
哔哩哔哩视频URL解析原理


.png)

哔哩哔哩视频URL解析原理
视频网址解析视频的原理通常涉及以下几个步骤:
1、获取视频页面源代码:通过HTTP请求获取视频所在网页的HTML源代码。这一步通常需要处理反爬虫机制,如验证码或用户登录。
2、解析页面源代码:分析HTML源代码,提取出包含视频信息的特定标签和属性。通常,这些信息会包含在JavaScript变量、HTML标签(如、)、或者
3、提取视频URL:从解析出的信息中提取出视频的实际播放地址(通常是一个流媒体URL)。这个地址可能需要进一步处理,例如解密或解码。
4、下载视频或播放:获取到实际的视频URL后,可以直接用播放器播放视频,或者使用下载工具将视频文件下载到本地。
具体实现时,解析视频网址通常需要用到一些技术和工具:
HTTP库:如requests(Python)、axios(JavaScript)等,用于发送HTTP请求,获取页面源代码。
HTML解析库:如BeautifulSoup(Python)、Cheerio(JavaScript)等,用于解析HTML并提取需要的信息。
正则表达式:用于匹配和提取特定模式的信息。
JavaScript执行环境:有些网站会通过JavaScript生成视频URL,需要用到像Puppeteer(JavaScript)、Selenium(Python)这样的工具来执行JavaScript代码。
下面是一个简单的Python代码示例,展示了如何解析视频页面并提取视频URL:
import requests
from bs4 import BeautifulSoup
import re
# 获取视频页面源代码
url = '视频页面URL'
response = requests.get(url)
html = response.text
# 解析页面源代码
soup = BeautifulSoup(html, 'html.parser')
# 找到视频标签或脚本标签中的视频URL
video_url = None
for script in soup.find_all('script'):
if 'video' in script.text:
# 假设视频URL在script标签的内容中,通过正则表达式提取
match = re.search(r'"videoUrl":"(http[^"]+)"', script.text)
if match:
video_url = match.group(1)
break
# 输出视频URL
if video_url:
print('Video URL:', video_url)
else:
print('Video URL not found')
这个示例展示了基本的原理,实际应用中可能需要处理更多的复杂情况,如页面动态加载、加密URL等。
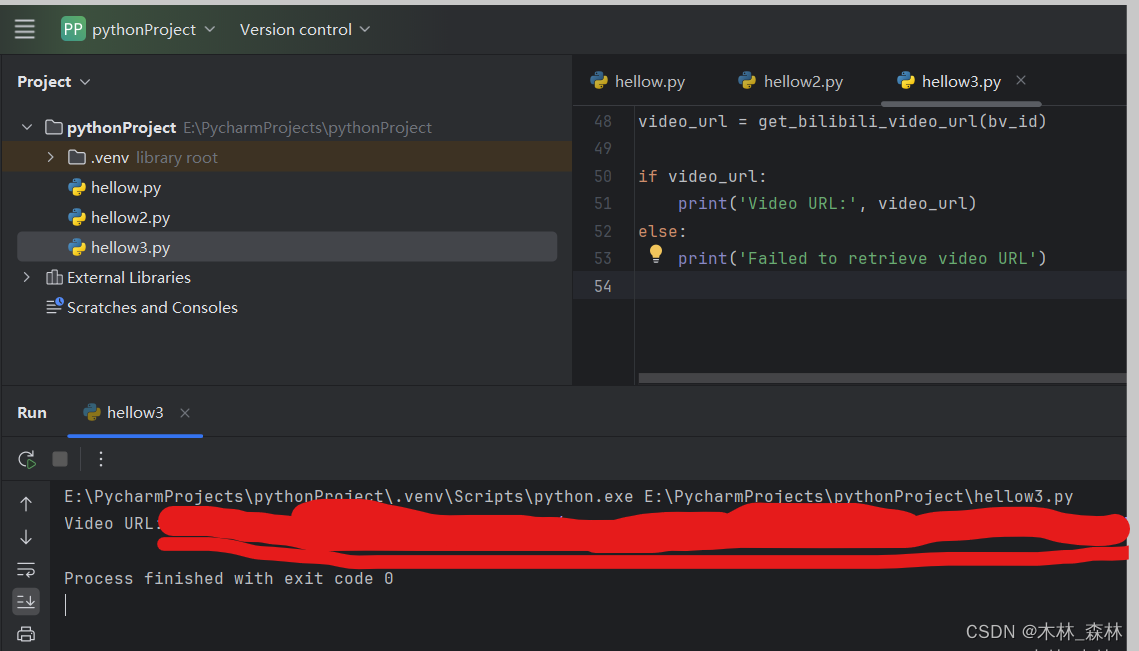
本人经过不断调试,上述代码的升级版已经可以实现根据哔哩哔哩视频链接解析出原视频,源代码注释清晰,只需要修改一处(取决于你想解析哪个视频)
本源代码效果(以此时B站热搜第一为例):
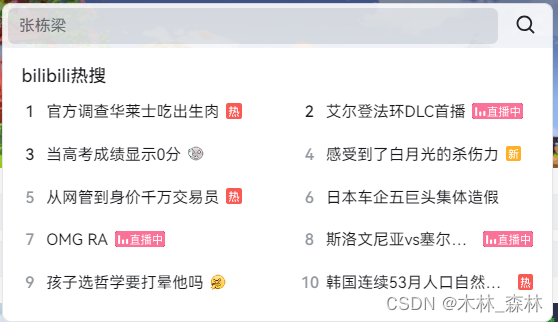
视频链接:https://www.bilibili.com/video/BV1ey411q7UE/?spm_id_from=333.337.search-card.all.click&vd_source=fc7e92b8ea5cfa8d6b60f51d83a80bf9
经过解析:
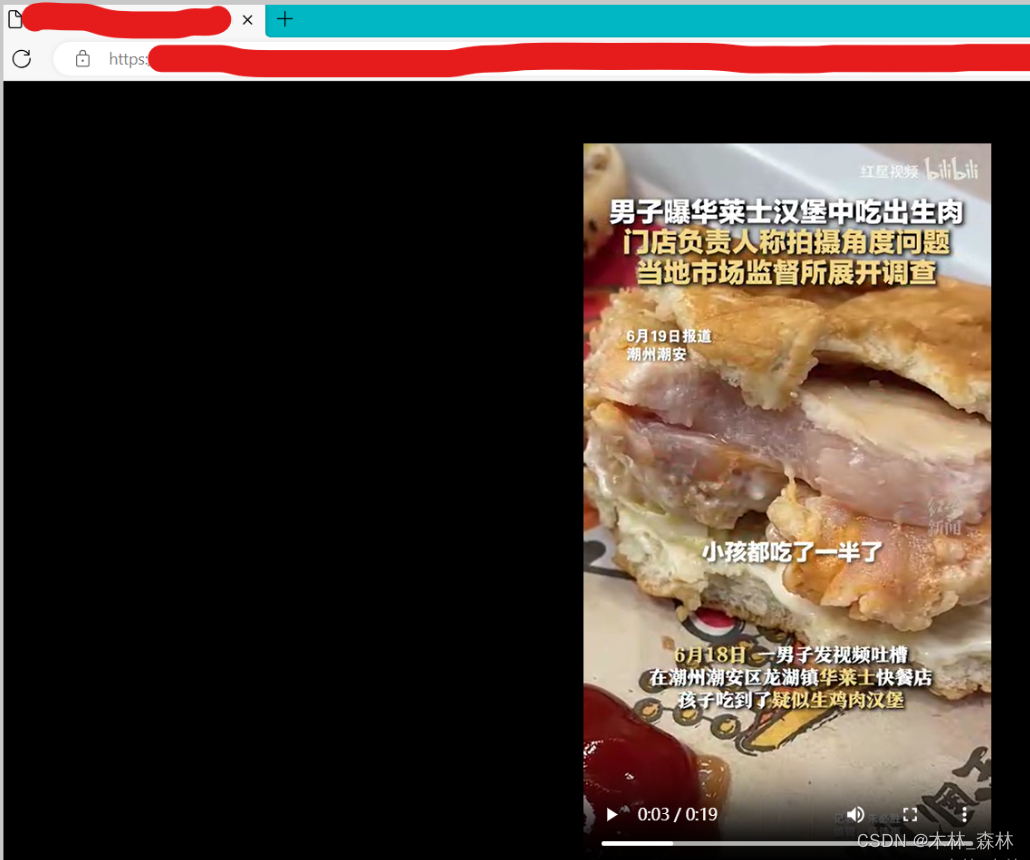
视频可下载


")



