
能理解你的意图的自动化采集工具——AI和爬虫相结合



⭐️我叫忆_恒心,一名喜欢书写博客的研究生👨🎓。
如果觉得本文能帮到您,麻烦点个赞👍呗!
近期会不断在专栏里进行更新讲解博客~~~
有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三连支持一下呗。👍⭐️❤️
📂Qt5.9专栏定期更新Qt的一些项目Demo
📂项目与比赛专栏定期更新比赛的一些心得,面试项目常被问到的知识点。
欢迎评论 💬点赞👍🏻 收藏 ⭐️加关注+
✍🏻文末可以进行资料和源码获取欧😄
前言
当我们需要收集一些数据的时候,自动化数据采集工具总是可以帮到我们,但是传统的自动化数据采集工具,存在以下不足:
- 工具的通用程度低:需要我们手动分析每个网站的特点;
- 保存的数据格式也比较单一
- 操作麻烦
当AI的阅读理解能力遇到了自动化采集工具的时候,将会产生怎么样的魔法呢?
能够理解你的意图并自动执行复杂的网络数据抓取任务,ScrapeGraphAI 就是这样一个工具,它利用最新的人工智能技术,让数据提取变得前所未有地简单。
工具的优点

- 简单易用:只需输入 API 密钥,您就可以在几秒钟内抓取数千个网页!
- 开发便捷:你只需要实现几行代码,工作就完成了。
- 专注业务:有了这个库,您可以节省数小时的时间,因为您只需要设置项目,人工智能就会为您完成一切。
一、介绍
***ScrapeGraphAI*是一个网络爬虫 Python 库,使用大型语言模型和直接图逻辑为网站和本地文档(XML,HTML,JSON 等)创建爬取管道。
只需告诉库您想提取哪些信息,它将为您完成!

scrapegraphai有三种主要的爬取管道可用于从网站(或本地文件)提取信息:
- SmartScraperGraph: 单页爬虫,只需用户提示和输入源;
- SearchGraph: 多页爬虫,从搜索引擎的前 n 个搜索结果中提取信息;
- SpeechGraph: 单页爬虫,从网站提取信息并生成音频文件。
- SmartScraperMultiGraph: 多页爬虫,给定一个提示 可以通过 API 使用不同的 LLM,如 OpenAI,Groq,Azure 和 Gemini,或者使用 Ollama 的本地模型。
官方提供了非常详细的文档:官方文档
二、准备工作
2.1 安装ollama
点击前往网站 https://ollama.com/ ,下载ollama软件,目前该软件支持支持win、Mac、linux
2.2 下载LLM
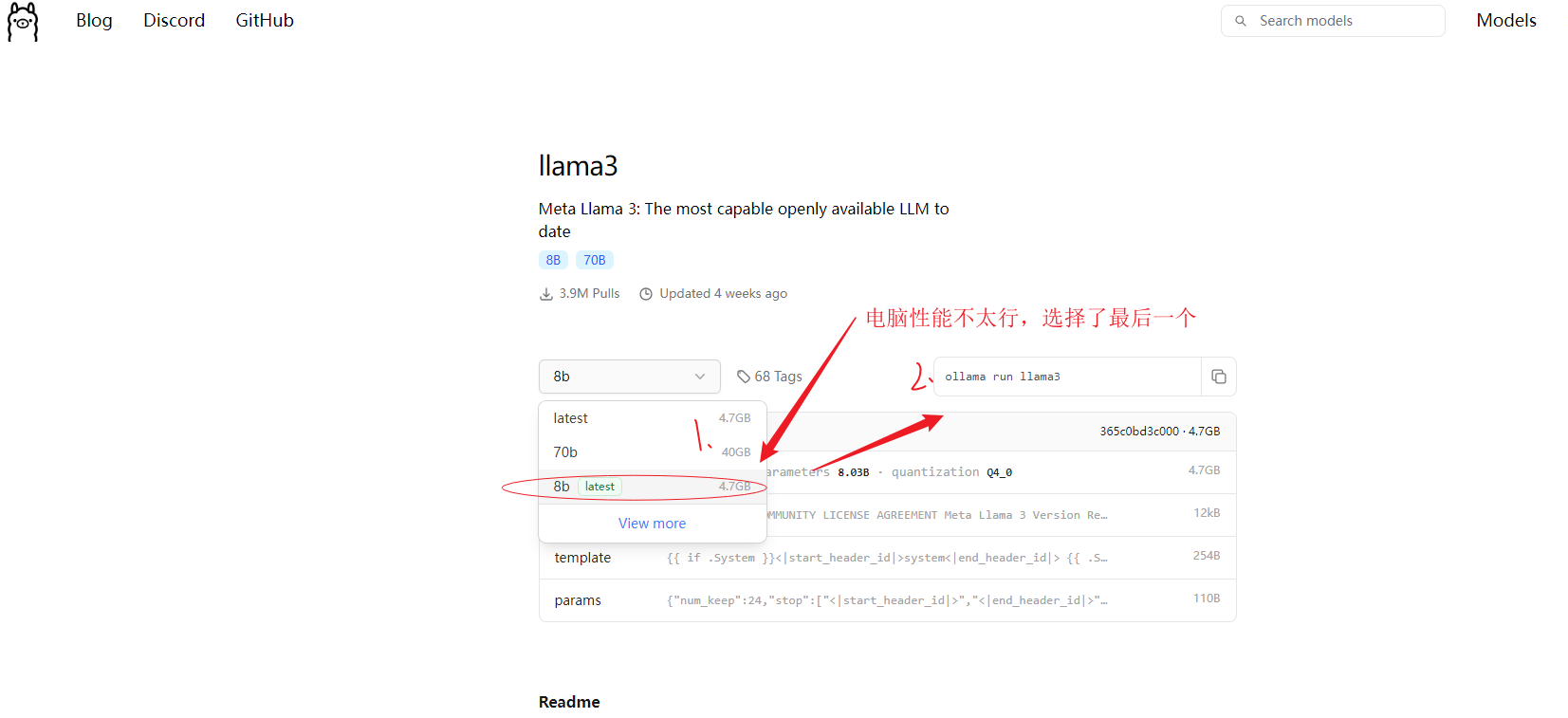
ollama软件目前支持多种大模型, 如阿里的(qwen、qwen2)、meta的(llama3),
以llama3为例,根据自己电脑显存性能, 选择适宜的版本。如果不知道选什么,那就试着安装,不合适不能用再删除即可。
打开电脑终端命令行cmd, 网络是连网状态,执行模型下载(安装)命令
强烈建议,更改默认路径
新建变量
OLLAMA_MODELS
值
D:\OllamaCache
添加了环境变量后,记得重启计算机,使其生效
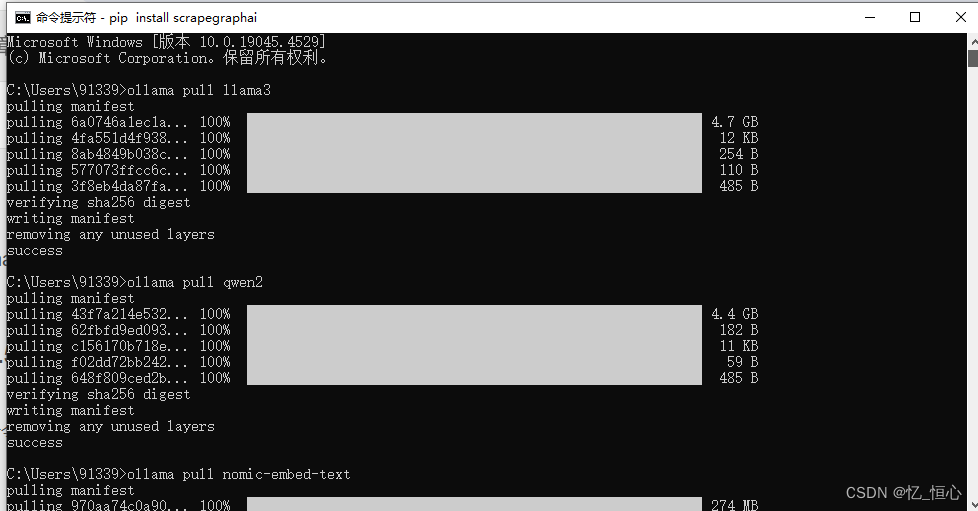
ollama pull llama3 ollama pull qwen2 ollama pull nomic-embed-text
等待 llama3、 nomic-embed-text 下载完成。
2.3 安装python包
在python中调用ollama服务,需要ollama包。
打开电脑命令行cmd(mac是terminal), 网络是连网状态,执行安装命令
pip3 install ollama
建议使用anaconda环境来管理这些包,因为默认的base环境可能会出现python版本不兼容的问题。
# 创建名为 ollama 的虚拟环境,并指定 Python 3.10 conda create --name ollama python=3.10 # 激活虚拟环境 conda activate ollama
2.4 启动ollama服务
在Python中调用本地ollama服务,需要先启动本地ollama服务, 打开电脑命令行cmd(mac是terminal), 执行
ollama serve
Run
cmd(mac是terminal)看到如上的信息,说明本地ollama服务已开启。
2.5 安装scrapegraphai及playwright
电脑命令行cmd(mac是terminal), 网络是连网状态,执行安装命令
pip install scrapegraphai
之后继续命令行cmd(mac是terminal)执行
playwright install
等待安装完成后,进行实验
三、实验
注意端口冲突,尽量不要使用8080
3.1 案例1
以我的博客 ydlin.blog.csdn.net 为例,假设我想获取标题、日期、文章链接,
代码如下:
from scrapegraphai.graphs import SmartScraperGraph graph_config = { "llm": { "model": "ollama/llama3", "temperature": 0, "format": "json", # Ollama 需要显式指定格式 "base_url": "http://localhost:11434", # 设置 Ollama URL }, "embeddings": { "model": "ollama/nomic-embed-text", "base_url": "http://localhost:11434", # 设置 Ollama URL }, "verbose": True, } smart_scraper_graph = SmartScraperGraph( prompt="返回该网站所有文章的标题、日期、文章链接", # 也接受已下载的 HTML 代码的字符串 #source=requests.get("https://ydlin.blog.csdn.net/").text, source="https://ydlin.blog.csdn.net/", config=graph_config ) result = smart_scraper_graph.run() print(result)Run
--- Executing Fetch Node --- --- Executing Parse Node --- --- Executing RAG Node --- --- (updated chunks metadata) --- --- (tokens compressed and vector stored) --- --- Executing GenerateAnswer Node --- Processing chunks: 100%|█████████████████████████| 1/1 [00:00 "llm": { "api_key": "OPENAI_API_KEY", "model": "gpt-3.5-turbo", }, } # ************************************************ # Create the SmartScraperGraph instance and run it # ************************************************ smart_scraper_graph = SmartScraperGraph( prompt="List me all the projects with their description.", # also accepts a string with the already downloaded HTML code source="https://perinim.github.io/projects/", config=graph_config ) result = smart_scraper_graph.run() print(result) if __name__ == "__main__": main() "llm": { "api_key": "OPENAI_API_KEY", "model": "gpt-3.5-turbo", }, "tts_model": { "api_key": "OPENAI_API_KEY", "model": "tts-1", "voice": "alloy" }, "output_path": "audio_summary.mp3", } # ************************************************ # Create the SpeechGraph instance and run it # ************************************************ speech_graph = SpeechGraph( prompt="Make a detailed audio summary of the projects.", source="https://perinim.github.io/projects/", config=graph_config, ) result = speech_graph.run() print(result)



