
Tensorflow2.0笔记 - 循环神经网络RNN做IMDB评价分析
本笔记记录使用SimpleRNNCell做一个IMDB评价系统情感二分类问题的例子。
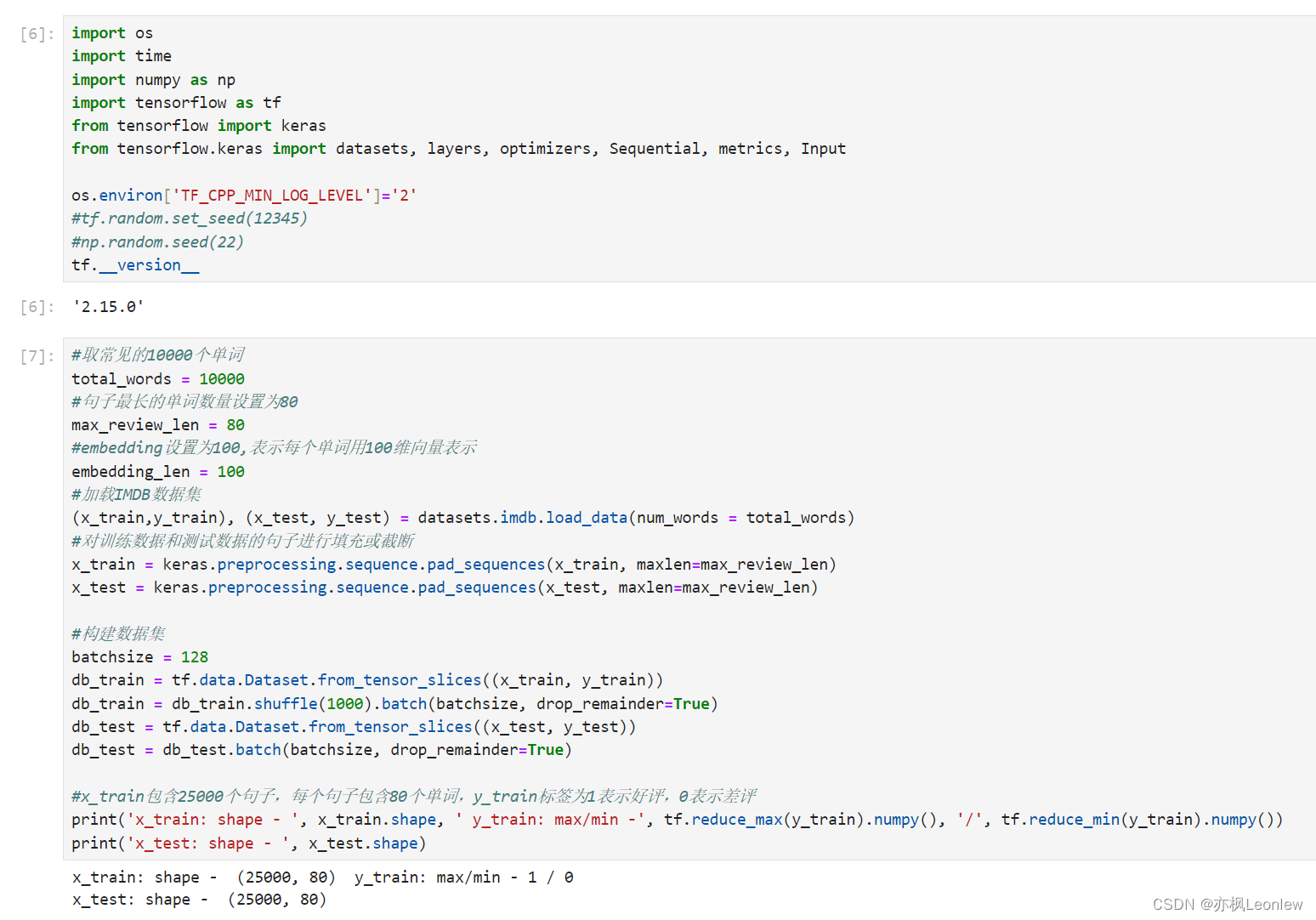
import os
import time
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, optimizers, Sequential, metrics, Input
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
#tf.random.set_seed(12345)
#np.random.seed(22)
tf.__version__
#取常见的10000个单词
total_words = 10000
#句子最长的单词数量设置为80
max_review_len = 80
#embedding设置为100,表示每个单词用100维向量表示
embedding_len = 100
#加载IMDB数据集
(x_train,y_train), (x_test, y_test) = datasets.imdb.load_data(num_words = total_words)
#对训练数据和测试数据的句子进行填充或截断
x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len)
x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len)
#构建数据集
batchsize = 128
db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
db_train = db_train.shuffle(1000).batch(batchsize, drop_remainder=True)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.batch(batchsize, drop_remainder=True)
#x_train包含25000个句子,每个句子包含80个单词,y_train标签为1表示好评,0表示差评
print('x_train: shape - ', x_train.shape, ' y_train: max/min -', tf.reduce_max(y_train).numpy(), '/', tf.reduce_min(y_train).numpy())
print('x_test: shape - ', x_test.shape)
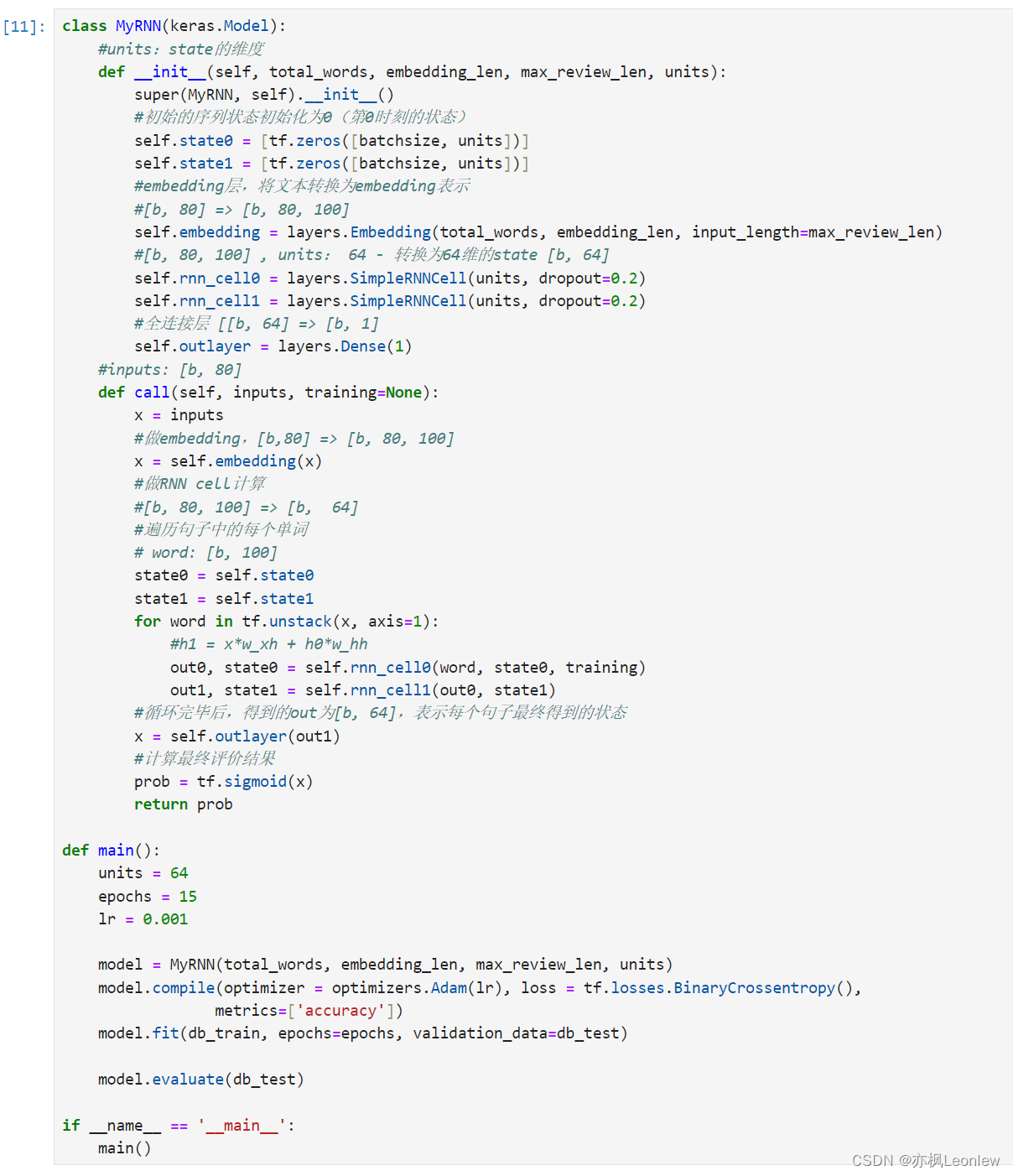
class MyRNN(keras.Model):
#units:state的维度
def __init__(self, total_words, embedding_len, max_review_len, units):
super(MyRNN, self).__init__()
#初始的序列状态初始化为0(第0时刻的状态)
self.state0 = [tf.zeros([batchsize, units])]
self.state1 = [tf.zeros([batchsize, units])]
#embedding层,将文本转换为embedding表示
#[b, 80] => [b, 80, 100]
self.embedding = layers.Embedding(total_words, embedding_len, input_length=max_review_len)
#[b, 80, 100] , units: 64 - 转换为64维的state [b, 64]
self.rnn_cell0 = layers.SimpleRNNCell(units, dropout=0.2)
self.rnn_cell1 = layers.SimpleRNNCell(units, dropout=0.2)
#全连接层 [[b, 64] => [b, 1]
self.outlayer = layers.Dense(1)
#inputs: [b, 80]
def call(self, inputs, training=None):
x = inputs
#做embedding,[b,80] => [b, 80, 100]
x = self.embedding(x)
#做RNN cell计算
#[b, 80, 100] => [b, 64]
#遍历句子中的每个单词
# word: [b, 100]
state0 = self.state0
state1 = self.state1
for word in tf.unstack(x, axis=1):
#h1 = x*w_xh + h0*w_hh
out0, state0 = self.rnn_cell0(word, state0, training)
out1, state1 = self.rnn_cell1(out0, state1, training)
#循环完毕后,得到的out为[b, 64],表示每个句子最终得到的状态
x = self.outlayer(out1)
#计算最终评价结果
prob = tf.sigmoid(x)
return prob
def main():
units = 64
epochs = 15
lr = 0.001
model = MyRNN(total_words, embedding_len, max_review_len, units)
model.compile(optimizer = optimizers.Adam(lr), loss = tf.losses.BinaryCrossentropy(),
metrics=['accuracy'])
model.fit(db_train, epochs=epochs, validation_data=db_test)
model.evaluate(db_test)
if __name__ == '__main__':
main()
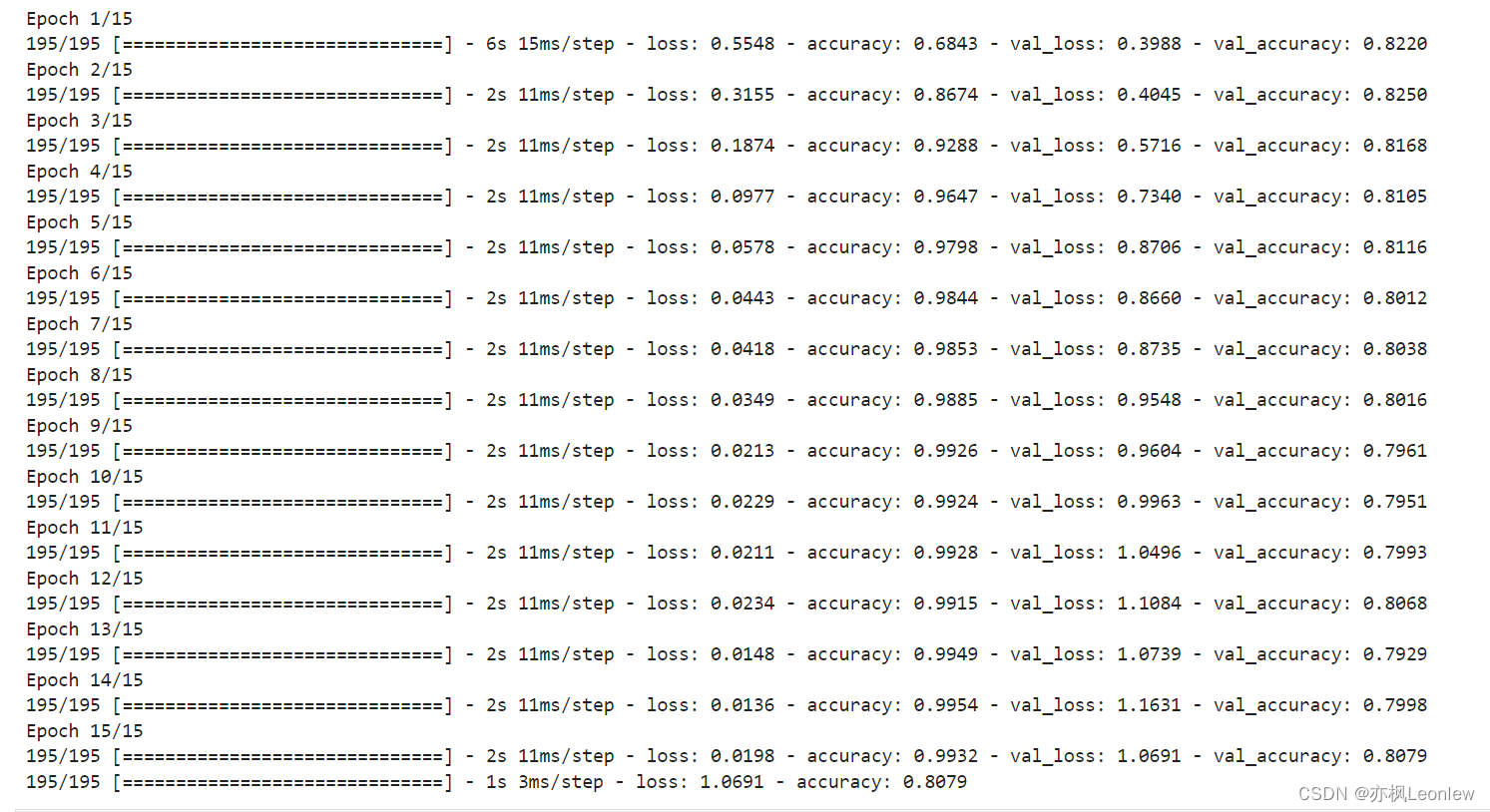
运行结果:
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



