
【编译原理】LL(1)分析法:C/C++实现



 🔖墨香寄清辞:空谷幽篁风动,梦中仙鹤月明。 辗转千秋豪情在,乘风翱翔志不移。
🔖墨香寄清辞:空谷幽篁风动,梦中仙鹤月明。 辗转千秋豪情在,乘风翱翔志不移。


目录
1. 编译原理之LL(1)分析法概念
1.1 编译原理
1.2 LL(1)分析法
2. LL(1)分析法
2.1 实验目的
2.2 实验要求
2.3 实验内容
2.3.1 实验解决代码
2.3.2 运行结果
2.3.3 详细代码分析
2.3.3.1 init()函数
2.3.3.2 analyse()函数
2.4 实验心得
1. 编译原理之LL(1)分析法概念
1.1 编译原理
编译原理是计算机科学领域的一个重要分支,它研究如何将高级编程语言的源代码转化成计算机能够执行的机器代码或中间代码的过程。编译原理涵盖了编译器的设计和实现,其中编译器是一种将源代码翻译成目标代码的软件工具。编译器的主要任务包括语法分析、词法分析、语义分析、优化和代码生成等环节。
1.2 LL(1)分析法
LL(1)分析法是一种常用的自顶向下的语法分析方法,用于分析和解释编程语言或其他形式的文本。LL(1)代表"Left-to-Right, Leftmost derivation, 1 symbol lookahead",这表示了分析器的工作方式和限制条件,通常用于编程语言的语法分析,编写编译器或解释器。主要步骤包括构建LL(1)文法、构建LL(1)分析表和使用递归下降分析或预测分析器等算法来分析输入文本。
🔥 资源获取:关注公众号【科创视野】回复 LL分析法源码
🔥 相关博文:编译原理之逆波兰式的产生及计算:C/C++实现(附源码+详解!)
2. LL(1)分析法
2.1 实验目的
(1)加深对预测分析LL(1)分析法的理解;
(2)根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串分析。
2.2 实验要求
实验规定对下列文法,用LL(1)分析法对任意输入的符号串进行分析,具体文法如下:
(1)E::=TG
(2)G::=+TG
(3)G::=ε
(4)T::=FS
(5)S::=*FS
(6)S::=ε
(7)F::=(E)
(8)F::=i
若输入串为
i+i*i#
则输出:
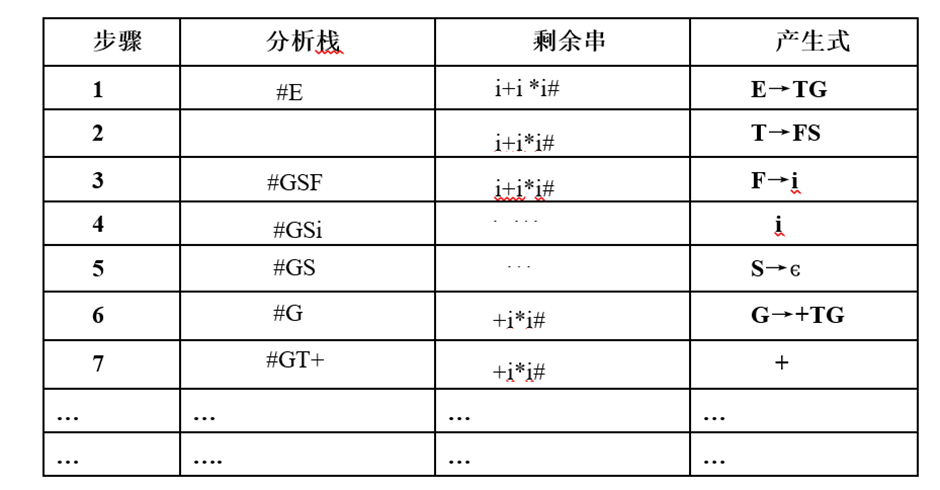
LL(1)的分析表:
| i | + | * | ( | ) | # | 说 明 | |
| E | e | e | Select(E→TG)={(,i} | ||||
| G | g | g1 | g1 | Select (G→+TG)={+} Select (G→є)={#,)} | |||
| T | t | t | Select (T→FS)={(,i} | ||||
| S | s1 | s | s1 | s1 | Select (S→*FS)={*}Select (S→є)={#,) +} | ||
| F | f1 | F | Select (F→(E))={(} Select (F→i)={i} |
参考代码(不完整):
do/*读入分析串*/
{
scanf("%c",&ch);
if ((ch!='i') &&(ch!='+') &&(ch!='*')&&(ch!='(')&&(ch!=')')&&(ch!='#'))
{
printf("输入串中有非法字符\n");
exit(1);
}
B[j]=ch;
j++;
}while(ch!='#');
l=j;/*分析串长度*/
ch=B[0];/*当前分析字符*/
A[top]='#'; A[++top]='E';/*'#','E'进栈*/
printf("步骤\t\t分析栈 \t\t剩余字符 \t\t所用产生式 \n");
do
{
x=A[top--];/*x为当前栈顶字符*/
printf("%d",k++);
printf("\t\t");
}
for(j=0;j


