
用R语言进行数据分析(回归模型)



文章目录
- 一、简单线性回归模型
- 1.定义
- 2.最小二乘法
- 3. lm函数实现
- 二. 多项式回归
- 1.定义
- 2.lm函数实现
- 三、多元线性回归
- 1.定义
- 2.lm函数实现
- 四、比较不同回归模型效果
- 1.测试误差
- 2.交叉验证
- 2.1 K折交叉验证
- 五、矫正措施
数据特征
包括:一个因变量Y,p个自变量X1,……,Xp,未知参数,误差项
通过一组自变量(独立变量)X1,……,Xp来预测或解释一个因变量(依赖变量)Y的值。
一、简单线性回归模型
1.定义
对于因变量Y和自变量 X,简单线性回归模型表示为:Y=β0+β1*X+ε
其中,ε是误差项。
对于样本数据(X1,Y1),(X2,Y2),……,(Xn,Yn)
我们假设每个样本点满足:
 其中,误差项εi(i=1,……,n)服从独立同分布的正态分布 N(0,σ^2)
其中,误差项εi(i=1,……,n)服从独立同分布的正态分布 N(0,σ^2)通过对模型参数β0和β1进行估计,我们得到估计值 :

2.最小二乘法
残差:残差表示实际观测值与模型预测值之间的差异。
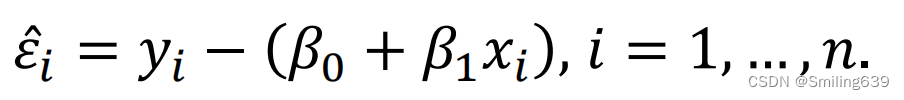
最小二乘法:目的是通过最小化残差的平方和来找到最佳拟合的回归直线。
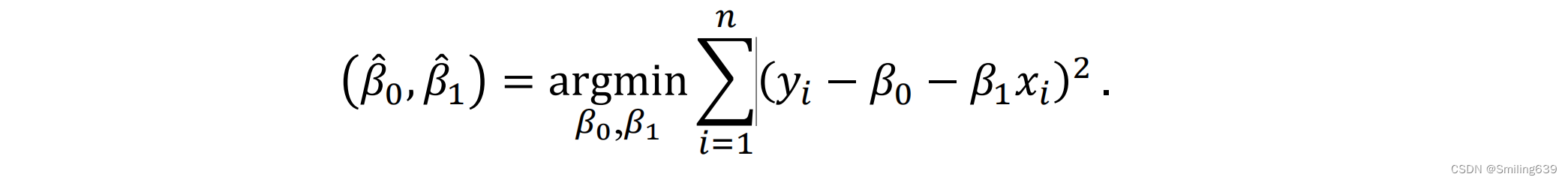
最小二乘估计:β0和β1分别是截距和斜率的估计值,通过它们可以建立回归方程,用来预测因变量的值。
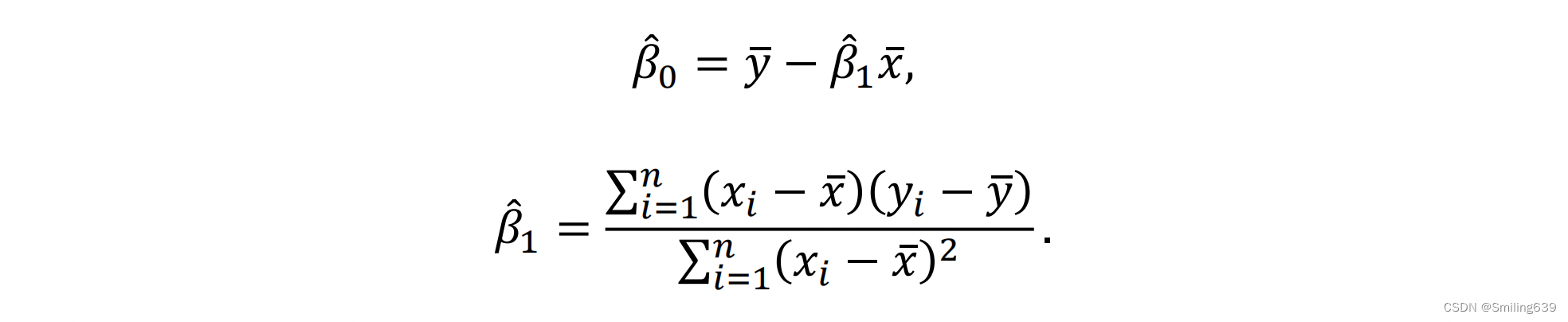
3. lm函数实现
在R语言中,用于拟合线性模型的基本函数是 lm()。其格式如下:
myfit mtcars2 fit class(fit) [1] "lm"
fit的类型是lm(线性模型)对象。
> names(fit) [1] "coefficients" "residuals" "effects" "rank" "fitted.values" "assign" [7] "qr" "df.residual" "xlevels" "call" "terms" "model"
输出fit对象的所有组件
> summary(fit) Call: lm(formula = mpg ~ wt, data = mtcars2) Residuals: Min 1Q Median 3Q Max -4.5432 -2.3647 -0.1252 1.4096 6.8727 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 37.2851 1.8776 19.858输出fit摘要信息,包括:
- Call: 显示拟合模型的公式。
- Residuals: 提供残差的五数摘要(最小值、第一四分位数、中位数、第三四分位数、最大值)。
- Coefficients: 显示回归系数(截距和斜率)、标准误差、t值及其对应的p值。
- (Intercept): 截距(37.2851),表示当 wt 为零时,mpg 的估计值。
- wt: 斜率(-5.3445),表示 wt 每增加一个单位,mpg 预计减少5.3445个单位。
- Pr(>|t|): p值,表示系数显著性的统计测试结果。这里两者都非常显著(p值远小于0.05)。
- Residual standard error: 残差标准误差,表示回归模型未解释的变异量。
- Multiple R-squared: 多重R平方,表示自变量解释的因变量变异的百分比(75.28%)。
- Adjusted R-squared: 调整后的R平方,调整了自变量数量的影响(74.46%)。
- F-statistic: F统计量及其p值,测试整体模型的显著性。这里F统计量为91.38,p值为1.294e-10,表明模型显著。
> coef(fit) (Intercept) wt 37.285126 -5.344472
提取回归系数,截距为37.285126,斜率为-5.344472。
plot(mpg ~ wt, data=mtcars2, pch=20, col=4) abline(lm(mpg ~ wt, data=mtcars2), lty=1, col=2) legend("topright", c("Real Points","Fitting"), cex=0.75, pch=c(20,NA), lty=c(NA,1), col=c(4,2))
模型表明 wt(重量)对 mpg(每加仑行驶英里数)有显著的负向影响,模型整体拟合良好。
二. 多项式回归
1.定义
与简单线性回归不同,多项式回归使用一个或多个自变量的多项式来拟合数据。基本思想是在原始数据点之间拟合一条多项式曲线,以便更好地捕捉数据中的趋势和模式。
对于一个自变量x和因变量 y,多项式回归模型可以表示为:
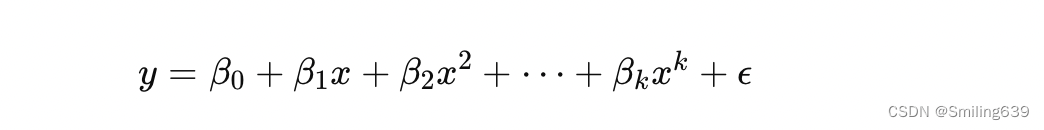
2.lm函数实现
fit2 lsfit(x,y)} theta.predict cbind(1,x)%*%fit$coef} results lsfit(x,y)} cbind(1,x)%*%fit$coef}
文章版权声明:除非注明,否则均为主机测评原创文章,转载或复制请以超链接形式并注明出处。





