
学习LLM的随笔


.png)

1、信息量、信息熵、交叉熵和困惑度
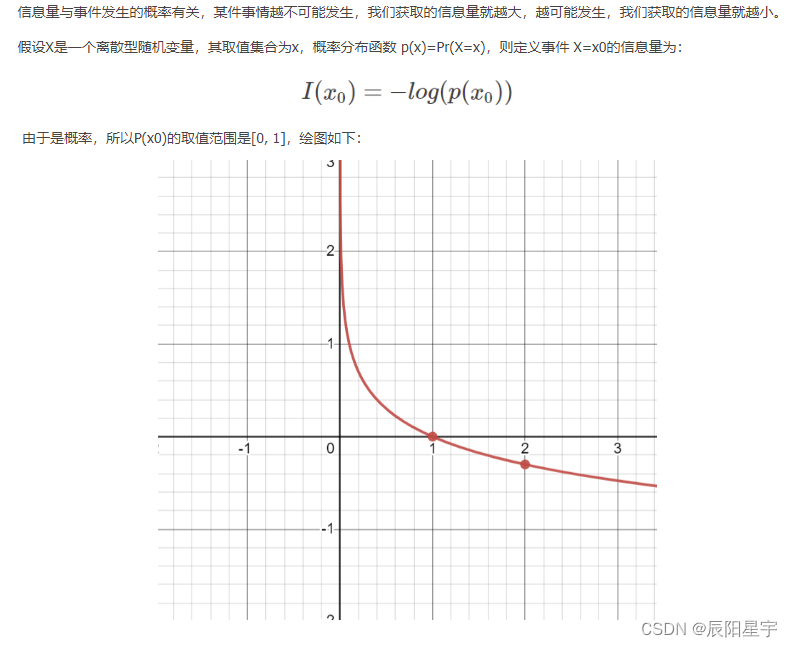




(1)信息熵:信息熵中使用 l o g 2 ( p ( x ) ) log_2(p(x)) log2(p(x)) 来表示对 x x x 编码需要的编码长度。由于不同事件发生的概率不同,我们不能简单地将这些信息量相加,而应该根据它们发生的概率进行加权平均。乘上 p ( x ) p(x) p(x) 并求和,相当于是做了加权求和。
熵值越大,所含信息量越多,事件发生的情况越不确定。熵值越小,所含信息量越小,事件发生的情况确定。
(2)交叉熵: H ( p , q ) H(p,q) H(p,q) 是用语言模型 q ( x ) q(x) q(x) 编码来估计真实数据分布 p ( x ) p(x) p(x)。
(3)困惑度:用来衡量模型在预测下一个词时的平均不确定性。困惑度可以被理解为每个标记(token)的平均"分支因子(branching factor)"。这里的“分支因子”可以理解为在每个位置,模型认为有多少种可能的词会出现。 p e r p l e x i t y ( x ) = P ( w 1 , w 2 , w 3 , . . . , w n ) − 1 n = 2 1 n l o g 2 P ( w 1 , w 2 , w 3 , . . . , w n ) perplexity(x)=P(w_1,w_2,w_3,...,w_n)^{-\frac{1}{n}}=2^{\frac{1}{n}log_2P(w_1,w_2,w_3,...,w_n)} perplexity(x)=P(w1,w2,w3,...,wn)−n1=2n1log2P(w1,w2,w3,...,wn),这种形式让指数部分成为了交叉熵形式,同时也便于将多个相乘的概率,变为以 log 嵌套的多个相加的形式。
-
- 困惑度为什么要有指数部分 − 1 n -\frac{1}{n} −n1?
- 答:施加 − 1 n \frac{-1}{n} n−1 是因为要考虑语料长度的影响。如果一个句子越长,这个句子出现的概率可能会越低(比如“你好”和“你是我心中最美的云彩”这两句话,前者出现的概率很高)。(-1/N)次幂相当于一个“惩罚因子”。对于一个位于(0,1)范围的数,施加了(-1/N)次幂后,N越大,施加之后的值越小。同时,采用几何平均来归一化,而不用平均值来归一化也是为了防止有概率0出现时,可以很好的表示出这种影响。
-
- 指数部分为什么是交叉熵?为什么是 − 1 N ∑ i = 1 N l o g 2 ( p ( w i ∣ w 1 , w 2 , . . . , w i − 1 ) ) -\frac{1}{N} \sum_{i=1}^N log_2(p(w_i|w_1,w_2,...,w_{i-1})) −N1∑i=1Nlog2(p(wi∣w1,w2,...,wi−1)) 这个形式?
- 答:使用交叉熵来度量对信息编码的二进制信息编码长度。这种形式实际上是对 p ( x ) p(x) p(x) 的平均几何值取 l o g 2 log_2 log2。采用平均几何值得好处是每个词标记的概率都被同等看待,并且一个极低的概率(如0)将会导致整个几何平均大幅度下降。因此,通过计算几何平均,我们可以更好地衡量模型在处理所有可能的词标记时的性能,特别是在处理那些模型可能会出错的情况。
-
- 底数部分为什么是以2为底数?
- 答:因为指数部分的交叉熵是衡量以二进制进行编码的编码长度,所以底数部分也取2,可得到以二进制编码时,可以编码的字符串长度。之后,就可以得到模型在每个预测位置上,所考虑的可能出现的词的平均选择数量,即平均分支因子。
采用困惑度时,会遇到一些问题。

(4)pytorch中困惑度的实现
torch.nn.CrossEntropyLoss()直帮我们实现了交叉熵损失值的计算,也就是困惑度公式中指数部分。
举例:
import torch import torch.nn as nn # 假设我们有一个批量大小为2的输入和对应的真实标签 logits = torch.tensor([[1.0, 2.0, 3.0], [3.0, 2.0, 1.0]]) true_labels = torch.tensor([2, 0]) # 第一个样本中的第二类,第二个样本中的第一类为正例 # 注意,这里的logits直接用原始输出,不需要添加Softmax层 # 创建CrossEntropyLoss loss_function = nn.CrossEntropyLoss() # 计算损失 loss = loss_function(logits, true_labels) print(loss)
nn.CrossEntropyLoss()的计算过程:
1、Softmax 转换为概率形式
对于一个logits向量 x x x,softmax函数会将每个元素 x i x_i xi 转换成一个概率 P P P: s o f t m a x ( x i ) = e x i ∑ j e x j softmax(x_i)=\frac{e^{x_i}}{\sum_j{e^{x_j}}} softmax(xi)=∑jexjexi。
2、计算负对数似然
交叉熵损失函数会根据真实标签计算负对数似然。对于每个样本 𝑖,交叉熵损失计算的是实际标签对应的负对数概率: l o s s i = − l o g ( s o f t m a x ( x i ) y j ) loss_i=-log(softmax(x_i)_{y_j}) lossi=−log(softmax(xi)yj),其中 y j y_j yj 是样本 i i i 的真实标签。
3、平均损失
交叉熵损失函数会对所有样本的损失取平均值,即 l o s s = 1 N ∑ i = 1 N l o s s i loss=\frac{1}{N}\sum_{i=1}^Nloss_i loss=N1∑i=1Nlossi。
然后,根据上面得到交叉熵损失计算困惑度,得到困惑度。(在pytorch中计算log时使用e为底数,因此这里计算困惑度时候底数也用e)
perplexity = torch.exp(loss) # 使用之前求得的交叉熵损失值loss
学习文章:深入理解语言模型的困惑度(perplexity)、第2章 大模型的能力、深度学习之PyTorch实战(5)——对CrossEntropyLoss损失函数的理解与学习

")




