
MySQL--分组查询获取每组最新的一条数据(group by)
业务场景:
最近项目中迭代一个旧的功能,再原有的设计上进行功能拓展(因成本等原因,不考虑项目重构),其中设计到了这么一个场景,同一个业务 ID 在同一张表中有 N 条数据,需要查询出最新的那一条数据。
解决方案:
- 使用 group by id, 再按时间或者 id 降序,理论上就可以获取最新的数据。
- 每个业务 id 都去数据库查询一次,再按时间降序,最后 limit 1,就可以获取到最新的数据(这个方案一般在项目中是不考虑的)。
- 使用 group by id。。。这里先卖个关子。
group by id 方案验证:
test 表是主键自增的。
先查看数据:
select id,kpa_id,progress from test where kpa_id=10;
执行结果:
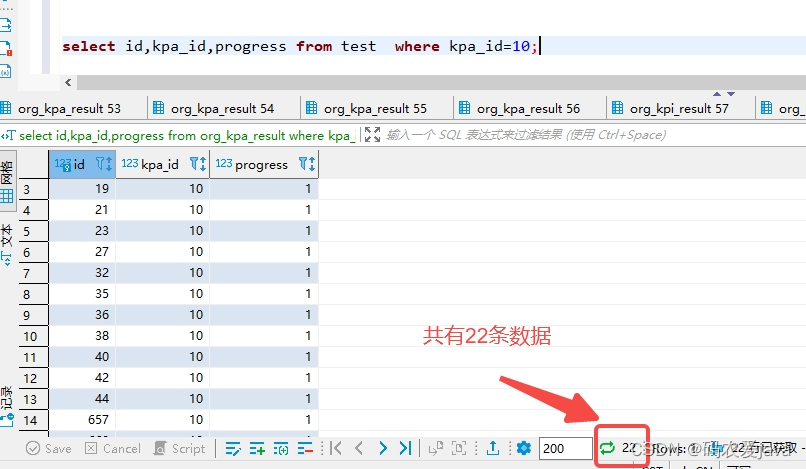
可知同一个业务 ID 查询结果有22条数据。
group by id 获取最新的一条数据,SQL如下:
select id,kpa_id,progress from test where kpa_id=10 group by kpa_id order by id desc;
执行结果:
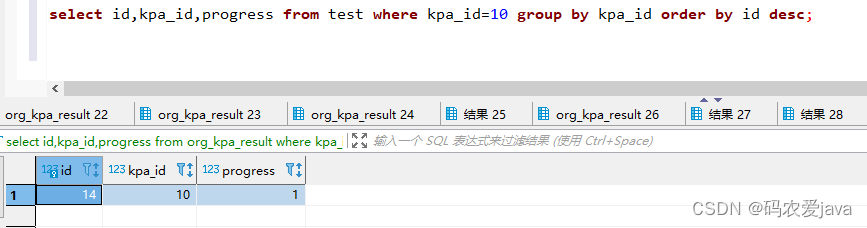
很明显没有获取到最新的一条数据,该方案不可行。
再次换一种SQL语法,如下:
select id,kpa_id,progress from (select * from test order by id desc)t where kpa_id=10 group by kpa_id;
执行结果:

很明显还是没有获取到最新的一条数据,该方案仍然不可行,那怎么样才可以实现呢?
那怎么样才可以实现呢?
分析:既然要获取最新的数据,id自增,时间也是顺序的,最新的数据是不是意味这就是 id 或者时间最大的那条数据?MySQL 中获取最大的值使用 max()函数既可,下面我们来验证一下。****
使用 max 函数获取最大的 id,SQL 如下:
select id,kpa_id,progress from test where id in(select max(id) from test where kpa_id=10 group by kpa_id);
执行结果如下:

结果显而易见,获取到了最大的那条数据,功能已经实现,但是子查询的效率比较低,我们还有没有更高效的方法呢?
使用 inner join 内连接,如下:
SQL如下:
select t1.id, t1.kpa_id, t1.progress from org_kpa_result t1 inner join ( select max(id) as id from org_kpa_result where kpa_id = 10 group by kpa_id) t2 on t1.id = t2.id;
执行结果如下:
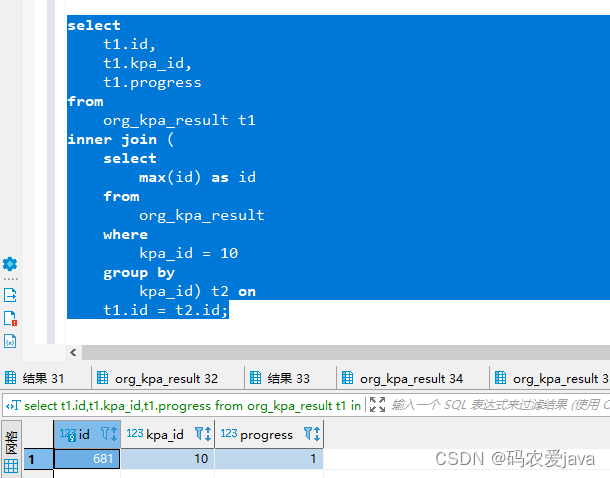
查询结果是一样的,但是我们都知道 inner join 内连接的查询效率要由于子查询,故推荐使用该方法实现。
如有不正确的地方请各位指出纠正。
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



