
【SAM综述】医学图像分割的分割一切模型:当前应用和未来方向
看到一篇SAM在医学图像分割中应用的综述,翻译记录一下。
原文传递:Segment Anything Model for Medical Image Segmentation: Current Applications and Future Directions
SAM代码解析系列篇:
【技术追踪】SAM(Segment Anything Model)代码解析与结构绘制之Image Encoder
【技术追踪】SAM(Segment Anything Model)代码解析与结构绘制之Prompt Encoder
【技术追踪】SAM(Segment Anything Model)代码解析与结构绘制之Mask Decoder
摘要
鉴于prompt的灵活性,foundation models已成为自然语言处理和计算机视觉领域中的主导力量。最近SAM的兴起,使得prompt-driven范式在图像分割领域显著发展,进而引入了大量以前未开发的功能。但医学图像与自然图像还是存在较大差异,SAM应用于医学图像的可行性尚未可知。
在本文中,作者进行了全面综述,介绍医学图像分割任务中SAM的有效性,包括基线测试和方法调整,还探索了SAM在医学图像分割中的潜在研究方向。
截至目前,直接将SAM应用于医学图像分割并没有在多模态和多目标医学数据集上产生令人满意的性能,但从这些研究中可以发现有价值的指导。
持续论文更新列表:https://github.com/YichiZhang98/SAM4MIS
1、前言
医学成像在疾病的诊断和治疗中起着至关重要的作用。医学图像分割旨在从医学图像的器官、病变、组织等中识别出特定的解剖结构。准确的分割可以提供可靠的目标结构的体积和形状信息,从而有助于疾病诊断、定量分析和手术计划等许多进一步的临床应用。(医学图像分割在临床中很有用)
由于深度学习模型能够学习复杂的图像特征,因此在医学图像分割领域显示出巨大的前景。然而,现有的方法通常是针对特定的模式或目标量身定制的,这限制了它们在不同任务之间有效推广的能力。(缺乏通用模型的意思)
大型foundation models的出现已经彻底改变了人工智能,并开创了一个新时代,因为它们在下游任务中具有出色的zero-shot和few-shot泛化能力。(嗯,大模型很强)为了解决医学成像中复杂的分割任务,开发能够适应各种成像方式的foundation models是非常重要的。(咋办,想要用于医学图像分割的大模型)
SAM作为开创性的图像分割foundation models,其可以全自动或交互式方式生成准确目标掩码,能力很强,受到广泛关注。这标志这prompt-driven范式开始进入图像分割领域。然而,作为图像分割的一个非常重要的分支,由于自然图像与医学图像的本质区别,这些基础模型能否应用于医学图像分割尚不清楚。(医学图像分割还是要难一些)为此,有大量的工作,进一步探索SAM在医学图像分割中的应用。
本文中,总结最近的工作,将SAM的成功应用到医学图像分割任务。首先,简要介绍了foundation models的产生背景和SAM的工作方式。随后,回顾现有工作,有两个主要方向。一个是评估不同prompt模式下SAM在各种医学图像分割任务中的zero-shot性能,另一个是探索SAM适应医学图像分割的方法。(一个prompt,一个adapter)最后,概述现有的挑战以及潜在的未来方向。
Figure 1:2023年医学图像分割中SAM及其变体的研究
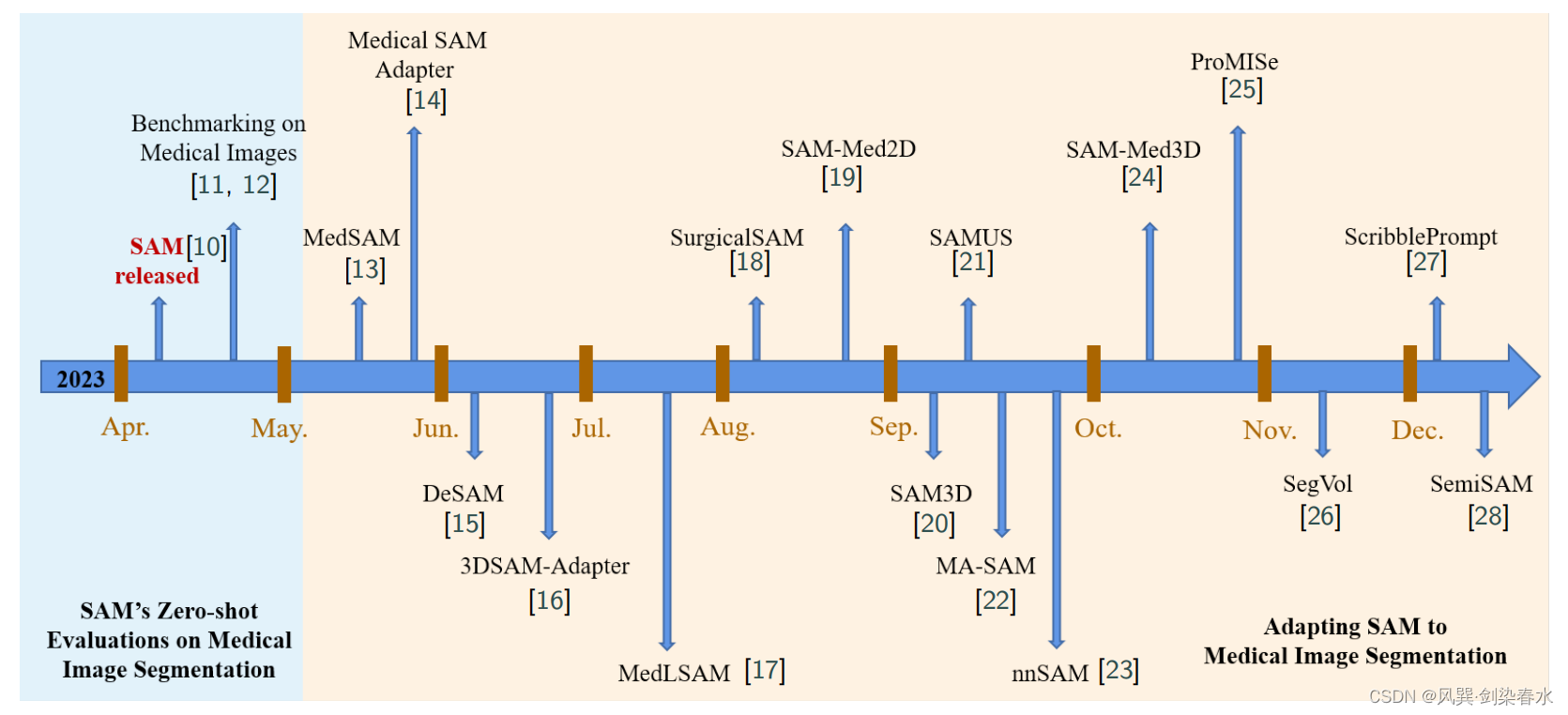
2、研究背景
2.1 Foundation Models
Foundation Models是人工智能研究的一个快速发展的领域,旨在开发大规模、通用的语言和视觉模型。(俗称大模型、通用模型或基础模型)这些模型通常在大量数据上进行训练,这使它们能够学习可以转移到不同领域和应用的一般表示能力。(俗称大力出奇迹)其中最广为人知的基础模型之一是GPT系列(Generative Pre-trained Transformer),它在各种自然语言处理任务上表现出很强的性能,如句子完型、问题回答和语言翻译。
这些研究成果激发了研究人员开发大规模的基础模型,来学习计算机视觉任务的通用表示,(NLP有的,我CV也要有)这些模型的重点是捕获视觉和语言之间的跨模态相互作用,如理解视觉概念和细节,生成图像区域的自然语言描述,以及从文本描述生成图像。(俗称文生图和图生文)
这些foundation models的成功催生了跨越不同行业的众多衍生作品和应用,这些衍生作品和应用已成为许多人工智能系统架构的重要组成部分,它们的持续发展有望推动语言和视觉任务的进一步发展。foundation models在解决医学图像分析的下游任务时也显示出强大的潜力,有助于加速又准确、又鲁棒的模型发展。
2.2 Segment Anything Model
略,详见系列篇
Figure 2:SAM架构概览
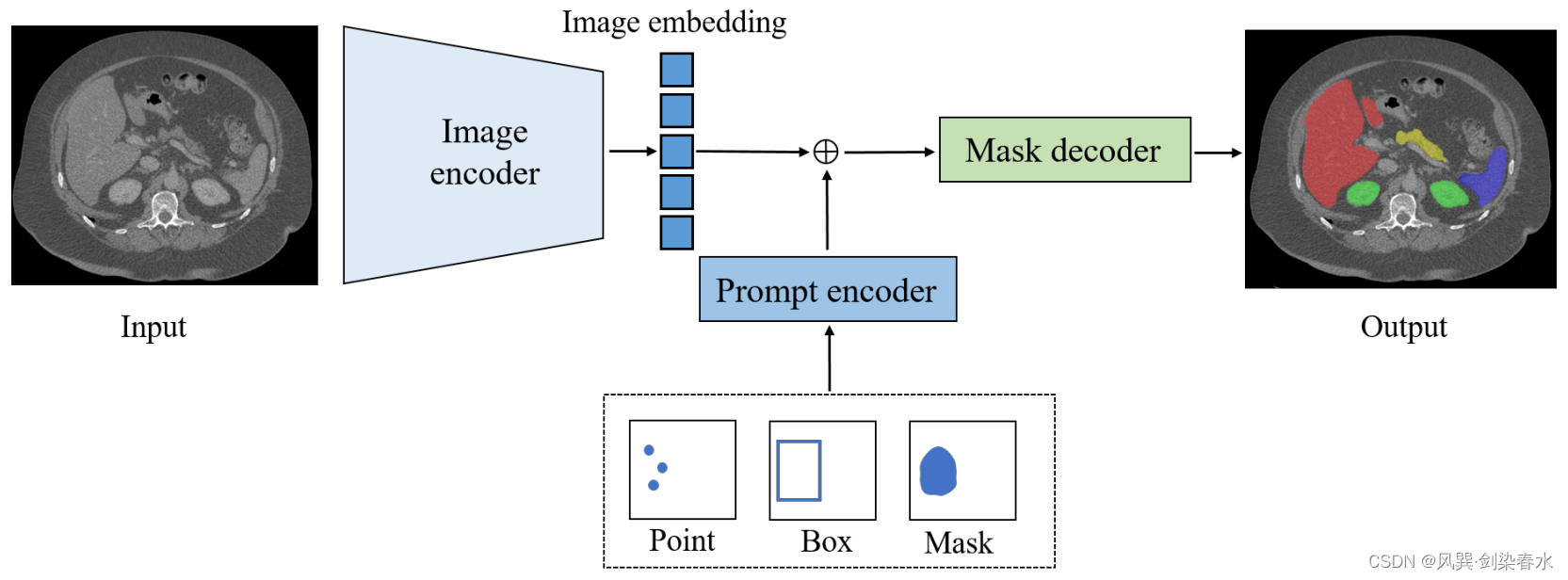
3、基于SAM的医学图像分割Zero-shot评估
尽管SAM在自然图像上的表现令人印象深刻,但由于许多内在问题,例如结构复杂性、低对比度和观察者之间的可变性,它是否能够解决医学图像分割的挑战仍不清楚。为了回答这个问题,许多工作研究了它在医学图像分割中的zero-shot性能,重点关注了不同医学成像方式下的各种解剖和病理目标。
这些模式包括二维医学图像(例如,x光、病理、超声、胃镜、肠镜)和三维医学图像(例如,CT、MRI和PET)。一些研究专门评估了SAM在特定成像模式下的有效性,而另一些研究则在各种模式下对广泛的分割任务进行了全面评估。
本节中,按医学成像模式分类,介绍SAM在医学图像分割中的zero-shot应用。
3.1 CT图像分割
CT扫描从身体周围的不同角度捕获多个x射线图像,以创建一系列详细的横截面切片,可以可视化身体内部结构和异常情况,如器官,骨骼和血管。
Roy等在AMOS22腹部CT器官分割数据集上进行了实验,评估了SAM在腹部器官分割时out-of-the-box zero-shot能力。(俗称直接用)他们从分割掩码中产生随机选择point和抖动box的不同设置,以模拟用户不同程度的不准确性。其结果表明,使用point提示的SAM不如最先进的(SOTA)性能,平均骰子相似系数(DSC)下降了20.3%到40.9%,而使用box提示,即使在中等抖动的情况下也可以获得高度竞争的性能。
为了评估SAM在分割肿瘤方面的性能,Hu等从对比增强计算机断层扫描(CECT)中进行了多相肝肿瘤分割的实验。结果表明,分割时使用的提示point越多,SAM的性能越好。然而,与经典的U-Net架构仍然存在很大的性能差距。
3.2 MRI图像分割
MRI是一种非侵入性成像技术,利用强大的磁体和无线电波产生内部解剖结构的高分辨率横断面视图,包括大脑、关节和其他软组织。
由于MRI在脑可视化中发挥着重要作用,Mohapatra等将SAM与brain Extraction Tool (BET)进行了比较,BET是目前广泛使用的脑提取和分割的金标准技术。他们在各种不同图像质量、MR序列和脑损伤部位扫描上进行了实验。结果表明,SAM可以获得相当甚至更好的性能,表明它有潜力成为一种有效的大脑提取和分割工具。
Zhang等人也评估了SAM在脑肿瘤分割上的性能,并验证了如果不进行模型微调,SAM与当前的SOTA方法之间仍然存在差距。
3.3 病理图像分割
病理图像通常使用显微镜技术获得,以描述人体内的异常组织结构,细胞变化或病理状况,特别是在肿瘤学中。
Deng等对SAM在全量影像(whole slide imaging,WSI)数据上的肿瘤分割、非肿瘤组织分割和细胞核分割进行了评估。通过进行多个提示设置,包括单个正点、20个点(10个正点和10个负点)和所有点/框。(这个设置有点意思)结果表明,SAM可以对大型连接对象实现显著的分割性能,但对于密集实例对象分割,即使每个图像有20个提示(points/boxes)也会失败。可能的原因有:WSI数据的图像分辨率明显高于SAM的训练图像分辨率,以及用于数字病理的不同组织类型的多个尺度。
3.4 肠镜图像分割
肠镜图像是在肠镜检查过程中通过将肠镜插入直肠来检查结肠和直肠而获得的。肠镜图像可提供结肠内膜的详细视图,使临床医生能够识别息肉和炎症等异常情况。
Zhou等在五个基准数据集上评估了自动设置的SAM在从结肠镜图像中分割息肉方面的性能。结果表明,与SOTA方法相比,SAM方法的性能明显较低,平均骰子相似系数(DSC)下降幅度为14.4%至36.9%。由于息肉与周围粘膜的界限模糊,直接应用息肉分割任务时,SAM不能达到令人满意的效果,需要prompts的参与或adaptation方法来提高性能。(直接用不太好使啊)
3.5 内镜图像分割
内镜图像是指通过内窥镜拍摄的视觉表现,这是一种微创的医疗手段,用于检查体内中空器官或腔体的内部。内窥镜通常用于机器人辅助手术,其中手术器械的分割对于器械跟踪和位置估计至关重要。
Wang等人在内镜手术器械分割的两个公开数据集EndoVis17和EndoVis18上对SAM的性能进行了评估。结果表明,当使用基于point的提示和非提示设置时,SAM准确分割整个仪器的能力存在缺陷。值得注意的是,SAM在预测某些仪器部件方面存在缺陷,特别是在提示较弱时重叠的仪器。此外,SAM还面临着在复杂的手术场景中识别以血液、反射、模糊和阴影为特征的器械的挑战。(器械分割好像也挺有意思的)
3.6 在多种模式下的分割
He等没有在单一成像方式上评估SAM,而是在12个公共医学图像分割数据集上进行了大规模的实证研究,对SAM的准确性进行了评估,这些数据集涵盖了脑、乳腺、胸、肺、皮肤、肝、肠、胰腺和前列腺等不同器官。(大工程啊)他们的评估跨越各种成像模式(例如,2D x光,2D 超声,3D MRI和3D CT),并涵盖不同的健康状况,包括正常和异常病例。结果表明,在不进行微调的情况下直接应用于医学图像时,SAM的精度不高,其性能受到维度、模态、尺寸和对比度等多种因素的影响。
同样,Mazurowski等人通过生成point提示来模拟交互式分割,对11个不同模态的医学图像分割数据集进行了广泛的SAM评估。观察到的性能表明,对于具有明确提示的明确边界对象,该方法具有较高的准确性,但在分割肿瘤时精度较低。(边界明确好用)
Cheng等在自动提示、box提示和point提示三种提示模式下,评估了SAM在代表各种器官和形态的12个公共医学图像数据集上的性能。结果表明,SAM在不同数据集上性能有差异,无抖动的box提示模式被证明是在zero-shot医学图像分割中最有效的方式。(box好用)
Zhang等通过对前列腺、肺、胃肠、头颈部等放射肿瘤学的主要治疗部位进行分割,评价了SAM在临床放疗中的表现。该评估强调了SAM描绘大型、独特的器官的能力,但强调了在分割较小、复杂的结构方面面临的挑战,特别是在面对模糊的提示时。(大器官好用)
为了充分验证SAM在医疗数据中的性能,Huang等人整理和组织了52个开源数据集,创建了COSMOS 1050K,这是一个大规模的医疗分割数据集,包含18个模态、84个objects、125个object-modality配对目标、1050K 2D图像和6033K掩模。(超大工程啊)对不同的SAM提示模式进行了综合实验,包括everything模式、point-based模式和box-based模式。结果表明,与everything模式相比,SAM在手动提示(即point和box)下对医学图像中的物体感知表现出更高的性能。此外,添加负点理论上应该提高性能,但在某些任务中会略微降低性能,特别是当背景对象与前景对象相似时。这一发现强调了基于领域知识明智地选择point提示以实现稳定性能改进的重要性。
Figure 3: SAM的zero-shot评估流程
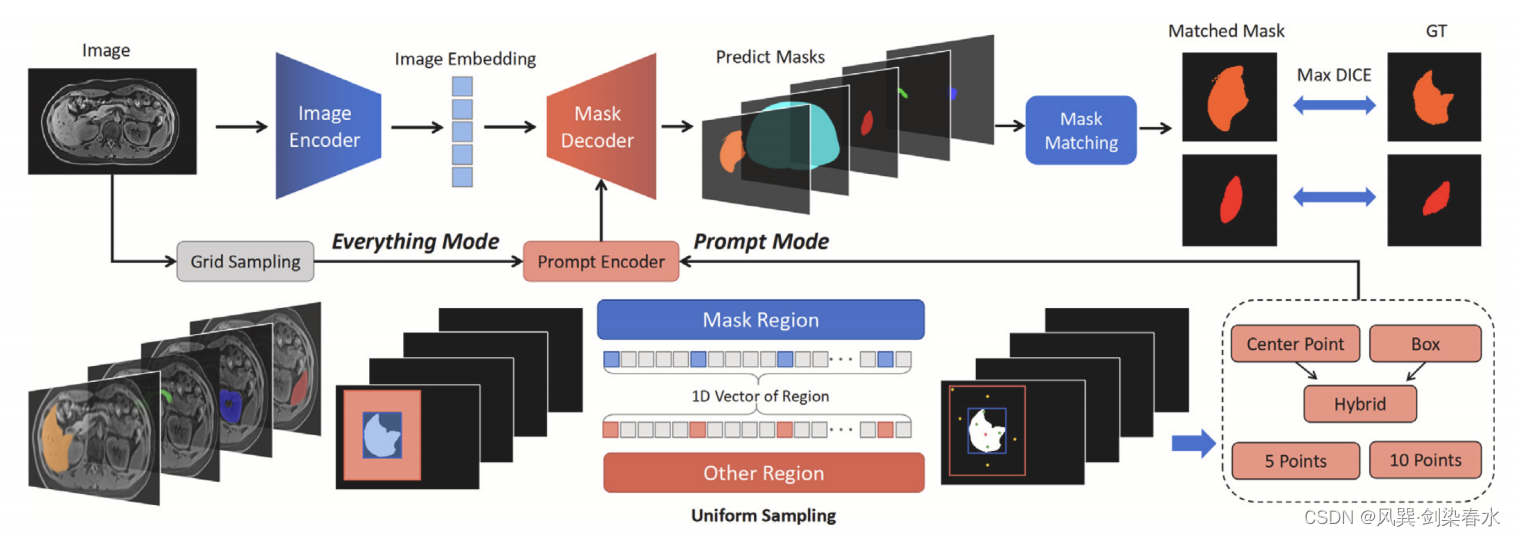
Figure 4:18种不同成像方式下SAM的分割结果

3.7 总结
本节中,回顾了最近的研究,探讨了SAM在不同医学图像分割任务中的zero-shot能力,并将其性能与现有的特定领域分割方法进行了比较。通常,SAM需要人工交互来实现适度的分割性能,这只需要几个point或box提示。不同数据集的评价结果表明,直接应用于医学图像分割的SAM泛化能力有限,在不同的数据集和任务之间差异显著。虽然SAM在某些成像模式中,识别边界良好的目标,表现出与SOTA方法相当的显著性能,但它在更具挑战性的情况下表现出缺陷或完全失败。当处理具有弱边界、低对比度、小尺寸和不规则形状的分割目标时,这一点尤其明显。(术业有专攻,通用就很难专精吧)对于大多数医学图像分割场景,SAM的分割性能低于标准,无法满足进一步应用的要求,特别是在一些要求极高精度的任务中。SA-1B数据集是SAM的训练数据,主要由边缘信息较强的自然图像组成,与医学图像有明显的不同。因此,在没有进行微调或再训练的情况下,直接应用SAM进行以前未见过的和具有挑战性的医学图像分割可能会产生有限的性能。(直接用不好使,还是需要微调的)
4、将SAM适配与医学图像分割
鉴于SAM的zero-shot转移到医学图像分割中一直存在的挑战,一个替代的研究方向出现了,强调提高SAM对各种医学图像分割任务的适应性。值得注意的是,很多研究注意力已经投入到改进2D和3D成像模式的SAM上,其中包括从头开始微调不同的SAM模块和类似SAM的训练架构。这些努力旨在提高SAM在医学图像分割任务中的性能,使其能够更好地适应不同的数据特征和复杂性。
4.1 在医学图像上微调
为了改善SAM在医学图像分割任务上不理想的性能,一种直接直观的方法是对医学图像上的SAM进行微调,包括全微调(full fine-tuning)和参数高效微调(parameter-efficient fine-tuning)。
4.1.1 全微调
将SAM用于医学图像分割的最直接的方法是,根据目标特定任务直接对SAM进行微调。
Hu等人对SAM进行了皮肤癌分割的微调验证,显示DSC评分从81.25%大幅提高到88.79%。(震惊)
Li等通过对SAM的所有组件进行微调,提出了 PolypSAM用于息肉分割,该方法在5个公共数据集上取得了优异的表现,DSC分数均在88%以上。
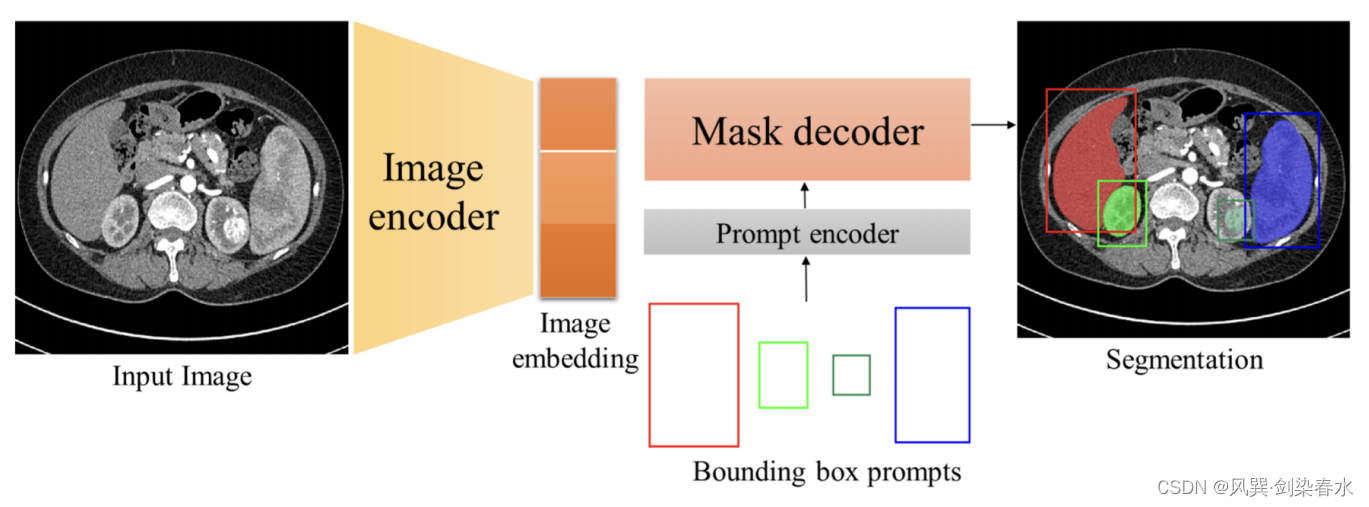
MedSAM被引入用于通用医学图像分割,它通过管理包含11种模式的超过100万医学图像对的综合数据集,以前所未有的规模改编了SAM。MedSAM在颅内出血CT、胶质瘤MR T1、气胸CXR和息肉内窥镜图像的分割任务中分别获得了94.0%、94.4%、81.5%和98.4%的中位DSC评分,超过了U-Net专家模型的表现。然而,MedSAM在分割血管状分支结构方面面临挑战,因为在这种情况下,box提示可能存在歧义。此外,它只将3D图像作为一系列2D切片处理,而不是作为体积处理。
Figure 5:MedSAM通过冻结提示编码器,同时微调图像编码器和掩码解码器,将SAM应用于医学图像分割
4.1.2 参数高效微调
更新SAM的所有参数是一个耗时、计算密集且具有挑战性的过程,因此不太适合广泛部署。因此,许多研究人员专注于使用各种参数高效微调(PEFT)技术对SAM的一小部分参数进行微调。Wu等提出了Medical SAM Adapter (Med-SA),它在将低秩自适应(low-rank adaptation, LoRA)模块集成到指定位置的同时,保持预先训练的SAM参数冻结,而不是完全调整所有参数。在5种不同模式的17种医学图像分割任务上进行的大量实验表明,MedSA优于SAM和以前的SOTA方法。
Figure 6:Medical SAM Adapter (Med-SA)以参数高效的方式将SAM用于医学图像分割
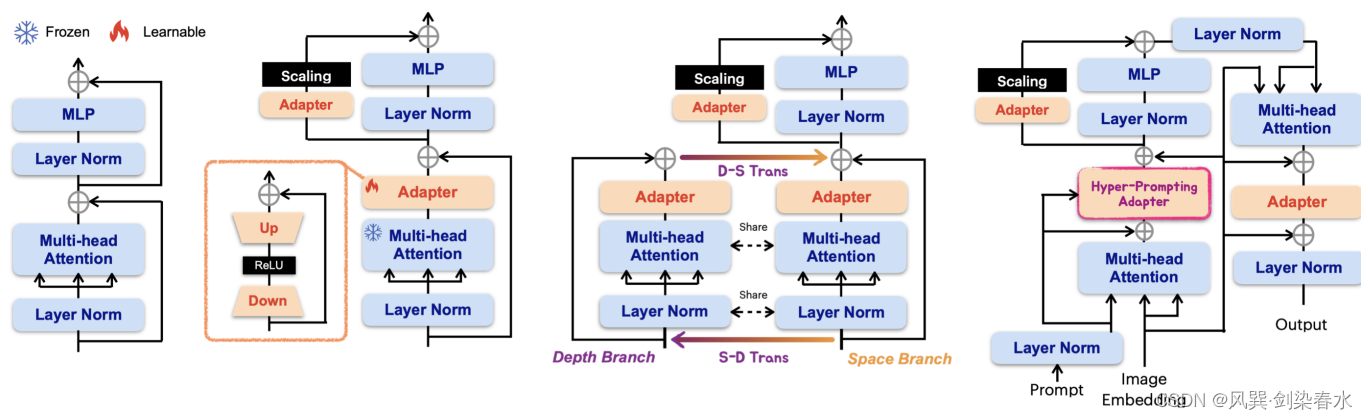
同样,SAMed将LoRA模块应用于预训练的SAM图像编码器,并在Synapse多器官分割数据集上,对prompt编码器和mask解码器一起进行微调。SAMed方法只更新了一小部分SAM参数,但与SOTA方法相比,它的DSC得分达到了81.88%。
Feng等人介绍了一种高效实用的方法,使用有限数量的样本对SAM进行微调,该方法结合了exemplar-guided synthesis module和LoRA微调策略,证明了即使在很少标记数据的情况下,SAM能在医疗领域内有效调整。
Paranjape等人提出了AdaptiveSAM,这是一种自适应调整,可以有效地使SAM适应新的数据集,并在医学领域实现文本提示分割。它采用 bias-tuning,可训练参数的数量比SAM少得多,同时利用自由格式的文本提示进行目标分割。实验表明,AdaptiveSAM在包括手术、超声和x光在内的各种医学成像数据集上优于当前的SOTA方法。
Cheng等为了桥接自然图像与医学图像之间巨大的域差距,引入了SAM-Med2D,这是将SAM应用于医学2D图像的最全面的研究,他们在image编码器中加入可学习的适配器层,对prompt编码器进行微调,并通过交互式训练更新mask解码器。他们收集并整理了一个医学图像分割数据集,其中包括超过4.6M图像和19.7M mask。通过对SAM-Med2D在不同形态、解剖结构和器官上的性能,以及在9个MICCAI 2023挑战数据集上的泛化能力进行综合评价和分析,表明其性能和泛化能力明显优于SAM。
Figure 7:SAM-Med2D冻结image编码器,同时引入可学习的适配器层,微调prompt编码器,并在训练期间更新mask解码器。
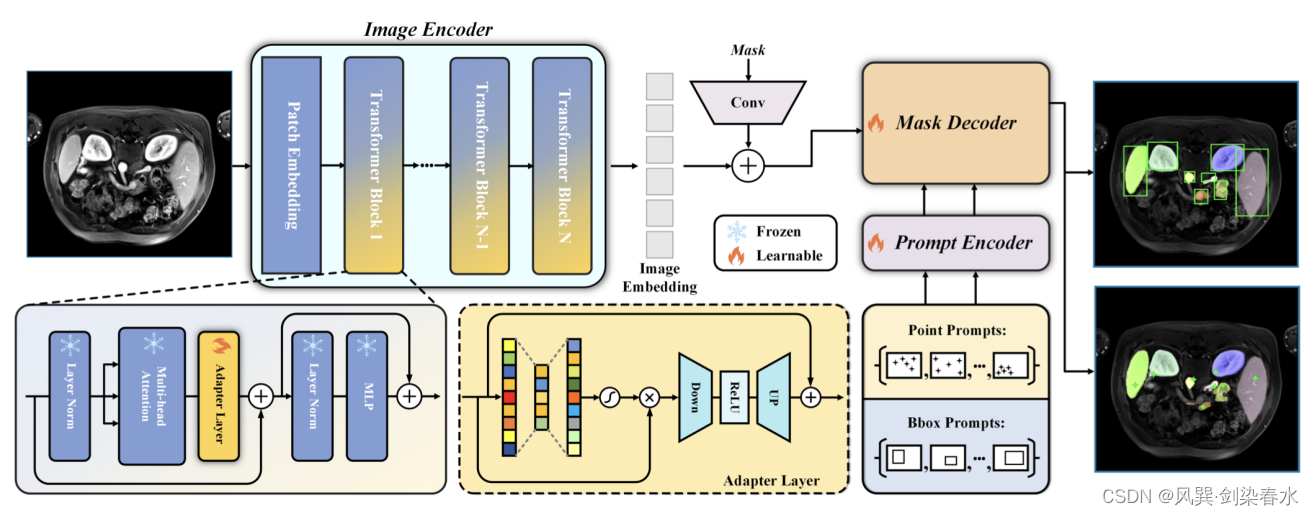
4.2 Auto-prompting Adaptation
虽然在某些情况下有效,但现有的SAM适应需要相对高质量的SAM典型prompts(即points、boxes和masks),才能在医学图像分割任务中获得可接受的性能。在大多数这些努力中,prompts都是在测试期间从ground truth生成的[13,69,14]。然而,创建准确可靠的prompts仍然需要来自医学专家的特定领域知识,而这些知识可能无法获得。在涉及众多类别的通用医学图像分割的背景下,这尤其具有挑战性。此外,由噪声注释引起的prompts提示会严重影响分割的准确性。因此,对自动prompts机制的探索,旨在建立一个强大的自适应框架,以减轻SAM性能的可变性,并有助于在医学图像分割中获得更可靠和准确的结果。(自动获取prompts)
4.2.1 Prompts自动生成
要实现自动Prompts,一种直接的方法是利用定位框架为SAM生成输入提示。为了在不同的医学成像数据集中分割感兴趣区域(ROI), Pandey等采用YOLOv8模型获得ROI边界框作为SAM的输入prompt,用于全自动医学图像分割。
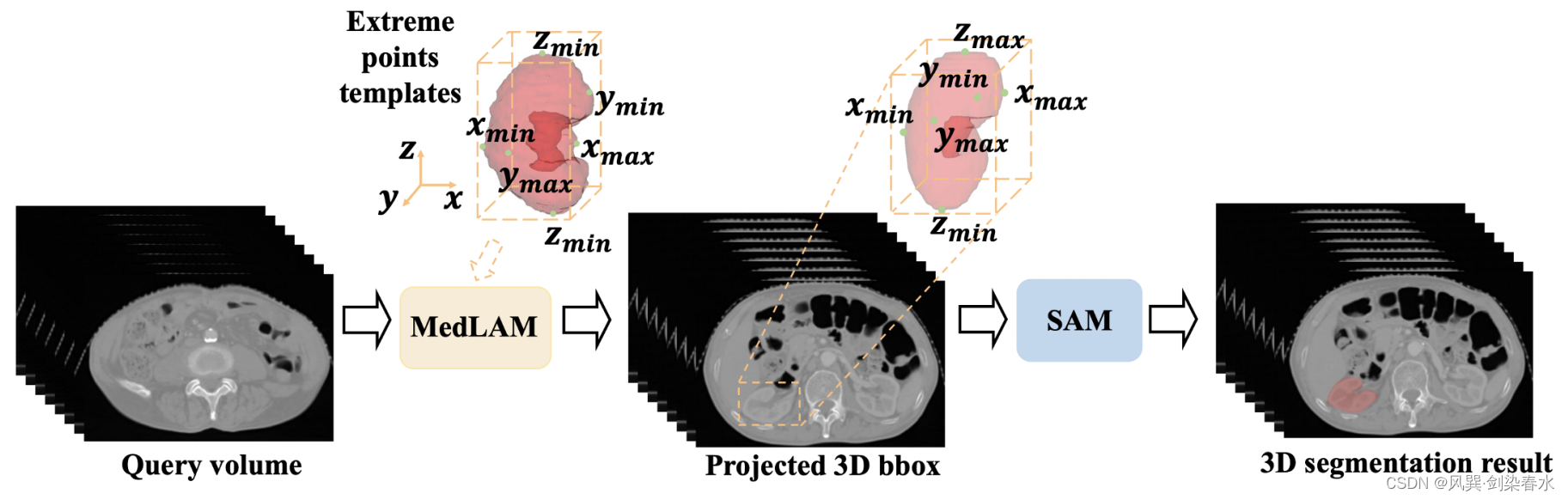
MedLSAM通过识别3D医学图像中包围感兴趣的任何解剖结构的3D边界框,应用了few-shot定位过程,这基于一个假设:局部像素分布相似的图像对应于不同个体的相同区域。(有点高级)随后,从三维box投影到每个切片上得到二维boxes,引导SAM自动分割目标解剖结构。
Figure 8:用于三维医学图像分割中box prompts自动生成的MedLSAM流水线。
Anand等人提出了一种one-shot定位和分割框架,利用与模板图像的对应关系来提示SAM。利用预训练的基于vit的foundation models从模板图像中提取dense features。
4.2.2 可学习的Prompts
AutoSAM通过训练一个辅助prompt编码器来生成代理prompt,而无需进一步微调SAM。辅助prompt编码器将输入图像本身的特征提取为条件prompts,扩展了典型prompts。通过这种策略,SAM变成了完全自动提示的方式,消除了手动prompts的必要性。AutoSAM在各种医学基准测试中具有SOTA的结果,展示了其在医学图像分割任务中的卓越性能。
allin-SAM pipeline首先利用预训练的SAM从弱prompts生成像素级注释,然后使用它们按照文献[75]中的策略对SAM进行微调。这样的pipeline在推理阶段不需要手动prompts,在核分割方面超越了以前的SOTA方法,与使用强逐像素注释数据相比,实现了具有竞争力的性能。
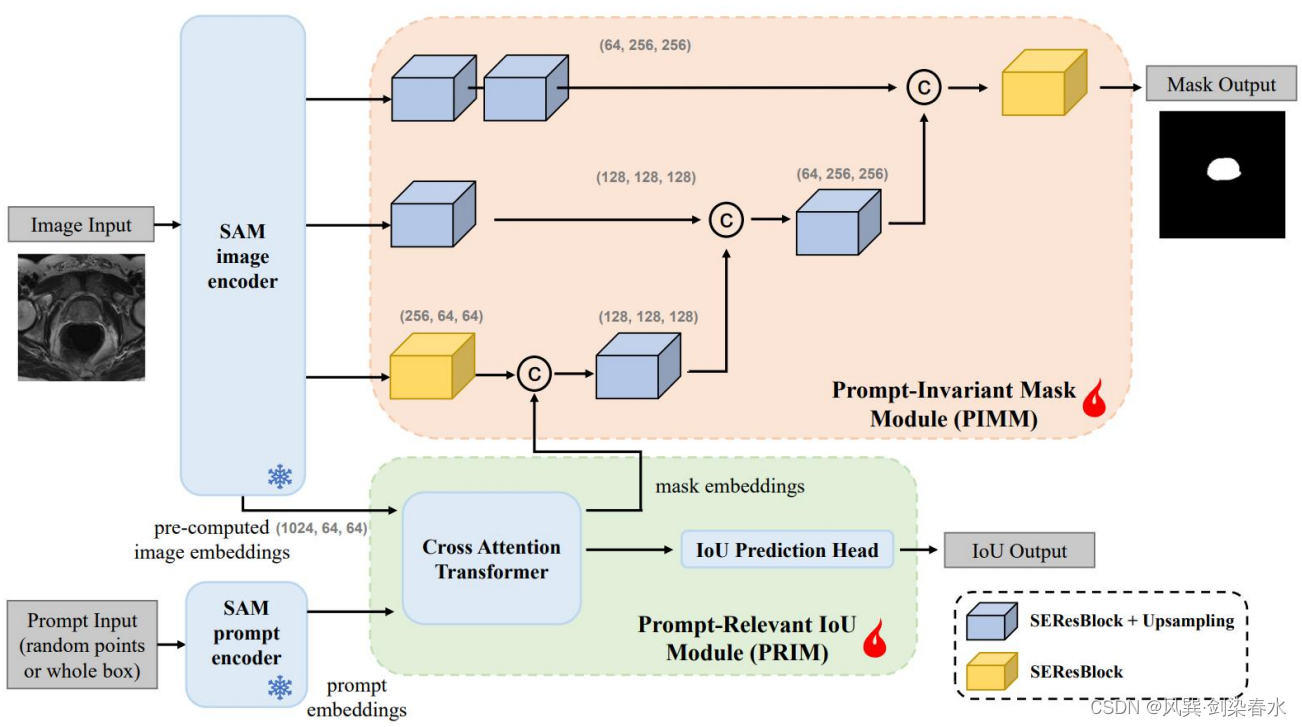
Gao等提出了解耦分割模型(Decoupling Segment Anything Model, DeSAM)来解决医学图像分割中poor prompts和mask分割的耦合效应。他们对SAM的mask解码器进行解耦,以执行两个子任务,包括一个基于给定prompt生成mask嵌入的Prompt-Relevant IoU模块(PRIM)和一个将image嵌入与mask嵌入融合以获得最终分割mask的Prompt-Invariant mask模块(PIMM)。(有点子绕)大量的实验表明,DeSAM可以提高全自动模式下SAM的的鲁棒性,平均DSC分数为8.96%。
Figure 9:DeSAM将mask解码器解耦为PIMM和PRIM
Yue等人介绍了SurgicalSAM,它通过使用轻量级的prototype-based class prompt编码器进行微调和contrastive prototype learning以获得更准确的class prompting,将特定于手术的信息与SAM的预训练知识集成在一起,从而改进了泛化。(不知道在说啥啊)在两个公共数据集上的大量实验结果表明,SurgicalSAM在只需要少量可调参数的情况下实现了SOTA性能。
4.2.3 增强不确定Prompts的可靠性
鉴于SAM对输入提示的敏感性,不确定度的估计是保证分割结果可靠性的关键。这在医学成像中尤其重要,其中分割准确性在临床程序中起着重要作用。
Xu等人提出了一种基于不确定性估计的无训练prompt生成方法EviPrompt,无需临床专家的交互,只需要单个image-annotation pair作为参考,即可自动为SAM生成prompts。
Deng等人提出了一种 multi-box prompt-triggered 的不确定性估计作为眼底图像分割SAM的测试时间增强技术。他们从多个box prompts生成不同的预测,通过蒙特卡罗模拟估计分布,并建立一个不确定性图,为潜在的分割错误提供指导,从而增强SAM对不同prompts的鲁棒性。
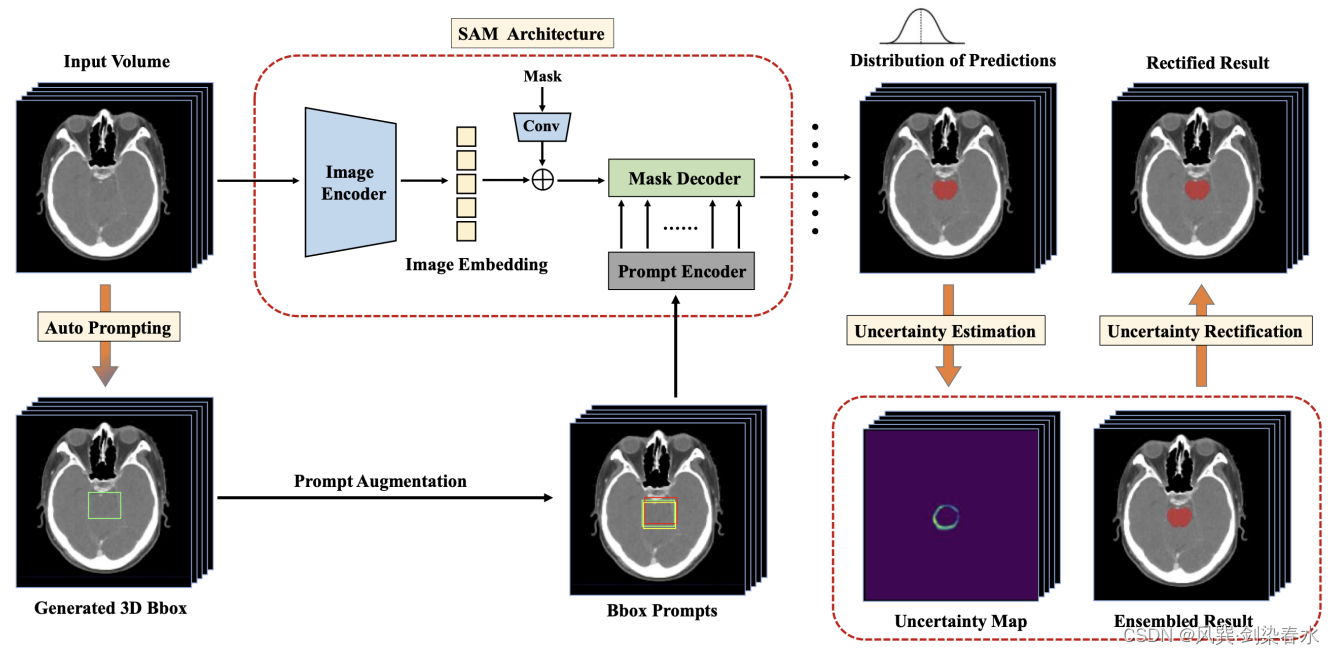
Zhang等提出了UR-SAM,一种不确定性校正的SAM框架,通过估计不确定性映射,并利用不确定性纠正可能的错误,提高 auto-prompting医学图像分割的鲁棒性和可靠性,从而改善分割结果。他们在涵盖35个器官分割的两个公共三维医学数据集上进行的实验表明,在没有人工prompts的情况下,估计和利用不确定性可以将分割性能提高10.7%和13.8%。
因此,不确定性的集成可以增强SAM对各种prompts的鲁棒性。估计的不确定性不仅有助于识别潜在的分割错误,而且为临床医生提供了有价值的指导,从而提高了分割的整体可靠性,促进了进一步的应用。
Figure 10:UR-SAM通过估计和利用不确定性来修正分割结果
4.3 框架调整
由于SAM是对自然图像分割进行预训练的强大基础模型,许多人试图通过修改其现有框架或将其无缝集成到新的训练方案中来利用SAM的能力,以构建先进的医学图像分割模型。
4.3.1 训练分割模型中的协同作用
Zhang等人提出了一个微调框架将SAM应用于数字病理的语义分割。SAM-Path为感兴趣的目标引入了可训练的classprompts,以及一个预先训练过的病理编码器,用于合并特定领域的知识,以弥补在SAM训练中缺乏全面的病理数据集。在CRAG数据集上的实验表明,与manual prompts的vanilla SAM相比,DSC得分相对提高了27.52%。
Chai等人利用了一种阶梯式微调方案,该方案将一个互补的CNN编码器与标准的SAM架构相结合,并且只专注于对额外的CNN和SAM解码器进行微调,以减少计算资源和训练时间。
Li等人提出了nnSAM,它将预训练的SAM模型作为即插即用模块与nnU-Net协同集成,以实现更准确和鲁棒的医学图像分割。
Zhang等人提出了SAMAug,它直接利用SAM生成的分割掩码来增强常用医学图像分割模型(如U-Net)的原始输入。在两个数据集上的实验表明,尽管SAM可能无法生成高质量的医学图像分割,但其生成的掩模和特征仍然有助于训练更好的医学图像分割模型。
Lin等人提出了SAMUS,通过引入一个并行的CNN分支,将局部特征注入到ViT编码器中。一个位置adapter和一个特征adapter,使SAM从大尺寸输入适应到小尺寸输入,以实现更多友好的临床部署。在一个包含30k图像和69k masks的综合超声数据集上进行评估,证明了其在超声图像分割中相对于SOTA特定任务模型和通用 foundation models 的优越性。
4.3.2 促进Annotation-efficient学习
由于医学图像分割的标注成本很高,需要有经验的临床专业人员的专业知识,因此人们在标注高效学习方面投入了大量精力,如半监督学习和弱监督学习。作为一种可靠的伪标签生成器,SAM为人工标注图像稀缺时的分割任务提供了新的机会。(角度新奇)
Zhang等人提出了一种迭代的半监督方法,该方法将SAM生成的分割建议与像素级和图像级领域特定知识相结合,用于构建未标记图像的注释。
为了产生可靠的伪标签,Li等人利用预训练的SAM进行与生成的伪标签一致的预测,并选择可靠的伪标签,进一步增强现有的半监督分割模型,在公开可用的ACDC数据集中5%的标记数据上,该模型分别比先进的两个基线提高了6.84%和10.76%。
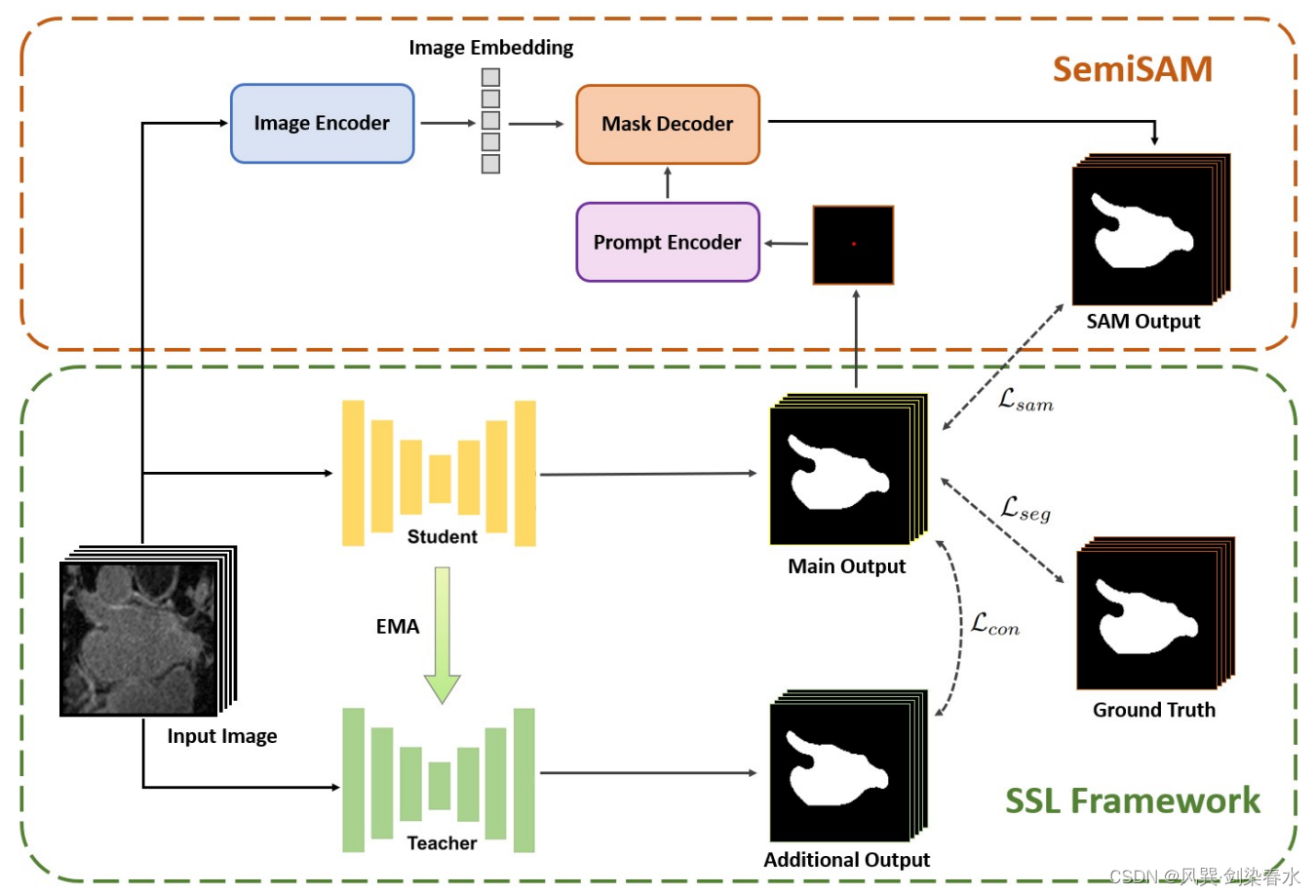
Zhang等人没有生成伪标签,而是提出了一种名为SemiSAM的半监督框架,其中经过领域知识训练的分割模型向SAM提供定位信息(即输入prompts),而SAM则作为额外的监督分支来协助一致性学习。在左心房MRI分割数据集上的实验结果表明,SemiSAM在标记数据极其有限的情况下取得了显著的改进。
Figure 11:SemiSAM探讨了使用SAM作为额外的监督分支来辅助半监督框架的学习过程
4.4 面向3D医学图像
直接利用具有固有2D架构的预训练SAM,往往会导致三维医学图像分割的次优结果,因为通过迁移学习进行的切片(2D)分割通常会丢弃3D医学图像中与深度相关的重要空间联系,而这对于识别某些物体以确保准确分割是极其重要的。为了解决这个问题,许多研究进行了具体的修改和增强,使SAM能够有效地处理3D医学图像模式。(走向3D应用)
4.4.1 从2D到3D的调整
为了实现2D到3D的调整,Medical SAM Adapter(Med-SA)引入了空间-深度转置(SDTrans)技术,其中通过捕获一个分支的空间相关性和另一个分支的深度相关性来利用分叉的注意力机制。
Gong等人提出了3DSAM-adapter,这是一种经过精心设计的SAM架构调整,用于支持3D医学图像分割,原始模型的可调参数(包括新增参数)仅为16.96%。实验结果表明,3DSAM-adapter在三个数据集上显著优于nnU-Net(肾肿瘤优于8.25%,胰腺肿瘤优于29.87%,结肠癌优于10.11%)。
Chen等人引入了一种模态无关的SAM自适应框架(MASAM),适用于各种体积和视频医疗数据,它将一系列可调的3D adapters注入图像编码器的每个 transformer 块,并将它们与mask解码器一起进行微调。在10个数据集上进行的大量实验表明,MA-SAM在不使用任何提示的情况下始终优于各种最先进的3D方法,并且在CT多器官分割、MRI前列腺分割和手术场景分割的DSC分数上分别超过nnUNet 0.9%、2.6%和9.9%。
Li等提出了一种prompt-driven的三维医学图像分割模型(ProMISe),该模型插入轻量级adapters来提取与深度相关的空间联系,而无需更新预训练的三维医学图像分割权值。对ProMISe在结肠和胰腺肿瘤分割数据集上的评估表明,与SOTA方法相比,ProMISe具有更优越的性能。
Bui等人介绍了SAM3D,该方法最初应用SAM单独处理每个输入 slices,产生 slices embeddings,并通过轻量级3D解码器对其进行解码,最终得到分割结果。
4.4.2 从头开始训练
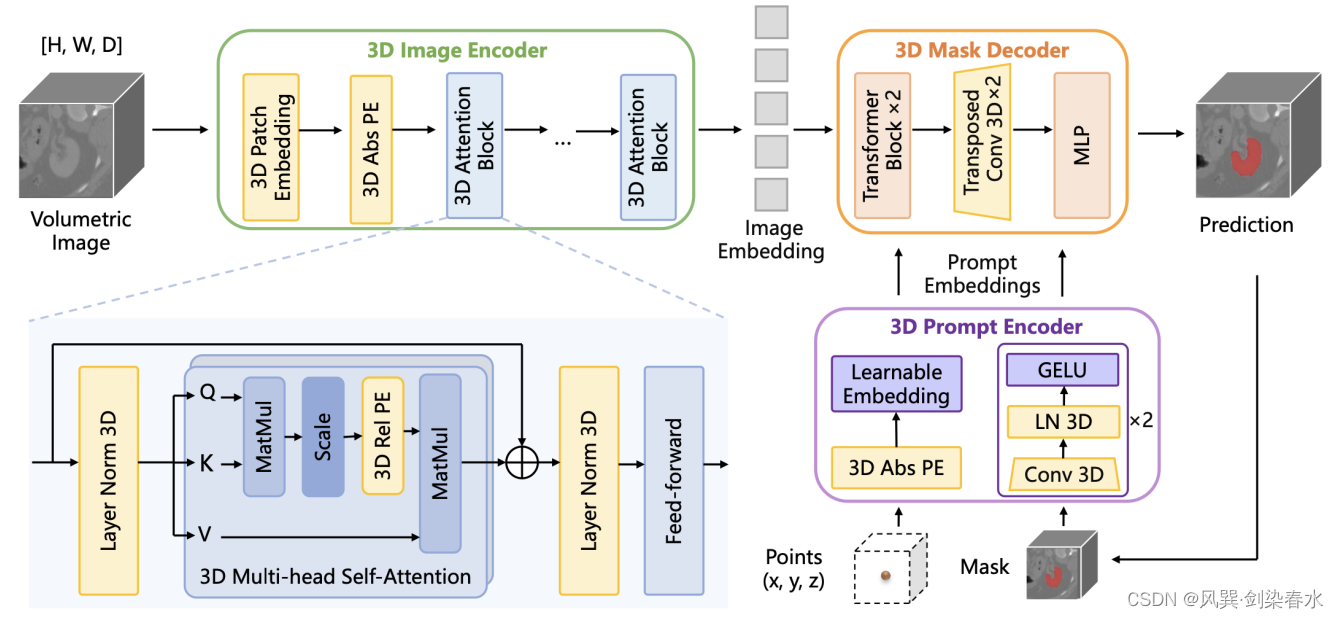
与通过2D到3D的适应来捕获3D空间信息的工作相反,Wang等人提出SAM-Med3D,具有完全可学习的3D SAM类架构的医学图像分割模型。SAM-Med3D是在一个大型3D数据集上训练的,该数据集包括21K医学图像和131K mask,具有247个类别。迄今为止,最全面的评估是利用15个公共数据集进行的,显示了其竞争性能,它的prompt points明显少于在医疗领域表现最好的微调SAM。
Figure 12:SAM-Med3D将SAM的原始2D组件转换为对应3D组件,包括3D image编码器、3D prompt编码器和3D mask解码器
基于SAM的架构,Du等人提出了一种交互式体积医学图像分割模型SegVol,用于CT体积分割。通过对90k个未标记CT序列和6k个标记CT序列进行训练,SegVol支持使用空间和文本prompts,对200多个解剖类别进行分割,并且在多个分割基准上大大优于SOTA方法。
4.5 总结
本节中,回顾了SAM适应医学图像分割的当前研究现状,其中包括几个不同但相互关联的方面。一些研究深入研究了微调策略,直接定制SAM的参数,专门用于医学图像分割。Auto-prompting adaptation探索自动prompt机制,以提高SAM的灵活性和鲁棒性。框架修改方法旨在改进SAM的架构或集成到新的训练框架中,确保在医学图像分割场景中的最佳性能。
此外,一个关键的探索是将SAM扩展到处理3D医学图像方面,这是为了克服其最初主要处理2D数据的局限性。这些方向中的每一个都增强了SAM在解决医学图像分割任务中固有的各种特征和复杂性方面的有效性,在各种模式和感兴趣的目标上优于特定于任务的模型。
5、讨论和结论
本文中,概述了最近将SAM应用于医学图像分割任务的工作。当直接使用SAM进行医学图像分割而不进行任何自适应时,不同数据集和任务的性能差异很大,这表明SAM在多模态和多目标医学数据集上一致准确地实现zero-shot分割是一个挑战。
成像方式和感兴趣目标的复杂性和多样性会影响SAM的分割效果,特别是对于形状不规则、边界弱、尺寸小或对比度低的物体,会出现次优结果。SAM的分割性能通常不足,特别是在医学图像分割中,需要极高的精度。
为了弥合自然图像和医学图像之间的巨大领域差距,一些研究探索了合适的适应策略,可以在一定程度上提高SAM的分割结果,与特定任务模型相比,具有竞争力的性能。虽然SAM目前的表现有时可能缺乏特定任务模型的稳定性,但我们相信它具有强大的潜力,可以作为一种有效的工具,在临床场景中推进有价值的应用。尽管取得了成功,但仍存在挑战,故概述了增强和改进的潜在未来方向如下。
5.1 构建大规模医疗数据集
几项研究在不同数据集和模式下的评估结果表明,由于自然图像和医学图像之间存在显著差异,直接将SAM应用于医学图像分割并不能产生令人满意的效果。尽管在特定医疗数据集上微调SAM可以提高性能,但在推广到其他任务时,其性能仍然受到限制。(数据集是个永恒的话题)
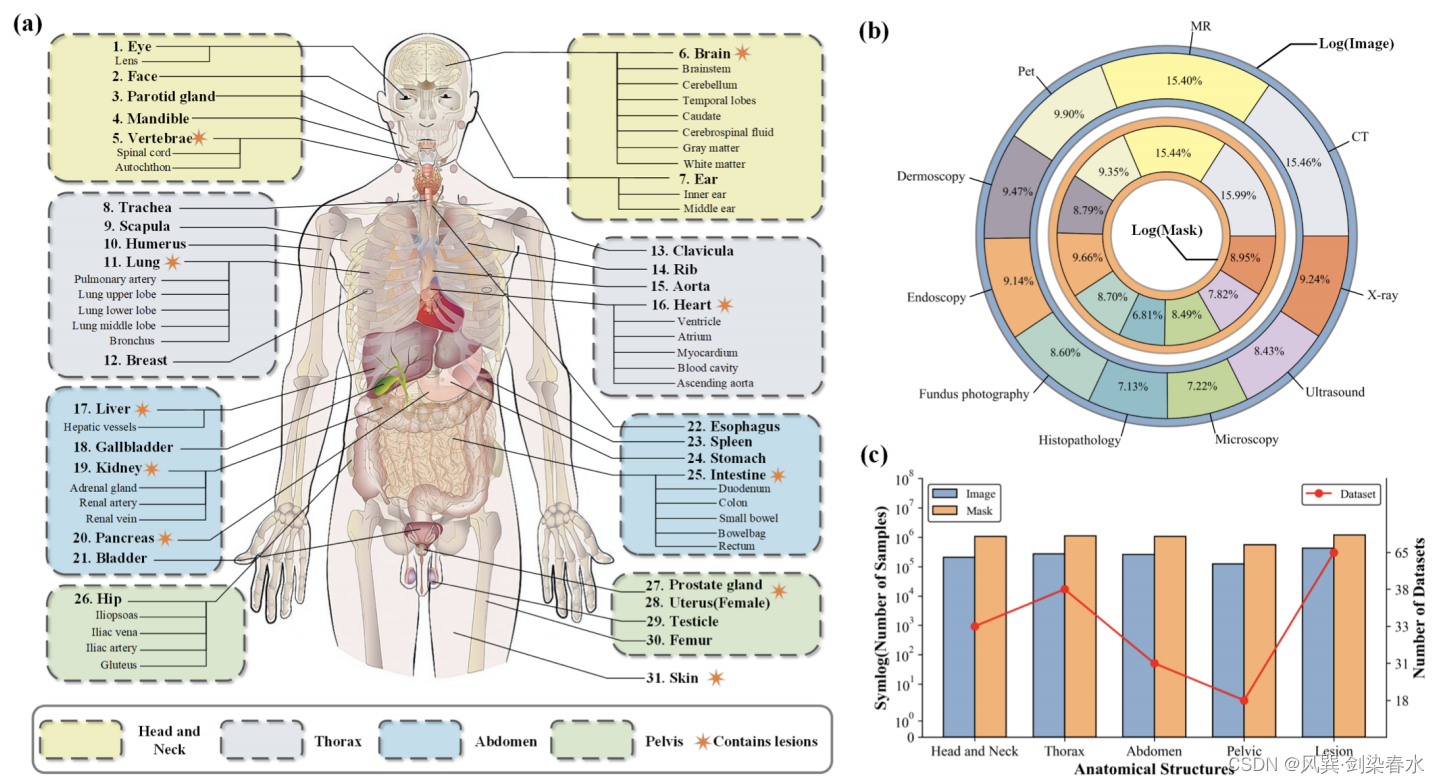
为了解决这一问题,构建包含各种模式和感兴趣目标的大规模医学数据集对于开发通用医学分割 foundation models至关重要。最近的一些研究侧重于通过收集现有的公共数据集和发布私有数据集来创建大规模医疗数据集。一个显著的例子是SA-Med2D-20M Dataset,是最近公开的大规模二维医学图像分割数据集,有4.6M二维医学图像和19.7M对应的mask。
Figure 13:SA-Med2D-20M数据集
5.2 加速医学图像标注
大规模医学数据集的构建对于医学基础模型的开发至关重要,但庞大的标注成本给大规模医学数据集的构建带来了巨大的挑战。为医学图像开发分割模型通常需要特定领域的专业知识来提供可靠和准确的注释,与自然图像相比,这增加了昂贵的标注成本。这在常用的3D医学数据中尤其明显,专家必须一丝不苟地逐片勾画目标,这给注释过程带来了密集劳动和耗时的工作量。
虽然SAM生成的分割结果并不总是完美的,但仍然可以考虑使用这些分割掩码来加速标注过程。专家可以利用SAM实现粗分割,然后手动修改分割,实现快速交互分割,而不是从头开始标记目标。最近的几项研究也在探索这一方向。例如,Liu等人将SAM扩展到常用的医学图像查看器3D Slicer中,使研究人员能够仅以0.6秒的延迟对医学图像进行分割。当一个切片的分割完成后,通过prompt的分割过程可以自动应用于下一个切片。
Wang等人]提出了 S A M M e d {SAM^{Med}} SAMMed框架,利用SAM进行医学图像标注,它由两个子模块组成:自动标注生成模块 S A M a u t o {SAM^{auto}} SAMauto和用户协助模块 S A M a s s i t {SAM^{assit}} SAMassit,
Shen等人通过自适应地为人类专家提供合适的prompt形式,利用SAM的zero-shot功能,采用一种名为临时扩展提示优化(temporally-extended prompts optimization, TEPO)的创新强化学习框架,进行交互式医学图像分割。
Huang等人提出了一种标签损坏框架(label corruption framework),利用一种新的噪声检测模块,通过基于不确定性的自校正来区分噪声标签和干净标签,从而突破基于SAM的伪标签校正分割的边界。
Ning等利用SAM辅助下的半自动标注工作流程,加快了光学相干断层扫描血管造影(OCTA)的标注过程。
5.3 结合Scribble和Text Prompts
一些实证研究表明,与point prompts相比,使用box prompts往往会产生更好的结果,因为它获取了相对更准确的位置信息。然而,如果在分割目标周围存在多个相似的实例,那么使用一个大的边界框可能会引入混淆,从而可能导致不准确的分割结果。除了point prompts和box prompts外,通过scribble prompts的交互在医学图像分割中也很普遍,当将其纳入SAM中时,它是有用且高效的。
将scribble prompts与point prompts或box prompts相结合,是一种直观而有效的策略,可以处理不规则形状不规则的非紧凑目标,特别是对于具有连续性和弯曲特征的血管、肠道和骨骼。除了位置信息prompts外,文本prompts也作为一种将临床知识注入医学图像分割的直观方式出现。例如,Zhao等人通过构建多模态医学知识树来组合多个知识来源,将文本prompts信息整合到SAM中,可应用于跨不同模态、解剖结构和身体区域的医学图像分割任务。
Figure 14:SAT (Segment Anything with Text) 利用文本prompts作为查询

Figure 15:ScribblePrompt使用 scribbles, clicks, 和 boxes 进行交互式医学图像分割
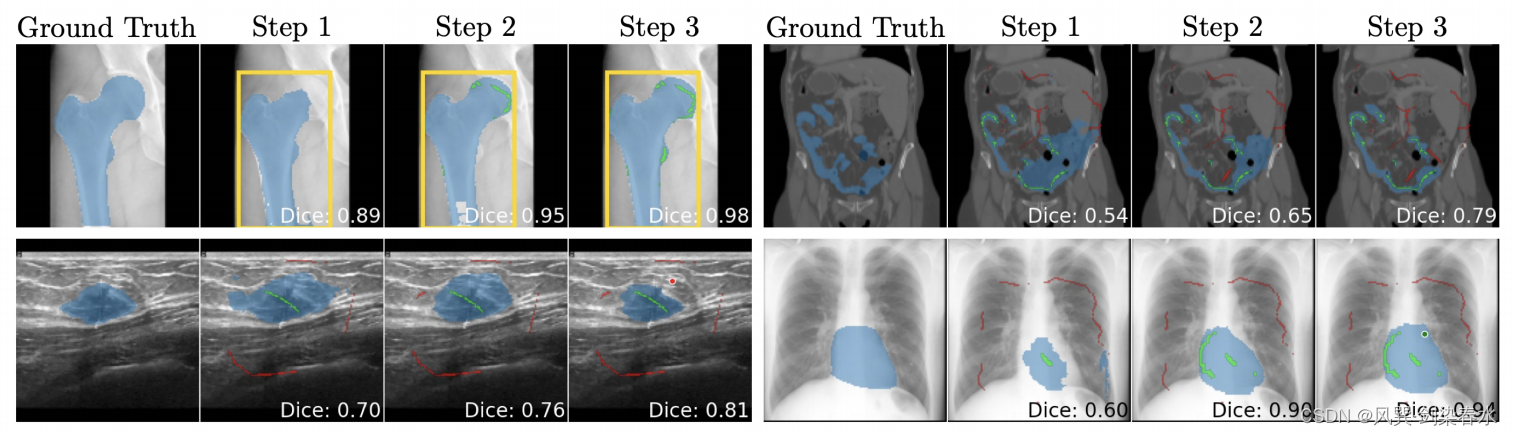
5.4 面向多模态医学图像
多模态医学图像在临床应用中发挥着至关重要的作用,因为它们能够提供有关人体解剖、功能和病理的补充信息。例如,通过将结构MRI与功能MRI (fMRI)相结合,临床医生可以评估组织的解剖结构和功能特性。将PET图像与相应的CT或MRI扫描相结合,可以同时评估代谢活动(来自PET)和详细的解剖定位(来自CT或MRI)。这在肿瘤学中广泛应用,精确识别和表征肿瘤,确定其代谢活性,评估其与周围组织的关系,从而实现更准确的诊断和治疗计划。将SAM扩展到从不同的输入模式中学习表示,可以潜在地改善不同患者群体和成像方式之间的泛化,使其成为推进临床应用的一种很有前途的方法。
5.5 辅助更多的临床应用
除了将SAM用于医学图像分割任务的现有方法外,一些研究人员正在探索将其整合到更多的临床应用中,以处理各种任务。其中一个应用GazeSAM,研究了SAM和眼球追踪技术的集成,设计了一个人机协作交互系统,使放射科医生能够通过观察感兴趣的区域获得分割masks。
Ning等人讨论了SAM在实现通用智能超声图像引导方面的潜在贡献。
Jiang等人提出了一种基于SAM的human-in-the-loop, label-free的早期DR诊断框架,可以实现实时分割。
Song等人利用SAM的语义先验来监督MRI跨模态合成和图像超分辨率统一框架的训练,确保合成过程中解剖结构的真实。
SAM的初步分割能力在识别需要深入审查的复杂病例方面也证明是有价值的,可以减轻临床专家的负担。此外,SAM可以帮助最小化观察者之间的可变性,这是manual contouring中普遍存在的问题。
5.6 总结
在过去的一年里,SAM在医学图像分割方面取得了前所未有的发展,极大地推动了医学图像分析通用foundation models的发展。本综述旨在为医学图像分割foundation models的发展轨迹提供有价值的见解。这一总结将促进对未来方向的更深入理解,并激发旨在创造临床应用人工智能的进一步研究。



