
【人工智能Ⅱ】实验4:Unet眼底血管图像分割



实验4:Unet眼底血管图像分割
一:实验目的与要求
1:掌握图像分割的含义。
2:掌握利用Unet建立训练模型。
3:掌握使用Unet进行眼底血管图像数据集的分割。
二:实验内容
1:用Unet网络完成眼底血管图像数据集的分割任务。
2:可视化比较Unet、Unet++的分割效果。
3:尝试调整网络参数提高模型的分割精度。
三:实验环境
本实验所使用的环境条件如下表所示。
| 操作系统 | Ubuntu(Linux) |
| 程序语言 | Python(3.8.10) |
| 第三方依赖 | torch, torchvision, matplotlib,tensorflow,PIL,os,opencv-python、keras、numpy等packages |
四:方法流程
1:编写数据加载代码,下载DRIVE.rar的眼球图像数据集。
2:编写UNet和UNet++模型的网络结构代码,其中UNet++需要分别输出L4、L3、L2和L1的结果,如下图所示。

3:编写可视化比较原图和 FCN 测试后的输出结果图,以及在训练过程中根据迭代次数增加的评价指标曲线图,包括train-accuracy、val-accuracy、train-loss和val-loss。
4:尝试增加训练的迭代次数Epoch,提高分割精度。
五:实验展示(训练过程和训练部分结果进行可视化)
1:UNet模型训练
采用【model.summary()】代码,输出UNet模型的详细结构,结果如下图所示。分析可知,本次训练的参数量为517090。

而后,模型采用Adam作为优化器,0.001作为初始学习率,交叉熵函数作为损失函数。在模型训练过程中,采用64作为批大小,200作为迭代次数。训练集和验证集的比例为8:2。
训练过程中的训练集和验证集上的损失值,如下图所示。

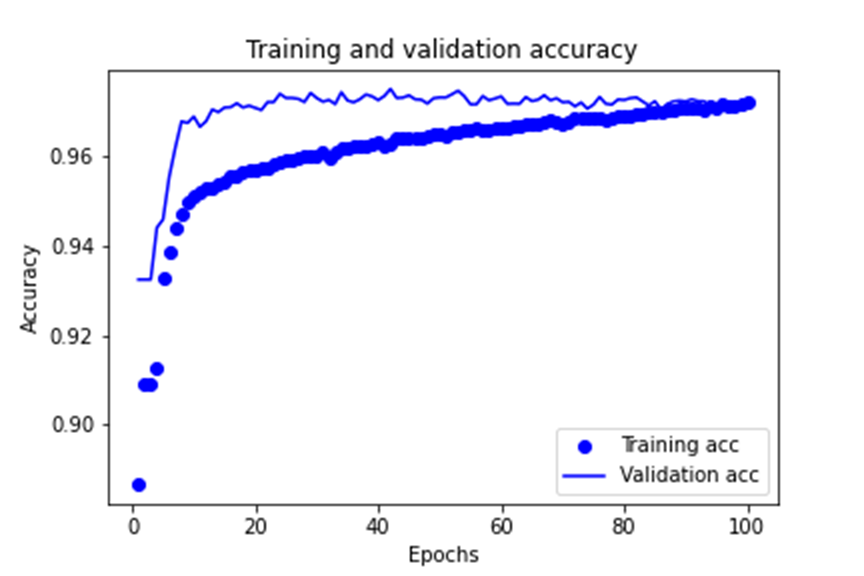
训练过程中的训练集和验证集上的准确率,如下图所示。

测试图像的预测结果与原图的对比结果,如下图所示。其中,左侧为预测结果,右侧为真实图像。

UNet中的关键代码如下表所示,即模型结构的搭建。
| def unet_model(n_ch,patch_height,patch_width): inputs = Input(shape=(n_ch,patch_height,patch_width)) conv1 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(inputs) conv1 = Dropout(0.2)(conv1) conv1 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv1) pool1 = MaxPooling2D((2, 2))(conv1)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(pool1) conv2 = Dropout(0.2)(conv2) conv2 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv2) pool2 = MaxPooling2D((2, 2))(conv2)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same',data_format='channels_first')(pool2) conv3 = Dropout(0.2)(conv3) conv3 = Conv2D(128, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv3)
up1 = UpSampling2D(size=(2, 2))(conv3) up1 = concatenate([conv2,up1],axis=1) conv4 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(up1) conv4 = Dropout(0.2)(conv4) conv4 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv4) up2 = UpSampling2D(size=(2, 2))(conv4) up2 = concatenate([conv1,up2], axis=1) conv5 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(up2) conv5 = Dropout(0.2)(conv5) conv5 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv5) conv6 = Conv2D(2, (1, 1), activation='relu',padding='same',data_format='channels_first')(conv5) conv6 = Reshape((2,patch_height*patch_width))(conv6) conv6 = Permute((2,1))(conv6)
conv7 = Activation('softmax')(conv6)
model = Model(inputs=inputs, outputs=conv7) return model |
2:UNet++模型训练
【1】UNet L1模型训练
采用【model.summary()】代码,输出UNet L1模型的详细结构,结果如下图所示。分析可知,本次训练的参数量为111202。

而后,模型采用Adam作为优化器,0.001作为初始学习率,交叉熵函数作为损失函数。在模型训练过程中,采用64作为批大小,100作为迭代次数。训练集和验证集的比例为8:2。
训练过程中的训练集和验证集上的损失值,如下图所示。

训练过程中的训练集和验证集上的准确率,如下图所示。
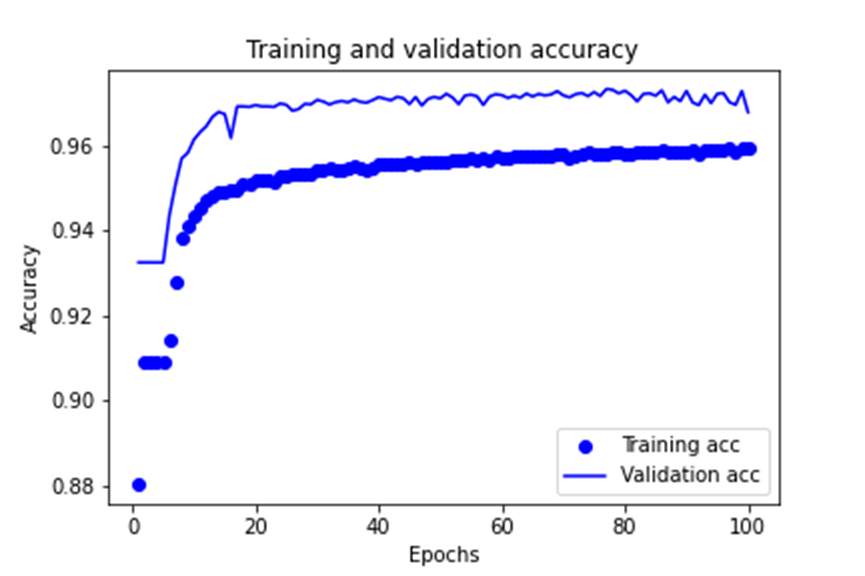
测试图像的预测结果与原图的对比结果,如下图所示。其中,左侧为预测结果,右侧为真实图像。

【2】UNet L2模型训练
采用【model.summary()】代码,输出UNet L2模型的详细结构,结果如下图所示。分析可知,本次训练的参数量为581666。


而后,模型采用Adam作为优化器,0.001作为初始学习率,交叉熵函数作为损失函数。在模型训练过程中,采用64作为批大小,100作为迭代次数。训练集和验证集的比例为8:2。
训练过程中的训练集和验证集上的损失值,如下图所示。

训练过程中的训练集和验证集上的准确率,如下图所示。

测试图像的预测结果与原图的对比结果,如下图所示。其中,左侧为预测结果,右侧为真实图像。

【3】UNet L3模型训练
采用【model.summary()】代码,输出UNet L3模型的详细结构,结果如下图所示。分析可知,本次训练的参数量为2536418。



而后,模型采用Adam作为优化器,0.001作为初始学习率,交叉熵函数作为损失函数。在模型训练过程中,采用64作为批大小,100作为迭代次数。训练集和验证集的比例为8:2。
训练过程中的训练集和验证集上的损失值,如下图所示。

训练过程中的训练集和验证集上的准确率,如下图所示。
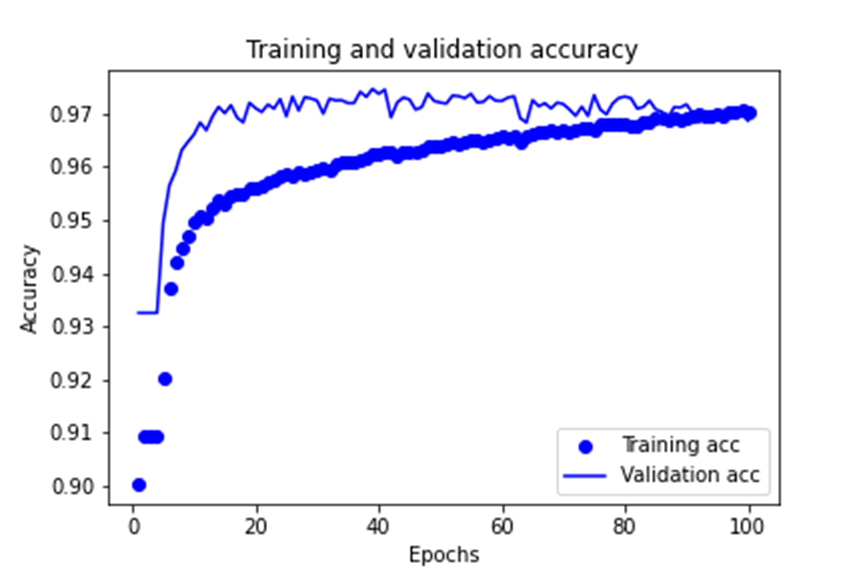
测试图像的预测结果与原图的对比结果,如下图所示。其中,左侧为预测结果,右侧为真实图像。
【4】UNet L4模型训练
采用【model.summary()】代码,输出UNet L4模型的详细结构,结果如下图所示。分析可知,本次训练的参数量为10436514。




而后,模型采用Adam作为优化器,0.001作为初始学习率,交叉熵函数作为损失函数。在模型训练过程中,采用64作为批大小,100作为迭代次数。训练集和验证集的比例为8:2。
训练过程中的训练集和验证集上的损失值,如下图所示。

训练过程中的训练集和验证集上的准确率,如下图所示。
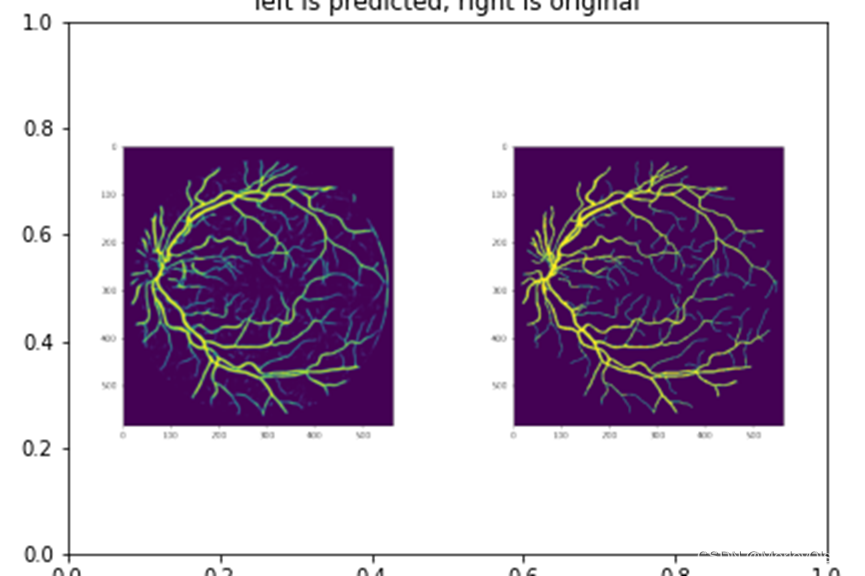
测试图像的预测结果与原图的对比结果,如下图所示。其中,左侧为预测结果,右侧为真实图像。

3:UNet++模型分析
UNet++中的关键代码如下表所示,即模型结构的搭建。
| def conv_block(input_tensor, num_filters): """构造一个简单的卷积块,包含两个卷积层""" x = Conv2D(num_filters, (3, 3), activation='relu', padding='same', data_format='channels_first')(input_tensor) x = Dropout(0.2)(x) x = Conv2D(num_filters, (3, 3), activation='relu', padding='same', data_format='channels_first')(x) return x def unet_pp(n_ch, patch_height, patch_width): inputs = Input(shape=(n_ch, patch_height, patch_width)) # 编码路径 x00 = conv_block(inputs, 32) p0 = MaxPooling2D((2, 2))(x00) x10 = conv_block(p0, 64) p1 = MaxPooling2D((2, 2))(x10) x20 = conv_block(p1, 128) p2 = MaxPooling2D((2, 2))(x20) x30 = conv_block(p2, 256) p3 = MaxPooling2D((2, 2))(x30) x40 = conv_block(p3, 512) # 最底层
# wtf 纯手写中间层啊,草 x40_up = UpSampling2D(size=(2, 2))(x40) x40_up = concatenate([x30,x40_up],axis=1) x31 = conv_block(x40_up, 256)
x30_up = UpSampling2D(size=(2, 2))(x30) x30_up = concatenate([x20,x30_up],axis=1) x21 = conv_block(x30_up, 128)
x20_up = UpSampling2D(size=(2, 2))(x20) x20_up = concatenate([x10,x20_up],axis=1) x11 = conv_block(x20_up, 64)
x10_up = UpSampling2D(size=(2, 2))(x10) x10_up = concatenate([x00,x10_up],axis=1) x01 = conv_block(x10_up, 32)
x31_up = UpSampling2D(size=(2, 2))(x31) x31_up = concatenate([x21,x31_up],axis=1) x31_up = concatenate([x20,x31_up],axis=1) x22 = conv_block(x31_up, 128)
x21_up = UpSampling2D(size=(2, 2))(x21) x21_up = concatenate([x11,x21_up],axis=1) x21_up = concatenate([x10,x21_up],axis=1) x12 = conv_block(x21_up, 64)
x11_up = UpSampling2D(size=(2, 2))(x11) x11_up = concatenate([x01,x11_up],axis=1) x11_up = concatenate([x00,x11_up],axis=1) x02 = conv_block(x11_up, 32)
x22_up = UpSampling2D(size=(2, 2))(x22) x22_up = concatenate([x12,x22_up],axis=1) x22_up = concatenate([x11,x22_up],axis=1) x22_up = concatenate([x10,x22_up],axis=1) x13 = conv_block(x22_up, 64)
x12_up = UpSampling2D(size=(2, 2))(x12) x12_up = concatenate([x02,x12_up],axis=1) x12_up = concatenate([x01,x12_up],axis=1) x12_up = concatenate([x00,x12_up],axis=1) x03 = conv_block(x12_up, 32)
x13_up = UpSampling2D(size=(2, 2))(x13) x13_up = concatenate([x03,x13_up],axis=1) x13_up = concatenate([x02,x13_up],axis=1) x13_up = concatenate([x01,x13_up],axis=1) x13_up = concatenate([x00,x13_up],axis=1) x04 = conv_block(x13_up, 32)
# 最终层 final_1 = Conv2D(2,(1,1),activation='relu',padding='same',data_format='channels_first')(x01) final_1 = Reshape((2,patch_height*patch_width))(final_1) final_1 = Permute((2,1))(final_1) final_1 = Activation('softmax')(final_1)
final_2 = Conv2D(2,(1,1),activation='relu',padding='same',data_format='channels_first')(x02) final_2 = Reshape((2,patch_height*patch_width))(final_2) final_2 = Permute((2,1))(final_2) final_2 = Activation('softmax')(final_2)
final_3 = Conv2D(2,(1,1),activation='relu',padding='same',data_format='channels_first')(x03) final_3 = Reshape((2,patch_height*patch_width))(final_3) final_3 = Permute((2,1))(final_3) final_3 = Activation('softmax')(final_3)
final_4 = Conv2D(2,(1,1),activation='relu',padding='same',data_format='channels_first')(x04) final_4 = Reshape((2,patch_height*patch_width))(final_4) final_4 = Permute((2,1))(final_4) final_4 = Activation('softmax')(final_4)
final = [final_1, final_2, final_3, final_4]
# Unet++ L4到L1需要manual modification。 model = Model(inputs=inputs, outputs=final_4) return model |
4:尝试提高模型的精度
本节部分将着重探讨不同epoch下得到的训练结果在测试图像上的验证结果。
在UNet模型中,当epoch=10时,得到的测试图像预测结果如下图所示。根据预测结果可以分析得到:在训练迭代次数较低的情况下,模型并不能很好的对眼球图像进行分割,只能看到比较粗的血管的纹路。
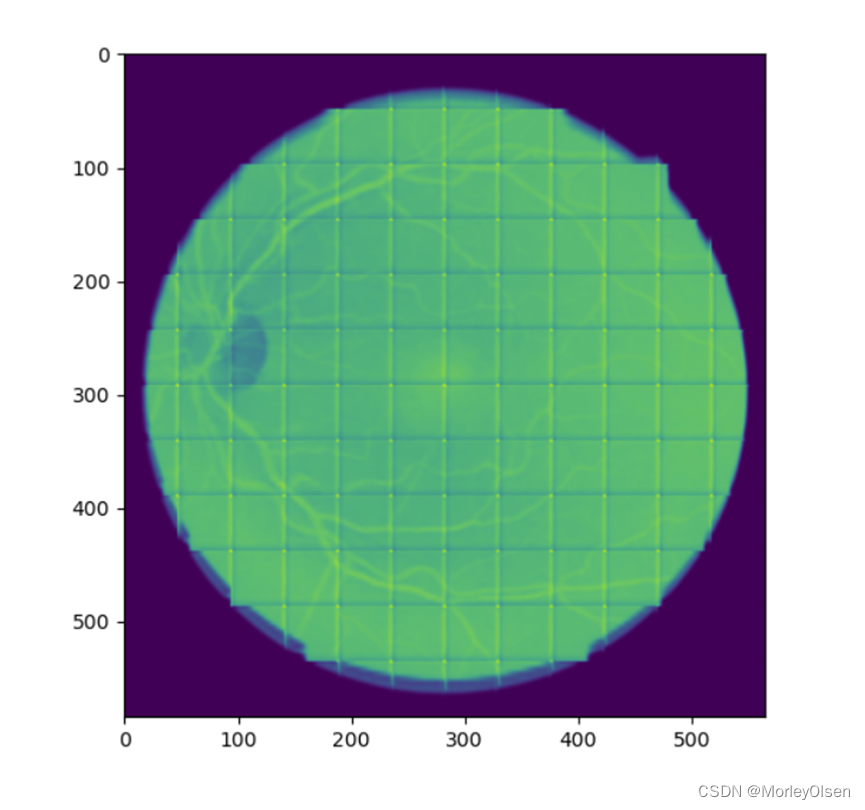
在UNet模型中,当epoch=40时,得到的测试图像预测结果如下图所示。根据预测结果可以分析得到:在训练迭代次数中等的情况下,模型能够基本完成对眼球图像进行分割,但是较细的血管仍然不可见。

在UNet模型中,当epoch=200时,得到的测试图像预测结果如下图所示。根据预测结果可以分析得到:在训练迭代次数较高的情况下,模型能够完全完成对眼球图像进行分割,所有眼球中的血管基本保持一个较高的能见度。
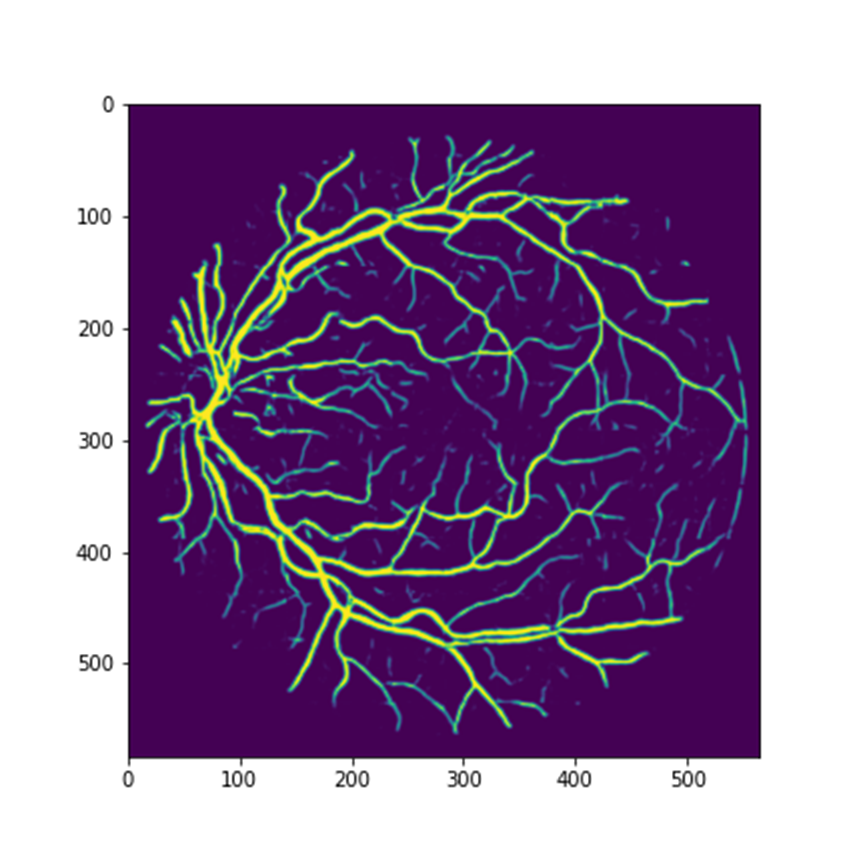
六:实验结论
1:UNet模型的网络结构,如下图所示。

2:UNet++模型中采用了L1到L4的子网络结构,且每个子网络的输出已经都是图像的分割结果。浅层的对小目标更敏感,深层对大目标更敏感,通过特征concat拼接到一起,可以整合二者的优点。
3:UNet模型和UNet++模型的参数量比较,如下图所示。
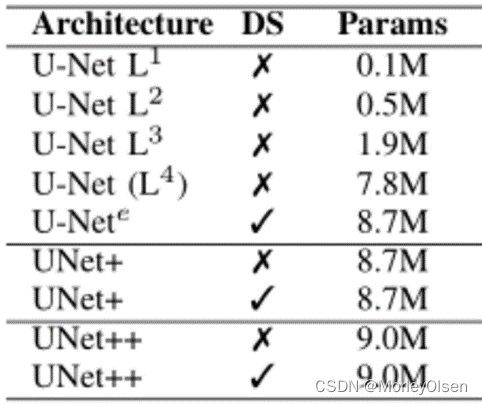
可以发现,UNet L4的参数 > UNet L3的参数 > UNet L2的参数 > UNet L1的参数。而真正实施的UNet++模型,通过pruning等方式,实现了参数的下降。
4:UNet系列模型中多次使用下采样和上采样。下采样可以增加对输入图像的一些小扰动的鲁棒性,比如图像平移,旋转等,减少过拟合的风险,降低运算量,增加感受野的大小。上采样可以把抽象的特征再还原解码到原图的尺寸,最终
得到分割结果。
5:浅层结构可以抓取图像的一些简单的特征,比如边界,颜色。深层结构因为感受野大,而且经过的卷积操作多,能抓取到图像的一些抽象特征。
七:遇到的问题和解决方法
问题1:运行代码时,出现dataset载入所调用的依赖包错误。
解决1:将transforms替换为torch中的模块,再进行图片的载入。
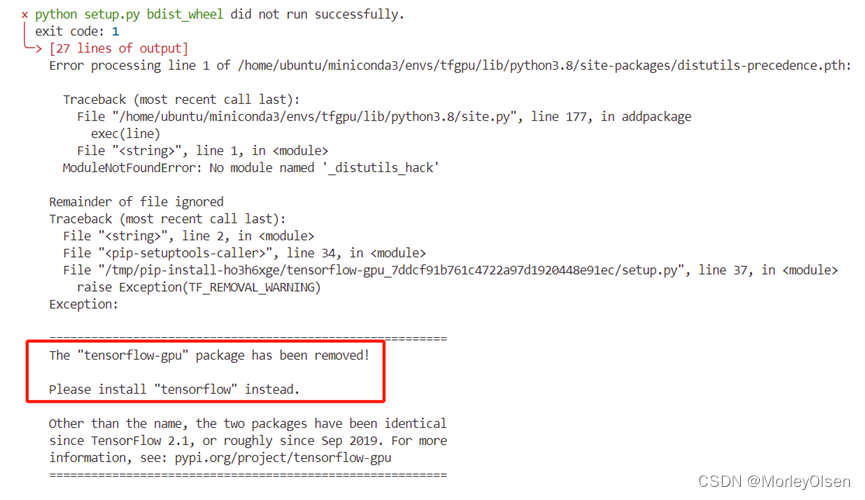
问题2:由于调用tensorflow包时,程序在训练过程中会显示【skip registering gpu】。即,无法正常调用gpu,只能调用cpu,因此训练速度非常慢。于是在服务器上尝试使用指令【pip install tensorflow-gpu】安装gpu版本的tensorflow,但是安装时出现以下报错。

解决2:尝试过conda指令安装【conda install tensorflow-gpu】、降低conda环境的python版本(conda create -n tfgpu python=3.8)和降低setuptools包的版本(如下图所示,参考自连接:https://blog.csdn.net/weixin_44244190/article/details/128863818),均未成功。因此,最后在AutoDL平台进行租借服务器进行训练,镜像采用TF基础镜像,后续配置完环境后可以调用gpu运行。
八:程序源代码
代码参考自:Unet简明代码实现眼底图像血管分割_unet网络进行眼底血管分割-CSDN博客,以下为最终实现的UNet模型和UNet++模型(或直接查看平台上的ipynb文件中的代码)。
| UNet模型 |
| import numpy as np import cv2 from PIL import Image import matplotlib.pyplot as plt import os from keras.models import Model from keras.layers import Input, concatenate, Conv2D, MaxPooling2D, UpSampling2D, Reshape, Permute, Activation, Dropout from keras.optimizers import Adam, SGD from keras.callbacks import ModelCheckpoint, LearningRateScheduler from keras import backend as K import tensorflow as tf config = tf.compat.v1.ConfigProto() config.gpu_options.allow_growth = True session = tf.compat.v1.Session(config=config) img_x, img_y = (576, 576) dx = 48 filelst = os.listdir(r'/home/ubuntu/DRIVE/training/images/') filelst = ['DRIVE/training/images/'+v for v in filelst] imgs = [cv2.imread(file) for file in filelst] filelst = os.listdir(r'/home/ubuntu/DRIVE/training/1st_manual/') filelst = ['DRIVE/training/1st_manual/'+v for v in filelst] manuals = [np.asarray(Image.open(file)) for file in filelst] imgs = [cv2.resize(v,(img_x, img_y)) for v in imgs] manuals = [cv2.resize(v,(img_x, img_y)) for v in manuals] X_train = np.array(imgs) Y_train = np.array(manuals) X_train = X_train.astype('float32')/255. Y_train = Y_train.astype('float32')/255. X_train = X_train[...,1] # the G channel X_train = np.array([[X_train[:,v*dx:(v+1)*dx, vv*dx:(vv+1)*dx] for v in range(img_y//dx)] for vv in range(img_x//dx)]).reshape(-1,dx,dx)[:,np.newaxis,...] Y_train = np.array([[Y_train[:,v*dx:(v+1)*dx, vv*dx:(vv+1)*dx] for v in range(img_y//dx)] for vv in range(img_x//dx)]).reshape(-1,dx*dx)[...,np.newaxis] temp = 1-Y_train Y_train = np.concatenate([Y_train,temp],axis=2) def unet_model(n_ch,patch_height,patch_width): inputs = Input(shape=(n_ch,patch_height,patch_width)) conv1 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(inputs) conv1 = Dropout(0.2)(conv1) conv1 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv1) pool1 = MaxPooling2D((2, 2))(conv1)
conv2 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(pool1) conv2 = Dropout(0.2)(conv2) conv2 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv2) pool2 = MaxPooling2D((2, 2))(conv2)
conv3 = Conv2D(128, (3, 3), activation='relu', padding='same',data_format='channels_first')(pool2) conv3 = Dropout(0.2)(conv3) conv3 = Conv2D(128, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv3)
up1 = UpSampling2D(size=(2, 2))(conv3) up1 = concatenate([conv2,up1],axis=1) conv4 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(up1) conv4 = Dropout(0.2)(conv4) conv4 = Conv2D(64, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv4) up2 = UpSampling2D(size=(2, 2))(conv4) up2 = concatenate([conv1,up2], axis=1) conv5 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(up2) conv5 = Dropout(0.2)(conv5) conv5 = Conv2D(32, (3, 3), activation='relu', padding='same',data_format='channels_first')(conv5) conv6 = Conv2D(2, (1, 1), activation='relu',padding='same',data_format='channels_first')(conv5) conv6 = Reshape((2,patch_height*patch_width))(conv6) conv6 = Permute((2,1))(conv6)
conv7 = Activation('softmax')(conv6)
model = Model(inputs=inputs, outputs=conv7) return model
model = unet_model(X_train.shape[1],X_train.shape[2],X_train.shape[3]) model.summary() checkpointer = ModelCheckpoint(filepath='best_weights.h5', verbose=1, monitor='val_acc', mode='auto', save_best_only=True) model.compile(optimizer=Adam(lr=0.001), loss='categorical_crossentropy',metrics=['accuracy']) # modify epoch!!!!!!!!!!!!!!!!!!!!!!!!! model.fit(X_train, Y_train, batch_size=64, epochs=200, verbose=2,shuffle=True, validation_split=0.2, callbacks=[checkpointer])
imgs = cv2.imread(r'/home/ubuntu/DRIVE/test/images/01_test.tif')[...,1] #the G channel imgs = cv2.resize(imgs,(img_x, img_y)) manuals = np.asarray(Image.open(r'/home/ubuntu/DRIVE/test/1st_manual/01_manual1.gif')) X_test = imgs.astype('float32')/255. Y_test = manuals.astype('float32')/255. X_test = np.array([[X_test[v*dx:(v+1)*dx, vv*dx:(vv+1)*dx] for v in range(img_y//dx)] for vv in range(img_x//dx)]).reshape(-1,dx,dx)[:,np.newaxis,...] # model.load_weights('best_weights.h5') Y_pred = model.predict(X_test) Y_pred = Y_pred[...,0].reshape(img_x//dx,img_y//dx,dx,dx) Y_pred = [Y_pred[:,v,...] for v in range(img_x//dx)] Y_pred = np.concatenate(np.concatenate(Y_pred,axis=1),axis=1) Y_pred = cv2.resize(Y_pred,(Y_test.shape[1], Y_test.shape[0])) plt.figure(figsize=(6,6)) plt.imshow(Y_pred) plt.savefig('predicted_image.png') # 保存预测的图像 plt.close() # 关闭当前图形以释放内存 plt.figure(figsize=(6,6)) plt.imshow(Y_test) plt.savefig('ground_truth_image.png') # 保存真实的图像 plt.close() # 关闭当前图形以释放内存 |
| UNet++模型 |
| import numpy as np import cv2 from PIL import Image import matplotlib.pyplot as plt import os from keras.models import Model from keras.layers import Input, concatenate, Conv2D, MaxPooling2D, UpSampling2D, Reshape, Permute, Activation, Dropout from keras.optimizers import Adam, SGD from keras.callbacks import ModelCheckpoint, LearningRateScheduler from keras import backend as K import tensorflow as tf config = tf.compat.v1.ConfigProto() config.gpu_options.allow_growth = True session = tf.compat.v1.Session(config=config) img_x, img_y = (576, 576) dx = 48 filelst = os.listdir(r'/home/ubuntu/DRIVE/training/images/') filelst = ['DRIVE/training/images/'+v for v in filelst] imgs = [cv2.imread(file) for file in filelst] filelst = os.listdir(r'/home/ubuntu/DRIVE/training/1st_manual/') filelst = ['DRIVE/training/1st_manual/'+v for v in filelst] manuals = [np.asarray(Image.open(file)) for file in filelst] imgs = [cv2.resize(v,(img_x, img_y)) for v in imgs] manuals = [cv2.resize(v,(img_x, img_y)) for v in manuals] X_train = np.array(imgs) Y_train = np.array(manuals) X_train = X_train.astype('float32')/255. Y_train = Y_train.astype('float32')/255. X_train = X_train[...,1] # the G channel X_train = np.array([[X_train[:,v*dx:(v+1)*dx, vv*dx:(vv+1)*dx] for v in range(img_y//dx)] for vv in range(img_x//dx)]).reshape(-1,dx,dx)[:,np.newaxis,...] Y_train = np.array([[Y_train[:,v*dx:(v+1)*dx, vv*dx:(vv+1)*dx] for v in range(img_y//dx)] for vv in range(img_x//dx)]).reshape(-1,dx*dx)[...,np.newaxis] temp = 1-Y_train Y_train = np.concatenate([Y_train,temp],axis=2) print("X_train shape:", X_train.shape) print("Y_train shape:", Y_train.shape) def conv_block(input_tensor, num_filters): """构造一个简单的卷积块,包含两个卷积层""" x = Conv2D(num_filters, (3, 3), activation='relu', padding='same', data_format='channels_first')(input_tensor) x = Dropout(0.2)(x) x = Conv2D(num_filters, (3, 3), activation='relu', padding='same', data_format='channels_first')(x) return x def unet_pp(n_ch, patch_height, patch_width): inputs = Input(shape=(n_ch, patch_height, patch_width)) # 编码路径 x00 = conv_block(inputs, 32) p0 = MaxPooling2D((2, 2))(x00) x10 = conv_block(p0, 64) p1 = MaxPooling2D((2, 2))(x10) x20 = conv_block(p1, 128) p2 = MaxPooling2D((2, 2))(x20) x30 = conv_block(p2, 256) p3 = MaxPooling2D((2, 2))(x30) x40 = conv_block(p3, 512) # 最底层
# wtf 纯手写中间层啊,草 x40_up = UpSampling2D(size=(2, 2))(x40) x40_up = concatenate([x30,x40_up],axis=1) x31 = conv_block(x40_up, 256)
x30_up = UpSampling2D(size=(2, 2))(x30) x30_up = concatenate([x20,x30_up],axis=1) x21 = conv_block(x30_up, 128)
x20_up = UpSampling2D(size=(2, 2))(x20) x20_up = concatenate([x10,x20_up],axis=1) x11 = conv_block(x20_up, 64)
x10_up = UpSampling2D(size=(2, 2))(x10) x10_up = concatenate([x00,x10_up],axis=1) x01 = conv_block(x10_up, 32)
x31_up = UpSampling2D(size=(2, 2))(x31) x31_up = concatenate([x21,x31_up],axis=1) x31_up = concatenate([x20,x31_up],axis=1) x22 = conv_block(x31_up, 128)
x21_up = UpSampling2D(size=(2, 2))(x21) x21_up = concatenate([x11,x21_up],axis=1) x21_up = concatenate([x10,x21_up],axis=1) x12 = conv_block(x21_up, 64)
x11_up = UpSampling2D(size=(2, 2))(x11) x11_up = concatenate([x01,x11_up],axis=1) x11_up = concatenate([x00,x11_up],axis=1) x02 = conv_block(x11_up, 32)
x22_up = UpSampling2D(size=(2, 2))(x22) x22_up = concatenate([x12,x22_up],axis=1) x22_up = concatenate([x11,x22_up],axis=1) x22_up = concatenate([x10,x22_up],axis=1) x13 = conv_block(x22_up, 64)
x12_up = UpSampling2D(size=(2, 2))(x12) x12_up = concatenate([x02,x12_up],axis=1) x12_up = concatenate([x01,x12_up],axis=1) x12_up = concatenate([x00,x12_up],axis=1) x03 = conv_block(x12_up, 32)
x13_up = UpSampling2D(size=(2, 2))(x13) x13_up = concatenate([x03,x13_up],axis=1) x13_up = concatenate([x02,x13_up],axis=1) x13_up = concatenate([x01,x13_up],axis=1) x13_up = concatenate([x00,x13_up],axis=1) x04 = conv_block(x13_up, 32)
# 最终层 final_1 = Conv2D(2,(1,1),activation='relu',padding='same',data_format='channels_first')(x01) final_1 = Reshape((2,patch_height*patch_width))(final_1) final_1 = Permute((2,1))(final_1) final_1 = Activation('softmax')(final_1)
final_2 = Conv2D(2,(1,1),activation='relu',padding='same',data_format='channels_first')(x02) final_2 = Reshape((2,patch_height*patch_width))(final_2) final_2 = Permute((2,1))(final_2) final_2 = Activation('softmax')(final_2)
final_3 = Conv2D(2,(1,1),activation='relu',padding='same',data_format='channels_first')(x03) final_3 = Reshape((2,patch_height*patch_width))(final_3) final_3 = Permute((2,1))(final_3) final_3 = Activation('softmax')(final_3)
final_4 = Conv2D(2,(1,1),activation='relu',padding='same',data_format='channels_first')(x04) final_4 = Reshape((2,patch_height*patch_width))(final_4) final_4 = Permute((2,1))(final_4) final_4 = Activation('softmax')(final_4)
final = [final_1, final_2, final_3, final_4]
# Unet++ L4到L1需要manual modification。 model = Model(inputs=inputs, outputs=final_4) return model
model = unet_pp(X_train.shape[1],X_train.shape[2],X_train.shape[3]) # model.summary() # mode = 'auto' checkpointer = ModelCheckpoint(filepath='best_weights.h5', verbose=1, monitor='val_acc', mode='max', save_best_only=True) model.compile(optimizer=Adam(lr=0.001), loss='categorical_crossentropy',metrics=['accuracy']) # modify epoch!!!!!!!!!!!!!!!!!!!!!!!!! # model.fit(X_train, Y_train, batch_size=64, epochs=1, verbose=2,shuffle=True, validation_split=0.2, callbacks=[checkpointer])
imgs = cv2.imread(r'/home/ubuntu/DRIVE/test/images/01_test.tif')[...,1] #the G channel imgs = cv2.resize(imgs,(img_x, img_y)) manuals = np.asarray(Image.open(r'/home/ubuntu/DRIVE/test/1st_manual/01_manual1.gif')) X_test = imgs.astype('float32')/255. Y_test = manuals.astype('float32')/255. X_test = np.array([[X_test[v*dx:(v+1)*dx, vv*dx:(vv+1)*dx] for v in range(img_y//dx)] for vv in range(img_x//dx)]).reshape(-1,dx,dx)[:,np.newaxis,...] print("X_test shape:", X_test.shape) print("input shape:", model.input_shape) print("output shape:", model.output_shape) # model.load_weights('best_weights.h5') Y_pred = model.predict(X_test) Y_pred = Y_pred[...,0].reshape(img_x//dx,img_y//dx,dx,dx) Y_pred = [Y_pred[:,v,...] for v in range(img_x//dx)] Y_pred = np.concatenate(np.concatenate(Y_pred,axis=1),axis=1) Y_pred = cv2.resize(Y_pred,(Y_test.shape[1], Y_test.shape[0])) plt.figure(figsize=(6,6)) plt.imshow(Y_pred) plt.savefig('unetpp_predicted_image.png') # 保存预测的图像 plt.close() # 关闭当前图形以释放内存 plt.figure(figsize=(6,6)) plt.imshow(Y_test) plt.savefig('unetpp_ground_truth_image.png') # 保存真实的图像 plt.close() # 关闭当前图形以释放内存 |



