网络配置,国内使用A800和H800服务器一般不是采用Nvidia DGX推荐的标准配置。例如,对于A800服务器,计算网卡配置常见的有两种方式:第一种是 8 x 200 GbE,即每张A800卡有单独的200 GbE网卡配置(8张A800卡一共有 ~1.6 Tbps RoCEv2计算网络连接[7]);
第二种是 4 x 200 GbE,即每两张A800卡共享一个200 GbE网卡,单卡最高是200 GbE网络,平均每张A800卡有对外100GbE的连接[7]。第二种方式类似Nvidia DGX V100的设计 [8]。考虑到可以先在A800服务器内进行通信聚合,然后再与其他服务器通信,所以这两种计算网卡配置方式对于整个集群效率的影响基本一致。
H800服务器支持PCIe Gen5,为8 x 400GbE计算网卡配置提供了强大的网络连接。每张H800卡可配置单独的400 GbE网卡,实现外部400 GbE计算网络连接。8张H800卡协同工作,可提供高达3.2 Tbps的极速RoCEv2计算网络连接。
华为昇腾910B NPU卡支持PCIe Gen5,提供400 GbE网络连接能力。16卡昇腾910B服务器可配置8块400 GbE网卡,平均每卡200 GbE网络带宽,显著提升数据传输效率和并行处理能力。
Nvidia使用NVLink和NVSwitch实现了单个服务器内多个GPU之间的高速互联,而使用多个服务器组建集群时,PCIe带宽仍然是主要性能瓶颈(集群网络瓶颈),这是因为当前网卡和GPU卡之间的连接主要还是通过PCIe Switch来连接。随着未来PCIe Gen6(2022年标准发布)普及应用,甚至PCIe Gen7(预计2025年标准发布)普及应用,GPU集群的整体性能又会上一个新台阶。还有2024年将要发布的Nvidia H20也是支持PCIe Gen5。
三、GPU集群网络和集群规模
上面讨论了单个GPU服务器的网卡配置,接下来讨论GPU集群网络架构(GPU cluster fabrics)和集群规模。实践中最常用的GPU集群网络拓扑是胖树(Fat-Tree)无阻塞网络架构(无收敛设计),这是因为Fat-Tree架构易于拓展、路由简单、方便管理和运维、鲁棒性好,且成本相对较低。实践中,一般规模较小的GPU集群计算网络采用两层架构(Leaf-Spine),而规模较大的GPU集群计算网络采用三层架构(Leaf-Spine-Core)。
这里 Leaf对应接入层(Access),Spine对应汇聚层(Aggregation),Core对应核心层。
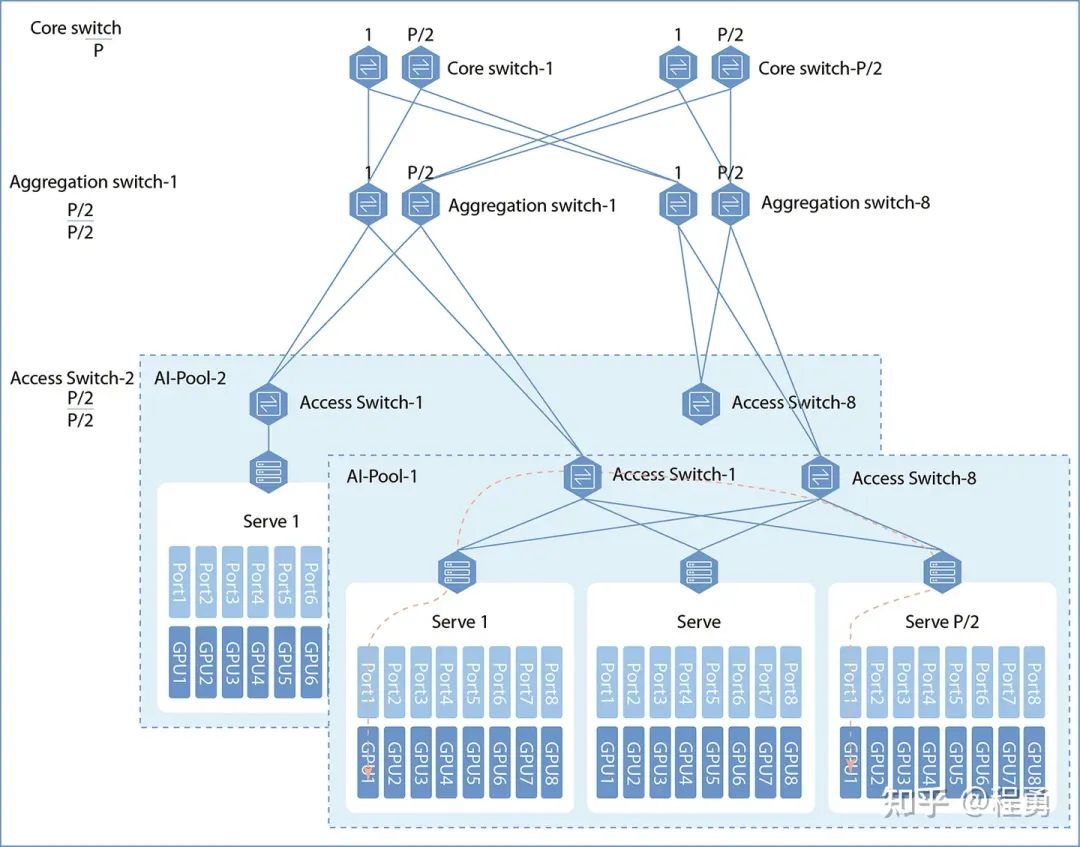
三层Fat-Tree计算网络示例 [9]
利用两层Fat-Tree无阻塞网络结构优化GPU集群计算网络,每个交换机端口数量为P。该网络支持最多P*P/2块GPU卡,实现高达50%的GPU连接密度。
在两层Fat-Tree无阻塞计算网络里(Leaf-Spine),第一层中每一台Leaf交换机用P/2个端口来连接GPU卡,另外P/2个端口向上连接Spine交换机(无阻塞网络要求向下和向上连接数量相同)。
第二层中每台Spine交换机也有P个端口,可以向下最多连接P台Leaf交换机,所以在两层Fat-Tree无阻塞计算网络里最多有P台Leaf交换机,所以总的GPU卡的数量最多为P*P/2。因为有P个Leaf交换机,每台Leaf交换机有P/2个端口向上连接Spine交换机,所以有P/2个Spine交换机。
部署 Nvidia A100 集群时,采用 Mellanox QM8700 等 40 端口交换机,并在两层 Fat-Tree 架构下,集群可容纳高达 800 个 A100 卡。专为高性能计算量身定制的此网络配置优化了连接和可扩展性,为数据密集型工作负载提供了无与伦比的性能。
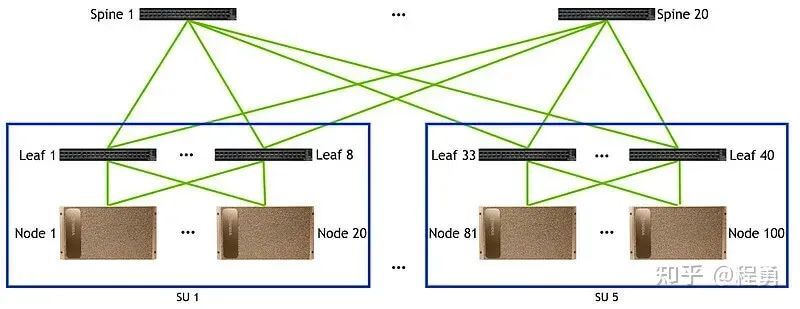
两层Fat-Tree计算网络示例 [10]
优化 GPU 服务器互联设置以提升分布式计算效率:
- 避免在同一服务器中将 GPU 卡连接到同一交换机叶节点,如果服务器内存在高速卡间互联(如 NVLink/NVSwitch)。
- 不同服务器中编号相同的 GPU 卡应连接到同一个交换机叶节点,以增强跨服务器 AllReduce 操作等分布式计算的效率。
避免跨NUMA通信,优化GPU服务器性能。
对于无卡间高速互联解决方案的GPU服务器,建议将同一服务器内的GPU卡连接到同一Leaf交换机。此举可有效避免跨NUMA通信,提升服务器性能。
三层计算网络优化:
采用三层计算网络,将接入的GPU数量提升至 32768,比两层网络提升四倍。该网络结构大幅扩展了 GPU 集群的规模,满足大型计算任务的需求。
对于大规模 GPU 集群,三层 Fat-Tree 计算网络架构可提供无阻塞互连。假设交换机端口数均为 P,则集群中 GPU 卡数量最大上限为 P^3/4。这种架构最大限度地利用了交换机容量,确保了高性能计算和通信。
从两层Fat-Tree网络向三层Fat-Tree网络扩展,我们可以把两层Fat-Tree网络看成一个单元(即一个两层Fat-Tree子网络)。因为每台Spine交换机有一半端口向下连接Leaf交换机(每台Spine交换机最多只能连接P/2个Leaf交换机),另一半端口向上连接Core交换机,所以每个两层Fat-Tree子网络里只能有P/2个Leaf交换机。
在无阻塞网络里,各层的连接数量都要保持相同,所以Spine交换机和Leaf交换机的数量相同。
在三层 Fat-Tree 无阻塞计算网络中,Leaf 交换机数量为 P*P/2,Spine 交换机数量也为 P*P/2,GPU 卡最大数量为 P*P*P/4。Spine 交换机连接 Core 交换机的数量为 P*P*P/4,因此 Core 交换机数量为 P*P/4。
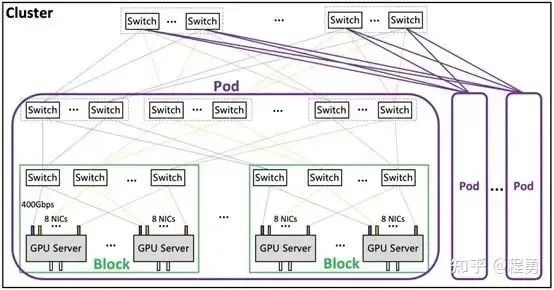
H800 GPU集群网络拓扑举例 [11]
GPU集群规模受计算网络架构和交换机端口数限制。
服务器中 GPU 数量的计算公式:
GPU 总数 = 单个网卡连接的 GPU 数 × 网卡数量
例如:
* 拥有 8 个 A800 GPU 的服务器配有 4 个 200 GbE 网卡:
> GPU 总数 = 2 x 4 = 8
交换机端口数(Leaf、Spine、Core交换机相同)
三层Fat-Tree无阻塞网络,GPU卡数量理论上限(GPU集群规模)
基于三层 Fat-Tree 无阻塞网络设计的 GPU 集群可充分满足大多数大模型训练和分布式计算需求,因此无需采用更复杂的网络拓扑。
在异构交换机网络环境下,GPU集群网络分析的复杂性提升。不同层的交换机差异,包括可能在单层内使用多种交换机,增加分析难度。
四、GPU集群算力
GPU集群算力公式
GPU集群有效算力 (Q) 由以下因素决定:
* 单个GPU峰值算力 (C)
* GPU数量 (N)
* 算力利用率 (u)
Q = C * N * u
对于大模型训练
在进行大模型训练时,算力利用率 (u) 即 MFU (Model FLOPS Utilization)。MFU 代表使用 N 个 GPU 的计算任务所能获得的有效算力。
关于算力利用率u,我们要进一步区分算力利用率与线性加速比k。即便是我们在使用单张GPU进行计算,也有算力利用率的问题(相应的,也有显存利用率的问题,Model Bandwidth Utilization (MBU) [12]),例如,单卡算力利用率 u = 75%。
如果一个计算任务里使用了N个GPU卡,那么算力利用率u一般会随着GPU数量N的增加而变小;总有效算力C会随着N的增加而增加,直到饱和(即N增加的边际效用递减)。一个GPU集群的总有效算力C随着N增加的变化速度就是线性加速比k。
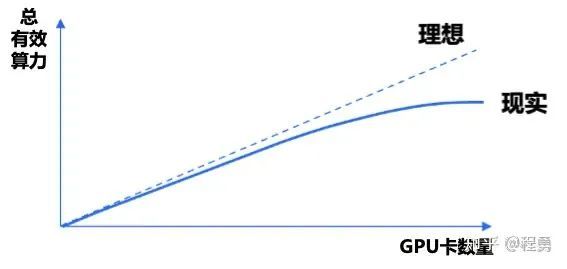
GPU集群总有效算力随着GPU卡数量的变化情况示例 [11]
流量系数 (k) 表明在相等流量条件下,材料 2 的线速度与材料 1 的关系。公式为:
k = u2/u1
其中:
* k 为流量系数
* u2 为材料 2 的线速度
* u1 为材料 1 的线速度
假设流量 (Q) 相等,材料 2 的线速度较小 (u2 ≤ u1),且材料 2 的数量 (N2) 较多 (N2 ≥ N1)。
在理想情况下,集群总有效算力与 GPU 卡数量呈线性增长。然而,这种增长受限于单个 GPU 的利用率,这可能是较低的。
算力利用率衡量单个 GPU 的效率,而线性加速比表示集群整体性能的增长。这两个指标从不同角度描述 GPU 集群的性能。
基于假设 u1 = 45.29% (N1 = 3584) 和 u2 = 42.19% (N2 = 10752),线性加速比得出为 k = 93%。
影响 GPU 集群加速比的因素众多,包括峰值算力、显存容量、互联方式和网络架构。
优化情况下,线性加速比可达 90% 以上。然而,大规模 GPU 集群的平均算力利用率仅约为 50%。

-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-



