Flink作业执行之 2.算子 StreamOperator
Flink作业执行之 2.算子 StreamOperator
前文介绍了Transformation创建过程,大多数情况下通过UDF完成DataStream转换中,生成的Transformation实例中,核心逻辑是封装了SimpleOperatorFactory实例。
UDF场景下,DataStream到Transformationg过程中,SimpleOperatorFactory实例的创建过程大致如下伪代码所示。
// 具体的函数实例 Function function = ; // 将函数实例封装到算子实例中 AbstractUdfStreamOperator operator = new AbstractUdfStreamOperator(function); // 通过算子实例得到其SimpleOperatorFactory实例 SimpleOperatorFactory factory = SimpleOperatorFactory.of(operator)
这里的UDF可以简单理解为需要我们自己传入对应Function实现类的操作,如map、filter等。
问题:
StreamOperator是什么?
为什么需要将Function封装到StreamOperator中?
1. Flink算子
在应用程序中通过各种各样的Function完成DataStream转换,但是Function仅表示数据处理逻辑,并不关心数据从哪里来到哪里去。
以MapFunction为例,map方法中仅包含对每一条到来数据的具体处理逻辑,并不清楚map方法何时被调用,结果返回到哪。
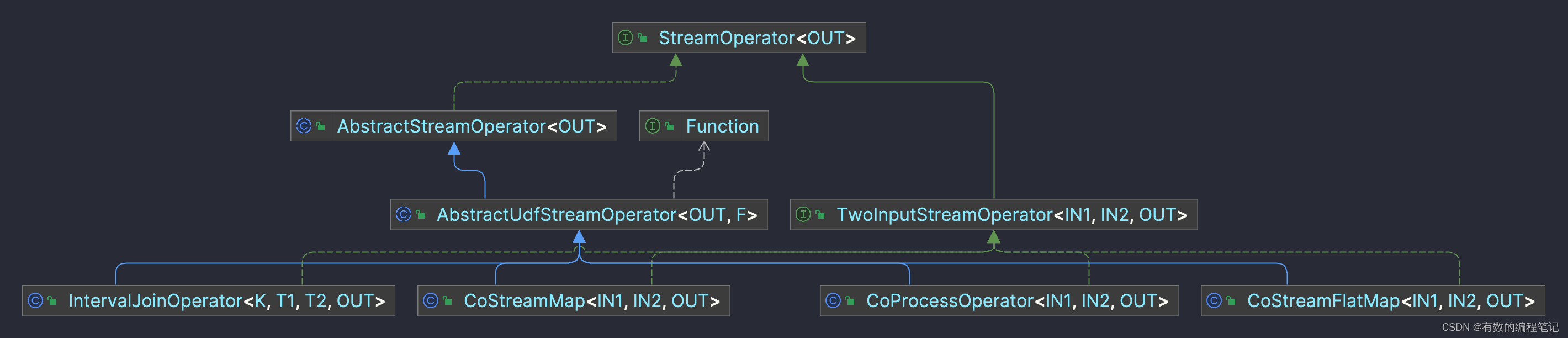
一个完整的数据处理逻辑应该是获取数据->处理数据->输出数据,在Flink中这个最小的完整逻辑通过算子表示,顶层抽象接口为StreamOperator。
因此Function作为算子的一部分参与后续的数据加工。
算子包含生命周期、状态和容错管理、数据处理3个方面。设计时分为两条线:
- 生命周期、状态和容错管理,主要是AbstractStreamOperator抽象类及其子类实现,以及未来的AbstractStreamOperatorV2抽象类。
- 数据处理,主要是OneInputStreamOperator、TwoInputStreamOperator和MultipleInputStreamOperator接口,分别表示单流、双流和多流的数据处理。在接口中定义了数据的处理方法。
StreamOperator完整的顶层抽象如下。
- AbstractStreamOperator,所有流运算的基类。提供了生命周期和属性方法的默认实现。
包含UDF的算子需继承其AbstractUdfStreamOperator子类
对于其具体实现,还必须实现OneInputStreamOperator或TwoInputStreamOperator其中一个。
将来将会使用AbstractStreamOperatorV2替换该基类
- OneInputStreamOperator,支持单流输入的运算符接口,如果要实现自定义运算符,需要使用AbatractUdfStreamOperator作为基类
- TwoInputStreamOperator,支持双流输入的运算符基类。同样需要和AbstractStreamOperator一起使用。
- AbstractStreamOperatorV2,所有流运算符的新基类,旨在取代AbatractUdfStreamOperator。
当前仅仅用于和MultipleInputStreamOperator一起配合使用。
OneInputStreamOperator、TwoInputStreamOperator和MultipleInputStreamOperator分别对应了Tranformation实现类的OneInputTransformation、TwoInputTransformation和AbstractMultipleInputTransformation。
MultipleInputStreamOperator和AbstractStreamOperatorV2是高版本中才加入的。因此,flink中最初仅支持单流或双流的输入,多流场景下需要拆分成单流或双流进行处理。在支持不同输入的流的实现中,梳理数据的方法分别如下
// 单流输入 public interface OneInputStreamOperator extends StreamOperator, Input { // 处理数据 void processElement(StreamRecord element) throws Exception; } // 双流输入 public interface TwoInputStreamOperator extends StreamOperator { // 处理双流输入中第一个流上的元素 void processElement1(StreamRecord element) throws Exception; // 处理双流输入中第二个流上的元素 void processElement2(StreamRecord element) throws Exception; } // 多流输入,这里的Input和单流输入继承的Input父类为同一个 public interface MultipleInputStreamOperator extends StreamOperator { List getInputs(); }在AbstractStreamOperator众多子类中,AbstractUdfStreamOperator抽象类中封装了Function接口,并且其中open、close等算子生命周期等方法,实际上就是调用Function实例的对应方法。
public abstract class AbstractUdfStreamOperator extends AbstractStreamOperator implements OutputTypeConfigurable { // 封装Function protected final F userFunction; // 通过Function实现进行算子的实例化 public AbstractUdfStreamOperator(F userFunction) { this.userFunction = requireNonNull(userFunction); checkUdfCheckpointingPreconditions(); } // 算子生命周期的相关方法,实际上调用Function的方法 @Override public void open() throws Exception { super.open(); FunctionUtils.openFunction(userFunction, new Configuration()); } @Override public void finish() throws Exception { super.finish(); if (userFunction instanceof SinkFunction) { ((SinkFunction) userFunction).finish(); } } @Override public void close() throws Exception { super.close(); FunctionUtils.closeFunction(userFunction); } }常用的实现类基本继承自AbstractUdfStreamOperator抽象类。
单流输入,如map、fliter、source、sink等实现类
sink算子有两个实现类,分别是SinkOperator和StreamSink。二者的关系为SinkOperator是StreamSink的特例。
双流输入,如concat、intervalJoin等实现类
本文开头提到通过SimpleOperatorFactory.of方式生成SimpleOperatorFactory实例,该方法如下
public static SimpleOperatorFactory of(StreamOperator operator) { if (operator == null) { return null; } else if (operator instanceof StreamSource && ((StreamSource) operator).getUserFunction() instanceof InputFormatSourceFunction) { // 通过addSoure方法添加的Source方式,且SourceFunction为InputFormatSourceFunction的子类 return new SimpleInputFormatOperatorFactory((StreamSource) operator); } else if (operator instanceof StreamSink && ((StreamSink) operator).getUserFunction() instanceof OutputFormatSinkFunction) { // 通过addSink方法添加的sink方式,且SinkFunction为OutputFormatSinkFunction的子类 return new SimpleOutputFormatOperatorFactory((StreamSink) operator); } else if (operator instanceof AbstractUdfStreamOperator) { return new SimpleUdfStreamOperatorFactory((AbstractUdfStreamOperator) operator); } else { return new SimpleOperatorFactory(operator); } }得到SimpleOperatorFactory实例后,在实际执行时,通过其createStreamOperator方法得到StreamOperator实例。
1.1. 算子生成示例
上述内容偏概念更多一些,通过map为例实际观察Function->StreamOperator->StreamOperatorFactory->Transformation的过程
// 步骤1,业务代码中使用map操作 DataStream counts = text.map(row -> Tuple2.of(row, 1)) // 步骤2,将业务代码中提供的MapFunction封装成StreamMap public SingleOutputStreamOperator map( MapFunction mapper, TypeInformation outputType) { // 将MapFunction封装成StreamMap,StreamMap为AbstractUdfStreamOperator子类 return transform("Map", outputType, new StreamMap(clean(mapper))); } // 步骤3,根据StreamMap获取其对应的SimpleOperatorFactory工厂实例 public SingleOutputStreamOperator transform( String operatorName, TypeInformation outTypeInfo, OneInputStreamOperator operator) { // 获取StreamMap对应的StreamOperatorFactory工厂类 return doTransform(operatorName, outTypeInfo, SimpleOperatorFactory.of(operator)); } // 步骤4,将工厂实例传入到Transformation中 protected SingleOutputStreamOperator doTransform( String operatorName, TypeInformation outTypeInfo, StreamOperatorFactory operatorFactory) { OneInputTransformation resultTransform = new OneInputTransformation( this.transformation, operatorName, // 将StreamOperatorFactory工厂实例,传入到Transformation中 operatorFactory, outTypeInfo, environment.getParallelism()); @SuppressWarnings({"unchecked", "rawtypes"}) SingleOutputStreamOperator returnStream = new SingleOutputStreamOperator(environment, resultTransform); getExecutionEnvironment().addOperator(resultTransform); return returnStream; }在步骤2中,将MapFunction封装成StreamMap,StreamMap是AbstractUdfStreamOperator的子类,并且同时实现了OneInputStreamOperator,进行数据处理逻辑。在处理数据时,实际上是调用MapFunction的map方法完成,即在业务代码中指定的row -> Tuple2.of(row, 1)的逻辑。
public class StreamMap extends AbstractUdfStreamOperator implements OneInputStreamOperator { // 以下3个属性从父类继承 // 函数实例 protected final F userFunction; // 结果输出 protected transient Output output; // 默认算子链生成策略 protected ChainingStrategy chainingStrategy = ChainingStrategy.HEAD; public StreamMap(MapFunction mapper) { super(mapper); // 实例化StreamMap时,指定ALWAYS的算子链生成策略 chainingStrategy = ChainingStrategy.ALWAYS; } @Override public void processElement(StreamRecord element) throws Exception { // userFunction即MapFunction处理数据时,实质调用MapFunction的map方法。 output.collect(element.replace(userFunction.map(element.getValue()))); } }要在Task中算子才会真正执行,这里仅仅是在逻辑上完成算子的定义。
2. 算子链
Flink中会将多个算子合并到一起,组成算子链从而提高算子的运行效率。同一个算子链意味着将在同一个线程中运行。flink中算子链使用OperatorChain抽象类表示。
算子的合并策略在ChainingStrateg枚举类中定义,详情如下
/** * StreamOperator 使用的默认值为 HEAD,这意味着算子不链接到其前身。大多数算子使用 ALWAYS 覆盖此操作,这意味着它们将尽可能链接到前身。 */ public enum ChainingStrategy { // 尽可能的将和上游算子链接到一起,大多数算子的默认值 ALWAYS, // 当前算子不会上下游算子链接到一起 NEVER, // 不会上游算子连接到一起,但是可以和下游算子链接到一起 HEAD, // 此运算符将运行在链的头部(与 HEAD 类似,但它还会尝试在可能的情况下链接source。这允许将多输入运算符与多个源链接到一个任务中。 HEAD_WITH_SOURCES; public static final ChainingStrategy DEFAULT_CHAINING_STRATEGY = ALWAYS; }
- AbstractStreamOperator,所有流运算的基类。提供了生命周期和属性方法的默认实现。