
从GPT-3.5到GPT-4O:探索AI的进化之旅,哪一版更懂你?



如何评价GPT-4o?
最新的GPT-4O,被誉为GPT-4的增强版。它在保持前代产品优秀性能的基础上,大幅降低了使用成本,使得更多的普通用户也能享受到顶尖AI的服务。GPT-4O在非英语语言处理上的强化,更是让其在全球范围内的适用性大大提高。对于小需求用户来说,这一版本的推出无疑是一大福音。
笔者作为一名从2022年11月开始使用GPT至今的“老兵”不妨说一下自身使用并在几个AI类项目中实际使用下来的体验吧,我先用一句话总结:有惊艳,但不多。
从GPT各个史诗级版本来看GPT各个版本的特点
在人工智能的世界里,每一次技术的迭代都不仅仅是一次简单的更新,而是一次对未来的深刻预见。OpenAI的GPT系列无疑是在这场科技革命中的佼佼者。从GPT-3.5到最新的GPT-4O,每一个版本的发布都不仅仅是技术的飞跃,更是对人类生活方式的一次深刻影响。
GPT-3.5:智能的崭露头角
GPT-3.5作为GPT-3的升级版,其在处理语言的复杂性和细腻度上有了显著提升。它在文本生成、语义理解方面的能力,使其在学术研究、内容创作等领域大放异彩。然而,它在处理非英语语言和高成本的问题上仍显得力不从心。
GPT-4:全面而深入的理解
随后,GPT-4的出现,不仅继承了GPT-3.5的优点,更在模型的多样性、适应性上进行了大幅度的扩展。GPT-4不仅提高了问题回答的精准性,其反应速度也得到了大幅提升,使其在实时交互、在线客服等场景中更加得心应手。此外,GPT-4在道德和情感理解上也表现出了惊人的敏感度,使其在心理咨询、教育辅导等领域更加贴心。
GPT-4-Vision:视觉与语言的跨界融合
GPT-4-Vision的推出,标志着OpenAI在跨模态人工智能领域的深入探索。这一版本不仅保持了文本处理的高水平,还加入了图像理解的能力。这使得GPT-4-Vision在图文编辑、广告创意等领域展现出了前所未有的创造力。
GPT-4O:成本降低,普及性增强
GPT-4O版本,可以说是在GPT-4的基础上进行了全方位的强化。官方宣称,GPT-4O在逻辑推理、创作能力、情感理解以及道德判断等方面都有显著提升。这使得GPT-4O不仅能够在更多语言上表现出色,其在文艺创作、心理咨询等需要深度情感理解的领域也将大放异彩。更重要的是,由于成本的大幅降低,GPT-4O为更多普通用户提供了免费试用的机会,极大地提升了用户体验,使得人工智能技术的普及门槛被进一步降低。
总结来说,GPT-4O不仅在技术上有了全面的提升,更在普及和应用上迈出了坚实的步伐。对于免费用户来说,这无疑是一大福音;对于有特定小需求的用户,也无需再投入大量资金。OpenAI的这一系列动作,不仅提升了用户体验,更预示着其在未来人工智能领域的领导地位将更加稳固。对于我们这些期待科技改变世界的观察者来说,GPT-4O的出现,无疑加速了这一进程
各版本的对比-直观感受GPT4-O到底有什么不一样
如果要说公平比较GPT个版本由其是让大家可以客观的切身体会到GPT4-O到底有什么不一样的点,我们使用Apple To Apple的比较方式来说明吧。
反应速度来比较
包括Stream或者是非Stream模型的每一次对话响应速度,在同等发送内容大小:发送4,096 Token,响应4,096 Token(生产级实用场景)下各版本表现如下:
- GPT3.5-3秒响应;
- GPT4-9秒~10秒响应;
- GPT4-Turbo和Vision反而更慢:12-15秒响应;
- GPT4-O,5秒响应;
GPT3.5完胜!
推理能力比较
这是我们在自己产品内的AI原生规则引擎产品-内部开发代号“汉摩拉比法典”,在“法典”中我们可以使用动态的AI线路去做切换(包括国内几个著名的LLM都可以热切换其实都已经做过比较了)。
它的参数+发送内容基本在一次出去2,000 Token,返回在900Token左右。
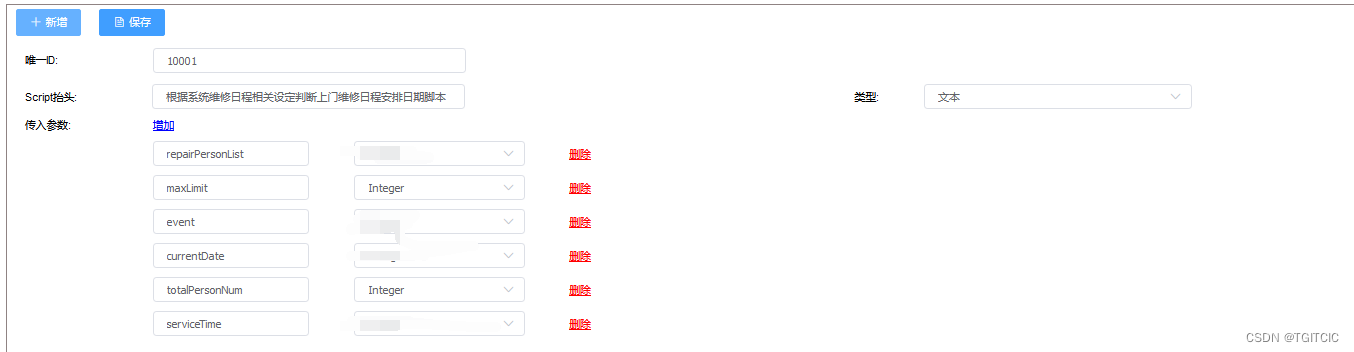
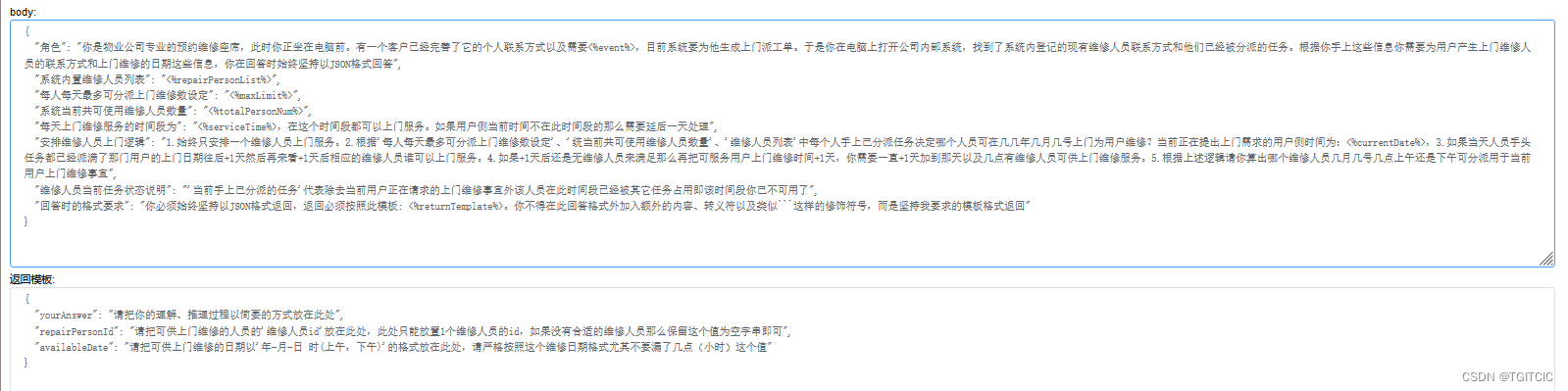
- 3.5推理这么一种至少含有3个维度间跳跃的,有5%失败率(返回不是我们要的甚至格式都错了),内容准确性在95%;
- 4.0(包括8K,32K和Turbo-128K版本),0%失败率,成功率达到100%,内容准确性达到100%;
- GPT4-O,成功率99%,内容准确性达到99%;
GPT4系列版本完胜!
理解能力比较
什么是理解能力?它是推理能力吗?嘿嘿嘿。
我告诉大家,RAG或者说AI Agent领域做多了就能真正体验到什么叫“理解能力”不等于“推理能力”了。上面我的推理能力里因为是一个生产级别的应用它带有多层推理,至少达到3层推理,这个推理是指根据提示出结果的正确性。
而理解能力是指它是不是真正的“听懂了”你说的话,叫理解能力,同样我们使用生产级别的内容来评判 这个理解能力,理解用范本如下:
对于住房管理维修业务分为分套内和套外两种。 套内(包括住房内所有电器、空调、住房内装修、住房内器具、用品、家具、住房内厨房、卫生间、洗浴等用品、住房内家内空间里的一切物品)指客户的住房内全部问题属于“A物业”公司负责。 套外(包括小区、苑、园区、楼道)即客户住房外部的一切问题如:楼道、电梯、公共走廊、门厅、小区内的绿化带、停车场、健身区、儿童游乐场等共享设施,以及建筑物的外墙装饰、屋顶防水处理这些问题这些都属于“B物业”公司负责。
根据这个背景知识我们追加提问:
家里马桶坏了,找谁?
- 3.5,回答为:这属于套外问题,找B物业;
- 4.0(包括8K,32K和Turbo-128K版本),回答为:这属于套内问题,找A物业;
- 4.0 O,回答为:这属于套内问题,找A物业;
4.0与4-O打平手。
注:为什么3.5在讲了这么明确的情况下还会把马桶认为是套内问题?因为提示语里的背景有套内是“住房内”,套外是“住房外部”。因此3.5把这个“住房内”理解成了你家假设有2室1厅1卫,你住的主卧叫“内”,而“外”是指你主卧外的空间那么马桶在卫生间所以它属于“套外”问题。

PS:为什么我们可以知道以上GPT3.5怎么理解错了?
很简单,每次让AI回答时让它多“带”点东西输出即在你的提示的最后加上以下这段魔咒你就能知道AI是怎么思考问题了:
请你回答后再加上一段内容,这段内容描述一下你是怎么理解、推理我的问题的详细过程。
结果3.5判定套内套外时在输出它的理解过程时输出了我上面这段标成紫色字体的内容了。
Token费用比较
如果是企业级应用肯定要用AZURE提供的GPT,全球唯一企业级GPT调用,因此我们直接拿官方的收费来比就可以了,这是公开的信息。
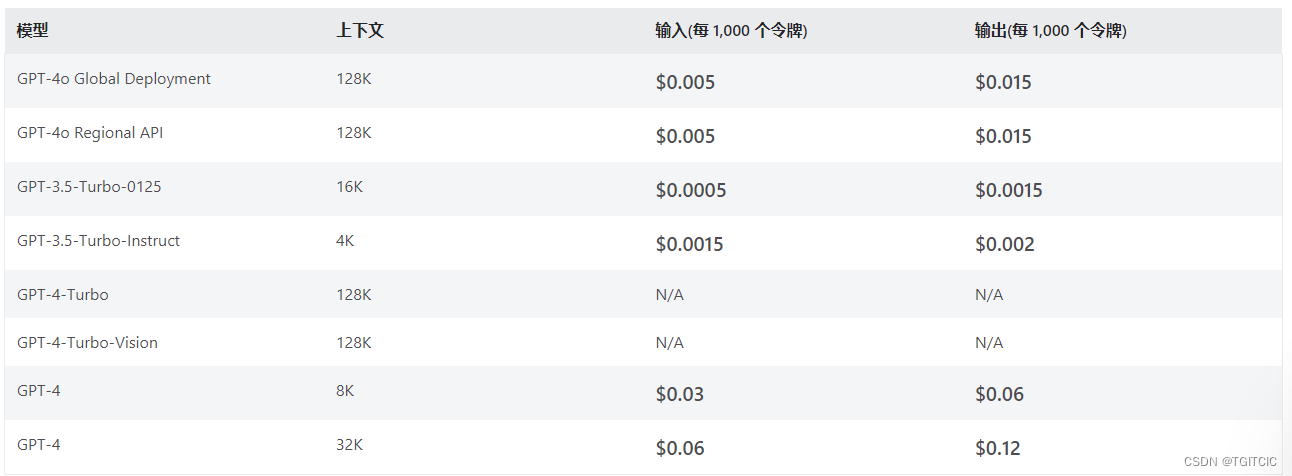
GPT3.5完胜!
特殊能力比较
- GPT3.5-只有文字,通过OCR、语音等技术、PYTORCH以及其它多媒体小模型加持,可以做到多模态,但对实施团队要求很高;
- GP4(包括GPT4-8K、32K、Turbo),通过OCR、语音技术、PYTORCH以及其它多媒体小模型加持,可以做到多模态,但对实施团队要求很高;
- GPT4-VISION,直接识别图,对于语音、手绘识别度不高需要使用其它相应的小模型来做辅助实施,对团队实施要求很高;
- GPT4-O,对语音、手绘均识别,且识别率极好,可以秒杀市面任何其它这方面的产品;
GPT4-O完胜!
GPT各版本-Apple To Apple完整比较视图

到底如何选型
从上面的比较来看,我们可以说“各有千秋”,没有绝对的好与坏,只有如何在充分理解你要实施的需求的前提下的“搭配使用”,说白了还是项目管理那套:成本、质量、进度。而不是只选1个版本来使用而不用其它的版本这种非0即1的选择。
对此我现在自己的团队得出了这么一套方法论供各位去做参考:
- 必须使用最快的来输出文字问答,这是必须使用快的;
- 对于推理、理解类的,需要把送出去的“猫娘-角色设定+提示语+数据”最小化到甚至连4都可以做到在1.5-2秒内返回时就一定要用4否则用3.5来做,但此时对提炼你将要送给GPT的内容需要做语义、措词、描述上的修改(最好用全英语写提示词,中文存在不少岐议会导致猫娘过长而取得的效果还不好);
- 对于精准要求很高的,可能需要重新考虑设计你的“用户交互层”,需要到处充满着“异步”或者一些技巧以便于在因为付出速度慢获得精准性时兼顾到用户的交互体验(这一块比实施之前中台类项目还复杂)更有点像在做“创意”而不是在做编程或者是技术工作了;
那么说到一些图片、语音交互是不是非要GPT4-O莫属?
答案是:不一定!
GPT4-O整体来说换算成人民币是1,000 Token1角4毛5分钱 RMB(按照今天汇率算)。不贵也不算太便宜,因为生产级别应用并发是一秒至少50-150,如果是TO C端这个底子一乘上去还是不便宜的。
它只是在性能、准确度、和反应速度上做出了一个较好的“折中”而己。如果只是语音识别,这方面有不少国内垂直领域做了相当好,甚至可以做到比如说:我走在上海南京路步行街,5.1号中午左右这个点街上人声鼎沸,周边分贝在75-80左右时在这样的一个环境下我们国内的一些AI语音识别SDK的识别率也能高达97%。
对于图片,我们可以使用图片向量搜索、比较这一类算法。
只有且仅只有需要实时识别图片时,GPT-4O的确是王者。比如说:一闪而过的高速路上的车牌号这样的识别,或者说是:模糊图片、不清晰图片的信息提取、校准。
GPT4-O对图片的分析的准确率的演示
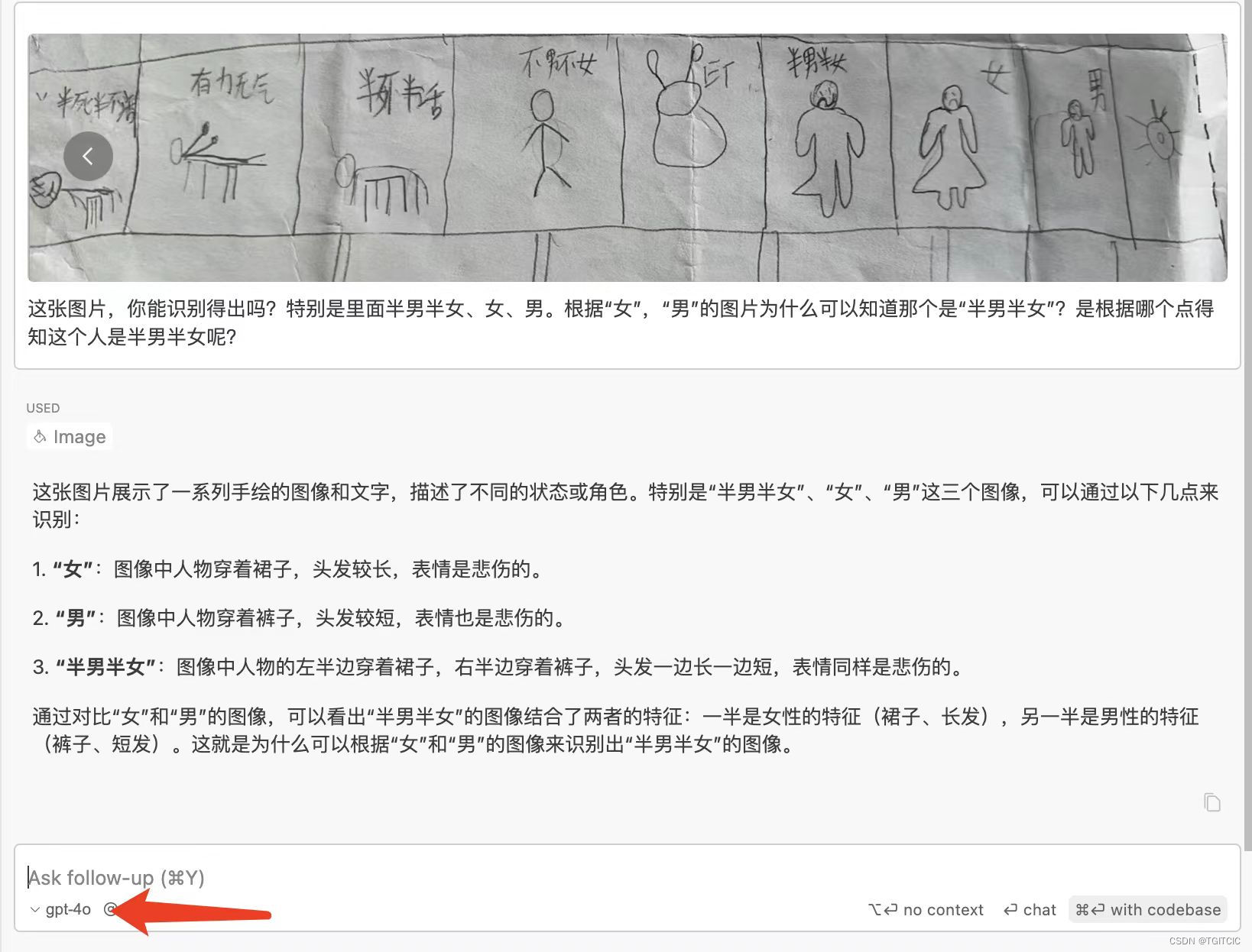
最后我们以GPT4-O在我这实际使用的例子演示来感受一下GPT4-O在图片识别这一块的强大吧。
例一、我儿子的手绘图让GPT4-O去分析
例二、手绘HTML,GPT4-O出代码准确率到达了100%
GPT4-O根据的绘生成HTML







