
Spark 基础教程 一文看懂 spark 常用操作汇总




💐💐扫码关注公众号,回复 spark 关键字下载geekbang 原价 90 元 零基础入门 Spark 学习资料💐💐
目录
SparkCore(单词计数)
创建 RDD
SparkContext.parallelize
SparkContext.textFile
RDD 内的数据转换
map:以元素为粒度的数据转换
mapPartitions:以数据分区为粒度的数据转换
flatMap:从元素到集合、再从集合到元素
filter:过滤 RDD
数据聚合
groupByKey:分组收集
reduceByKey:分组聚合
aggregateByKey:更加灵活的聚合算子
sortByKey:排序
内存管理
RDD Cache
数据准备
union
sample
数据预处理
repartition
coalesce
结果收集
first、take 和 collect
saveAsTextFile
广播变量&累加器
广播变量(Broadcast variables)
累加器(Accumulators)
SparkSql(小汽车摇号分析)
数据源与数据格式
从 Driver 创建 DataFrame
createDataFrame 方法
toDF 方法
从文件系统创建 DataFrame
从 CSV 创建 DataFrame
从 Parquet / ORC 创建 DataFrame
从 RDBMS 创建 DataFrame
数据转换
SQL 语句
DataFrame 算子
同源类算子
探索类算子
清洗类算子
转换类算子
分析类算子
Broadcast Join
持久化类算子
Structured Streaming
Window 操作
SparkCore(单词计数)
要先对文件中的单词做统计计数,然后再打印出频次最高的 5 个单词,江湖人称“Word Count”wikiOfSpark.txt 文件下载地址:这里
import org.apache.spark.rdd.RDD
// 这里的下划线"_"是占位符,代表数据文件的根目录
val rootPath: String = "/Users/mustafa/Documents/databases/bigdata/spark/spark_core"
val file: String = s"${rootPath}/wikiOfSpark.txt"
// 读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
// 以行为单位做分词
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))
// 把RDD元素转换为(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
// 打印词频最高的5个词汇
wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5)
创建 RDD
SparkContext.parallelize
用 parallelize 函数来封装内部数据
import org.apache.spark.rdd.RDD
val words: Array[String] = Array("Spark", "is", "cool")
val rdd: RDD[String] = sc.parallelize(words)
SparkContext.textFile
RDD 内的数据转换
map:以元素为粒度的数据转换
把 Word Count 的计数需求,从原来的对单词计数,改为对单词的哈希值计数
// 把普通RDD转换为Paired RDD
import java.security.MessageDigest
val cleanWordRDD: RDD[String] = _ // 请参考第一讲获取完整代码
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map{ word =>
// 获取MD5对象实例
val md5 = MessageDigest.getInstance("MD5")
// 使用MD5计算哈希值
val hash = md5.digest(word.getBytes).mkString
// 返回哈希值与数字1的Pair
(hash, 1)
}
mapPartitions:以数据分区为粒度的数据转换
// 把普通RDD转换为Paired RDD
import java.security.MessageDigest
val cleanWordRDD: RDD[String] = _ // 请参考第一讲获取完整代码
val kvRDD: RDD[(String, Int)] = cleanWordRDD.mapPartitions( partition => {
// 注意!这里是以数据分区为粒度,获取MD5对象实例
val md5 = MessageDigest.getInstance("MD5")
val newPartition = partition.map( word => {
// 在处理每一条数据记录的时候,可以复用同一个Partition内的MD5对象
(md5.digest(word.getBytes()).mkString,1)
})
newPartition
})
把实例化 MD5 对象的语句挪到了 map 算子之外。如此一来,以数据分区为单位,实例化对象的操作只需要执行一次,而同一个数据分区中所有的数据记录,都可以共享该 MD5 对象,从而完成单词到哈希值的转换。
flatMap:从元素到集合、再从集合到元素
由原来统计单词的计数,改为统计相邻单词共现的次数
// 读取文件内容
val lineRDD: RDD[String] = _ // 请参考第一讲获取完整代码
// 以行为单位提取相邻单词
val wordPairRDD: RDD[String] = lineRDD.flatMap( line => {
// 将行转换为单词数组
val words: Array[String] = line.split(" ")
// 将单个单词数组,转换为相邻单词数组
for (i (word, word))
// 按照单词做分组收集
val words: RDD[(String, Iterable[String])] = kvRDD.groupByKey()
reduceByKey:分组聚合
把 Word Count 的计算逻辑,改为随机赋值、提取同一个 Key 的最大值
import scala.util.Random._
// 把RDD元素转换为(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, nextInt(100)))
// 显示定义提取最大值的聚合函数f
def f(x: Int, y: Int): Int = {
return math.max(x, y)
}
// 按照单词提取最大值
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey(f)
aggregateByKey:更加灵活的聚合算子
想对单词计数的计算逻辑做如下调整:
- 在 Map 阶段,以数据分区为单位,计算单词的加和;
- 而在 Reduce 阶段,对于同样的单词,取加和最大的那个数值。
// 把RDD元素转换为(Key,Value)的形式 val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1)) // 显示定义Map阶段聚合函数f1 def f1(x: Int, y: Int): Int = { return x + y } // 显示定义Reduce阶段聚合函数f2 def f2(x: Int, y: Int): Int = { return math.max(x, y) } // 调用aggregateByKey,实现先加和、再求最大值 val wordCounts: RDD[(String, Int)] = kvRDD.aggregateByKey(0) (f1, f2)sortByKey:排序
rdd.sortByKey(false)
内存管理
RDD Cache
wordCounts.cache // 使用cache算子告知Spark对wordCounts加缓存 wordCounts.count // 触发wordCounts的计算,并将wordCounts缓存到内存
在最后追加了 saveAsTextFile 落盘操作,这样一来,wordCounts 这个 RDD 在程序中被引用了两次,take 和 saveAsTextFile 这两个操作执行得都很慢,可以考虑通过给 wordCounts 加 Cache 来提升效率。
import org.apache.spark.rdd.RDD val rootPath: String = "/Users/mustafa/Documents/databases/bigdata/spark/spark_core" val file: String = s"${rootPath}/wikiOfSpark.txt" // 读取文件内容 val readLineRDD: RDD[String] = spark.sparkContext.textFile(file) val lineRDD: RDD[String] = readLineRDD.repartition(10) // 以行为单位做分词 val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" ")) val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals("")) // 把RDD元素转换为(Key,Value)的形式 val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1)) // 按照单词做分组计数 val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y) wordCounts.cache// 使用cache算子告知Spark对wordCounts加缓存 wordCounts.count// 触发wordCounts的计算,并将wordCounts缓存到内存 // 打印词频最高的5个词汇 wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5) // 将分组计数结果落盘到文件 val targetPath: String = "/Users/mustafa/Documents/databases/bigdata/spark/out" wordCounts.saveAsTextFile(targetPath)数据准备
union
把两个类型一致、但来源不同的 RDD 进行合并,从而构成一个统一的、更大的分布式数据集。
// T:数据类型 val rdd1: RDD[T] = _ val rdd2: RDD[T] = _ val rdd3: RDD[T] = _ val rdd = (rdd1.union(rdd2)).union(rdd3) // 或者 val rdd = rdd1 union rdd2 union rdd3
sample
RDD 的 sample 算子用于对 RDD 做随机采样,从而把一个较大的数据集变为一份“小数据”。相较其他算子,sample 的参数比较多,分别是 withReplacement、fraction 和 seed。因此,要在 RDD 之上完成数据采样,你需要使用如下的方式来调用 sample 算子:sample(withReplacement, fraction, seed)。
其中,withReplacement 的类型是 Boolean,它的含义是“采样是否有放回”,如果这个参数的值是 true,那么采样结果中可能会包含重复的数据记录,相反,如果该值为 false,那么采样结果不存在重复记录。
fraction 参数最好理解,它的类型是 Double,值域为 0 到 1,其含义是采样比例,也就是结果集与原数据集的尺寸比例。seed 参数是可选的,它的类型是 Long,也就是长整型,用于控制每次采样的结果是否一致。
// 生成0到99的整型数组 val arr = (0 until 100).toArray // 使用parallelize生成RDD val rdd = sc.parallelize(arr) // 不带seed,每次采样结果都不同 rdd.sample(false, 0.1).collect // 结果集:Array(11, 13, 14, 39, 43, 63, 73, 78, 83, 88, 89, 90) rdd.sample(false, 0.1).collect // 结果集:Array(6, 9, 10, 11, 17, 36, 44, 53, 73, 74, 79, 97, 99) // 带seed,每次采样结果都一样 rdd.sample(false, 0.1, 123).collect // 结果集:Array(3, 11, 26, 59, 82, 89, 96, 99) rdd.sample(false, 0.1, 123).collect // 结果集:Array(3, 11, 26, 59, 82, 89, 96, 99) // 有放回采样,采样结果可能包含重复值 rdd.sample(true, 0.1, 456).collect // 结果集:Array(7, 11, 11, 23, 26, 26, 33, 41, 57, 74, 96) rdd.sample(true, 0.1, 456).collect // 结果集:Array(7, 11, 11, 23, 26, 26, 33, 41, 57, 74, 96)
数据预处理
repartition
// 生成0到99的整型数组 val arr = (0 until 100).toArray // 使用parallelize生成RDD val rdd = sc.parallelize(arr) rdd.partitions.length // 4 val rdd1 = rdd.repartition(2) rdd1.partitions.length // 2 val rdd2 = rdd.repartition(8) rdd2.partitions.length // 8
coalesce
给定任意一条数据记录,repartition 的计算过程都是先哈希、再取模,得到的结果便是该条数据的目标分区索引。对于绝大多数的数据记录,目标分区往往坐落在另一个 Executor、甚至是另一个节点之上,因此 Shuffle 自然也就不可避免。
coalesce 则不然,在降低并行度的计算中,它采取的思路是把同一个 Executor 内的不同数据分区进行合并,如此一来,数据并不需要跨 Executors、跨节点进行分发,因而自然不会引入 Shuffle
// 生成0到99的整型数组 val arr = (0 until 100).toArray // 使用parallelize生成RDD val rdd = sc.parallelize(arr) rdd.partitions.length // 4 val rdd1 = rdd.repartition(2) rdd1.partitions.length // 2 val rdd2 = rdd.coalesce(2) rdd2.partitions.length // 2
结果收集
first、take 和 collect
rdd.take(5)
saveAsTextFile
val targetPath: String = "/Users/mustafa/Documents/databases/bigdata/spark/out" wordCounts.saveAsTextFile(targetPath)
广播变量&累加器
广播变量(Broadcast variables)
val list: List[String] = List("Apache", "Spark") // sc为SparkContext实例 val bc = sc.broadcast(list) // 读取广播变量内容 bc.value // List[String] = List(Apache, Spark)把 Word Count 变更为“定向计数”。所谓定向计数,它指的是只对某些单词进行计数,例如,给定单词列表 list,我们只对文件 wikiOfSpark.txt 当中的“Apache”和“Spark”这两个单词做计数,其他单词我们可以忽略。
import org.apache.spark.rdd.RDD val rootPath: String = "/Users/mustafa/Documents/databases/bigdata/spark/spark_core" val file: String = s"${rootPath}/wikiOfSpark.txt" // 读取文件内容 val lineRDD: RDD[String] = spark.sparkContext.textFile(file) // 以行为单位做分词 val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" ")) // 创建单词列表list val list: List[String] = List("Apache", "Spark") // 创建广播变量bc val bc = sc.broadcast(list) // 使用bc.value对RDD进行过滤 val cleanWordRDD: RDD[String] = wordRDD.filter(word => bc.value.contains(word)) // 把RDD元素转换为(Key,Value)的形式 val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1)) // 按照单词做分组计数 val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y) // 获取计算结果 wordCounts.collect // Array[(String, Int)] = Array((Apache,34), (Spark,63))累加器(Accumulators)
在过滤掉空字符的同时,还想知道文件中到底有多少个空字符串,这样我们对文件中的“脏数据”就能做到心中有数了
import org.apache.spark.rdd.RDD val rootPath: String = "/Users/mustafa/Documents/databases/bigdata/spark/spark_core" val file: String = s"${rootPath}/wikiOfSpark.txt" // 读取文件内容 val lineRDD: RDD[String] = spark.sparkContext.textFile(file) // 以行为单位做分词 val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" ")) // 定义Long类型的累加器 val ac = sc.longAccumulator("Empty string") // 定义filter算子的判定函数f,注意,f的返回类型必须是Boolean def f(x: String): Boolean = { if(x.equals("")) { // 当遇到空字符串时,累加器加1 ac.add(1) return false } else { return true } } // 使用f对RDD进行过滤 val cleanWordRDD: RDD[String] = wordRDD.filter(f) // 把RDD元素转换为(Key,Value)的形式 val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1)) // 按照单词做分组计数 val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y) // 收集计数结果 wordCounts.collect // 作业执行完毕,通过调用value获取累加器结果 ac.value // Long = 79SparkSql(小汽车摇号分析)
零基础入门 Spark 包含 sparkCore,sparkSql,sparkStreaming 全套零基础入门到精通教程。
为了限制机动车保有量,从 2011 年开始,北京市政府推出了小汽车摇号政策。随着摇号进程的推进,在 2016 年,为了照顾那些长时间没有摇中号码牌的“准司机”,摇号政策又推出了“倍率”制度。
所谓倍率制度,它指的是,结合参与摇号次数,为每个人赋予不同的倍率系数。有了倍率加持,大家的中签率就由原来整齐划一的基础概率,变为“基础概率 * 倍率系数”。参与摇号的次数越多,倍率系数越大,中签率也会相应得到提高。
不过,身边无数的“准司机”总是跟我说,其实倍率这玩意没什么用,背了 8 倍、10 倍的倍率,照样摇不上!那么今天这一讲,咱们就来借着学习 Spark SQL 的机会,用数据来为这些还没摸过车的“老司机”答疑解惑,帮他们定量地分析一下,倍率与中签率之间,到底有没有关系?
2011 年到 2019 年北京市小汽车的摇号数据,你可以通过这个地址,从网盘进行下载,提取码为 ajs6
//spark-shell --conf spark.executor.memory=4g --conf spark.driver.memory=4g import org.apache.spark.sql.DataFrame val rootPath: String = "/Users/mustafa/Documents/databases/bigdata/spark/spark_sql" // 申请者数据 val hdfs_path_apply: String = s"${rootPath}/apply" // spark是spark-shell中默认的SparkSession实例 // 通过read API读取源文件 val applyNumbersDF: DataFrame = spark.read.parquet(hdfs_path_apply) // 数据打印 applyNumbersDF.show // 中签者数据 val hdfs_path_lucky: String = s"${rootPath}/lucky" // 通过read API读取源文件 val luckyDogsDF: DataFrame = spark.read.parquet(hdfs_path_lucky) // 数据打印 luckyDogsDF.show // 过滤2016年以后的中签数据,且仅抽取中签号码carNum字段 val filteredLuckyDogs: DataFrame = luckyDogsDF.filter(col("batchNum") >= "201601").select("carNum") // 摇号数据与中签数据做内关联,Join Key为中签号码carNum val jointDF: DataFrame = applyNumbersDF.join(filteredLuckyDogs, Seq("carNum"), "inner") // 以batchNum、carNum做分组,统计倍率系数 val multipliers: DataFrame = jointDF.groupBy(col("batchNum"),col("carNum")).agg(count(lit(1)).alias("multiplier")) // 以carNum做分组,保留最大的倍率系数 val uniqueMultipliers: DataFrame = multipliers.groupBy("carNum").agg(max("multiplier").alias("multiplier")) // 以multiplier倍率做分组,统计人数 val result: DataFrame = uniqueMultipliers.groupBy("multiplier").agg(count(lit(1)).alias("cnt")).orderBy("multiplier") result.collect数据源与数据格式
从 Driver 创建 DataFrame
createDataFrame 方法
import org.apache.spark.rdd.RDD val seq: Seq[(String, Int)] = Seq(("Bob", 14), ("Alice", 18)) val rdd: RDD[(String, Int)] = sc.parallelize(seq) import org.apache.spark.sql.types.{StringType, IntegerType, StructField, StructType} val schema:StructType = StructType( Array( StructField("name", StringType), StructField("age", IntegerType) )) import org.apache.spark.sql.Row val rowRDD: RDD[Row] = rdd.map(fileds => Row(fileds._1, fileds._2)) import org.apache.spark.sql.DataFrame val dataFrame: DataFrame = spark.createDataFrame(rowRDD,schema)toDF 方法
import org.apache.spark.rdd.RDD val seq: Seq[(String, Int)] = Seq(("Bob", 14), ("Alice", 18)) import spark.implicits._ val dataFrame: DataFrame = seq.toDF("name", "age")从文件系统创建 DataFrame
从 CSV 创建 DataFrame
import org.apache.spark.sql.DataFrame val csvFilePath: String = "/Users/mustafa/Documents/databases/bigdata/spark/spark_sql/users.csv" import org.apache.spark.sql.types.{StringType, IntegerType, StructField, StructType} val schema:StructType = StructType( Array( StructField("name", StringType), StructField("age", IntegerType) )) val df: DataFrame = spark.read.format("csv").schema(schema).option("header", true).option("mode", "dropMalformed").load(csvFilePath) df.show从 Parquet / ORC 创建 DataFrame
val parquetFilePath: String = "/Users/mustafa/Documents/databases/bigdata/spark/spark_sql/apply/batchNum=201101/part-00000-f8bb8e7b-904f-42a7-a616-a413406f06fb.c000.snappy.parquet" val df: DataFrame = spark.read.format("parquet").load(parquetFilePath)从 RDBMS 创建 DataFrame
//spark-shell --driver-class-path /Users/mustafa/Documents/databases/maven/mysql/mysql-connector-java/8.0.26/mysql-connector-java-8.0.26.jar --jars /Users/mustafa/Documents/databases/maven/mysql/mysql-connector-java/8.0.26/mysql-connector-java-8.0.26.jar import org.apache.spark.sql.DataFrame val df: DataFrame = spark.read.format("jdbc") .option("driver", "com.mysql.cj.jdbc.Driver") .option("url", "jdbc:mysql://myserver:3306/test1") .option("user", "root") .option("password","123456") .option("numPartitions", 10) .option("dbtable", "t2") .load()需要额外注意的是,在默认情况下,Spark 安装目录并没有提供与数据库连接有关的任何 Jar 包,因此,对于想要访问的数据库,不论是 MySQL、PostgreSQL,还是 Oracle、DB2,我们都需要把相关 Jar 包手工拷贝到 Spark 安装目录下的 Jars 文件夹。与此同时,我们还要在 spark-shell 命令或是 spark-submit 中,通过如下两个命令行参数,来告诉 Spark 相关 Jar 包的访问地址。
- –driver-class-path mysql-connector-java-version.jar
- –jars mysql-connector-java-version.jar
数据转换
SQL 语句
对于任意的 DataFrame,我们都可以使用 createTempView 或是 createGlobalTempView 在 Spark SQL 中创建临时数据表。
两者的区别在于,createTempView 创建的临时表,其生命周期仅限于 SparkSession 内部,而 createGlobalTempView 创建的临时表,可以在同一个应用程序中跨 SparkSession 提供访问。有了临时表之后,我们就可以使用 SQL 语句灵活地倒腾表数据
import org.apache.spark.sql.DataFrame import spark.implicits._ val seq = Seq(("Alice", 18), ("Bob", 14)) val df = seq.toDF("name", "age") df.createTempView("t1") val query: String = "select * from t1" // spark为SparkSession实例对象 val result: DataFrame = spark.sql(query) result.showDataFrame 算子
同源类算子

探索类算子

清洗类算子

import org.apache.spark.sql.DataFrame import spark.implicits._ val employees = Seq((1, "John", 26, "Male"), (2, "Lily", 28, "Female"), (3, "Raymond", 30, "Male")) val employeesDF: DataFrame = employees.toDF("id", "name", "age", "gender") employeesDF.printSchema employeesDF.dropDuplicates("gender").show转换类算子
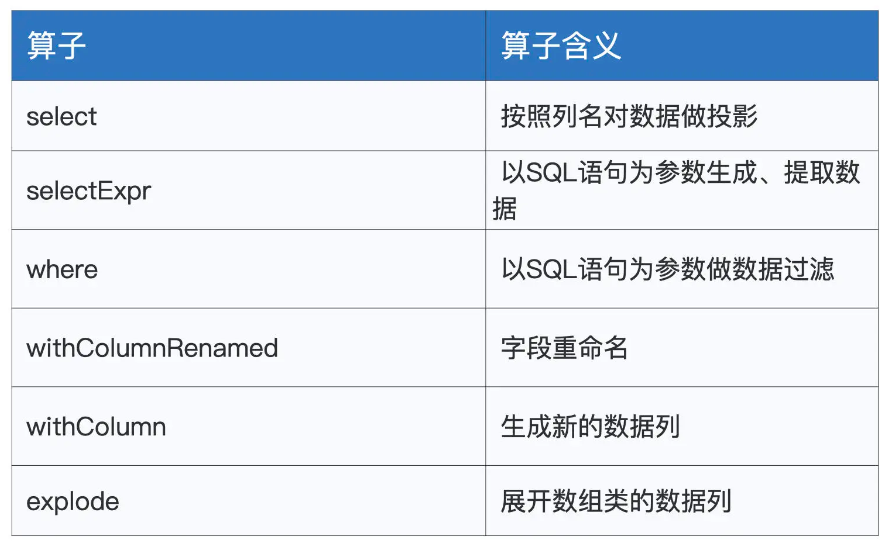
employeesDF.select("name", "gender").show employeesDF.selectExpr("id", "name", "concat(id, '_', name) as id_name").show employeesDF.where(“gender = ‘Male’”).show employeesDF.withColumnRenamed(“gender”, “sex”).show employeesDF.withColumn("crypto", hash($"age")).showval seq = Seq( (1, "John", 26, "Male", Seq("Sports", "News")), (2, "Lily", 28, "Female", Seq("Shopping", "Reading")), (3, "Raymond", 30, "Male", Seq("Sports", "Reading")) ) val employeesDF: DataFrame = seq.toDF("id", "name", "age", "gender", "interests") employeesDF.show employeesDF.withColumn("interest", explode($"interests")).show分析类算子

Broadcast Join
import spark.implicits._ import org.apache.spark.sql.DataFrame // 创建员工信息表 val seq = Seq((1, "Mike", 28, "Male"), (2, "Lily", 30, "Female"), (3, "Raymond", 26, "Male")) val employees: DataFrame = seq.toDF("id", "name", "age", "gender") // 创建薪水表 val seq2 = Seq((1, 26000), (2, 30000), (4, 25000), (3, 20000)) val salaries:DataFrame = seq2.toDF("id", "salary") import org.apache.spark.sql.functions.broadcast // 创建员工表的广播变量 val bcEmployees = broadcast(employees) // 内关联,PS:将原来的employees替换为bcEmployees val jointDF: DataFrame = salaries.join(bcEmployees, salaries("id") === employees("id"), "inner")val fullInfo: DataFrame = salaries.join(employees, Seq("id"), "inner") val aggResult = fullInfo.groupBy("gender").agg(sum("salary").as("sum_salary"), avg("salary").as("avg_salary")) aggResult.sort(desc("sum_salary"), asc("gender")).show持久化类算子
aggResult.write.format("csv").option("header", true).mode("overwrite").save("/Users/mustafa/Documents/databases/bigdata/spark/spark_sql/salary_analyze_csv") aggResult.write.format("parquet").mode("overwrite").save("/Users/mustafa/Documents/databases/bigdata/spark/spark_sql/salary_analyze_parquet")Structured Streaming
零基础入门 Spark 包含 sparkCore,sparkSql,sparkStreaming 全套零基础入门到精通教程。
在之前的 Word Count 中,数据以文件(wikiOfSpark.txt)的形式,一次性地“喂给”Spark,从而触发一次 Job 计算。而在“流动的 Word Count”里,数据以行为粒度,分批地“喂给”Spark,每一行数据,都会触发一次 Job 计算。
具体来说,使用 netcat 工具,向本地 9999 端口的 Socket 地址发送数据行。而 Spark 流处理应用,则时刻监听着本机的 9999 端口,一旦接收到数据条目,就会立即触发计算逻辑的执行。这里的计算逻辑,就是 Word Count。计算执行完毕之后,流处理应用再把结果打印到终端(Console)上。
打开一个终端,在 9999 端口喂数据。linux nc -lk 9999 ,mac nc -l -p 9999
import org.apache.spark.sql.DataFrame // 设置需要监听的本机地址与端口号 val host: String = "127.0.0.1" val port: String = "9999" // 从监听地址创建DataFrame var df: DataFrame = spark.readStream .format("socket") .option("host", host) .option("port", port) .load() // 首先把接收到的字符串,以空格为分隔符做拆分,得到单词数组words df = df.withColumn("words", split($"value", " ")) // 把数组words展平为单词word .withColumn("word", explode($"words")) // 以单词word为Key做分组 .groupBy("word") // 分组计数 .count() df.writeStream // 指定Sink为终端(Console) .format("console") // 指定输出选项 .option("truncate", false) // 指定输出模式 .outputMode("complete") //.outputMode("update") // 启动流处理应用 .start() // 等待中断指令 .awaitTermination()Window 操作
df = df.withColumn("inputs", split($"value", ",")) // 提取事件时间 .withColumn("eventTime", element_at(col("inputs"),1).cast("timestamp")) // 提取单词序列 .withColumn("words", split(element_at(col("inputs"),2), " ")) // 拆分单词 .withColumn("word", explode($"words")) // 按照Tumbling Window与单词做分组 .groupBy(window(col("eventTime"), "5 minute"), col("word")) // 统计计数 .count()



