
python爬虫实战代码(一)
目录
一、程序效果
二、程序代码
三、答疑解惑
四、同步视频讲解
python爬虫爬取豆瓣电影top250数据并存入excel表格
一、程序效果
爬虫的效果如下
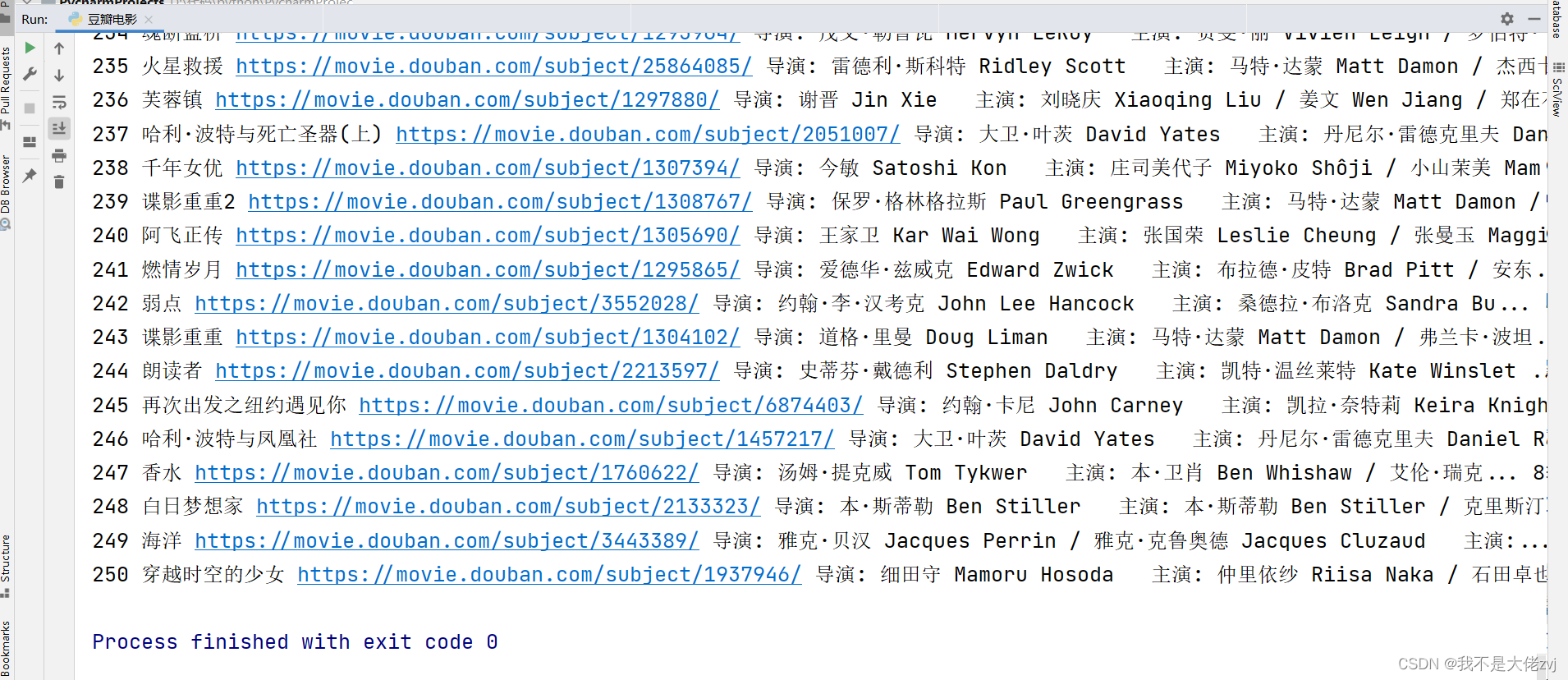
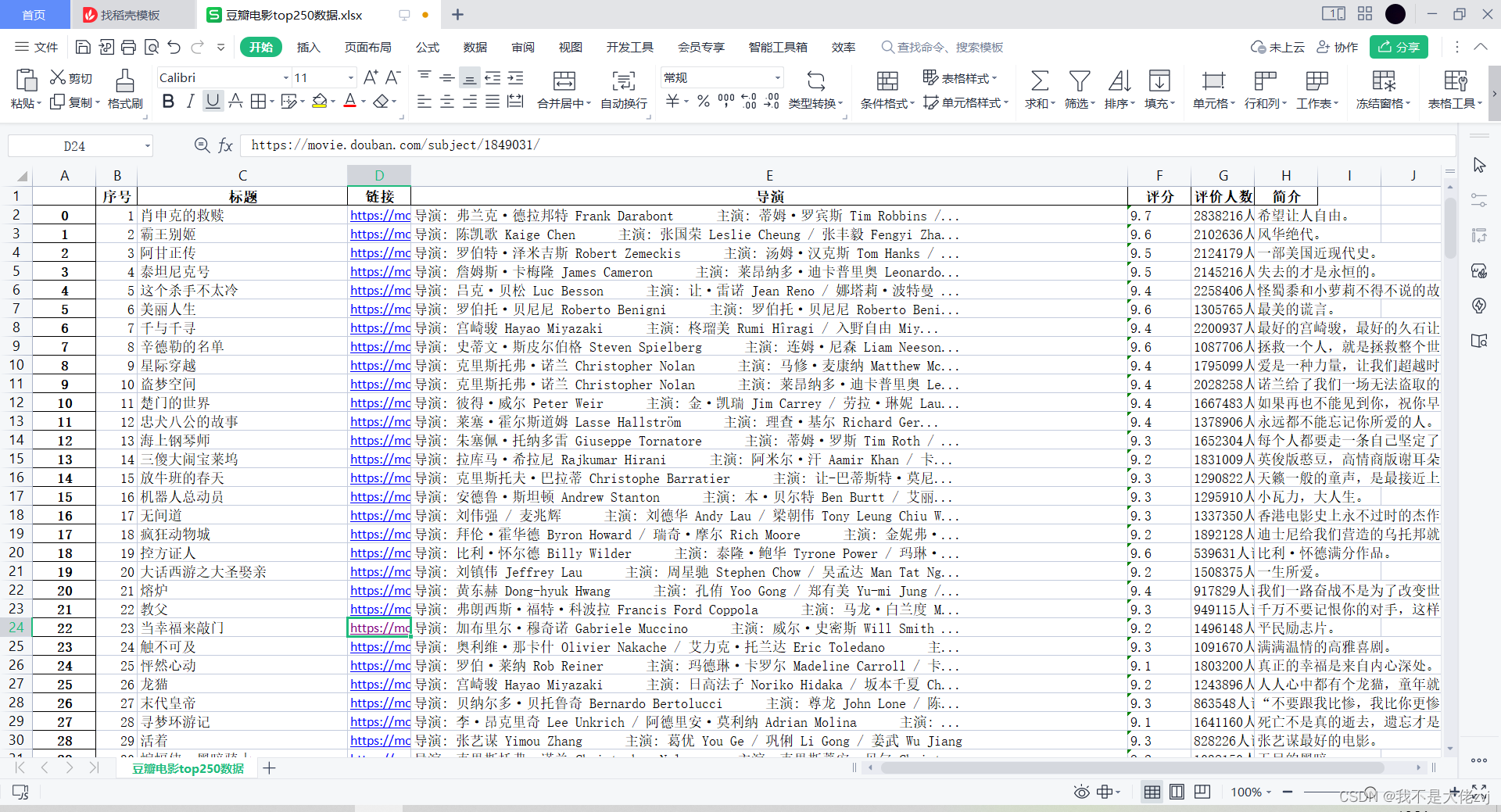

二、程序代码
完整程序代码如下,复制粘贴可直接运行出结果!
# encoding: utf-8
'''
@author: 我不是大佬
@contact: 2869210303@qq.com
@wx; safeseaa
@qq; 2869210303
@time: 2023/4/16 8:40
'''
import requests # 网络请求模块
from lxml import etree # 数据解析模块
# 请求头信息
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.46'
}
# 功能函数,胡哦去列表的而第一个元素
def get_first_text(list):
try:
return list[0].strip() # 返回第一个字符串,除去两端的空格
except:
return "" # 返回空字符串
import pandas as pd
df=pd.DataFrame(columns=["序号","标题","链接","导演","评分","评价人数","简介"])
# 使用列表生成式表示10个页面的地址
urls = ['https://movie.douban.com/top250?start={}&filter='.format(str(i * 25)) for i in range(10)]
count = 1 # 用来计数
for url in urls:
res = requests.get(url=url, headers=headers) # 发起请求
html = etree.HTML(res.text) # 将返回的文本加工为可以解析的html
lis = html.xpath('//*[@id="content"]/div/div[1]/ol/li') # 获取每个电影的li元素
# 解析数据
for li in lis:
title = get_first_text(li.xpath('./div/div[2]/div[1]/a/span[1]/text()')) # 电影标题
src = get_first_text(li.xpath('./div/div[2]/div[1]/a/@href')) # 电影链接
dictor = get_first_text(li.xpath('./div/div[2]/div[2]/p[1]/text()')) # 导演
score = get_first_text(li.xpath('./div/div[2]/div[2]/div/span[2]/text()')) # 评分
comment = get_first_text(li.xpath('./div/div[2]/div[2]/div/span[4]/text()')) # 评价人数
summary = get_first_text(li.xpath('./div/div[2]/div[2]/p[2]/span/text()')) # 电影简介
print(count, title, src, dictor, score, comment, summary) # 输出
df.loc[len(df.index)]=[count,title,src,dictor,score,comment,summary]
count += 1
df.to_excel("豆瓣电影top250数据.xlsx",sheet_name="豆瓣电影top250数据",na_rep="")
print("excel文件已经生成!")
三、答疑解惑
有任何问题的小伙伴可以添加我的微信:safeseaa
四、同步视频讲解
推荐大家两个相关的视频讲解,有需要的可以去看看。
【python】手把手带你爬虫爬取豆瓣电影top250【超详细教程】
【python】手把手带你爬虫爬取豆瓣电影top250【超详细教程】
【补充】python爬取爬取豆瓣电影数据并储存到excel里面【超详细讲解】【一看就会】
【补充】python爬取爬取豆瓣电影数据并储存到excel里面【超详细讲解】【一看就会】
如果对您有帮助,记得给我点个关注哦!
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



