
大数据实战——基于Hadoop的Mapreduce编程实践案例的设计与实现



🌟欢迎来到 我的博客 —— 探索技术的无限可能!
🌟博客的简介(文章目录)
基于Hadoop的Mapreduce编程实践案例的设计与实现
- 一、数据排序案例的设计与实现
- 1.1设计思路
- 1.2实践过程
- 1.3成果展示+数据可视化分析
- 二、求数据平均值案例的设计与实现
- 2.1设计思路
- 2.2实践过程
- 2.3编写java程序并运行文件
- 2.4成果展示+数据可视化分析
- 三、基于hadoop的PageRank算法实现
- 3.1设计思路
- 3.2实践过程
- 3.3成果展示
- 3.4 数据的可视化分析
一、数据排序案例的设计与实现
1.1设计思路
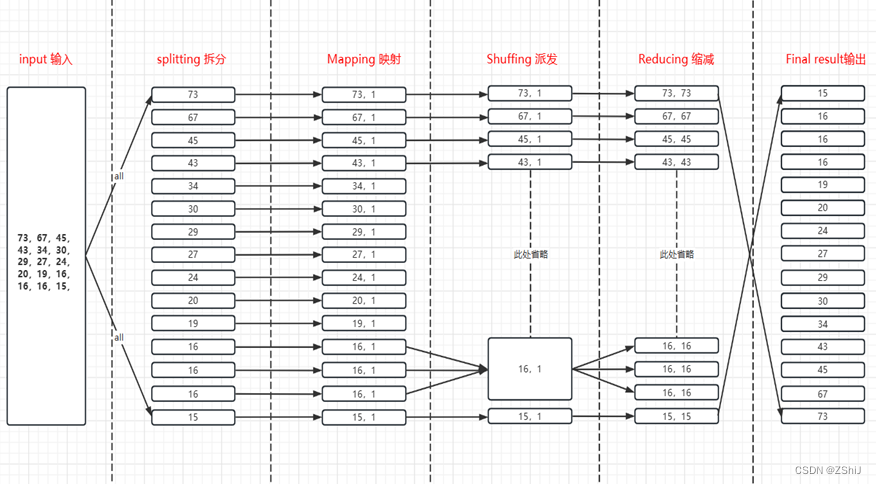
图1:MaxCompute MapReduce各个阶段思路设计
设计思路分析分为六个模块:input输入数据、splitting拆分、Mapping映射、Shuffing派发、Reducing缩减、Final result输出。
输入数据:直接读入文本不进行分片,数据项本身作为单个Map Worker的输入。
Map阶段:Map处理输入,每获取一个数字,将数字的Count设置为1,并将此对输出,此时以Word作为输出数据的Key。
Shuffle>合并排序:在Shuffle阶段前期,首先对每个Map Worker的输出,按照Key值(即Word值)进行排序。排序后进行Combiner操作,即将Key值(Word值)相同的Count累加,构成新的对。此过程被称为合并排序。
Shuffle>分配Reduce:在Shuffle阶段后期,数据被发送到Reduce端。Reduce Worker收到数据后依赖Key值再次对数据排序。此时进行数据项目复制,将key复制一份赋值给value,设计新的排序模式。
Reduce阶段:每个Reduce Worker对数据进行处理时,采用value的值作为新的排序规则(从小到大),每一个key值都会自动绑定一个全局的index,用于记录输出的排序序列号,得到输出结果。
输出结果:数据在hadoop服务器上展示。
1.2实践过程
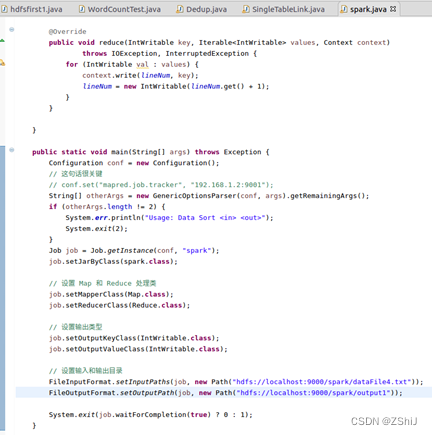
图2:代码设计
代码:
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class spark { public static class Map extends Mapper { private static IntWritable data = new IntWritable(); @Override public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); data.set(Integer.parseInt(line)); context.write(data, new IntWritable(1)); } } public static class Reduce extends Reducer { private static IntWritable lineNum = new IntWritable(1); @Override public void reduce(IntWritable key, Iterable values, Context context) throws IOException, InterruptedException { for (IntWritable val : values) { context.write(lineNum, key); lineNum = new IntWritable(lineNum.get() + 1);}}} public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); // 这句话很关键 // conf.set("mapred.job.tracker", "192.168.1.2:9001"); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: Data Sort "); System.exit(2); } Job job = Job.getInstance(conf, "spark"); job.setJarByClass(spark.class); // 设置 Map 和 Reduce 处理类 job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); // 设置输出类型 job.setOutputKeyClass(IntWritable.class); job.setOutputValueClass(IntWritable.class); // 设置输入和输出目录 FileInputFormat.setInputPaths(job, new Path("hdfs://localhost:9000/spark/dataFile6.txt")); FileOutputFormat.setOutputPath(job, new Path("hdfs://localhost:9000/spark/output1")); System.exit(job.waitForCompletion(true) ? 0 : 1); } }

图3:将项目打包方便后续在hadoop服务器上运行
图4:执行相关指令(文件上传分布式+运行jar包)
1.3成果展示+数据可视化分析
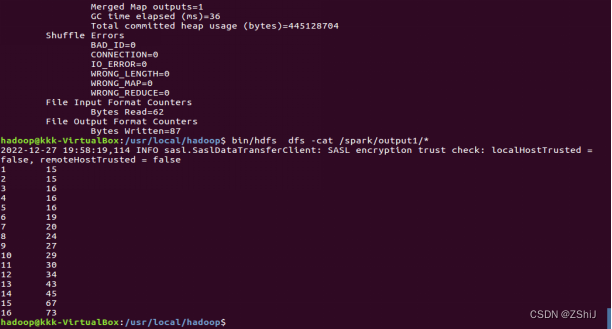
图5:排序输出各个国家世界杯累计胜场
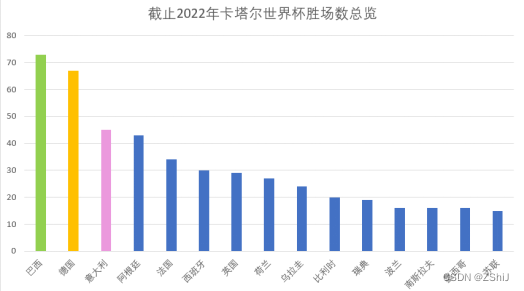
图6:2022卡塔尔世界杯累计胜场数目柱状图

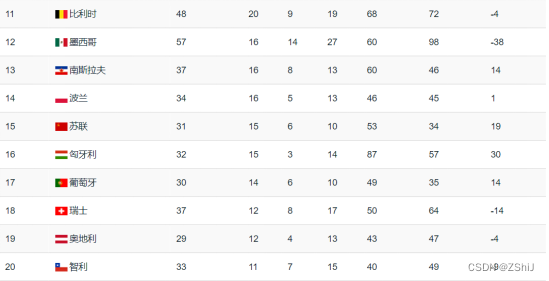
图7:2022卡塔尔世界杯累计胜场数-FIFA官方数据
分析:根据数据可视化的结果不难发现,巴西、德国、意大利、阿根廷四个国家的总胜场数超过其他国家,位列世界杯第一届至第二十二届胜场数top3,因此我们大胆预测在2026年举行的第二十三届世界杯上最有可能取得冠亚军的队伍就是巴西和德国队。按照截止到二十一届俄罗斯世界杯胜场数来看,阿根廷、德国、巴西三个国家最有可能登顶冠军,二十二届世界杯的冠军就是阿根廷,因此数据分析是有说服力的。同时我们仍然可以对输入的数据进行改造,譬如按照胜场数/比赛场数来计算胜率,并按照胜率的结果估算出最有可能成为冠亚军的队伍,将IntWritable类换成FloatWritable类作为输入数据的类型。
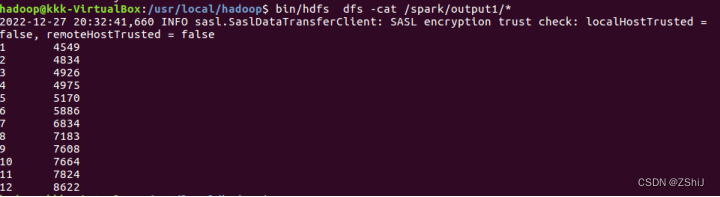
图8:排序爱奇艺舆情热度单日榜单数据
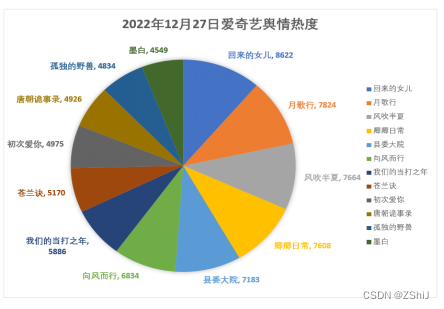
图9:排序爱奇艺舆情热度单日榜单数据扇形图(12月27日)
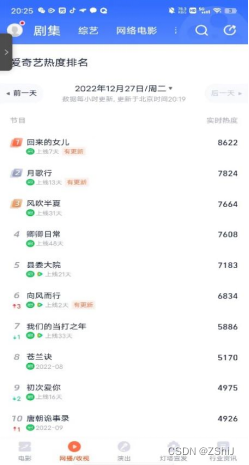

图10:爱奇艺舆情热度灯塔数据专业版
根据大数据可视化扇形图,在12月27日当天用户在爱奇艺平台讨论的热播剧中:回来的女儿、月歌行、风吹半夏三部剧位列前三,说明用户对于悬疑题材、仙侠题材、现实主义题材比较感兴趣,对于东北插班生、危险爱人这种现代偶像剧接受度不高,同时我们大胆的预测,在12月28日当天,回来的女儿仍然可以以大优势位居舆情榜单榜首,月歌行、风吹半夏、卿卿日常等剧集差距不大仍有赶超“上位”的可能。
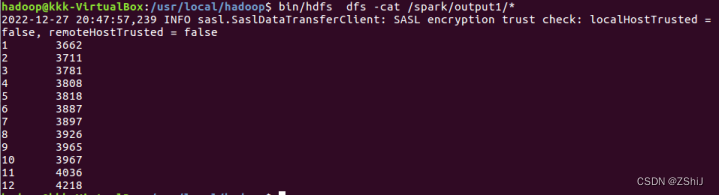
图11:NBA常规球赛胜场分数排序
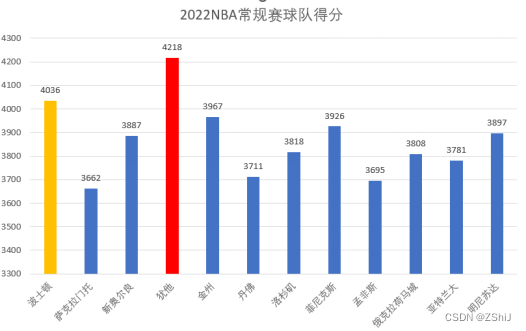
图12:NBA常规球赛胜场分数柱状图
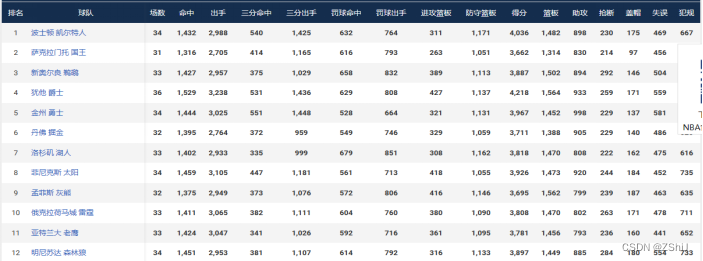
图13:NBA常规球赛胜场情况统计(数据来自体育赛事官网)
在2022年NBA常规赛事中,犹他爵士篮球队以大比分的优势取得年冠,评选年度MVP最佳篮球手的殊荣将以47.11%的概率入驻犹他爵士篮球队,其中波士顿 凯尔特人篮球队也有机会实现反超,于此同时国王球队评分垫底,可能无缘出圈12强赛事战队。
二、求数据平均值案例的设计与实现
2.1设计思路
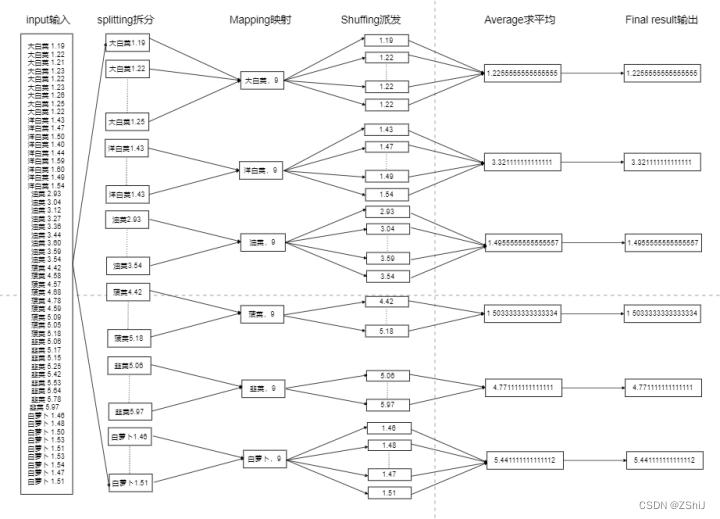
图14:Average the data MapReduce各个阶段思路设计
设计思路分析分为六个模块:input输入数据、splitting拆分、Mapping映射、Shuffing派发、Average求平均、Final result输出。
input输入数据:直接读入自定义文本数据,不进行分片,数据项本身作为单个Map Worker的输入。求数据平均值设计数据如下图所示:

图15:Average the data测试数据设计
Splitting拆分:即将input输入的数据进行一一拆分到每个运行处理模块中,让系统进行对数据的拆分与分解分析工作。
Map阶段:在MapReduce里排序默认是按照自然排序的,且只能对key进行排序,所以第一步需要包装一个实体类做key,所以在Map处理输入,每获取一个蔬菜,将不同蔬菜的一个月内价格变化数目number设置为n,并将此对输出,此时以number作为输出数据的Key,同时将自动或手动为index中的每月平均蔬菜价格数据变化建立的一种数据结构和相关配置。
Shuffle派发:在Shuffle阶段前期,首先对每个Map Worker的输出按照Key值(即Word值)进行相应派发与分配,将每一种蔬菜每天对应的价格派发后进行Combiner操作,即将Key值(Word值)Count累加,进行Average。
Final result输出结果:数据进行Average求平均成功后,会将结果在hadoop服务器上展示。
2.2实践过程

图16:打开hdfs
在终端输入./sbin/start-dfs.sh启动hdfs。
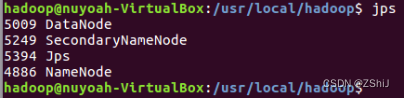
图17:确定Hadoop处于启动状态
通过输入jps确定Hadoop处于启动状态。
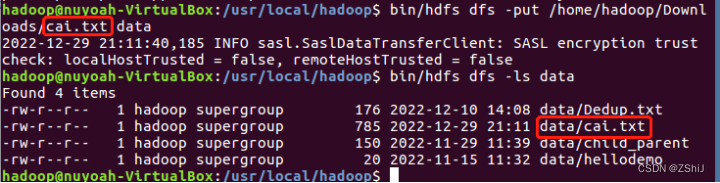
图18:上传到hdfs的data目录
在终端输入命令:bin/hdfs dfs -put /home/hadoop/Downloads/cai.txt data将cai.txt文件上传到hdfs的data目录下。
在终端输入命令:bin/hdfs dfs -ls data查看data目录下的内容,可以看到我们已经成功将cai.txt文件上传到hdfs的data目录下。
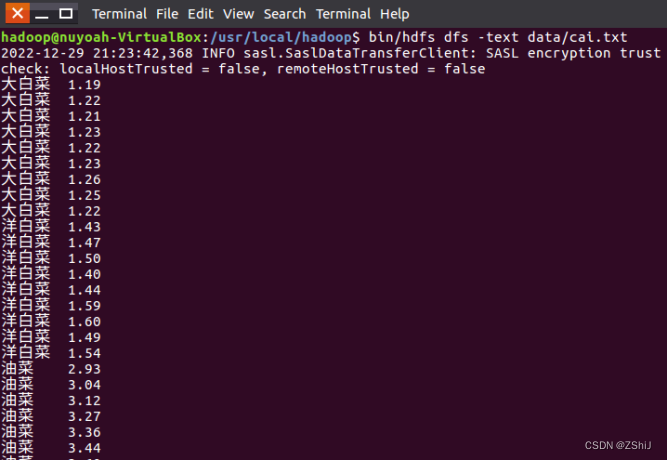
图19:查看cai.txt文件内容
在终端输入命令:bin/hdfs dfs -text data/cai.txt查看cai.txt文件内容。
2.3编写java程序并运行文件
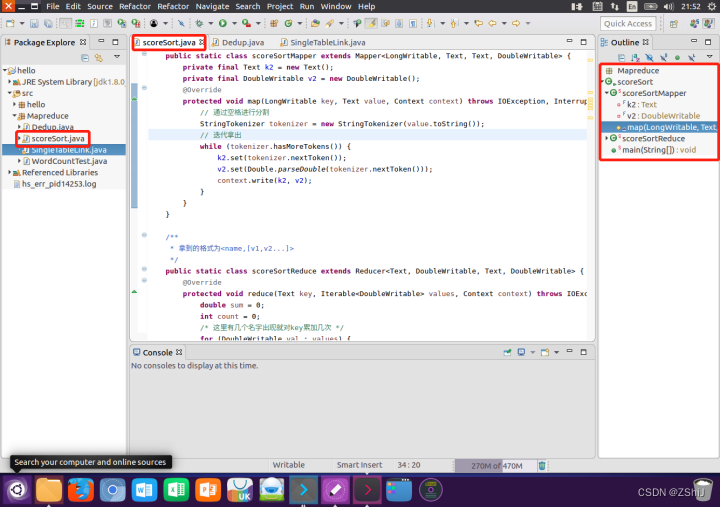
图20:java程序代码
代码:
package Mapreduce; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.io.DoubleWritable; import org.apache.hadoop.io.LongWritable; public class scoreSort { public static class scoreSortMapper extends Mapper { private final Text k2 = new Text(); private final DoubleWritable v2 = new DoubleWritable(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 通过空格进行分割 StringTokenizer tokenizer = new StringTokenizer(value.toString()); // 迭代拿出 while (tokenizer.hasMoreTokens()) { k2.set(tokenizer.nextToken()); v2.set(Double.parseDouble(tokenizer.nextToken())); context.write(k2, v2); } } } public static class scoreSortReduce extends Reducer { @Override protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException { double sum = 0; int count = 0; for (DoubleWritable val : values) { sum += val.get(); count++; } context.write(key, new DoubleWritable(sum / count)); } } public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { /* 配置文件 */ Configuration config = new Configuration(); Job job = Job.getInstance(config, "App"); /* mapper操作 */ job.setMapperClass(scoreSortMapper.class); /* 设置map后输出数据类型,如果不设置会默认输出类型,会报错 */ job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(DoubleWritable.class); /* 设置输出文件类型 */ job.setOutputKeyClass(Text.class); job.setOutputValueClass(DoubleWritable.class); /* combiner操作 */ job.setCombinerClass(scoreSortReduce.class); /* reduce操作 */ job.setReducerClass(scoreSortReduce.class); /* 设置输入、输出目录,输出目录不能存在 */ /* 设置输入输出的目录 */ Path inputpath = new Path("hdfs://localhost:9000/user/hadoop/data/cai.txt"); Path outpath = new Path("hdfs://localhost:9000/out4"); /* 设置需要计算的文件 */ FileInputFormat.addInputPath(job, inputpath); /* 删除多余的目录 */ //MpUtil.delOutPut(config, outpath); FileOutputFormat.setOutputPath(job, outpath); /* 0表示正常退出,1表示错误退出 */ System.exit(job.waitForCompletion(true) ? 0 : 1); } }
图21:scoreSort工程打包生成Sort.jar

图22:查看是否打包成功
在进入myapp目录下终端输入命令:ls,可以看到,“/usr/local/hadoop/myapp”目录下已经存在一个Sort.jar文件。

图23:使用hadoop jar命令运行程序
在终端输入命令:./bin/hadoop jar ./myapp/Sort.jar.jar运行打包的程序。

图24:运行结果
结果已经被写入了HDFS的“/user/hadoop/out4”目录中。
2.4成果展示+数据可视化分析
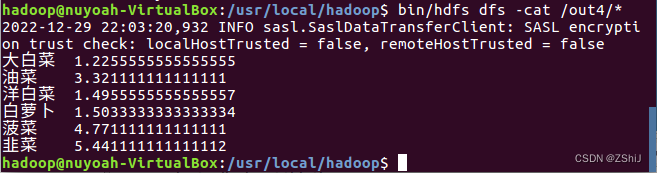
图25:查看输出文件内容
在终端输入命令:bin/hdfs dfs -cat /out4/*查看输出文件内容.
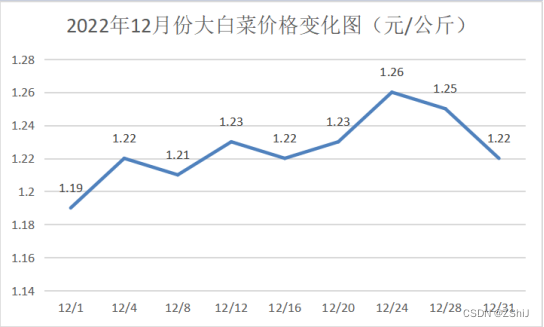
图26:2022年12月份大白菜价格变化图
表格数据中可分析出,大白菜的最高价格为1.26元/公斤,最低价格为1.15元/公斤,平均价格为1.22元/公斤,中位数价格为1.19元/公斤,当前价格处于中间。
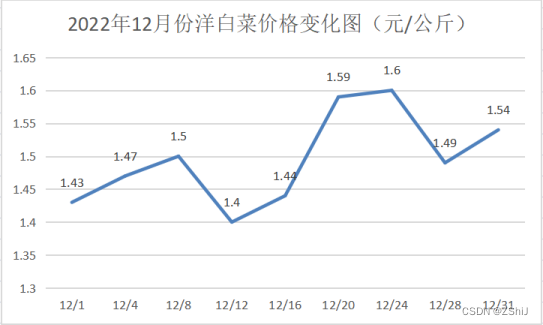
图27:2022年12月份洋白菜价格变化图
洋白菜的最高价格为1.66元/公斤,最低价格为1.41元/公斤,平均价格为1.49元/公斤,中位数价格为1.50元/公斤,当前价格处于高位。
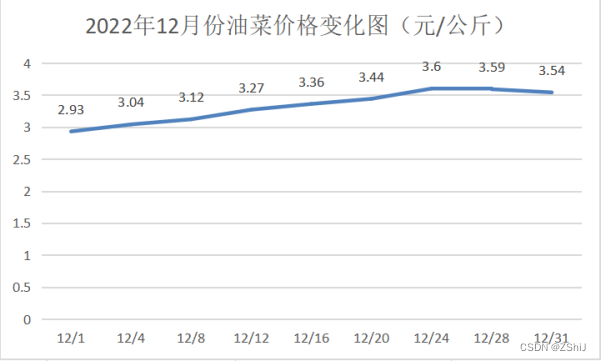
图28:2022年12月份油菜价格变化图
油菜的最高价格为4.48元/公斤,最低价格为2.93元/公斤,平均价格为3.32元/公斤,中位数价格为3.64元/公斤,当前价格处于高位。
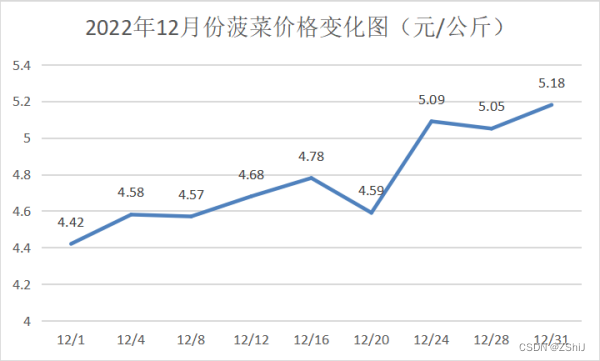
图29:2022年12月份菠菜价格变化图
菠菜的最高价格为6.40元/公斤,最低价格为4.42元/公斤,平均价格为4.77元/公斤,中位数价格为5.17元/公斤,当前价格处于高位。
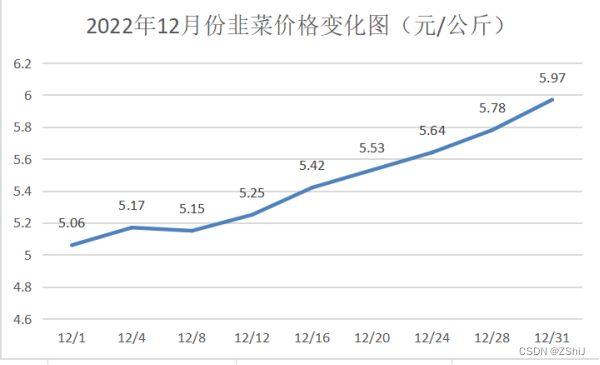
图30:2022年12月份韭菜价格变化图
韭菜的最高价格为6.80元/公斤,最低价格为5.06元/公斤,平均价格为5.44元/公斤,中位数价格为6.17元/公斤,当前价格处于高位。
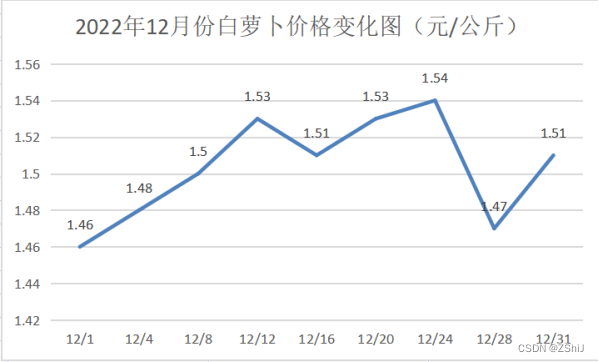
图31:2022年12月份白萝卜价格变化图
白萝卜的最高价格为1.55元/公斤,最低价格为1.39元/公斤,平均价格为1.50元/公斤,中位数价格为1.48元/公斤,当前价格处于高位。
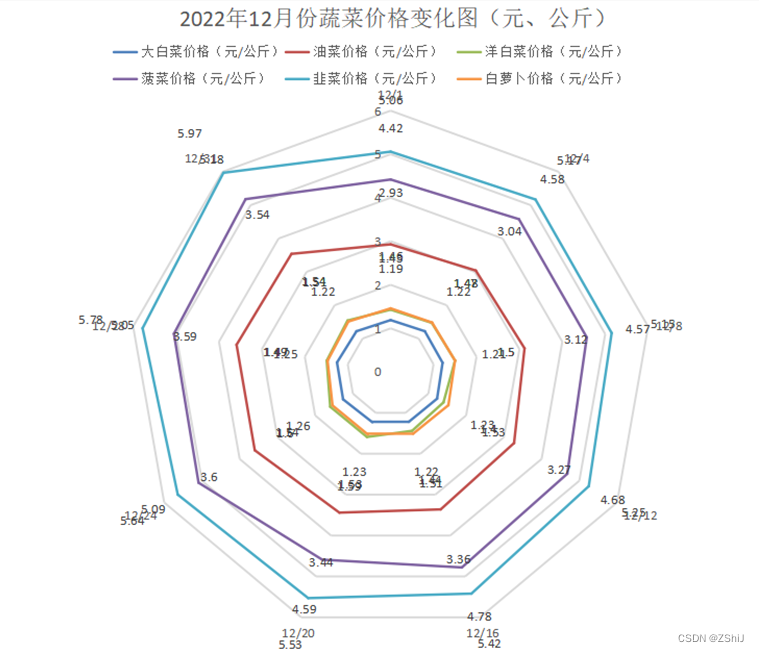
图32:2022年12月份蔬菜价格变化雷达图
分析:蔬菜价格整体随时间增长逐渐增高,“前低后高”,呈斜“N”分布态势,变化图来看,2022年12月份全国主要蔬菜批发均价在中旬起逐渐走高,价格在1.26~5.97元/kg之间波动,此后在波动中上升较明显,总体来看整个月份菜价“前低后高”,上半个月的平均菜价明显低于下半个月,呈现出斜“N”分布态势。
价格整体波动幅度缩小,价格的波动幅度指某个产品一年中的高低价差与一年中最低价的比值。从图表显示数据和linux系统运行得出的Average data可得,2022年我国大白菜平均价格为1.25元/公斤,油菜平均价格为3.32元/公斤,洋白菜平均价格为1.50元/公斤,白萝卜平均价格为1.50元/公斤,菠菜平均价格为4.77元/公斤,韭菜平均价格为5.44元/公斤,蔬菜平均最高值5.97元/kg,最低值为1.10元/kg,高低价差为4.87元/kg,波动幅度为27.6%,为近6年来最小波幅,也是近年来波幅低于30%的唯一月份。波幅缩小表明蔬菜供应淡旺季区别不明显,蔬菜均衡供应能力进一步增强。
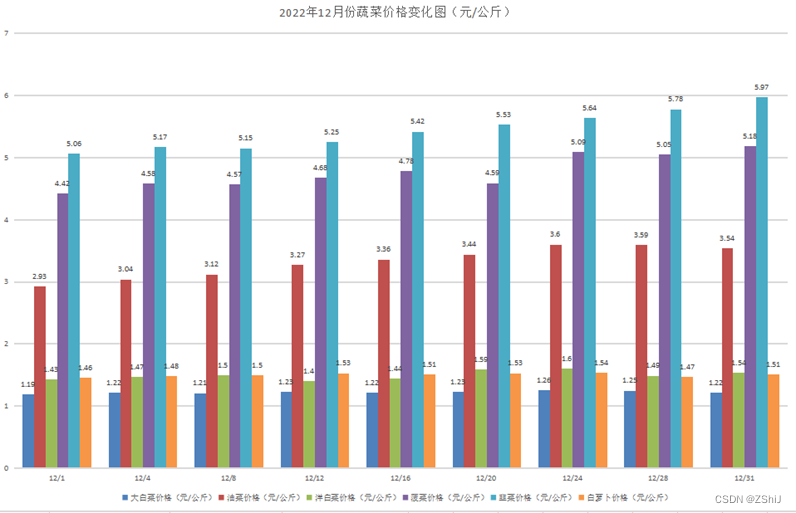
图33:2022年12月份蔬菜价格变化柱状图
三、基于hadoop的PageRank算法实现
3.1设计思路
1、首先MapReduce的元语是不能被破坏的:即 “相同”的key为一组,调用一次reduce方法,方法内迭代这组数据。
2、通过观察,我们可以看到这样的现象,页面包含超链接,每次迭代将pr值除以链接数后得到的值传递给所链接的页面,每次迭代都要包含页面链接关系和该页面的pr值。
3、MapReduce设计思路: 其中:
map阶段:主要做两件事情。
第一,读懂数据,第一次附加初始pr值。
第二,映射k:v。传递页面链接关系,key为该页面,value为页面链接关系,计算链接的pr值,key为所链接的页面,value为pr值。
reduce阶段:按页分组。
第一: 两类value分别处理。
第二: 最终合并为一条数据输出:key为页面&新的pr值,value为链接关系。
3.2实践过程
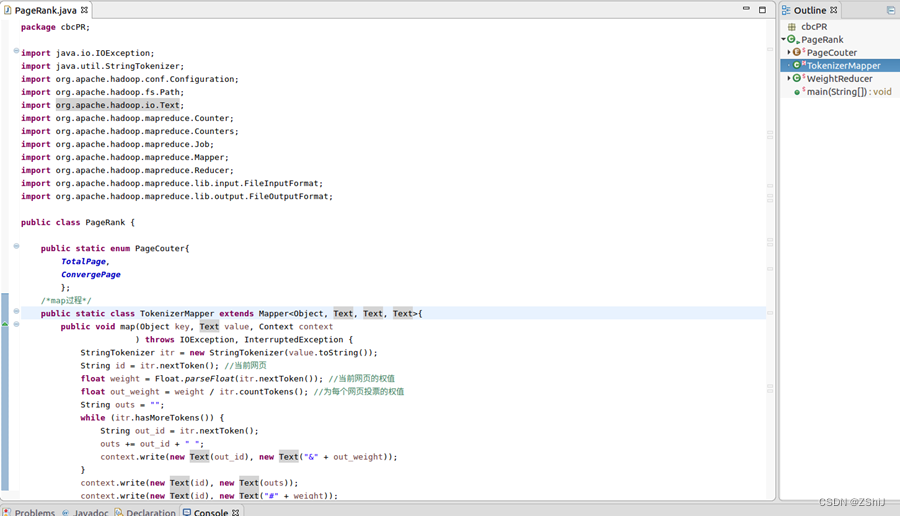
图34:java程序设计
代码:
package cbcPR; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Counter; import org.apache.hadoop.mapreduce.Counters; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class PageRank { public static enum PageCouter{ TotalPage, ConvergePage }; /*map过程*/ public static class TokenizerMapper extends Mapper{ public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); String id = itr.nextToken(); //当前网页 float weight = Float.parseFloat(itr.nextToken()); //当前网页的权值 float out_weight = weight / itr.countTokens(); //为每个网页投票的权值 String outs = ""; while (itr.hasMoreTokens()) { String out_id = itr.nextToken(); outs += out_id + " "; context.write(new Text(out_id), new Text("&" + out_weight)); } context.write(new Text(id), new Text(outs)); context.write(new Text(id), new Text("#" + weight)); //'#'表示当前的权值,用于reduce阶段判断是否收敛 //枚举计数器,计算有几个Page context.getCounter(PageCouter.TotalPage).increment(1); } } /*reduce过程*/ public static class WeightReducer extends Reducer { public void reduce(Text key, Iterable values, Context context ) throws IOException, InterruptedException { float sum_weight = 0; //新的权值 float pre_weight = 0; //上一轮的权值,比较是否收敛 String outs = ""; for (Text val : values) { String tmp = val.toString(); if (tmp.startsWith("&")) sum_weight+=Float.parseFloat(tmp.substring(1)); else if (tmp.startsWith("#")) pre_weight =Float.parseFloat(tmp.substring(1)); else outs = tmp; } sum_weight = 0.8f * sum_weight + 0.2f * 0.125f; //平滑处理,处理终止点和陷阱 context.write(key, new Text(sum_weight + " " + outs)); if (sum_weight == pre_weight) //枚举计数器,计算有几个已收敛 context.getCounter(PageCouter.ConvergePage).increment(1); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String in_path = args[0]; String out_path = args[1] + "/iter"; for (int i = 0; i
图35: 打包生成PageRank2.jar

图36:查看是否打包成功
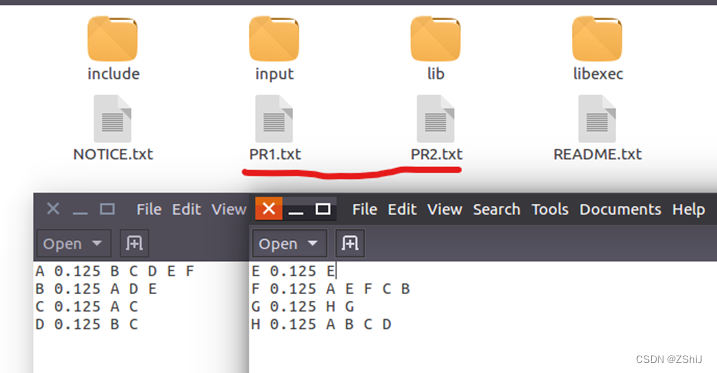
图37:准备数据
图38:启动hadoop并确认状态

图39:确保运行程序不出错,新建input
图40:上传数据

图41:运行jar包
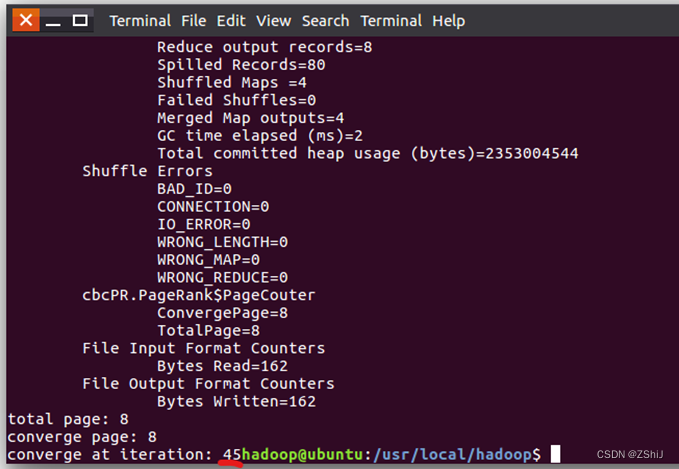
图42:运行结果
图43:查看数据
3.3成果展示

图44:实验结果
3.4 数据的可视化分析
有4个网页,链接关系如下,A网页有到B和C网页的链接,B有到D网页的链接,其余类似。
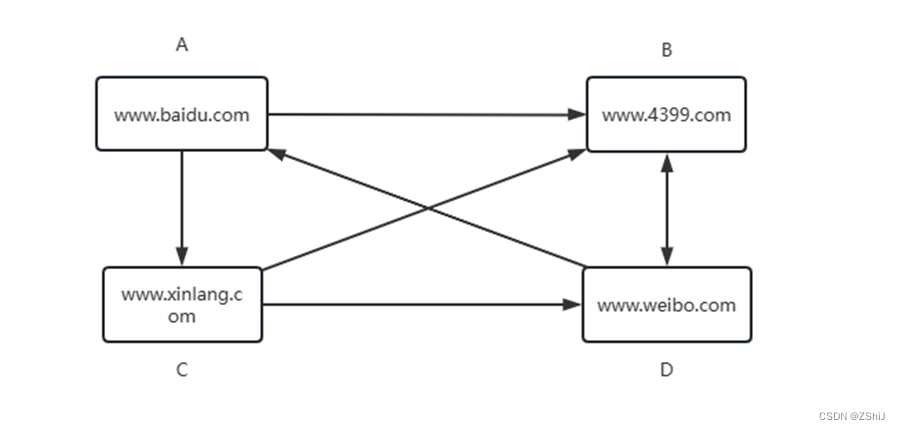
图45:网页链接状态
初始化每个网页的PageRank为1/N = 1/4
每个网页根据出链数均分自己的权值,更新所有网页的PageRank,即
A的PageRank为0.25,则分给B和C各0.125,而A得到D分得的0.125,所以A的PageRank更新为0.125
同理,B更新为0.375,C更新为0.125,D更新为0.375,四个网页和仍为1
重复第二步直到收敛
通常我们使用一种合适的数据结构来表示页面间的链接关系。设一共有N个页面,则要生成一个N维矩阵,其中第i行表示的是其他页面对 第i个页面链接的概率,第j列表示的是第j个页面对其他页面链接的概率。这样的矩阵叫做转移矩阵。对应到上图,转移矩阵为:

在上图中,第一列为页面A对各个页面转移的概率,第一行为各个页面对页面A转移的概率。初始时,每一个页面的PageRank值都是均等的,为1/N,这里也即是1/4。然后对于页面A来说,根据每一个页面的PageRank值和每个页面对页面A的转移概率,可以算出新一轮页面A的PageRank值。这里,只有页面B和页面C转移了自己的1/2给A。所以新一轮A的PageRank值为1/41/2+1/41/2=9/24。为了计算方便,我们设置各页面初始的PageRank值为一个列向量V0。然后再基于转移矩阵,我们可以直接求出新一轮各个页面的PageRank值。即 V1 = MV0
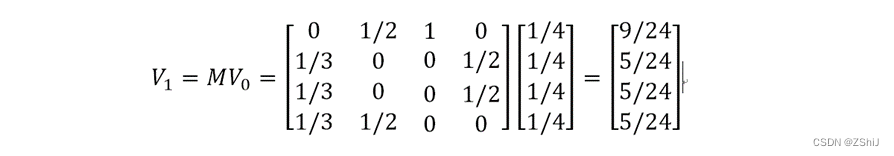
现在得到了各页面新的PageRank值V1, 继续用M 去乘以V1 ,就会得到更新的PageRank值。一直迭代这个过程,可以证明出V最终会收敛。此时停止迭代。这时的V就是各个页面的PageRank值。在上图中,一直迭代的中间V如下:

按照这种方式计算下去我们就可以得到了,迭代到i= 45时,两个计数器都为8,即在i = 45时收敛,查看输出文件,如代码中设置的,每一轮有两份输出。
分析:PageRank的Page可是认为是网页,表示网页排名,也可以认为是Larry Page(google 产品经理),因为他是这个算法的发明者之一,还是google CEO。PageRank算法计算每一个网页的PageRank值,然后根据这个值的大小对网页的重要性进行排序。它的思想是模拟一个悠闲的上网者,上网者首先随机选择一个网页打开,然后在这个网页上呆了几分钟后,跳转到该网页所指向的链接,这样无所事事、漫无目的地在网页上跳来跳去,PageRank就是估计这个悠闲的上网者分布在各个网页上的概率。首先分为ABCDEFGH,8组网址数据初始的总分配权值是0.125,首先进行的是平均分配权值的操作。图是强连通的,即从任意网页可以到达其他任意网页:互联网上的网页不满足强连通的特性,因为有一些网页不指向任何网页,如果按照上面的计算,上网者到达这样的网页后便走投无路、四顾茫然,导致前面累计得到的转移概率被清零,这样下去,最终的得到的概率分布向量所有元素几乎都为0。然后通过处理终止点问题和陷阱问题。上网者是一个悠闲的上网者,而不是一个愚蠢的上网者,我们的上网者是聪明而悠闲,他悠闲,漫无目的,总是随机的选择网页,他聪明,在走到一个终结网页或者一个陷阱网页,不会傻傻的干着急,他会在浏览器的地址随机输入一个地址,当然这个地址可能又是原来的网页,但这里给了他一个逃离的机会,让他离开这万丈深渊。模拟聪明而又悠闲的上网者,对算法进行改进,每一步,上网者可能都不想看当前网页了,不看当前网页也就不会点击上面的连接,而上悄悄地在地址栏输入另外一个地址,而在地址栏输入而跳转到各个网页的概率是1/n。假设上网者每一步查看当前网页的概率为a,那么他从浏览器地址栏跳转的概率为(1-a)。采用矩阵相乘,不断迭代,直到迭代前后概率分布向量的值变化不大,一般迭代到30次以上就收敛了。真的的web结构的转移矩阵非常大,目前的网页数量已经超过100亿,转移矩阵是100亿*100亿的矩阵,直接按矩阵乘法的计算方法不可行,需要借助Map-Reduce的计算方式来解决





