
【Python爬虫】Python爬取喜马拉雅,爬虫教程!




一、思路设计
(1)分析网页

在喜马拉雅主页找到自己想要的音频,得到目标URL:https://www.ximalaya.com/qinggan/321787/

通过分析页面的网络抓包,最终的到一个比较有用的json数据包
通过分析,得到了发送json数据包的一个有用的API接口:https://www.ximalaya.com/revision/play/album?albumId=321787&pageNum=2
其中album为主播的ID在页面url中有显示,pageNum为json数据包的“页数”。每个json数据包有30个json数据
(2)设计代码
向服务器发送请求 ----> 得到json数据包 ----> 分析json数据包 ----> 提取json数据包中的有用数据 ----> 存储到本地MongoDB数据库
二、代码实例
代码共分为两部分,执行脚本(ximalaya.py)和配置文件(config_ximalaya.py)
ximalaya.py
1 # -*- coding:utf-8; -*-
2 # Author : Bingnan Huo
3 # Create : 2018-12-06
4 import os
5 import time
6 import json
7 import requests
8
9 from threading import Thread
10 from datetime import datetime
11 from pymongo import MongoClient
12 from config_xiamalaya import *
13
14 def getWorkTimeNow():
15 '''Acquire work time '''
16 t = datetime.now()
17 year = t.year
18 month = t.month
19 day = t.day
20 hour = t.hour
21 minute = t.minute
22 time_str = "[%s-%s-%s-%s:%s]"%(str(year),
23 str(month),
24 str(day),
25 str(hour),
26 str(minute)
27 )
28 return time_str
29
30 def getJsonData(userID,page):
31 '''Get target server json data'''
32 count = 0
33 pa = {"albumId":userID,"pageNum":page}
34 while(ERROR):
35 if count > 10:
36 return False
37 try:
38 ret = requests.get(url=INDEXURL,params=pa,headers=HEADERS,timeout=30,verify=True,proxies=None)
39 ret.raise_for_status()
40 except Exception as e:
41 count += 1
42 print(getWorkTimeNow(),end='')
43 print(" [INFO] Retry...")
44 continue
45 else:
46 ret.encoding = ret.apparent_encoding
47 return ret.text
48
49 def analyseJsonData(jsonData):
50 '''Analyse json data and save into MongoDB'''
51 if jsonData:
52 client = MongoClient()
53 print(getWorkTimeNow() + " [INFO] Connected to MongoDB!")
54 db = client.ximalaya# Create DataBase
55 print(getWorkTimeNow() + " [INFO] Create new database!")
56 table = getattr(db,TABLENAME)# Create Table
57 print(getWorkTimeNow() + " [INFO] Create new table --> %s" %(TABLENAME))
58 dict_obj = json.loads(jsonData)
59 data = dict_obj["data"]# Json attr data
60 content = data["tracksAudioPlay"]# json content
61 for i in content:
62 tmp_dict = {'序号':None,'名称':None,'Url':None,'源':None,'状态':False,'时长':None,}
63 tmp_dict['序号'] = i['index']
64 tmp_dict['名称'] = i['trackName']
65 tmp_dict['Url'] = "https://www.ximalaya.com" + i['trackUrl']
66 tmp_dict['源'] = i['src']
67 if i['isPaid']:
68 tmp_dict['状态'] = True
69 tmp_dict['时长'] = i['duration']
70 table.insert_one(tmp_dict)
71 print(getWorkTimeNow() + " [INFO] Insert one data!")
72
73
74 def DBStart(dbpath):
75 '''start MongoDB client'''
76 status = os.system("start mongod --dbpath " + dbpath)
77 if not status:
78 print(getWorkTimeNow() + " [INFO] DataBase start!")
79 return True
80 else:
81 print(getWorkTimeNow() + " [INFO] DataBase Failed...")
82 return False
83 def execute(user_id,page):
84 json_data = getJsonData(user_id, page)
85 analyseJsonData(json_data)
86
87 def main():
88 DBStart(DBPATH)
89 for page in PAGECONTIANER:
90 execute(USERID, str(page))
91
92
93
94
95 if __name__ == "__main__":
96 main()
config_ximalaya.py
1 # -*- coding:utf-8 -*-
2 # ximalaya.py -- config
3 import time
4
5 def getUnixTime():
6 t = time.time()
7 return str(int(t))
8
9
10
11 INDEXURL = " https://www.ximalaya.com/revision/play/album"
12
13 ERROR = True
14
15 HEADERS = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0",
16
17
18 }
19 """
20 Cookie:x_xmly_traffic=utm_source%253A%2526utm_medium%253A%2526utm_campaign%253A%2526utm_content%253A%2526utm_term%253A%2526utm_from%253A;
21 device_id=xm_1544076474056_jpc79kg8f1h3u6;
22 Hm_lvt_4a7d8ec50cfd6af753c4f8aee3425070=1544076479;
23 Hm_lpvt_4a7d8ec50cfd6af753c4f8aee3425070=1544076479
24 API : https://www.ximalaya.com/revision/play/album?albumId=321787&pageNum=1
25
26 """
27 COOKIE = {"x_xmly_traffic":"utm_source%253A%2526utm_medium%253A%2526utm_campaign%253A%2526utm_content%253A%2526utm_term%253A%2526utm_from%253A",
28 "device_id":"xm_1544076474056_jpc79kg8f1h3u6",
29 "Hm_lvt_4a7d8ec50cfd6af753c4f8aee3425070":getUnixTime(),
30 "Hm_lpvt_4a7d8ec50cfd6af753c4f8aee3425070":getUnixTime()
31 }
32
33 DBPATH = "D:\\MongoDB\\data\\db"
34
35 TABLENAME = "Test_321787_02"
36
37 PAGECONTIANER = [i for i in range(1,10)]
38
39 USERID = "321787"
三、执行结果
最终的数据插入到了本地的MongoDB数据库
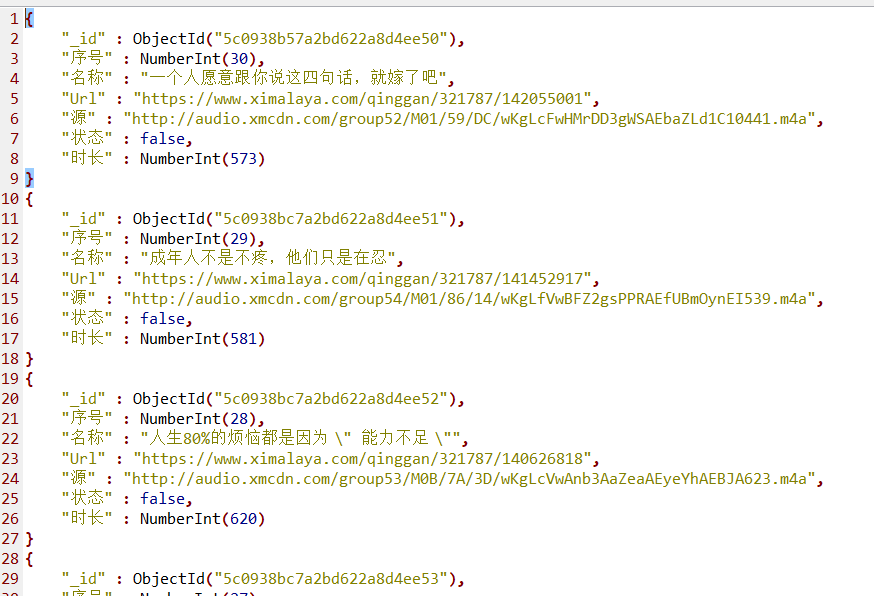
由于MongoDB为NoSQL型数据库,该数据库采用BOSN数据类型(json加强版)进行存储
在RoboMongo中也可以用MySQL数据库的表形式进行显示
最后:如果你对Python感兴趣,想要学习Python,希望可以帮到你,一起加油!以上是给大家分享的Python全套学习资料,都是我自己学习时整理的:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
**学习资源已打包,需要的小伙伴可以戳这里:【学习资料】



