
Hadoop生态简介,Hive、Spark、HBase等



目录
- 1. Hadoop
- 1.1 Hadoop简介
- 1.2 大数据产生的时代背景
- 1.3 Hadoop产生的背景
- 1.4 Hadoop的核心组件
- 1.5 Hadoop存在的问题
- 2. Spark
- 2.1 简介
- 2.2 Spark解决了什么问题
- 2.3 Spark在Hadoop生态中的作用
- 2.4 Spark的缺点
- 3. Hive
- 2.1 简介
- 2.2 Hive的优点
- 2.3 Hive在Hadoop生态中的作用
- 2.4 Hive的缺点
- 2.5 Hive和SparkSQL对比
- 2.6 Hive和Spark该如何选择
- 2.7 Pig
- 3. HBase
- 3.1 简介
- 3.2 HBase的适用场景
- 3.3 HBase的缺点
- 3.4 HBase的SQL方案
- 3.4.1 Phoenix
- 3.4.2 HBaseStorageHandler
- 3.5 在生产环境中使用HBase
- 4. Zookeeper
- 4.1 简介
- 4.2 Zookeeper在Hadoop生态中的作用
- 4.3 Zookeeper在各个组件中的作用
- 4.3 Zookeeper的缺点
- 5. Kafka
- 5.1 简介
- 5.2 Kafka的作用
- 6. Elasticsearch
- 6.1 简介
- 6.2 Elasticsearch的作用
- 7. Ooize
- 8. Sqoop && Flume
- 9. 结语
1. Hadoop
1.1 Hadoop简介
Hadoop现在已经是大数据领域事实上的标准,基本提到大数据,大家首先想到的就是Hadoop。
在本文中,笔者会结合自己的实际使用经验,力求以简单易懂的语言讲清楚Hadoop及其衍生生态下各个组件产生的背景,以及它们之间的关系,除了简述它们的作用之外,还会介绍它们各自的缺点,这个世上没有万金油,每项技术都有它适用的场景,也有它们的局限性。
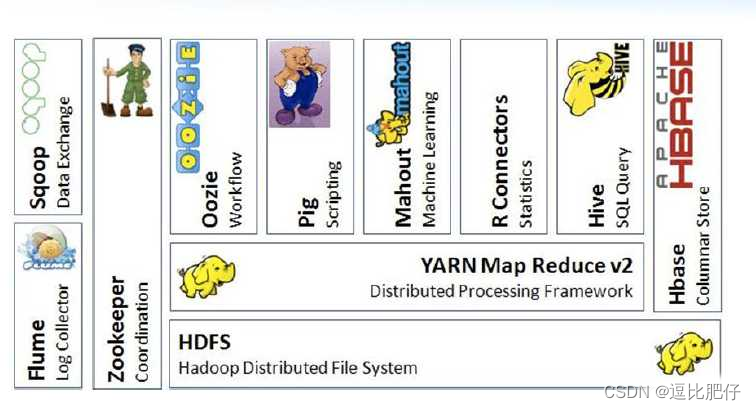
1.2 大数据产生的时代背景
在21世纪初互联网技术井喷式发展,人类进入互联网时代,各类电商网站、博客、微博、新闻门户层出不穷,大家似乎无时无刻都在产生数据,数据开始野蛮增长,随之而来就是如此体量的数据如何存储和计算的问题,这也是大数据技术诞生的背景。
其实以Hadoop为代表的大数据技术主要解决了以下2个问题:
- 海量数据存储的问题,在Hadoop出现之前,各业务系统将业务数据单独存储,存储不下就分库分表,各种数据库中间件、插件大行其道,系统架构复杂且费用昂贵,很容易出现数据孤岛,无法发挥数据真正的价值,Hadoop的出现让海量数据存储成为了可能。
- 海量数据计算的问题,海量的存储就需要海量的计算,Hadoop的MapReduce则为大数据处理提供了可能,MapReduce是一个分布式的并行处理框架,用户只需要实现简单map()和reduce()函数就可以完成海量数据的并行计算。
1.3 Hadoop产生的背景
Hadoop诞生于Nutch项目,项目目标是构建一个大型的全网搜索引擎,随着抓取的数据量越来越多,Nutch项目遇到了严重的可扩展性问题,几乎与此同时,Google发表了著名的3篇论文,为Nutch提供了解决思路。
Google的3篇论文发表于2003 ~ 2006年间,内容分别对应GoogleFileSystem、MapReduce和BigTable,前2项分别对应Hadoop中的HDFS和MapReduce,在最初的Hadoop设计中并没有BigTable的实现(这篇论文发布较晚),BigTable后面由HBase实现,并捐献给了Apache社区。
1.4 Hadoop的核心组件
- HDFS:分布式文件系统,以文件形式将数据分布式存储在不同服务器上,HDFS集群具有良好的扩展性,适合存储超大规模数据集,适合一次写入多次读取的场景。
- MapReduce:分布式并行计算框架,主要用于处理存储在HDFS上的大规模数据集,也可以处理数据库和本地文件系统中的数据,MapReduce主要用于开发计算任务。
- YARN:分布式资源管理和调度框架,Hadoop2.X引入的新组件,主要用于集群资源统一管理(内存、CPU、网络、磁盘等)和计算任务的调度运行,YARN不仅可以运行MapReduce任务,还可以运行Spark、Tez等任务。
1.5 Hadoop存在的问题
其实Hadoop核心的3个组件中,HDFS和YARN仍在大规模使用,存在问题较大还是MapReduce:
- 开发难度大,MapReduce开发需要掌握Java语言,对DBA或运维人员不友好,简单map()和reduce()虽然简化了处理流程,但也降低了任务开发的灵活性,任务编排组织使得代码非常臃肿,使用MapReduce只能实现简单逻辑,复杂任务使用MapReduce开发简直就是灾难。
- 执行效率低下,MapReduce执行过程中需要频繁IO和落盘,任何任务执行都必须经过Map=>Shuffle=>Reduce这3个基本流程,在这个过程中会经过多次的磁盘读写,导致效率难以提升。
- 算子能力太弱,MapReduce()只提供了map()和reduce()两个最基本的接口,其它任何操作都需要开发人员基于这2个固定流程开发,哪怕是一个简单的left join都需要写一堆代码实现。
2. Spark
2.1 简介
正是由于MapReduce存在种种问题,所以才出现了Spark,Spark是一款用于处理大规模数据集的通用计算引擎,我们通常用它来替代Hadoop中MapReduce,Spark专注于的领域是计算,通用计算引擎的含义是它不依赖任何存储,既可以对HDFS上数据进行计算,也可以对关系型数据库、Kafka、S3中的数据进行运算。

2.2 Spark解决了什么问题
相比于MapReduce,我觉得Spark主要有如下优点:
- 内存计算:Spark没有像MapReduce那样频繁读写磁盘,而是优先使用内存,节省了数据从内存到磁盘,然后再从磁盘到内存的资源消耗。
- 计算路径的优化:Spark使用DAG(有向无环图)来规划任务执行路径,它会将DAG划分为多个Stage,每个Stage都可以并发执行,相比于MapReduce,Spark设计更加精密,它会选择最佳路径执行计算任务。
- 丰富的算子:不同于MapReduce简单的map()和reduce()操作,Spark提供了海量的內置算子,例如leftJoin()、group()等,几乎涵盖了传统数据库支持的全部计算操作。
- 开发较为简单:Spark提供了SQL、Scala、Java、Python等多种接口,满足不同背景的开发人员使用。
- 丰富的数据源:Spark内置很多现成的数据读写能力,例如常用的jdbc、orc、parquet、csv、hbase等。
2.3 Spark在Hadoop生态中的作用
Spark通常用于替代MapReduce,作为集群的计算引擎存在。
2.4 Spark的缺点
虽然Spark已经非常强大了,基本可以满足大数据场景下的计算需求,但是它还是有很多不足的地方:
- Spark擅长的领域是批处理,尽管Spark Streaming可以进行流计算,但相比于Flink,Spark Streaming的吞吐量稍显不足,延迟性也比Flink高,Spark追求的是流批一体,Flink只专注于流处理。
- Spark虽然执行效率高,但占用大量内存容易导致程序不稳定,在稳定性和并发性方面确实不如MapReduce,特别是数据仓库数万任务运行的场景,这种问题就会被放大,这也是很多数仓仍使用hive-on-mapreduce的原因。
- Spark通常运行在YARN上用于计算HDFS上的数据,这导致Spark的优化还是围绕Hadoop模型展开,其计算效率相比于ClickHouse、Doris等OLAP新势力还是有所差距。
3. Hive
2.1 简介
前面已经提到MapReduce有开发难度较大,复杂任务编排困难的问题,Hive就是为了解决这些问题而诞生的。
Hive是一款数据仓库管理工具,也可以把它当成一种数据统计工具,Hive以数据库形式管理HDFS上的目录和文件,Hive可以将结构化数据映射成数据表,并使用类似SQL的脚本语言(HiveQL)操作数据,Hive会将这些SQL翻译为一连串的MapReduce任务运行。
虽然Hive跟传统数据库很像,但它确实不是数据库,它仅仅是一个工具,如果以MySQL的4层架构(连接层/服务层/引擎层/存储层)作为对比,那么Hive也仅仅是实现到了服务层,Hive本身不具备任何计算能力和存储能力,Hive依赖MapReduce或Spark作为其计算引擎,而Hive处理的巨大部分数据都是HDFS上的文件。

2.2 Hive的优点
- 操作简单:以SQL方式操作数据,并且提供JDBC驱动,大大降低了大数据的使用门槛,不论是开发人员还是DBA都能快速上手。
- 任务优化:Hive会将SQL翻译为一连串的MapReduce任务,优化器会自动选择最佳的执行路径查询数据。
- 多执行引擎:Hive不仅支持MapReduce引擎,还支持使用Spark和Tez作为其计算引擎。
2.3 Hive在Hadoop生态中的作用
在Hadoop生态中,Hive通常作为SQL执行引擎存在,后续出现的SparkSQL也兼容Hive语法规范。
Hive常用于构建数据仓库,所以Hive也可以作为集群数据文件的管理工具。
2.4 Hive的缺点
- 执行效率低,虽然Hive已支持Spark引擎,但目前仍有很多Hive任务运行在MapReduce上,MapReduce的执行效率会影响SQL的执行。
- SQL的好处是使用简单,但是表达能力较弱,复杂分析任务需要嵌套多层子查询,可读性就会变得非常差,复杂的嵌套查询也给调优带来了一定挑战。
- 调优复杂,Hive不像传统数据库那样经过简单调优便可稳定运行,Hive调优涉及方面较多,参数冗杂,调优需要一定的使用经验。
2.5 Hive和SparkSQL对比
- SparkSQL的执行效率要优于Hive,虽然Hive支持Spark作为计算引擎,但hive-on-spark底层使用的是RDD API,而不是DataFrame API,SparkSQL使用的最新的DataFrame API,天然使用Spark作为计算引擎,执行效率比Hive要高一些。
- Hive的稳定性要优于SparkSQL,由于Spark优先使用内存计算,占用资源相对较多,相较于Hive稳定性会差一些。
- Hive的并发性要优于SparkSQL,Spark相较于Hive占用的内存资源较多,在集群资源一定的情况下,能同时运行的任务数就会减少。
2.6 Hive和Spark该如何选择
其实在实际生产过程中,Hive和Spark使用都比较多,它们各自有自己适用的场景。
- 如果需要构建复杂的分析或处理任务,Spark更为合适,Hive SQL嵌套多层之后可读性会变差,并且会给调优带来一定的挑战。
- 在数据仓库或业务系统中的查询任务,Hive更为合适,因为业务查询需要稳定执行,并且需要更高的并发性能,前文也提到了,Hive在稳定性和并代性方面要优于Spark。
- 普通分析查询任务,建议使用Spark,因为它确实比Hive要快很多。
2.7 Pig
前文提到MapReduce存在种种问题,其实早在Hive出现之前,Pig就尝试解决这些问题,Pig采用一种类似SQL的PigLatin语言来编排MapReduce任务,相比于直接编写MapReduce任务,Pig已经可以节省很多人力。
但是Apache Pig却没有大规模使用起来,主要是后来者Hive和Spark比它更为优秀。PigLatin相较于SQL还是具有一定的学习成本,HiveQL接近于MySQL方言,只要会使用SQL的人员都可以快速上手。与Spark相比,Pig更加不具备任何优势,Spark书写更加简单,且代码可读性更强,不论是简单的查询还是复杂的分析任务,Spark都可以轻松搞定,在执行效率方面,Spark更是明显快于Pig。
无论从哪种方面来看,Apache Pig都像是上个时代的产物,该项目已经很久没有更新了。

3. HBase
3.1 简介
HBase是Hadoop Database的缩写,意为Hadoop数据库,是Google经典3篇论文中BigTable的开源实现,它是一个功能完整的K-V数据库,主要用于存储海量的结构化和半结构化数据。
HBase将数据存储在HDFS上,HDFS保证了HBase数据的安全性和扩展性,理论上HDFS上能存多少数据,HBase就能存下多少数据,其实HBase的真正瓶颈在于RootRegion的大小(存储元数据信息的Region),只要元数据信息能存下,HBase中的数据量就可以无限增长。
在计算方面,HBase使用自己RegionServer实现计算,并不依赖其它组件。关于HBase的知识恐怕几篇文章都介绍不完,这里不再深入介绍,大家只需简单了解HBase是个什么即可,后续有时间单独开篇博客介绍。

3.2 HBase的适用场景
- 适合实时增删改查的场景,存在HDFS上的数据通常以批处理为主,如果想要插入的数据立马可以就能读取到,那么HBase就比较合适。HDFS上的数据通常是一次写入多次读取,更新和删除操作困难,如果业务系统中需要对数据进行更新或删除,那么可以考虑使用HBase做实时查询系统。
- 适合简单查询的场景,其实理论上HBase的索引只有1个就是row_key,如果想要在HBase中快速检索数据,就需要将相关数据设计到row_key中,但这种row_key长度毕竟有限,如果想要实现更为复杂的检索,就必须依赖Elasticsearch等第三方检索工具。
- 也可以作为数据仓库的底层存储,如果数仓中的数据存在删除或更新的需求,可以考虑使用HBase,但不建议完全使用HBase作为数据仓库,因为建设数仓的目的是为了分析统计,HBase不适合大规模统计分析,再者大规模扫表也会对HBase服务造成巨大压力,只建议将有删改需求的表数据存储在HBase中。
其实在笔者的工作过程中,HBase使用的频率远远不如Hive和Spark,只有少量需要实时检索的场景才会用到HBase。
3.3 HBase的缺点
- 检索困难:只有row_key检索较快,row_key之外的Scan较慢,HBase适合围绕row_key的简单检索,复杂查询的优化可能需要依赖Phoenix等第三方组件组件提供二级索引服务。
- 只支持单表操作:HBase无法实现多表操作,多表操作需要依赖Hive或Phoenix的第三方组件。
- 统计分析困难:HBase主要用于K-V检索,统计分析需要应用程序在内存中自己处理,或者使用Hive或Phoenix等第三方组件。
3.4 HBase的SQL方案
3.4.1 Phoenix
Phoenix是HBase的SQL引擎插件,使得用户可以以SQL方式操作HBase,Phoenix支持多表查询,并提供了多种二级索引方案。

Phoenix的优点:
- 提供标准SQL和完整的事务支持,并提供JDBC驱动供应用使用,Phoenix会将SQL转换成原生Scan,效率与原生API差距不大。
- 提供完整的二级索引方案,弥补了原生HBase只能根据row_key检索的缺点。
- 支持复杂查询和分析统计,支持例如join、group by等常用操作。
- Phoenix创建的表与原生HBase完全兼容,可以直接使用HBase API查询。
Phoenix的缺点:
- 数据精度的损失,HBase原来设计的列族/限定词/时间戳的三维结构被强制拉伸成一维列结构。
- 复杂查询和分析统计效果不是太理想,尽管Phoenix内部做了很多的优化,但是HBase本身就不是一款分析型数据库,不论怎么优化,其效果始终差强人意。
- Phoenix的索引方案会新建索引表或利用本地存储,会浪费很多存储空间,以空间换时间,索引那部分数据会存多份。
3.4.2 HBaseStorageHandler
HBaseStorageHandler是Hive提供的用于查询HBase的处理器,通过这个处理器,就可以在Hive中以SQL形式查询HBase表。
HBaseStorageHandler的优点:
- 可以直接使用标准Hive查询HBase数据库,并与Hive中其它表进行关联,而Phoenix则只能在HBase库内计算,我们在构建数仓时也会将部分表数据存储到HBase中。
HBaseStorageHandler的缺点:
- 底层使用MapReduce全表扫描,查询效率较低,即使添加了过滤条件,也会全表扫描,而Phoenix则会将SQL转换为原生Scan,将过滤条件转换为原生Filter。
3.5 在生产环境中使用HBase
如果是按照row_key检索更新的场景,通常会直接HBase API。
如果是统计分析的场景,更多的还是使用Spark和Hive查询HBase,简单查询会用Phoenix,如果需要频繁扫描HBase表,建议将数据导出至HDFS,减轻HBase服务压力。
如果是在数仓中使用,还是Hive查询HBase较多。
4. Zookeeper
4.1 简介
Zookeeper一款分布式的应用程序协调程序,解决数据一致性问题,它的作用主要有2个:
- 各节点之间的分布式协调,例如选举主备节点、管理各个节点之间的状态,可以简单将它理解为集群的管理者,从各个节点中选出一个老大,然后其它节点听从老大指挥,大家互通消息、行动一致。
- 存储重要数据,例如Kafka的副本信息、HBase的元数据信息都直接存储在Zookeeper中。

4.2 Zookeeper在Hadoop生态中的作用
Zookeeper在Hadoop中主要作为统一协调中心和统一配置中心存在,说它是整个集群的大管家也毫不为过。
4.3 Zookeeper在各个组件中的作用
- Hadoop利用Zookeeper实现高可用,但主节点挂掉之后,会切换到备节点。
- Hive利用Zookeeper实现高可用,当主节点挂掉之后,会切换到备节点。
- Kafka利用Zookeeper实现分布式协调,选举主从节点,每个Topic的副本信息等也会存储在Zookeepr中。
- HBase利用Zookeeper实现高可用,当HBase的一个Master挂掉之后,会立马切换到备用Master,HBase还会将一些比较重要的元数据信息存储到Zookeepr中。
- Elasticsearch利用Zookeepr实现分布式协调,它会将所有的节点信息都存储到Zookeepr中。
4.3 Zookeeper的缺点
Zookeeper采用选举机制选举Leader,其它节点作为Follower或Observer存在,当Leader挂掉之后,会重新选举Leader,但选举的过程需要时间,对于Hadoop这样的计算性集群而言可能不算什么,但对于电商系统这样高速运算的系统而言,集群停摆几秒就可能导致非常严重的后果,所以之前Dubbo这样的中间件使用Zookeepr作为注册中心就具有一定的风险,只要Leader停摆,集群就需要一直等,等待新的Leader上线。
5. Kafka
5.1 简介
Kafka是一款数据流平台,通过Kafka数据在各个组件之间流转,Kafka也可以作为消息中间件,用于各业务系统之间的解耦。

5.2 Kafka的作用
- 实时数据流处理,负责集群中的实时数据流转,关于实时流数据处理的经典组合是业务系统将数据发往Kafka,然后Flink从Kafka拉取实时数据处理。
- 流量削峰,有些业务流量不均,高峰时的流量是平时的数倍,这时就可以把数据发往Kafka,后续系统就可以在流量较低时慢慢处理Kafka中的数据。
- 系统解耦,Kafka也可以直接作为消息队列,用于各个业务系统之间解耦,但Kafka模型简单,如果业务复杂,需要更多功能,可以考虑RabbitMQ等专业MQ。
6. Elasticsearch
6.1 简介
Elasticsearch是一款基于Lucene的分布式检索引擎,可以完成复杂的实时检索,稳定可靠、可扩展。
6.2 Elasticsearch的作用
Elasticsearch的作用就是做大数据实时检索,通过Elasticsearch提供Restful API可以完成各种复杂的数据检索,甚至可以跨索引检索。
需要注意的是Elasticsearch专注的领域是数据检索,如果有统计分析的场景,还是建议使用Spark或Hive,而且Elasticsearch也不属于Hadoop生态,需要将数据导入到Elasticsearch中。
7. Ooize
基于Hadoop的分布式调度系统,可以将我们写的MapReduce或Spark打包上传,由Ooize负责定时执行。
在我们实际生产过程中,还是有很多需要定时执行的Spark任务的,这时Ooize就排上用场了。
8. Sqoop && Flume
为什么最后介绍这两个组件,是因为它们和Apache Pig一样,存在感确实很低。
Sqoop是一款将关系型数据库中的数据导入到Hadoop平台的ETL工具,但几乎没有哪家厂商愿意使用它,要么自己开发ETL工具,要么使用Kettle、DataX等开源的ETL工具。
Flume是一个高可用的、高可靠的分布式的海量日志采集、聚合和传输的系统。
9. 结语
这是最好的时代,也是最坏的时代。Hadoop从诞生至今已不知不觉走过了20多年的时间,英雄迟暮,志在千里!但时代总要继续向前发展,希望大家在拥抱Hadoop的同时,也积极去拥抱ClickHouse,拥抱Doris。






