
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用



博客导读:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
目录
一、引言
二、LLaMA-Factory项目介绍
2.1 项目特色
2.2性能指标
2.3支持模型
2.4训练方法
2.5硬件依赖
三、LLaMA-Factory项目安装、部署
3.1 拉取项目代码
3.2 项目目录结构
3.3 Dockerfile适配国内网络环境
3.4 docker-compose.yml适配国内网络环境
3.5 docker compose方式启动
四、LLaMA-Factory项目微调训练
4.1 大模型微调训练-Train(训练)
4.2 大模型微调训练-Evaluate&Predict(评估&预测)
4.3 大模型微调训练-Chat(对话)
4.4 大模型微调训练-Export(导出)
五、总结
一、引言
贫富差距的产生是信息差,技术贫富差距的产生亦如此。如果可以自我发现或者在别人的指导下发现优秀的开源项目,学习或工作效率真的可以事半功倍。
今天力荐的项目是LLaMA-Factory,我在去年8月份就开始使用这个项目进行模型部署和微调训练(fine tune),当时各家大模型仅限于推理测试,OpenAI还没有对外提供微调服务,加上这个项目部署丝滑(更新及时,不会出现环境依赖问题,代码逻辑上几乎无错误),觉得好牛啊。现在来看项目已经达到22K星,果然酒深不怕巷子香。
本文的核心价值在于适配国内网络环境:官方文档是以国际hugging face库为示例,本篇文章以国内modelscope库为示例。让国内网络环境用户进行大模型微调训练更加丝滑。
二、LLaMA-Factory项目介绍
2.1 项目特色
- 多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
- 集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练和 ORPO 训练。
- 多种精度:32 比特全参数微调、16 比特冻结微调、16 比特 LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8 的 2/4/8 比特 QLoRA 微调。
- 先进算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 Agent 微调。
- 实用技巧:FlashAttention-2、Unsloth、RoPE scaling、NEFTune 和 rsLoRA。
- 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
- 极速推理:基于 vLLM 的 OpenAI 风格 API、浏览器界面和命令行接口。
2.2性能指标
与 ChatGLM 官方的 P-Tuning 微调相比,LLaMA Factory 的 LoRA 微调提供了 3.7 倍的加速比,同时在广告文案生成任务上取得了更高的 Rouge 分数。结合 4 比特量化技术,LLaMA Factory 的 QLoRA 微调进一步降低了 GPU 显存消耗。
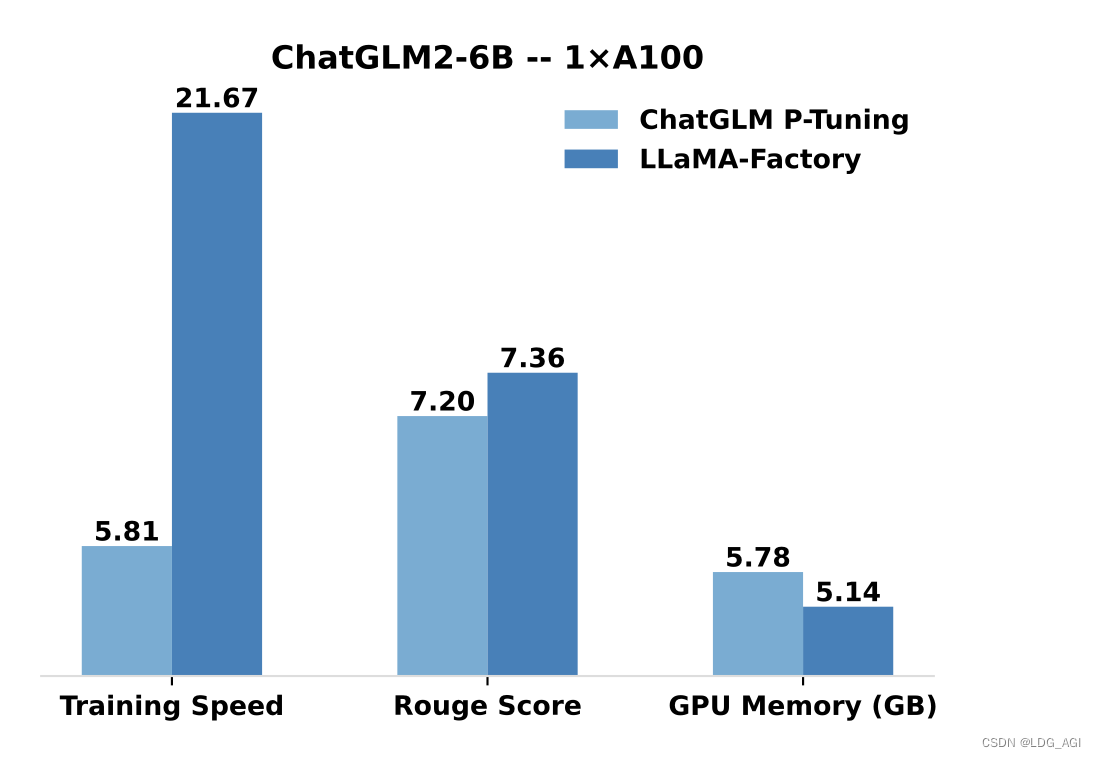
- Training Speed: 训练阶段每秒处理的样本数量。(批处理大小=4,截断长度=1024)
- Rouge Score: 广告文案生成任务验证集上的 Rouge-2 分数。(批处理大小=4,截断长度=1024)
- GPU Memory: 4 比特量化训练的 GPU 显存峰值。(批处理大小=1,截断长度=1024)
- 我们在 ChatGLM 的 P-Tuning 中采用 pre_seq_len=128,在 LLaMA Factory 的 LoRA 微调中采用 lora_rank=32。
2.3支持模型
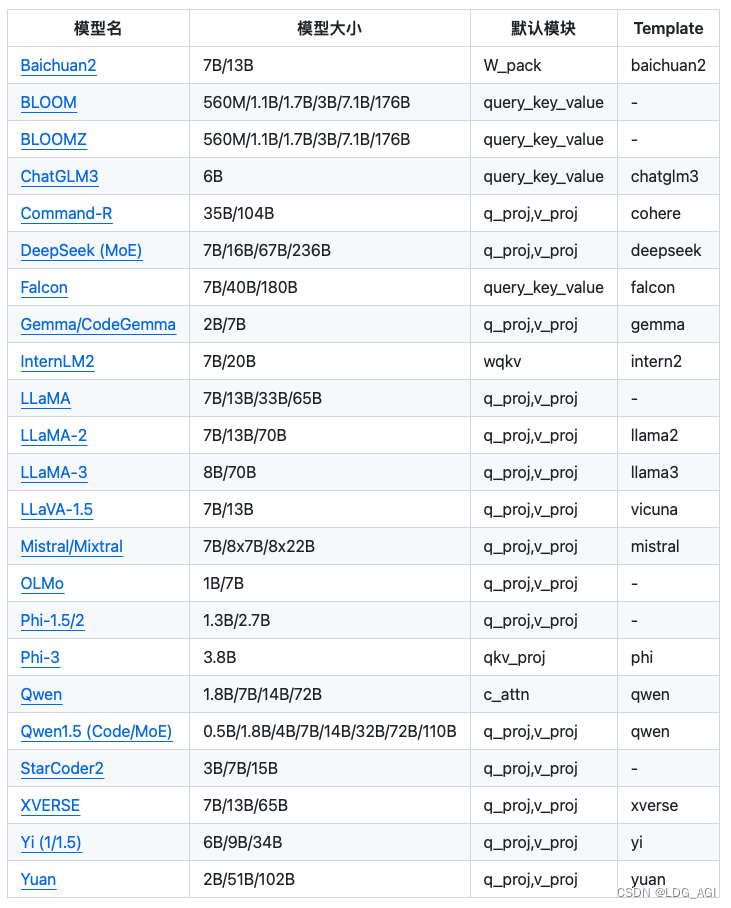
- 默认模块应作为 --lora_target 参数的默认值,可使用 --lora_target all 参数指定全部模块以取得更好的效果。
- 对于所有“基座”(Base)模型,--template 参数可以是 default, alpaca, vicuna 等任意值。但“对话”(Instruct/Chat)模型请务必使用对应的模板。
- 请务必在训练和推理时使用完全一致的模板。
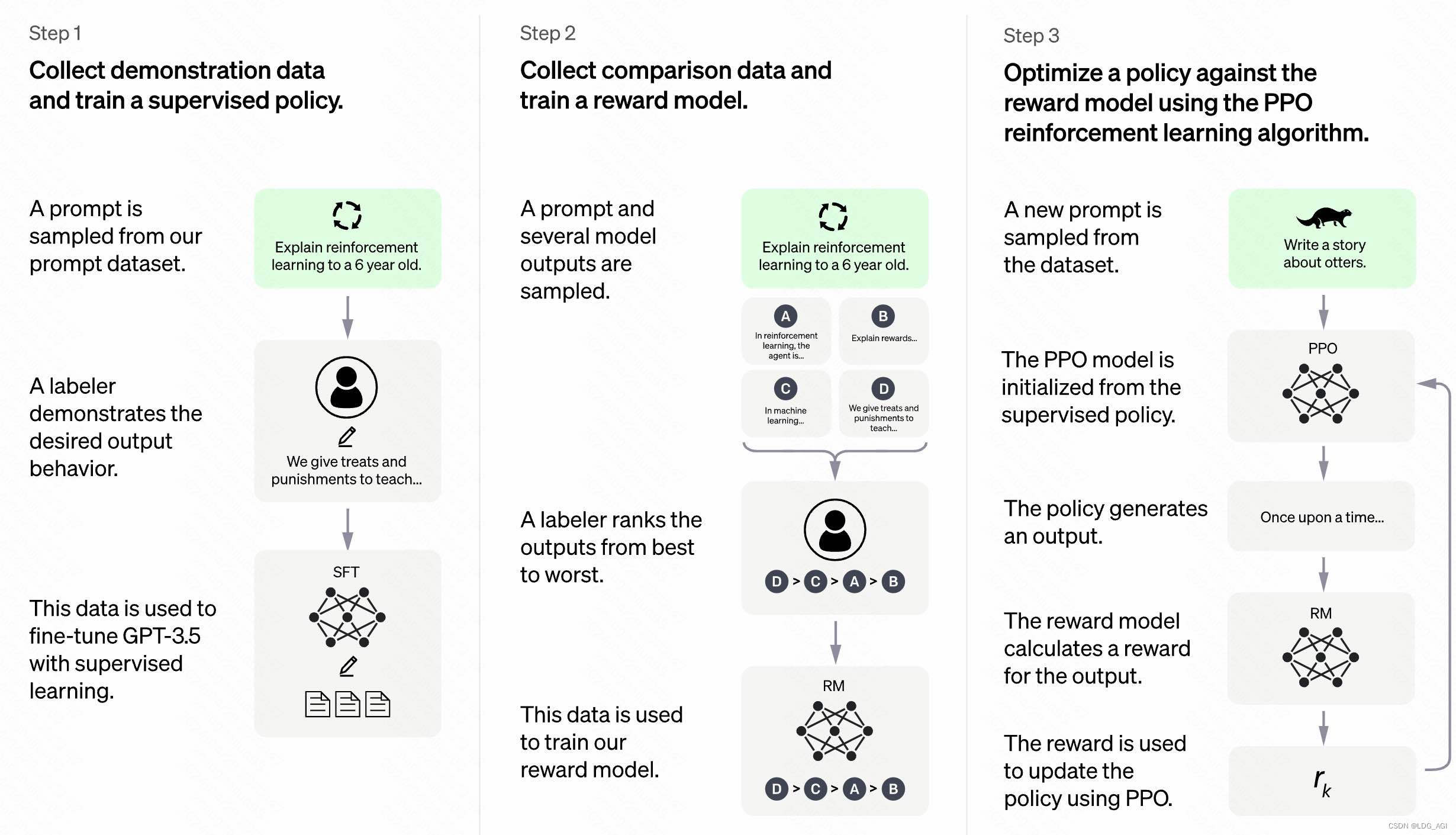
2.4训练方法
这里特别说一下,本框架不仅支持预训练(Pre-Training)、指令监督微调训练(Supervised Fine-Tuning),还是支持奖励模型训练(Reward Modeling)、PPO、DPO、ORPO等强化学习训练

各训练阶段的含义参考此图:
2.5硬件依赖
不同尺寸的模型,不同训练方式,所需GPU显存见下表,在工作中经常被问到需要多少资源,建议收藏

三、LLaMA-Factory项目安装、部署
这里建议使用docker compose部署,conda及docker部署方式见项目文档。
3.1 拉取项目代码
git clone https://github.com/hiyouga/LLaMA-Factory.git
3.2 项目目录结构
[root@localhost LLaMA-Factory]# tree -d . ├── assets ├── data //训练数据放在这,里面有配置文件可以新增自己的数据 │ ├── belle_multiturn │ ├── example_dataset │ ├── hh_rlhf_en │ ├── mllm_demo_data │ └── ultra_chat ├── evaluation //评测脚本在这里 │ ├── ceval │ ├── cmmlu │ └── mmlu ├── examples //各种推理、训练的配置文件在这里(以前还是shell脚本,现在是配置文件了) │ ├── accelerate │ ├── deepspeed │ ├── extras │ │ ├── badam │ │ ├── fsdp_qlora │ │ ├── galore │ │ ├── llama_pro │ │ ├── loraplus │ │ └── mod │ ├── full_multi_gpu │ ├── inference │ ├── lora_multi_gpu │ ├── lora_single_gpu │ ├── merge_lora │ └── qlora_single_gpu ├── hf_cache //docker镜像中关联的huggingface目录,存储从hf库下载的模型,本文不用 ├── ms_cache //docker镜像中关联的modelscope目录,存储从ms库下载的模型,本文用这个 │ └── hub │ ├── baichuan-inc │ │ └── Baichuan2-7B-Chat //现在了百川2-7B举例 │ └── temp ├── output //训练输出的ckpt模型数据在这里 ├── scripts //训练代码依赖的脚本 ├── src //核心目录,源代码在这里 │ └── llmtuner │ ├── api │ ├── chat │ ├── data │ ├── eval │ ├── extras │ ├── hparams │ ├── model │ │ └── utils │ ├── train │ │ ├── dpo │ │ ├── orpo │ │ ├── ppo │ │ ├── pt │ │ ├── rm │ │ └── sft │ └── webui │ └── components └── tests //测试代码 55 directories
3.3 Dockerfile适配国内网络环境
[root@localhost LLaMA-Factory]# vim Dockerfile FROM nvcr.io/nvidia/pytorch:24.01-py3 WORKDIR /app COPY requirements.txt /app/ RUN pip install -r requirements.txt -i https://mirrors.cloud.tencent.com/pypi/simple #修改点1:在官方代码中加入腾讯pip镜像,否则默认镜像拉取依赖包极慢 COPY . /app/ RUN pip install -e .[deepspeed,metrics,bitsandbytes,qwen,modelscope] -i https://mirrors.cloud.tencent.com/pypi/simple #修改点2:同上,在官方代码中加入腾讯pip镜像,否则默认镜像拉取依赖包极慢 #修改点3:在可选依赖包内加入modelscope,这样就可以下载modelscope的模型了 VOLUME [ "/root/.cache/modelscope/", "/app/data", "/app/output" ] #修改点4:匿名卷中,将/root/.cache/huggingface/改为/root/.cache/modelscope/ #小知识:docker run -v与Dockerfile中VOLUME的区别: #VOLUME主要用于具有数据存储需求的Dockerfile中,以免用户docker run忘记指定-v导致容器删除后,造成的数据丢失,这个项目要存储模型、训练数据、训练输出的模型数据,所以分别建立这3个匿名卷 #如果没有-v指定,默认存储在/var/lib/docker/volumes/{容器ID}中,如果-v指定,则存储在指定目录中 EXPOSE 7860 #默认指定监听的端口 CMD [ "llamafactory-cli", "webui" ] #镜像模型启动模型为webui,我觉得也可以改为train、chat、expose、api,还没试。3.4 docker-compose.yml适配国内网络环境
[root@localhost LLaMA-Factory]# vim docker-compose.yml version: '3.8' services: llama-factory: build: dockerfile: Dockerfile context: . container_name: llama_factory volumes: - ./ms_cache:/root/.cache/modelscope/ #修改点1:将./ms_cache:/root/.cache/huggingface/修改为./ms_cache:/root/.cache/modelscope/,使用Dockerfile里建立的modelscope挂载点 - ./data:/app/data - ./output:/app/output environment: - CUDA_VISIBLE_DEVICES=1 #修改点2:nvidia-smi看看服务器哪张卡显存充足,指定为对应的显卡,目前webui仅支持单卡,多卡训练请使用命令行。 - USE_MODELSCOPE_HUB=1 #修改点3:环境变量中加入USE_MODELSCOPE_HUB=1,采用从modelscope库中下载模型 ports: - "7860:7860" ipc: host deploy: resources: reservations: devices: - driver: nvidia count: "all" capabilities: [gpu] restart: unless-stopped3.5 docker compose方式启动
修改完Dockerfile和docker-compose.yml之后,就可以打本地镜像启动啦,期待您一遍过~
docker compose -f ./docker-compose.yml up -d # -f 指定docker-compose.yml # -d 后台运行,可以使用docker logs llama_factory -f --tail 100查看启动日志
如果启动没问题,在浏览器输入宿主机ip+7860(如123.123.123.123:7860)进入webui界面,恭喜!

四、LLaMA-Factory项目微调训练
终于来到我们最喜欢的炼丹环节!开发工作中,搭环境永远是最麻烦的,雨过天晴,让我们一起训练大模型吧!
4.1 大模型微调训练-Train(训练)
根据WebUI逐个勾选参数,点击预览命令便会生成后台执行的命令,这个命令可以保存下来,以命令行方式运行也是可以的,点击开始进行训练,下面参照命令说明每个参数的意义。

CUDA_VISIBLE_DEVICES=1 llamafactory-cli train \ --stage sft \ #指定sft微调训练,可选rm,dpo等 --do_train True \ #训练是do_train,预测是do_predict --model_name_or_path baichuan-inc/Baichuan2-7B-Chat \ #模型目录,如果网络不行,可以配置本地目录,但今天的modelscope教程已经解决这个问题 --finetuning_type lora \ #训练类型为lora,也可以进行full和freeze训练 --quantization_bit 4 \ #量化精度,4bit,可选8bit和none不量化 --template baichuan2 \ #模版,每个模型要选对应的模版,对应关系见上文 --flash_attn auto \ #flash attention,闪光注意力机制,一种加速注意力计算的方法,后面会专门写一篇,baichuan2暂不支持,这里选auto,对于支持的模型可以选择fa2 --dataset_dir data \ #数据目录 --dataset oaast_sft_zh \ #数据集,可以通过更改dataset_info.json文件配置自己的数据集 --cutoff_len 1024 \ #截断长度 --learning_rate 5e-05 \ #学习率,AdamW优化器的初始学习率 --num_train_epochs 20.0 \ #训练轮数,需要执行的训练总轮数 --max_samples 100000 \ #最大样本数,每个数据集的最大样本数 --per_device_train_batch_size 1 \ #批处理大小,每个GPU处理的样本数量,推荐为1 --gradient_accumulation_steps 1 \ #梯度累积,梯度累积的步数,推荐为1 --lr_scheduler_type cosine \ #学习率调节器,可选line,constant等多种 --max_grad_norm 1.0 \ #最大梯度范数,用于梯度裁剪的范数 --logging_steps 100 \ #日志间隔,每两次日志输出间的更新步数 --save_steps 5000 \ #保存间隔,每两次断点保存间的更新步数。 --warmup_steps 0.1 \ #预热步数,学习率预热采用的步数。 --optim adamw_torch \ #优化器,使用的优化器:adamw_torch、adamw_8bit 或 adafactor --packing False \ --report_to none \ --output_dir saves/Baichuan2-7B-Chat/lora/train_2024-05-13-06-18-23 \ #数据目录 --fp16 True \ #计算类型,可以fp16、bf16等 --lora_rank 32 \ #LoRA秩,LoRA矩阵的秩大小,越大精度越高,推荐32 --lora_alpha 16 \ #LoRA 缩放系数 --lora_dropout 0 \ --lora_target W_pack \ #模型对应的模块,具体对应关系见上文 --val_size 0.1 \ --evaluation_strategy steps \ --eval_steps 5000 \ --per_device_eval_batch_size 1 \ --load_best_model_at_end True \ --plot_loss True项目经过长时间的积淀,支持的功能非常全面,写了一些Lora的参数说明,后面还有RLHF、GeLore参数说明,BAdam参数说明,文章会逐渐补全,对于重点微调技术,后面会单独开文章讲解。
4.2 大模型微调训练-Evaluate&Predict(评估&预测)
评估&预测模块,针对微调完成的模型进行评估。

根据勾选参数预测&评估的命令如下,多数都好理解,不再赘述
CUDA_VISIBLE_DEVICES=1 llamafactory-cli train \ --stage sft \ --model_name_or_path baichuan-inc/Baichuan2-7B-Chat \ --finetuning_type lora \ --quantization_bit 4 \ --template baichuan2 \ --flash_attn auto \ --dataset_dir data \ --dataset oaast_sft_zh \ --cutoff_len 1024 \ --max_samples 100000 \ --per_device_eval_batch_size 2 \ --predict_with_generate True \ --max_new_tokens 512 \ --top_p 0.7 \ --temperature 0.95 \ --output_dir saves/Baichuan2-7B-Chat/lora/eval_2024-05-13-06-18-23 \ --do_predict True执行成功后,可以看到进度条。

4.3 大模型微调训练-Chat(对话)
在训练、评估之后,可以进行Chat测试,如果配置了微调后的适配器路径,就会将基座模型与微调模型合并在一起进行测试,如果不配置适配器路径,只对基座模型进行测试。

推理引擎默认为huggingface,可以选择vllm进行加速。
4.4 大模型微调训练-Export(导出)
模型导出,可将基座模型与微调后的模型合并到出,一键完成。

五、总结
本文先对LLaMA-Factory项目进行介绍,之后逐行详细介绍了该项目在国内网络环境下如何安装、部署,最后以Baichuan2-7B为例,通过讲解训练参数的方式详细介绍了基于LLaMA-Factory WebUI的大模型微调训练。篇幅有限,专栏内会持续更新,详细介绍大模型微调训练方法。如果觉得对你有帮助,期待您的关注,点赞、收藏或评论,您的支持是我持续码字的动力。
如果不过瘾,还可以接着看看我的其他文章:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战







