
【LLM之KG】TOG论文阅读笔记


.png)

研究背景
本文针对大型语言模型(LLMs)在处理深度和负责任的推理任务时常见的幻觉问题进行研究,特别是在需要深层次逻辑链和多跳知识推理的场景中。为了解决这些问题,作者提出通过结合外部知识图谱(KGs)来增强LLMs的推理能力。
研究目标
研究的核心目标是开发一种新的算法框架“Think-on-Graph”(ToG),该框架通过在知识图谱上进行动态探索和推理,使LLMs能够进行更深入和负责任的推理。ToG框架的目标是提供一种灵活的、无需额外训练成本的解决方案,以提高模型在知识密集型任务中的表现。
相关工作
论文详细回顾了使用LLMs进行推理的现有方法,特别强调了链式思考(Chain-of-Thought)和自我一致性(Self-Consistency)等技术。此外,文章还探讨了知识图谱在增强LLMs推理能力方面的作用,分析了将KGs作为外部知识源用于减轻LLMs幻觉问题的各种方法。
方法论
数据处理
ToG开始于定义问题的初始实体,接着利用LLM对这些实体在KG中的相应三元组进行动态检索。这一过程涉及到从KG中提取与问题直接相关的信息,并构建可能的推理路径。举个例子:

解决方案
ToG采用了一个三阶段的推理框架:初始化、探索和推理。在初始化阶段,ToG识别问题中的关键实体并定位它们在KG中的位置。探索阶段通过beam search算法迭代地探索多个可能的推理路径。最后,在推理阶段,LLM评估当前的推理路径是否足够回答问题,如果不够则继续探索,直到找到满足条件的答案或达到搜索的最大深度。流程如下:

- 主题实体提取,使用LLM初始化实体提取,得到若干后续主题实体;
- 子图查询,包括关系查询和实体查询,先根据实体,查找其存在的关系,然后再根据关系,查询对应的实体;
- 关系裁剪,对于给定的实体,通过查询,可以得到多个路径(关系),需要对路径进行排序,在这里,利用大模型进行评估,通过prompt完成,如:请检索对问题有贡献的N个关系(用分号隔开),并按0到1的等级对其贡献进行评分(N个关系的分数总和为 1);
- 实体裁剪,让大模型用0至1分给各实体对问题的贡献打分(所有实体得分之和为1),用来做评分对比,也是通过prompt实现;
- 相关度判断,通过探索过程获得当前推理路径P后,会提示LLM评估当前推理路径是否足以生成答案。如果评估结果是肯定的,就提示LLM以查询为输入,使用推理路径生成答案。反之,如果评估结果为负,则重复探索和推理步骤,直到评估结果为正或达到最大搜索深度Dmax。如果算法尚未结束,则表明即使达到最大搜索深度Dmax,ToG仍无法探索出解决问题的推理路径。在这种情况下,ToG将完全根据LLM中的固有知识生成答案。这一目标,同样也是依赖prompt完成处理,思想在于:给定一个问题和相关的检索知识图谱三元组(实体、关系、实体),要求大模型回答用这些三元组和大模型知识是否足以回答这个问题(是或否);
- 生成结果,直接将检索到的文本加入到prompt中,送入大模型,完成答案生成。
同时,本文还提出了TOG的变体ToG-R,即“Think-on-Graph with Relation-based reasoning”(基于关系的思考图推理),专注于利用关系链进行推理。与基本的ToG框架主要通过实体和它们的三元组进行推理不同,ToG-R更加专注于利用从知识图谱(KG)中提取的关系来推动问题的解答。
ToG-R的优点:
- 效率:通过关注关系链而非多个实体间的复杂连接,ToG-R可以更快地导航知识图谱,减少了计算负荷。
- 专注性:这种方法使模型更专注于利用和分析那些直接与问题相关的知识,有助于提高答案的相关性和准确性。
- 简化的推理路径:关系链的使用简化了推理过程,使得从问题到答案的逻辑更加清晰,也便于解释和验证。
实验
实验处理
实验设计部分使用了多个KBQA数据集来评估ToG的性能,包括CWQ和WebQSP等。实验中,ToG与现有的基于提示的方法和微调方法进行了比较:

实验结论
- ToG在大多数数据集上都实现了新的最佳性能,特别是在多步骤推理任务上的表现优于其他所有方法。(注:IO指直接few-shot prompt提示,SC指Self-Consistency)
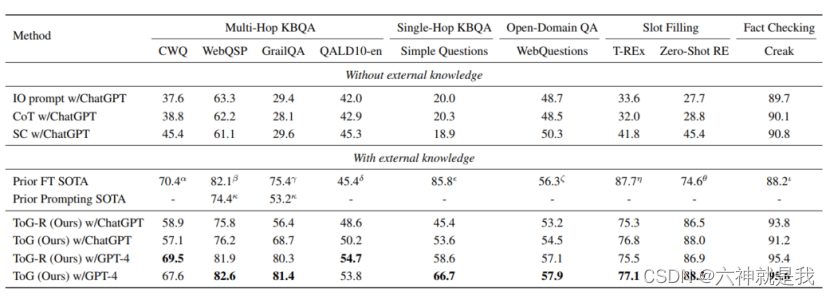
- 特定的知识图谱、搜索深度和宽度、以及prompt设计显著影响ToG的性能


- 些LLMs可能因为其语言理解能力或训练数据的差异而表现更好或更差
参考资料
- 论文
- 代码
- ToG在大多数数据集上都实现了新的最佳性能,特别是在多步骤推理任务上的表现优于其他所有方法。(注:IO指直接few-shot prompt提示,SC指Self-Consistency)


")



