
从零开始学数据结构系列之第三章《中序线索二叉树线索化及总代码》



文章目录
- 中序线索化
- 总代码
- 往期回顾
中序线索化

void inThreadTree(TreeNode* T, TreeNode** pre) { if(T) { inThreadTree(T->lchild,pre); if(T->lchild == NULL) { T->ltag = 1; T->lchild = *pre; } if(*pre != NULL && (*pre)->rchild == NULL) { (*pre)->rtag = 1; (*pre)->rchild = T; } *pre = T; inThreadTree(T -> rchild, pre); } } 你会发现,代码中除了if语句以外,和二叉树中序遍历的递归代码几乎一模一样。只不过是将打印的代码改为了线索化功能的代码。
i如果某结点的左指针域为空,因为其前驱结点刚刚访问过(如果是第一个元素则前驱指向NULL),赋值给了 pre,所以可以将pre赋值给pre->lchild,并修改pre->L为1,以完成前驱结点的线索化。

我们以这个来讲解代码:
void inThreadTree(TreeNode* T, TreeNode** pre) { if(T) { inThreadTree(T->lchild,pre); if(T->lchild == NULL) { T->ltag = 1; T->lchild = *pre; } if(*pre != NULL && (*pre)->rchild == NULL) { (*pre)->rtag = 1; (*pre)->rchild = T; } *pre = T; inThreadTree(T -> rchild, pre); } }首先:
if(T)
这一个是我们递归的重要部分,用来判断T是否有值,如果没有的话,跳出并返回上一级,防止无限递归

inThreadTree(T->lchild,pre);
之后,因为是中序遍历,要先找他的左子树,就开始一直递归他的左子树,直到找到他最后一项D,D后面因为都是空的了,所以不满足if(T)的条件,所以直接跳回上一级,继续向下执行
if(T->lchild == NULL) { T->ltag = 1; T->lchild = *pre; }因为D的左子树为空,所以标记他的 T->ltag 为1,同时将空着的左子树中的指针存放他的前驱*pre的值(注意,这里的pre是二级指针),一开始传进来的pre的值是NULL
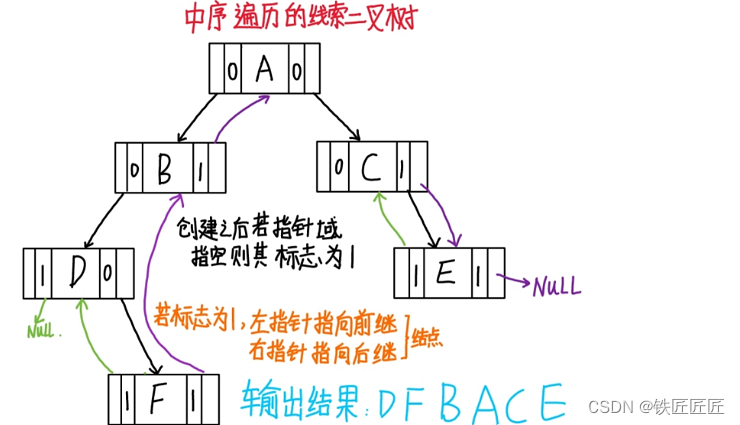
此时的图是这样子的

然后代码继续往下运行
if(*pre != NULL && (*pre)->rchild == NULL) { (*pre)->rtag = 1; (*pre)->rchild = T; }由于pre == NULL,则跳过,但是为什么要这样设计呢?
因为这是他的后继并没有访问到,我们这里的D他的后继是B,因此只能放后面进行处理,同时我们要满足*pre != NULL && (*pre)->rchild == NULL这两个条件才能执行
*pre = T; inThreadTree(T -> rchild, pre);
于是我们开始执行这两行代码,每处理一个节点 当前结点是下一个节点的前驱,所以*pre = T,这一个是我们从图中的出来的普遍规律

之后看D是否有右子树,但这里的D也是没有右子树,所以直接跳过,返回上一级,注意此时*pre 中的值是为节点D
此时上一级的T是B的节点,执行代码6-10行的时候,因为不满足条件直接跳过
注意此时满足11行的代码,所以将D的右子树后继赋值为B节点,同时rtag至1

于是将当前节点B再赋予给*pre节点
之后在递归进去B的右子树E
void inThreadTree(TreeNode* T, TreeNode** pre) { if(T) { inThreadTree(T->lchild,pre); if(T->lchild == NULL) { T->ltag = 1; T->lchild = *pre; } if(*pre != NULL && (*pre)->rchild == NULL) { (*pre)->rtag = 1; (*pre)->rchild = T; } *pre = T; inThreadTree(T -> rchild, pre); } } 此时是E的节点,因为左子树为空,所以E的前端为B(此时pre为B),而后面因为不满足条件直接跳过,来到代码的第16行,将pre赋值为E,之后返回上上级A

之后以相同的步骤执行
需要主要的是

我们这里的只有D,E,C,是空闲的,而A,B都是内部以存储完毕的。
所以我们一共有 10(2N)个节点
其中一共有 4(n-1)个节点 是已经存储了数据的
所以还剩下有 6(n+1)个节点 是为存储数据的
我们可以按下面的图来直观的感受到,牺牲空间来换取时间
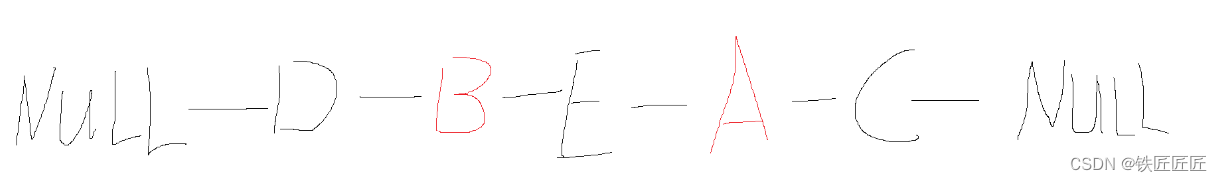
总代码
/*可以输入 ABD##E##CF##G## 来进行验证 */ #include #include #define size 20 typedef struct TreeNode { char data; struct TreeNode *lchild; struct TreeNode *rchild; int ltag; int rtag; }TreeNode; void createTree(TreeNode** T,char* temp,int* index) { char ch; ch = temp[*index]; (*index)++; if( ch == '#') *T = NULL; else { *T =(TreeNode*)malloc(sizeof(TreeNode)); (*T)->data = ch; (*T)->ltag = 0; (*T)->rtag = 0; createTree(&(*T)->lchild,temp,index); createTree(&(*T)->rchild,temp,index); } } void inThreadTree(TreeNode* T, TreeNode** pre) { if(T) { inThreadTree(T->lchild,pre); if(T->lchild == NULL) { T->ltag = 1; T->lchild = *pre; } if(*pre != NULL && (*pre)->rchild == NULL) { (*pre)->rtag = 1; (*pre)->rchild = T; } *pre = T; inThreadTree(T -> rchild, pre); } } /* 找到最左的节点数 */ TreeNode* getFirst(TreeNode* T) { while (T -> ltag == 0) T = T -> lchild; return T; } /* 按线索来查找 */ TreeNode* getNext(TreeNode* node) { if (node -> rtag == 1) return node -> rchild; else return getFirst(node -> rchild); } int main(int argc, char* argv[]) { TreeNode *T; TreeNode* pre = NULL; int i=0; char *temp=NULL; TreeNode* node = NULL; temp=(char*)malloc(sizeof(char) * (size+1)); gets(temp); createTree(&T,temp,&i); inThreadTree(T, &pre); // 注意,这时候要手动给C节点增加上NULL pre -> rtag = 1; pre -> rchild = NULL; node = getFirst(T); for (node; node != NULL; node = getNext(node)) { printf("%c ", node -> data); } printf("\n"); return 0; }
往期回顾
1.【第一章】《线性表与顺序表》
2.【第一章】《单链表》
3.【第一章】《单链表的介绍》
4.【第一章】《单链表的基本操作》
5.【第一章】《单链表循环》
6.【第一章】《双链表》
7.【第一章】《双链表循环》
8.【第二章】《栈》
9.【第二章】《队》
10.【第二章】《字符串暴力匹配》
11.【第二章】《字符串kmp匹配》
12.【第三章】《树的基础概念》
13.【第三章】《二叉树的存储结构》
14.【第三章】《二叉树链式结构及实现1》
15.【第三章】《二叉树链式结构及实现2》
16.【第三章】《二叉树链式结构及实现3》
17.【第三章】《二叉树链式结构及实现4》
18.【第三章】《二叉树链式结构及实现5》
19.【第三章】《中序线索二叉树理论部分》
20.【第三章】《中序线索二叉树代码初始化及创树》



