
Flink作业执行之 1.DataStream和Transformation



Flink作业执行之 1.DataStream和Transformation
1. 滥觞
在使用Flink完成业务功能之余,有必要了解下我们的任务是如何跑起来的。知其然,知其所以然。
既然重点是学习应用程序如何跑起来,那么应用程序的内容不重要,越简单越好。
WordCount示例作为学习数据引擎时hello word程序,再合适不过。接下来便以任务执行顺序为线索开启对源码逐步学习。
public class WordCount {
public static void main(String[] args) throws Exception {
// 初始化执行环境
Configuration configuration = new Configuration();
configuration.setString("rest.port", "9091");
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(configuration);
env.setParallelism(1);
// 业务逻辑转换
DataStream text = env.fromCollection(Arrays.asList("zhangsan", "lisi", "wangwu", "zhangsan")).name("zl-source");
DataStream counts = text.map(row -> Tuple2.of(row, 1))
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(value -> value.f0)
.sum(1)
.name("counter");
counts.print().name("print-sink");
// 执行应用程序
env.execute("WordCount");
}
}
为了使示例代码足够纯粹(直接复制粘贴后即可跑起来的那种),因此在示例中直接使用List数据作为Source。
最后,计划将自己学习的过程以系列文档的形式作为记录。同时作为自己学习过程的记录,可能存在错误或片面理解,欢迎一起讨论。
2. 头疼的“角色”
在学习源码或查阅资料的同时,以下单词(但不限于)一定会频繁出现,它们或者直接对应flink源码中的接口、类名,或者是一些概念名称。初次看到难免让人抓狂。现在先对这些单词混个脸熟。
Client
JobManager/JobMaster
TaskManager/TaskExecutor
Transformation
StreamOperator
StreamGraph
JobGraph
ExecutionGraph
Task
StreamTask
……
3. 宏观视角
当任务开始执行后,便可以在WebUI上查看其对应的物理执行拓扑,即Task DAG。从我们编写的应用程序代码到Task DAG势必经历了复杂的解析转换操作,这个过程大体如下所示。
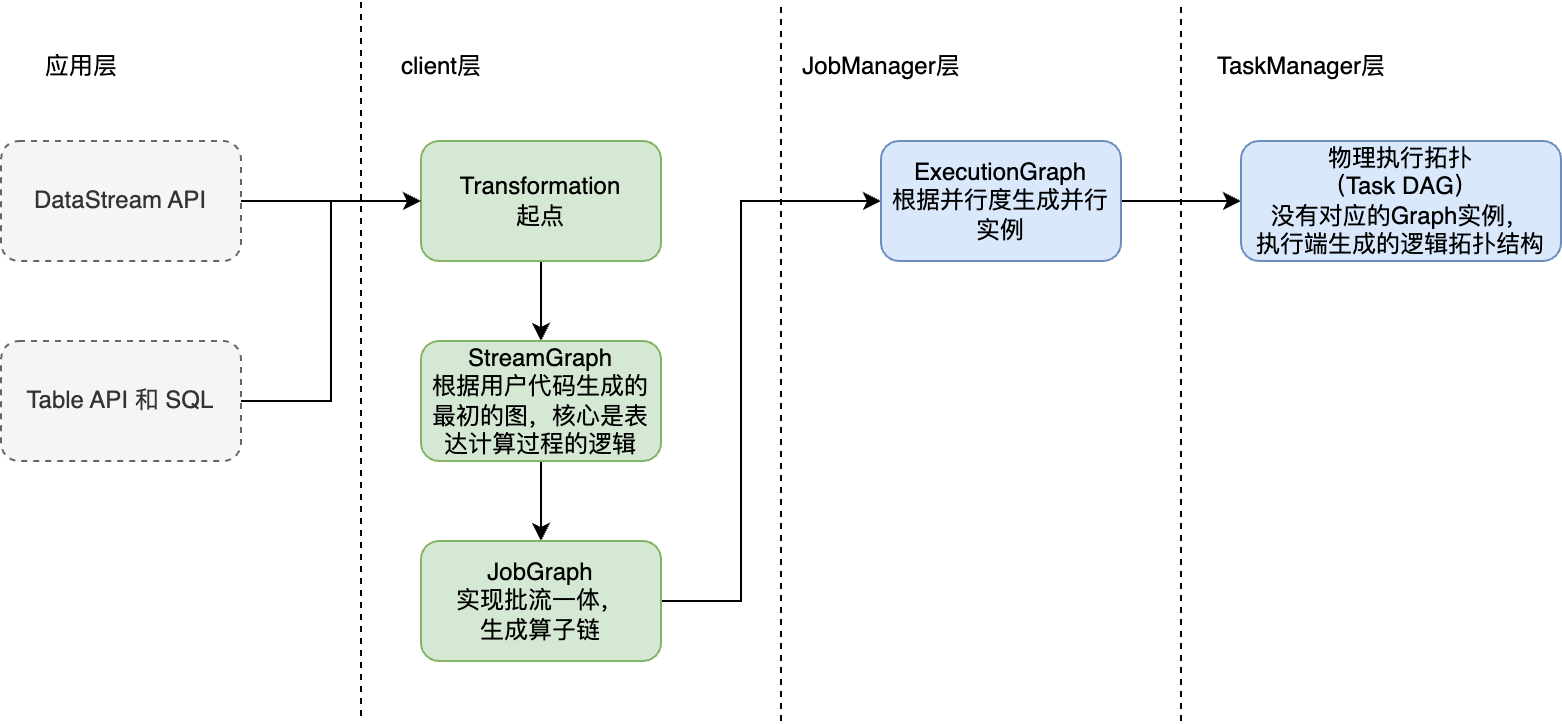
我们编写的应用程序代码首先会转化为Transformation,该实例将作为Flink世界中的起点,开启了之后一系列“旅程”。
4. env.execute()方法做了什么?
在使用DataStream API编写应用程序时,无论业务逻辑如何如何的复杂,但整体结构大致由三部分构成,即
// 1.初始化执行环境 StreamExecutionEnvironment env = ; // 2.业务逻辑转换,即一系列的DataStream转化 DataStream source = ; // 3.env.execute() env.execute();
既然最后必须执行 env.execute()方法,那么首先了解下execute都执行了那些操作。
基于1.16版本的源码,并只保留了源码中的关键逻辑。
// 方法1
public JobExecutionResult execute(String jobName) throws Exception {
final List> transformations = new ArrayList();
5. Transformation何时生成?
从StreamExecutionEnvironment的源码中可知,transformations属性只有addOperator方法会执行集合的add操作,其余地方均为集合的get操作。
然而addOperator方法有诸多调用方,且均为其他类中的调用,继续往上查看调用方有些困难,因此这里暂时记下addOperator方法唯一对transformations集合中执行add操作的结论。
// 该方法不适合用户使用。创建operator的api方法必须调用此方法
@Internal
public void addOperator(Transformation transformation) {
Preconditions.checkNotNull(transformation, "transformation must not be null.");
this.transformations.add(transformation);
}
通过查看StreamExecutionEnvironment实例的创建过程,可以发现在创建过程中并无transformations的add操作,因此是在DataStream转换操作中对transformations执行了add操作。
5.1. DataStream
在Flink中使用DataStream表示数据流。其仅用于表达业务转化逻辑,实际上并没有真正的存储数据。
DataSteam是顶层封装类,其子类如下
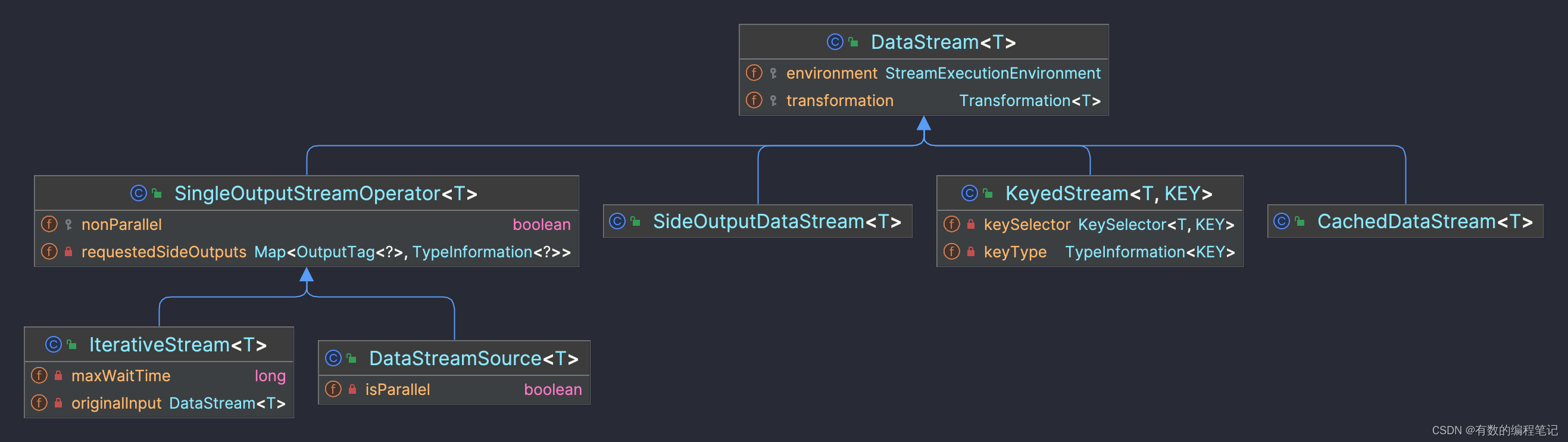
DataStream类中只有两个成员属性,分别是StreamExecutionEnvironment和Transformation,并在构造方法中对其进行初始化。因此实例化DataStream的同时除执行环境外,还必须传入Transformation的实例。
public class DataStream {
protected final StreamExecutionEnvironment environment;
protected final Transformation transformation;
public DataStream(StreamExecutionEnvironment environment, Transformation transformation) {
this.environment =
Preconditions.checkNotNull(environment, "Execution Environment must not be null.");
this.transformation =
Preconditions.checkNotNull(
transformation, "Stream Transformation must not be null.");
}
// ...
}
回到WordCount示例代码中,从集合到DataStream的过程,封装示意如下。
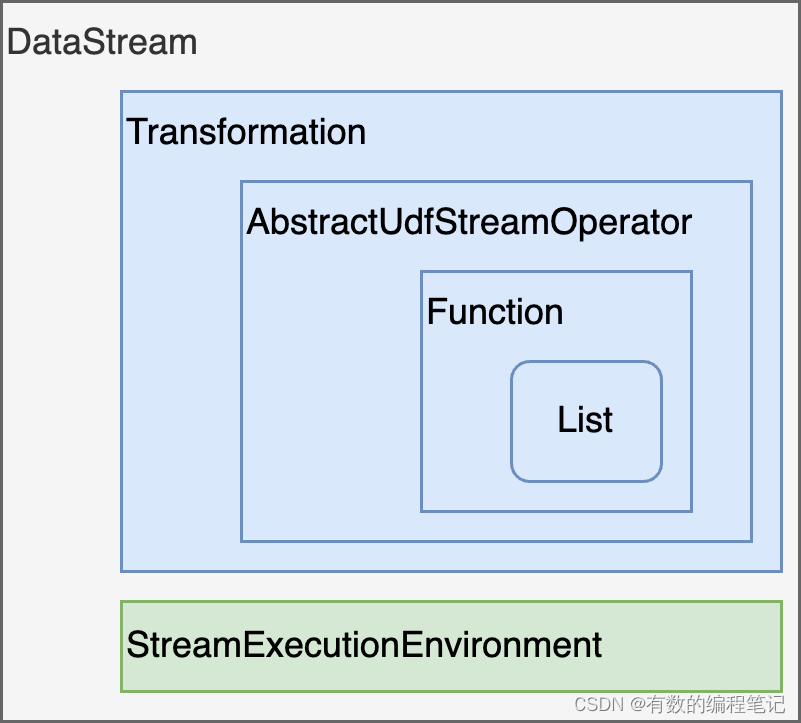
注意,Transformation中并不是直接持有了AbstractUdfStreamOperator的引用,而是对应的工厂。
源码中关键步骤如下
// 步骤1,从List到Function
public DataStreamSource fromCollection(
Collection data, TypeInformation typeInfo) {
// ...
// 创建SourceFunction实例,SourceFunction是Function的实现
SourceFunction function = new FromElementsFunction(data);
return addSource(function, "Collection Source", typeInfo, Boundedness.BOUNDED)
.setParallelism(1);
}
// 步骤2,从Function到StreamOperator
private DataStreamSource addSource(
final SourceFunction function,
final String sourceName,
@Nullable final TypeInformation typeInfo,
final Boundedness boundedness) {
// ...
// 创建StreamSource实例,StreamSource是AbstractUdfStreamOperator的子类,Flink中算子的表示
final StreamSource sourceOperator = new StreamSource(function);
return new DataStreamSource(
this, resolvedTypeInfo, sourceOperator, isParallel, sourceName, boundedness);
}
// 步骤3,从StreamOperator到Transformation,再到DataStream
public DataStreamSource(
StreamExecutionEnvironment environment,
TypeInformation outTypeInfo,
StreamSource operator,
boolean isParallel,
String sourceName,
Boundedness boundedness) {
super(
environment,
// 创建Transformation实例,Transformation是PhysicalTransformation的子类
new LegacySourceTransformation(
sourceName,
// 将StreamSource封装到Transformation中
operator,
outTypeInfo,
environment.getParallelism(),
boundedness));
// ...
}
继续查看DataStream的map操作可以可以发现,核心流程和上述由集合创建DataStream的过程基本一致:
- 首先创建Function实例
- 其次由Function实例创建AbstractUdfStreamOperator实例
- 然后将AbstractUdfStreamOperator实例封装到Transformation实例中
- 最后由Transformation和StreamExecutionEnvironment实例创建DataStream实例
不同之处在于,map操作最后将得到的PhysicalTransformation实例添加到StreamExecutionEnvironment实例中的transformations集合中去了。这点差异其实和Transformation实例表示的含义有关,放在文章末尾解释。
protected SingleOutputStreamOperator doTransform( String operatorName, TypeInformation outTypeInfo, StreamOperatorFactory operatorFactory) { // ... OneInputTransformation resultTransform = new OneInputTransformation( this.transformation, operatorName, operatorFactory, outTypeInfo, environment.getParallelism()); SingleOutputStreamOperator returnStream = new SingleOutputStreamOperator(environment, resultTransform); // 区别:添加Transformation到StreamExecutionEnvironment中 getExecutionEnvironment().addOperator(resultTransform); return returnStream; }但并不是全部的DataStream转化操作都需要经历上述将Function实例封装成AbstractUdfStreamOperator实例,然后将AbstractUdfStreamOperator实例封装到PhysicalTransformation实例的过程。如示例代码中的keyBy和sum操作。其中keyBy并未直接涉及Function,而sum操作直接将得到的SumAggregator函数实例封装到了ReduceTransformation实例中,然后由ReduceTransformation实例得到DataStream实例。
5.2. Transformation
DataStream面向开发者,而Transformation面向flink内核。
每个DataStream实例中都包含一个Transformation实例,表示当前Datastream从上游的DataStream使用该Transformation而来。而所有DataStream中Transformation又都添加到了StreamExecutionEnvironment实例中的transformations集合中去,用于接下来的StreamGraph实例的生成。
Transformation中记录了上游的数据来源,但其并关心数据的物理来源、序列化、转发等问题。
Transformatio是顶层抽象类,有众多的子类,涵盖了DataStream的所有转换,其直接子类如下,可以分为两大类
- PhysicalTransformation,将会转换成后续graph中节点信息
- 非PhysicalTransformation,将会转换成后续graph中的边信息

Transformation中属性如下所示,其中Optional表示共享槽位信息,只有开启了允许共享槽位后,该属性才会被设置值。
其构造方法如下,除name外还需要输出类型和并行度两个参数。
public Transformation(String name, TypeInformation outputType, int parallelism) { this.id = getNewNodeId(); this.name = Preconditions.checkNotNull(name); this.outputType = outputType; this.parallelism = parallelism; this.slotSharingGroup = Optional.empty(); }PhysicalTransformation仅在其父类的基础上增加了设置ChainingStrategy的方法,用于表示生成算子链的策略。
@Internal public abstract class PhysicalTransformation extends Transformation { PhysicalTransformation(String name, TypeInformation outputType, int parallelism) { super(name, outputType, parallelism); } /** Sets the chaining strategy of this {@code Transformation}. */ public abstract void setChainingStrategy(ChainingStrategy strategy); }PhysicalTransformation中有众多的实现子类,全部子类继承关系如下。
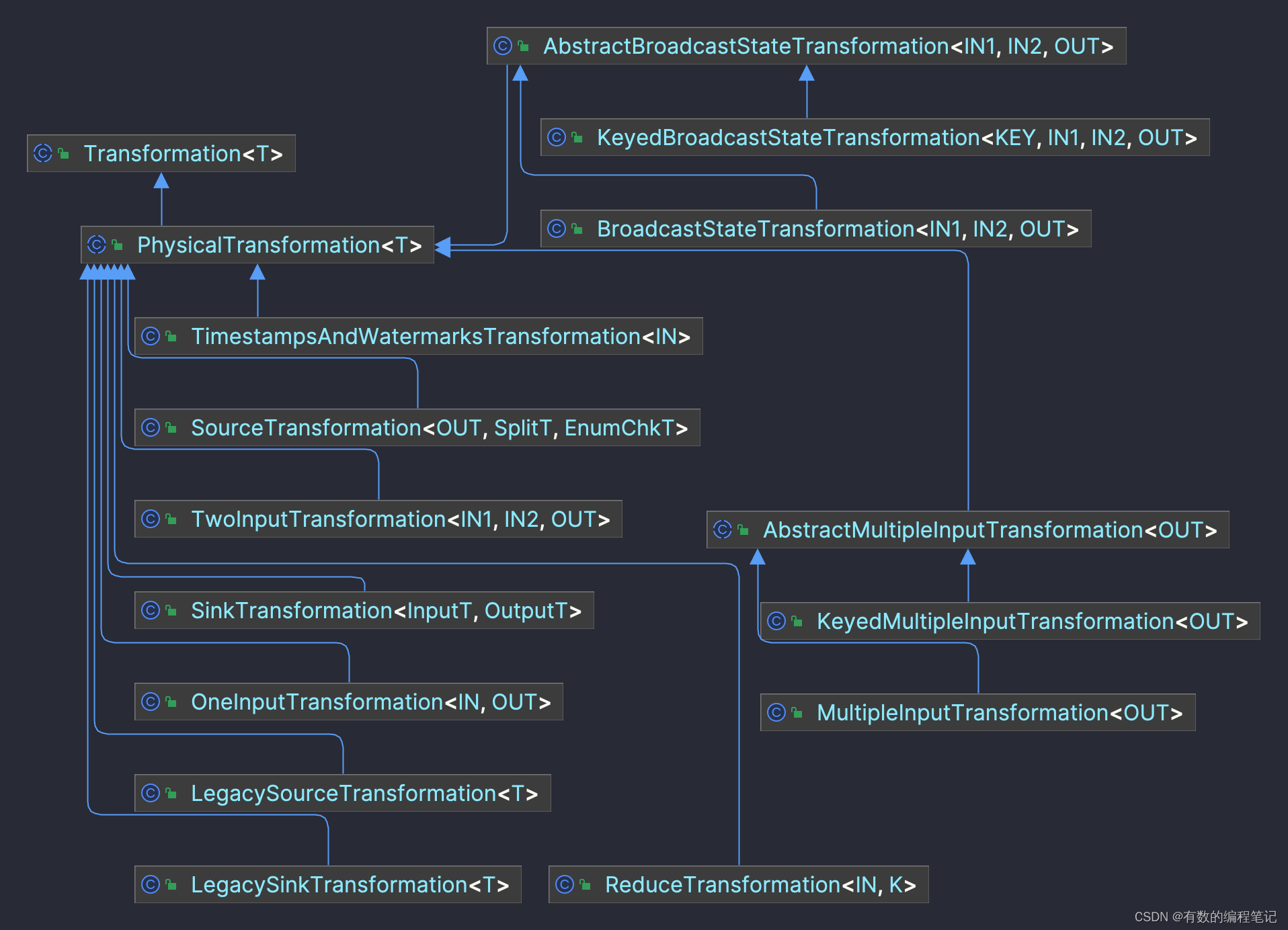
其中以下几个子类出场频率相对更高一些,其他子类只有我们的业务逻辑比较复杂时才会用到。
- LegacySourceTransformation 表示Source的Transformation
- LegacySinkTransformation 表示Sink的Transformation
- SourceTransformation
- SinkTransformation
- OneInputTransformation 表示单个输入流的Transformation,如常见的map、flatMap、fliter等
- TwoInputTransformation 表示两个输入流的Transformation,如concat
疑问:为什么Source和Sink都各自分别有两个Transformation子类?
通过名称也可以看出一些端倪,新老两种实现。
在1.14版本之前,分别通过env.addSource(SourceFunction)和DataStream.addSink(SinkFunction)方法生成source和sink
从1.14版本开始新增了env.fromSource(Source)和DataStream.sinkTo(Sink)的方式生成source和sink。
新旧方法中入参类型不同,因此导致了两种不同的Transformation实现,从各自的实现类中也可以体现这一点,如下所示。
public class LegacySourceTransformation extends PhysicalTransformation implements WithBoundedness { // sourceFunction的引用 private final StreamOperatorFactory operatorFactory; // ... } public class SourceTransformation extends PhysicalTransformation implements WithBoundedness { // source的引用 private final Source source; // ... } public class LegacySinkTransformation extends PhysicalTransformation { private final Transformation input; // sinkFunction的引用 private final StreamOperatorFactory operatorFactory; // ... } public class SinkTransformation extends PhysicalTransformation { private final DataStream inputStream; // sink的引用 private final Sink sink; private final Transformation input; // ... }Source作为整个数据流的头部,不存在上游,因此其Transformation实现中没有上游Transformation的引用,除此之外其余的Transformation子类中,均持有一个表示上游Transformation的引用,如上述sink中的input属性。
最后解释下,前面提到的为什么没有将表示Source的DataStream中的Transformation加入到env中表示Transformation的集合中,而接下来的转化中,将对应的Transformation加入到了env中。因为Source作为数据源的头部,不会存在上游,而Source作为其他DataSteam的上游,一定会加入到其Transformation的input中,因此没必要单独将Source的transformation加入到env中。



