
python 邮箱自动化操作(1) 邮件的自动获取 imapclient 非常详细!有范例!!



版本
python 3.8
imapclient:3.0.0
注意: 这里是以腾讯企业邮箱为例,不同的邮箱可能会有不同的编码格式,就可能会产生错误。
邮件协议概述
-
SMTP (Simple Mail Transfer Protocol):
- SMTP 是用于发送电子邮件的标准协议。
- 客户端使用 SMTP 将邮件发送到邮件服务器。
- SMTP 客户端连接到 SMTP 服务器的 25 号端口。
- SMTP 协议通常用于将邮件从发送方传输到接收方的邮件服务器。
-
POP3 (Post Office Protocol version 3):
- POP3 是用于从邮件服务器上获取邮件的协议。
- 客户端使用 POP3 从邮件服务器下载邮件到本地计算机。
- POP3 客户端连接到 POP3 服务器的 110 号端口。
- POP3 协议通常会将邮件从服务器上下载到客户端,并在下载后从服务器上删除邮件。
-
IMAP (Internet Message Access Protocol):
- IMAP 也是用于从邮件服务器上获取邮件的协议,与 POP3 类似,但提供了更多的功能。
- IMAP 允许客户端在多个设备上同步查看邮件,因为邮件仍然保留在服务器上。
- IMAP 客户端连接到 IMAP 服务器的 143 号端口。
- IMAP 协议通常更适合需要在多个设备上访问邮件的用户,因为它允许在所有设备上同步邮件状态。
这里列举了三种协议,其中SMTP用于发送邮件,POP3和IMAP用于获取邮件,由于IMAP更强大,所有本文的邮件获取也是基于IMAP协议。
从邮箱获取邮件 (标题、内容、附件等)
python虽然自带imaplib这个包,但用起来比较复杂,所以在这一部分,本文使用imapclient,这是一个用于 IMAP 客户端的第三方库,提供了更高级的功能,例如搜索、标记、文件夹管理等,它比标准库中的 imaplib 更易于使用。
1. 邮箱登录
from imapclient import IMAPClient
# 邮箱登录
email_address = 'xxxx@xxxx.com' # 邮箱地址
password = 'xxxxxx' # 密码
# 邮箱服务器信息
s_mail = IMAPClient('imap.exmail.qq.com') # HOST = "imap.host.com"
s_mail.login(email_address, password)
2. 选择邮箱 select_folder
就是选择如下所示:

可以先查看邮箱文件夹
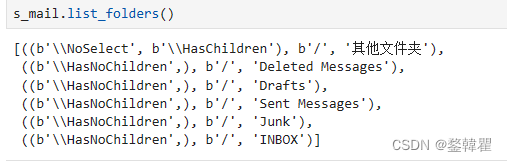
选择邮箱文件夹
# 选择邮箱 s_mail.select_folder(folder='inbox', readonly=True) # 这里folder也可以选择 已发送等
运行结果:
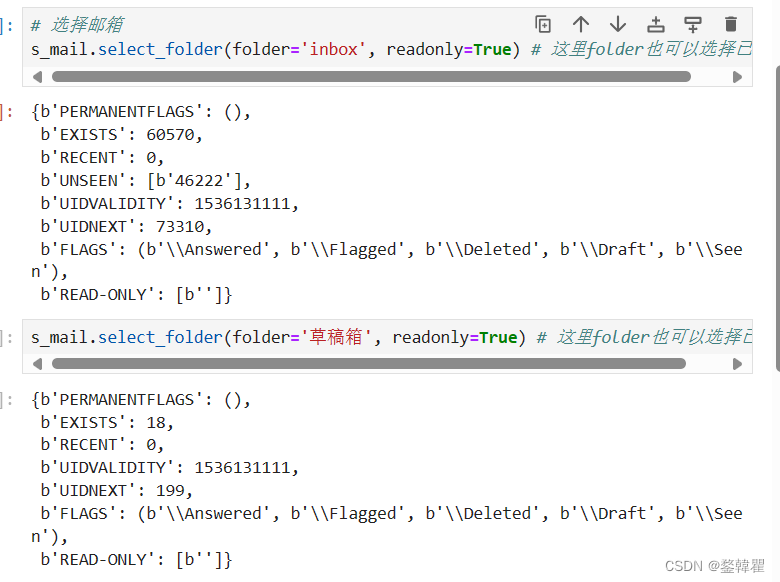
这里可以看到,选择不同邮箱会收到不同的返回结果,返回的结果是字典格式的,一般不会用到,这里也没有去赋值。
3. 邮件筛选 search
在选择好邮箱之后,比如收件箱,会拿到大量的邮件,search我看代码可以根据标题、正文、时间、标记(‘SEEN’, 'UNSEEN', 'Flagged')等,但是实际上无法通过标题和正文检索,我想可能原因是跟邮箱编码格式有关,这里我查了很多资料依旧没有解决,但是可以通过遍历邮件的方法实现。
通过时间区间筛选 这里的时间要转换为datetime的格式
# 从 20240101 这一天开始 message_ids = s_mail.search(['SINCE', datetime.date(2024, 1, 1)]) # 在 20240101 这一天之前 不包括20240101 message_ids = s_mail.search(['BEFORE', datetime.date(2024, 1, 1)]) # 在某个时间区间 since_date = datetime.datetime.strptime(search_date_since, '%Y%m%d') before_date = datetime.datetime.strptime(search_date_before, '%Y%m%d') message_ids = s_mail.search(['SINCE', since_date, 'BEFORE', before_date])
通过多个条件筛选 比如在上面的基础上加一个 “未读”
message_ids = s_mail.search(['SINCE', since_date, 'BEFORE', before_date, 'UNSEEN'])
4. 获取邮件数据 fetch
通过 fetch 方法,可以获取邮件的各种信息,如邮件的正文、发件人、收件人、主题、日期等。
以下是 imapclient 中 fetch 方法的一般用法:
fetch_data = s_mail.fetch(message_ids, ['BODY[]', 'FLAGS', 'INTERNALDATE', 'RFC822.SIZE'])
这里的 message_ids 是一个邮件的序号或 UID 列表,用于指定要检索的邮件。第二个参数是一个列表,包含了你想要检索的邮件属性。常见的邮件属性包括:
- 'BODY[]': 获取邮件的全部内容,包括头部和正文。
- 'FLAGS': 获取邮件的标志,如已读、已删除等。
- 'INTERNALDATE': 获取邮件的内部日期,即邮件的收到时间。
- 'RFC822.SIZE': 获取邮件的大小。
除了以上列出的属性外,还可以指定其他属性,如 'BODY[HEADER]'(获取邮件的头部)、'ENVELOPE'(获取邮件的信封信息,如发件人、收件人、主题等)等。这里的细则可以查看这篇文章python imap fetch的坑
 http://t.csdnimg.cn/qdtYV
http://t.csdnimg.cn/qdtYV一般在使用的时候,可以根据需求选择属性,这样获取的数据量会小一点,速度会更快。
这里以‘BODY[]’举例,目的是介绍获取邮件全部内容后,如何获取邮件中各个属性的信息。
通过fetch(message_ids, ['BODY[]']) 获得是一个字典的格式,可以自行输出查看一下。
数据解析方法:
4.1 获取邮件头部信息
content = s_mail.fetch(uid, ['BODY[]'])[uid][b'BODY[]'] email_content = email.message_from_bytes(content) # 第一种 解析 邮件头部信息 # 像 收件人、发件人、抄送、标题等 这些都是同样的方式 所以以其中一种举例 # 定义解码函数 (这个) def __decode_str__(hs): """ 编码处理 :param hs: :return: """ if isinstance(hs, bytes): hs = hs.decode() if hs: # loger.info(" ==== {}".format(hs[0])) if hs[0] == "=": s, de = decode_header(hs)[0] # s is bytes de='gbk' failout = base64.b64encode(s).decode() s = failout if not de else s.decode(de) # str(s, 'gbk') = s.decode('gbk') return s else: return hs return '' # 获取标题 subject = __decode_str__(email_content['Subject']) ''' 以下都可以通过上述方式获得 邮件头部信息: Subject:邮件主题 From:发件人 To:收件人 Date:日期时间 Cc:抄送 Bcc:暗送 Message-ID:消息唯一标识符 In-Reply-To:回复邮件的消息标识符 References:参考消息标识符列表 '''4.2 获取邮件正文
envelope = s_mail.fetch(uid, ['BODY[]'])[uid][b'BODY[]'] email_content = email.message_from_bytes(content) # 提取邮件正文内容 if email_content.is_multipart(): for part in email_content.walk(): content_type = part.get_content_type() if content_type == 'text/plain': # 只提取纯文本正文 body = part.get_payload(decode=True).decode('gbk') print("邮件正文内容:") print(body) break else: body = email_content.get_payload(decode=True).decode('gbk') print("邮件正文内容:") print(body)4.3 获取邮件附件
for part in email_content.walk(): fileName = part.get_filename() fileName = __decode_str__(fileName) print(fileName) # 附件下载 for part in email_content.walk(): fileName = part.get_filename() fileName = __decode_str__(fileName) if fileName: with open(fileName, 'wb') as f: data = part.get_payload(decode=True) f.write(data)邮件检索 (遍历)
上述三种方法没有办法直接获取目标邮件的指定信息的功能,由1select_flod,2search两种方法,我们也只可以获得一个范围,在search函数中,可以看到subject字段,但是可能由于邮箱的问题,没有达到通过标题筛选的效果。所以邮件检索的方法,可以理解为在一个范围内遍历邮箱。
当邮箱邮件数很多的时候,这个找到目标邮件的方法会很慢,这里有一个小技巧,就是比如通过标题找到目标邮件时,可以在fetch中选择 'BODY[HEADER]',这样数据量相对较小,速度会稍微快一点。
以下是一个范例 (可以直接使用)
获取一个时间区间内的所有邮件,然后通过标题筛选,再拿到目标附件。
search_data_since、search_date_before: 字符串 like:'20240101'
def get_excel_from_mail(search_date_since, search_date_before, target_subject, target_filename): # 邮箱登录 print("email login...") email_address = 'xxx@xxx.com' password = 'xxxxxxx' # 邮箱服务器信息 # 搜索邮件 s_mail = IMAPClient('imap.exmail.qq.com') s_mail.login(email_address, password) s_mail.select_folder('收件箱', readonly=True) since_date = datetime.datetime.strptime(search_date_since, '%Y%m%d').date() # 指定日期范围为since_date到since_date的后一天 next_day = datetime.datetime.strptime(search_date_before, '%Y%m%d').date() result = s_mail.search(['SINCE', since_date, 'BEFORE', next_day]) print('SINCE', since_date, 'BEFORE', next_day) for uid in reversed(result): # 优先获取最新的邮件 try: subject = s_mail.fetch(uid, ['ENVELOPE'])[uid][b'ENVELOPE'] subject = __decode_str__(subject.subject) print(subject) if target_subject not in str(subject): continue except Exception as e: print(e) # print(s_mail.fetch(uid, ['ENVELOPE'])) continue massageList = s_mail.fetch(uid, ['BODY[]']) mailBody = massageList[uid][b'BODY[]'] # 邮件内容解析最里面那层是按字节来解析邮件主题内容,这个过程生成Message类型 try: email_content = email.message_from_string(mailBody) except TypeError: email_content = email.message_from_bytes(mailBody) for part in email_content.walk(): fileName = part.get_filename() fileName = __decode_str__(fileName) # print('fileName', fileName) if fileName == target_filename: print(' OK Subject = {}'.format(subject)) print('邮件附件下载') # 附件下载 for part in email_content.walk(): fileName = part.get_filename() fileName = __decode_str__(fileName) if fileName == target_filename: # savefile = os.path.join(dirs_email, fileName) # with open(savefile, 'wb') as f: # print('--------savefile') data = part.get_payload(decode=True) # 获取excel内容 保存文件 ----- # f.write(data) return data return False def __decode_str__(hs): """ 编码处理 :param hs: :return: """ if isinstance(hs, bytes): hs = hs.decode() if hs: # loger.info(" ==== {}".format(hs[0])) if hs[0] == "=": s, de = decode_header(hs)[0] # s is bytes de='gbk' failout = base64.b64encode(s).decode() s = failout if not de else s.decode(de) # str(s, 'gbk') = s.decode('gbk') return s else: return hs return ''



