
探索异常传播:深入剖析Python中的错误处理机制



文章目录
- 1. 异常传播的基本原理
- 2. 复杂的异常传播场景
- 3. 再次抛出异常的意义是什么?
- 4. 最佳实践与异常处理策略
理解异常传播(也称为异常冒泡)的过程是至关重要的。这一机制确保当在程序执行中发生错误时,错误能被有效地捕获和处理,从而防止程序崩溃并提供错误恢复的机会。本文将详细探讨Python中的异常传播,包括它是如何工作的,以及如何正确地管理异常。
1. 异常传播的基本原理
当发生异常时,如果在当前执行环境中没有捕获该异常,异常将会向上冒泡至上一层的执行环境。这一过程会持续进行,直到找到相应的异常处理代码块,或者达到最外层的执行环境(通常是程序的最顶层),导致程序终止并可能输出错误信息。
简单的异常传播示例
def func1(): print("函数 func1 开始执行") raise ValueError("一个由 func1 引发的 ValueError") def func2(): print("函数 func2 开始执行") func1() try: func2() except ValueError as e: print(f"捕获到异常: {e}")在这个示例中,func1 中抛出了一个 ValueError 异常,但并未在该函数内部处理。异常随后传播到调用者 func2,func2 也未处理此异常,继续向上传播。最终,在 try-except 块中成功捕获并处理了该异常。
异常传播的细节理解
通过上述例子,可以看到异常是如何在函数调用栈中向上传递的。每一层函数调用都有机会处理从其内部函数传递上来的异常。如果某一层没有处理,异常就会继续向上传递,直到找到适当的处理代码或达到程序的顶层。
图解
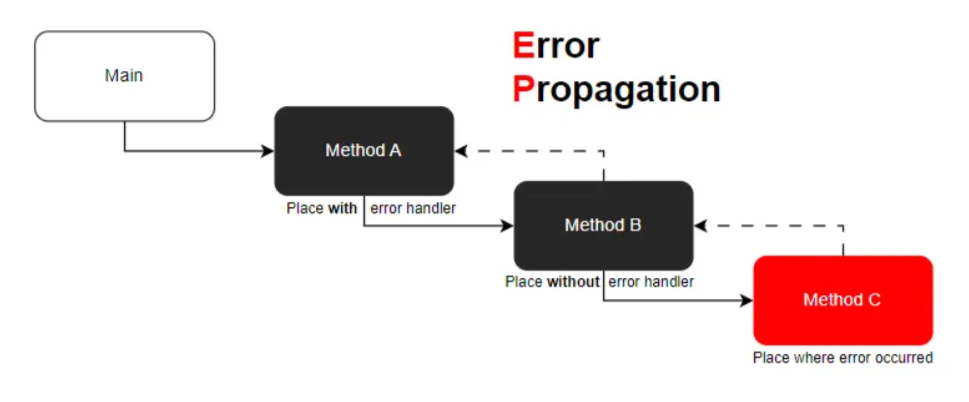
- Method C 是产生异常的地方。
- Method B 调用了方法 C,但没有处理异常,因此异常继续向上传播。
- Method A 调用了方法 B,并设置了异常处理器来捕获和处理异常。
- Main 是程序的入口,它调用了方法 A。如果方法 A 也未处理异常,异常将传播至此,并可能导致程序终止。
2. 复杂的异常传播场景
在更复杂的应用中,异常传播可能涉及多个层级和条件。理解这些复杂情况下的异常传播对于编写健壮的应用程序至关重要。
嵌套异常处理
在实际应用中,可能会遇到嵌套的 try-except 结构,这种结构可能导致异常在多个层级间传播。
def compute(): try: value = 10 / 0 except ZeroDivisionError: print("compute 内部捕获除零异常") raise # 再次抛出异常以供外部处理 try: compute() except ZeroDivisionError: print("外部捕获除零异常")这个例子中,compute 函数内部的 try-except 块首先捕获了除以零的异常,对异常进行了部分处理(打印信息),然后通过 raise 关键字再次抛出同一异常。这使得异常可以在外部的 try-except 块中被再次捕获和处理。
异常传播的控制
可以通过设计来控制异常的传播方式。例如,可以决定在何处重新抛出异常,何处彻底处理异常,以避免异常传递到不希望它到达的地方。
3. 再次抛出异常的意义是什么?
允许程序在局部(例如函数或方法内部)对异常进行处理,比如记录日志、资源清理或执行一些局部的恢复操作,然后将相同的异常传递到更高层次的调用者,以便可以进行更广泛的处理或者简单地让程序优雅地失败。
- 分层异常处理: 在软件架构中,较低层次的函数通常负责具体的操作,如数据访问、文件操作等,而上层函数则处理更抽象的逻辑。通过在低层捕获并再次抛出异常,可以让上层决定是否继续执行、回退操作或是向用户显示错误消息等。
- 错误日志记录: 在函数内部捕获异常并记录错误的具体信息(例如,错误发生的上下文),然后再抛出,这样错误日志可以保留详细的异常信息,而不会丢失异常发生的原始场景。
- 资源清理: 在异常发生时进行必要的资源清理(如关闭文件、释放锁等),确保资源被妥善处理后,再将异常传递出去,避免资源泄漏。
实际应用示例:数据库操作中的异常处理
def get_user_data(user_id): try: connection = database.connect() data = connection.query(f"SELECT * FROM users WHERE id = {user_id}") return data except DatabaseError as e: logging.error(f"Database error occurred: {e}") raise # 把异常传递给调用者,可能会显示错误信息或进行其他处理 finally: connection.close() # 确保数据库连接被关闭 try: user_data = get_user_data(123) except DatabaseError: print("无法获取用户数据")get_user_data首先尝试连接数据库并查询用户数据。如果发生DatabaseError,它会记录错误信息然后重新抛出异常,确保上层调用者能够感知到数据库操作失败,并做出相应的处理。不管是否发生异常,finally块确保数据库连接总是被关闭。
4. 最佳实践与异常处理策略
处理异常不仅仅是捕获它们,更重要的是如何有效地利用异常提供的信息来使程序更加健壮。
- 设计清晰的异常传播策略
应该明确哪些层级负责处理哪些类型的异常。一般情况下,底层函数应该处理具体的、详细的异常,而顶层更多地处理通用异常或者是策略性的异常处理。
- 使用日志记录异常信息
在捕获并处理异常的同时,使用日志记录详细的异常信息是一种很好的做法。这不仅帮助开发者进行调试,也为系统的监控提供支持。
import logging try: risky_operation() except Exception as e: logging.error("操作失败", exc_info=True)在这个例子中,使用 logging 模块来记录异常信息,包括堆栈跟踪。这样可以在不中断程序运行的情况下获得异常的详细背景。
推荐: python 错误记录
参考:Server-Side Exception Handling Patterns & Practices







