
简单爬虫案例——爬取快手视频



网址:aHR0cHM6Ly93d3cua3VhaXNob3UuY29tL3NlYXJjaC92aWRlbz9zZWFyY2hLZXk9JUU2JThCJTg5JUU5JTlEJUEy
找到视频接口:
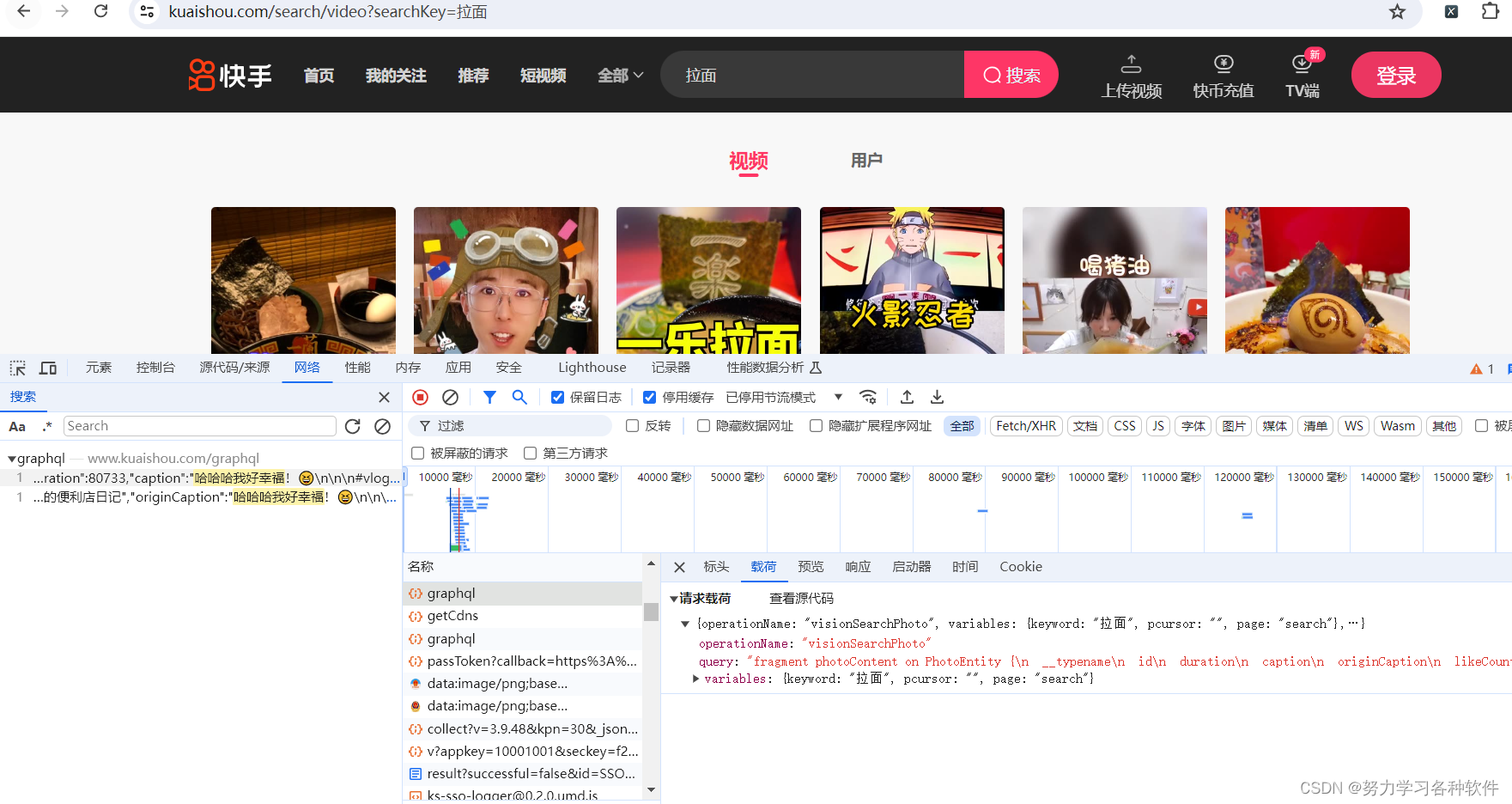
视频链接在photourl中
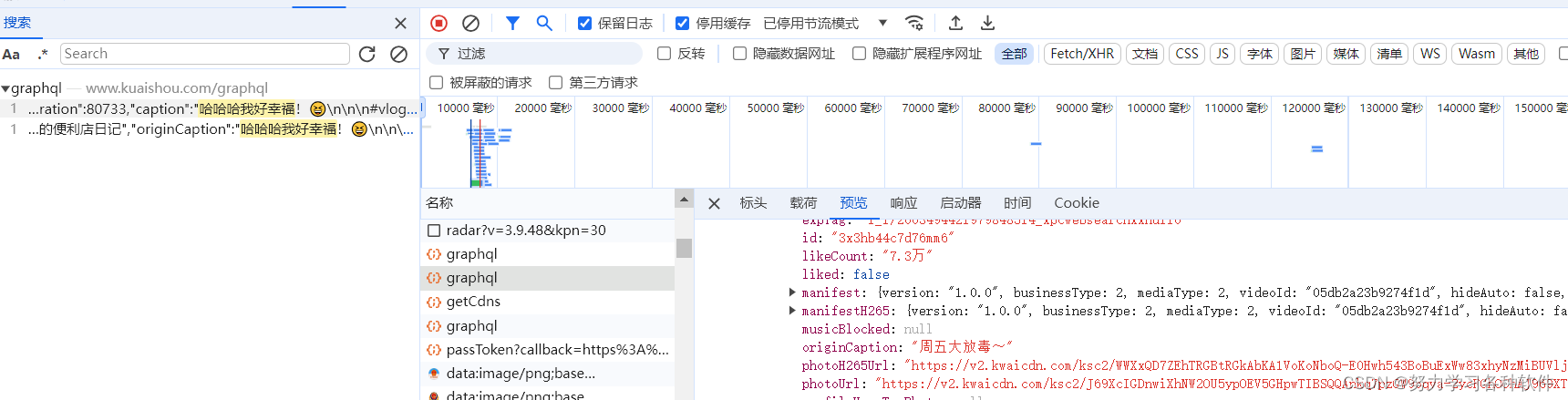
完整代码:
import requests
import re
url = 'https://www.kuaishou.com/graphql'
cookies = {
'did': 'web_9e8cfa4403000587b9e7d67233e6b04c',
'didv': '1719811812378',
'kpf': 'PC_WEB',
'clientid': '3',
'kpn': 'KUAISHOU_VISION',
}
headers = {
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
# 'Cookie': 'did=web_9e8cfa4403000587b9e7d67233e6b04c; didv=1719811812378; kpf=PC_WEB; clientid=3; kpn=KUAISHOU_VISION',
'Origin': 'https://www.kuaishou.com',
'Pragma': 'no-cache',
'Referer': 'https://www.kuaishou.com/search/video?searchKey=%E6%8B%89%E9%9D%A2',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36',
'accept': '*/*',
'content-type': 'application/json',
'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Google Chrome";v="126"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
json_data = {
'operationName': 'visionSearchPhoto',
'variables': {
'keyword': '拉面',
'pcursor': '',
'page': 'search',
},
'query': 'fragment photoContent on PhotoEntity {\n __typename\n id\n duration\n caption\n originCaption\n likeCount\n viewCount\n commentCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n musicBlocked\n riskTagContent\n riskTagUrl\n}\n\nfragment recoPhotoFragment on recoPhotoEntity {\n __typename\n id\n duration\n caption\n originCaption\n likeCount\n viewCount\n commentCount\n realLikeCount\n coverUrl\n photoUrl\n photoH265Url\n manifest\n manifestH265\n videoResource\n coverUrls {\n url\n __typename\n }\n timestamp\n expTag\n animatedCoverUrl\n distance\n videoRatio\n liked\n stereoType\n profileUserTopPhoto\n musicBlocked\n riskTagContent\n riskTagUrl\n}\n\nfragment feedContent on Feed {\n type\n author {\n id\n name\n headerUrl\n following\n headerUrls {\n url\n __typename\n }\n __typename\n }\n photo {\n ...photoContent\n ...recoPhotoFragment\n __typename\n }\n canAddComment\n llsid\n status\n currentPcursor\n tags {\n type\n name\n __typename\n }\n __typename\n}\n\nquery visionSearchPhoto($keyword: String, $pcursor: String, $searchSessionId: String, $page: String, $webPageArea: String) {\n visionSearchPhoto(keyword: $keyword, pcursor: $pcursor, searchSessionId: $searchSessionId, page: $page, webPageArea: $webPageArea) {\n result\n llsid\n webPageArea\n feeds {\n ...feedContent\n __typename\n }\n searchSessionId\n pcursor\n aladdinBanner {\n imgUrl\n link\n __typename\n }\n __typename\n }\n}\n',
}
response = requests.post(url=url, cookies=cookies, headers=headers, json=json_data)
for index in response.json()['data']['visionSearchPhoto']['feeds']:
title = index['photo']['caption']
newtitle = re.sub(r'[\\/?:*|\n\r]','',title)
link = index['photo']['photoUrl']
print(title,link)
content = requests.get(url=link,headers=headers).content
with open('快手video//'+title+'.mp4','wb') as f:
f.write(content)
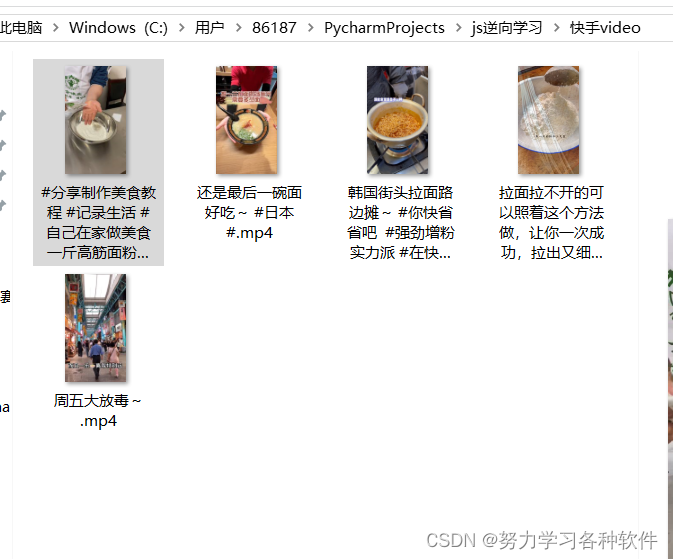
结果展现:
文章版权声明:除非注明,否则均为主机测评原创文章,转载或复制请以超链接形式并注明出处。



