
Hadoop3单机伪分布集群安装


.png)

Hadoop3单机伪分布集群安装
1.配置SSH免密钥登录
要安装部署Hadoop3,除了安装JDK外,还要进行SSH免密钥登录功能的配置,这是为了方便进行集群主机间的通信,配置SSH免密钥登录的步骤如下:
1)在需要进行集群统一管理的虚拟机上输入命令 ssh-keygen -t rsa
生成密钥(根据提示可以不用输入任何内容,连续按4次Enter键确认即可)。
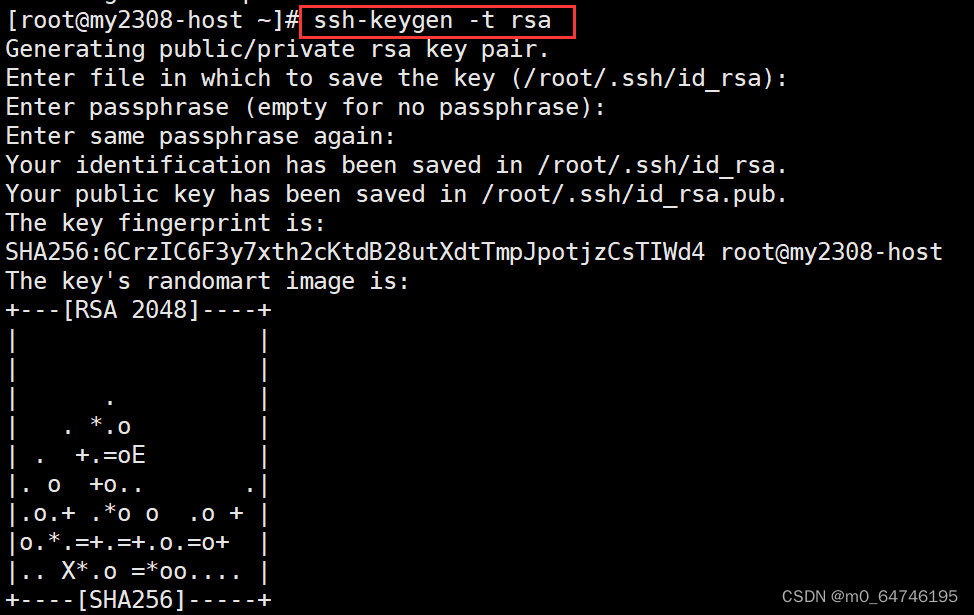
(2)生成密钥操作默认会在root目录下生成一个包含有密钥文件的.ssh隐藏目录。执行命令
cd /root/.ssh
进入.ssh隐藏目录,在该目录下执行ll -a命令查看当前目录下的所有文件。其中,id_rsa和id_rsa.pub这两个文件分别是私钥文件和公钥文件。
(3)为了便于文件配置和虚拟机通信,通常会对主机名和IP做映射配置,在虚拟机执行命令 vi /etc/hosts编辑映射文件hosts,在映射文件中添加如下内容:
将文件中主机IP地址修改为自己的主机IP地址。
(4)在虚拟机上执行命令
"ssh-copy-id 主机名"
将公钥复制到相关联的虚拟机(包括自身)

(5)在本虚拟机上执行"ssh 目标机器"命令连接到目标机器上,进行验证免密钥登录操作,此时无需输入密码便可直接登录目标虚拟机进行操作,如需返回本虚拟机,执行exit命令即可。
- Hadoop集群启动必须确保防火墙的关闭
查看防火墙状态:
firewall-cmd --state
停止防火墙服务:
systemctl stop firewalld
禁用防火墙服务,确保其在系统重新启动后不会自动启动
systemctl disable firewalld
2.Hadoop 伪分布集群安装
下面开始在 1 台 linux 虚拟机上开始安装 Hadoop3 伪分布环境,Linux虚拟机采用centos7,在这里我们使用 hadoop3.2.0 版本:hadoop-3.2.0.tar.gz
(1)把 hadoop-3.2.0.tar.gz 安装包上传到 linux 机器的/export/software/ 目录下
通过软件Xftp7将 hadoop-3.2.0.tar.gz 上传到虚拟机
(2)解压 hadoop 安装包到/export/servers目录下
tar -zxvf -C hadoop-3.2.0.tar.gz /export/servers
(3)进入配置文件所在目录
cd hadoop-3.2.0/etc/hadoop/
(4)修改 hadoop-env.sh 文件,增加环境变量信息
vi hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_161 export HADOOP_LOG_DIR=/export/data/hadoop_repo/logs/hadoop

保存退出
注意:需要先创建/export/data/hadoop_repo/logs/hadoop日志目录。
sudo mkdir -p /export/data/hadoop_repo/logs/hadoop
(5)修改 core-site.xml 文件,注意 fs.defaultFS 属性中的主机名**(my2308-host)**需要和你配置的主机名保持一致
#cd hadoop-3.2.0/etc/hadoop/ #vi core-site.xml
fs.defaultFS hdfs://my2308-host:9000 hadoop.tmp.dir /export/data/hadoop_repo(6)修改 hdfs-site.xml 文件,把 hdfs 中文件副本的数量设置为 1,因为现在伪分布集群只有一个节点
vi hdfs-site.xml
dfs.replication 1(7)修改 mapred-site.xml,设置 mapreduce 使用的资源调度框架
vi mapred-site.xml
mapreduce.framework.name yarn(8)修改 yarn-site.xml,设置 yarn 上支持运行的服务和环境变量白名单
vi yarn-site.xml
yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.env-whitelist JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME(9)格式化 namenode
cd /export/servers/hadoop-3.2.0 bin/hdfs namenode -format
如果在后面的日志信息中能看到这一行,则说明 namenode 格式化成功。
common.Storage: Storage directory xxx has been successfully
formatted.
(10)修改start-dfs.sh文件(在hadoop-3.2.0/sbin目录下),在文件前面增加如下内容
vi start-dfs.sh
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
(11)修改stop-dfs.sh文件(在hadoop-3.2.0/sbin目录下),在文件前面增加如下内容
vi stop-dfs.sh
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
(12)修改 start-yarn.sh文件(在hadoop-3.2.0/sbin目录下),在文件前面增加如下内容
vi start-yarn.sh
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
(13)修改stop-yarn.sh 文件(在hadoop-3.2.0/sbin目录下),在文件前面增加如下内容
vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
(14)启动 hadoop 集群
sbin/start-all.sh
(15)验证集群进程信息
执行 jps 命令可以查看集群的进程信息,除了jps 这个进程之外还需要有 5 个进程才说明集群是正常启动的
jps

#注:如果缺少节点则有可能是core-site.xml 或hosts文件配置错误
(16)通过 webui 界面来验证集群服务是否正常:
hdfs webui 界面:http://虚拟机IP:9000
yarn webui 界面:http://虚拟机IP:8088
(16)停止hadoop集群
sbin/stop-all.sh

")

:JobManager 内存分配(含实际计算案例)")

