
YOLOv8测试3:在Python中将YOLOv8模型封装成API接口使用(上传测试图片并返回识别结果,附测试代码)
一、概述
记录时间 [2024-4-4]
本文讲述的是在Windows系统(Python+PyTorch+Conda+cpu)中YOLOv8模型的简单应用。这里附带上YOLOv8官方文档,里面记载了详细的使用方法,如果觉得看文档比较麻烦的话,可以直接看文章,需要用到的部分已经在文章中进行了摘录。
经过了前几次的尝试,我们不仅能使用CLI的方式运行yolov8n.pt模型,对图像和视频进行目标识别,并得到结果。
参考文章:YOLOv8模型的简单测试,Windows环境下安装部署(Python+PyTorch+Conda+cpu+CLI)
也可以在PyCharm集成开发环境中编写简单的python文件,以python的方式对YOLOv8模型进行简单的测试。
参考文章:YOLOv8模型的简单测试2,PyCharm集成开发环境安装使用(Windows+Python+PyTorch+Conda+cpu)
同时也了解了在Python中使用Flask封装网络接口的方法,能实现文件的上传。
参考文章:API接口简单使用(二):Python中使用Flask(接口封装整理版,含文件上传接口的详细实现)
接下来,本文将介绍在Python中将YOLOv8模型封装成API接口使用的方法,然后通过调用封装好的API接口,我们可以上传自定义的测试图片,并返回识别结果。识别结果有两种:一种是完成识别后的图片;另一种是识别目标的类型,以及它们在图片中的坐标、大小,以文本形式返回。
二、思路整理
想要实现在Python中将YOLOv8模型封装成API接口使用,首先整理下思路:
- (服务端)使用Flask框架编写一个简单的测试实例,可以实现文件上传
- (客户端)通过API接口,以文件形式上传自定义的测试图片
- (服务端)获取图片名称和类型,然后保存到指定路径
- (服务端)下载并使用YOLOv8模型进行图片预测/识别
- (服务端)保存图片目标识别的结果
- (服务端)返回目标识别的结果
- (客户端)得到服务端返回的识别结果
三、过程实现
此处主要讲述这个案例的实现过程,想要直接上手的朋友可以在文章下半部分获取详细完整版的测试代码哦。
1. 编写测试实例
(服务端)使用Flask框架编写一个简单的测试实例,可以实现文件上传
简单了解
简单的测试实例如下:
from flask import Flask, request app = Flask(__name__) @app.route('/...') def hanshu(): # 这里是写接口函数的地方 if __name__ == '__main__': app.run()文件上传功能的网络接口参考这个:(简单看一下即可)
@app.post('/upload') def upload(): # 文件作为参数传递,其 id为 file # 如果没有接收到这个请求,返回 No file part if 'file' not in request.files: return "No file part" # 获取上传的文件 file = request.files['file'] # 获取文件名 if file.filename == '': return "No selected file" # file_format 获取文件类型,并返回 if file: filename = file.filename file_format = filename.rsplit('.', 1)[1] return "File format is: " + file_format.upper()创建测试文件
然后,开始动手操作。
使用PyCharm打开我们之前从仓库下载的YOLOv8项目ultralytics-main,找到tests目录,在该目录下新建image_test.py文件。
导入依赖
导入YOLOv8项目运行所需的依赖和配置:
# Ultralytics YOLO 🚀, AGPL-3.0 license import contextlib from copy import copy from pathlib import Path import cv2 import numpy as np import pytest import torch import yaml from PIL import Image from torchvision.transforms import ToTensor from ultralytics import RTDETR, YOLO from ultralytics.cfg import TASK2DATA from ultralytics.data.build import load_inference_source from ultralytics.utils import ( ASSETS, DEFAULT_CFG, DEFAULT_CFG_PATH, LINUX, MACOS, ONLINE, ROOT, WEIGHTS_DIR, WINDOWS, Retry, checks, is_dir_writeable, ) from ultralytics.utils.downloads import download from ultralytics.utils.torch_utils import TORCH_1_9, TORCH_1_13 MODEL = WEIGHTS_DIR / "path with spaces" / "yolov8n.pt" # test spaces in path CFG = "yolov8n.yaml" SOURCE = ASSETS / "bus.jpg" TMP = (ROOT / "../tests/tmp").resolve() # temp directory for test files IS_TMP_WRITEABLE = is_dir_writeable(TMP)导入Flask框架使用所需依赖:(如果Flask依赖报错,说明没有导入成功,重新导入一下即可。)
from flask import Flask, request, send_file
编写文件上传接口
app = Flask(__name__) @app.post('/image') def return_image(): return "Succeed" if __name__ == '__main__': app.run(host='0.0.0.0', port=5001)大家可以自行测试下这个接口可不可用,后面我们在return_image()函数中编写内容。
创建上传目录
在ultralytics-main/tests/tmp/目录下新建upload文件夹,用来存放我们上传的文件。
2. 上传测试图片
(客户端)通过API接口,以文件形式上传自定义的测试图片
这里简单写一个HTML文件用于测试即可:
文件上传3. 获取图片信息并保存
(服务端)获取图片名称和类型,然后保存到指定路径
在return_image()函数中编写内容:
# 1. 获取上传的图片资源 # 文件作为参数传递,其 id为 file # 如果没有接收到这个请求,返回 No file part if 'file' not in request.files: return "No file part" # 获取图片文件 file = request.files['file'] # 获取文件名 if file.filename == '': return "No selected file" filename = file.filename # 2. 保存到指定位置 file.save(TMP / 'upload' / filename)4. 进行图片预测
(服务端)下载并使用YOLOv8模型进行图片预测/识别
在return_image()函数中编写内容:
# 3. 使用 YOLOv8模型对该图片进行预测 model = YOLO(MODEL) # Define path to the image file source = TMP / 'upload' / filename # 具体要在 predict中添加一些参数 model.predict(source)
5. 保存图片目标识别的结果
(服务端)保存图片目标识别的结果
图片结果
我们要保存识别后的图片结果,主要使用的参数是save,我们设置save=True即可。
# 4. 保存结果 results = model.predict(source, save=True, imgsz=320, conf=0.5)
文本结果
如果要保存识别目标的类型,以及它们在图片中的坐标、大小,以文本形式返回
则使用参数save_txt,设置为True:
results = model.predict(source, save_txt=True)
结果会以txt文件的形式保存在tests\tmp\runs\detect\predict[i]\labels目录下。
6. 返回目标识别的结果
(服务端)返回目标识别的结果
图片结果
send_file(image_path)是直接将返回的结果在浏览器中进行预览,
如果想要下载图片,就添加as_attachment=True参数。
# 获取文件保存的路径 save_path = Path(results[0].save_dir) image_path = save_path / filename # 5. 返回结果 return send_file(image_path) # 下载版 return send_file(image_path, as_attachment=True)
文本结果
想要获取识别目标的类型,以及它们在图片中的坐标、大小的信息,
我们需要读取tests\tmp\runs\detect\predict[i]\labels目录中的txt文件
# 获取文件保存的路径 save_path = Path(results[0].save_dir) # 获取label标签文件 for r in results: im_name = Path(r.path).stem labels = save_path / f"labels/{im_name}.txt" # 读取标签文件中的内容 txt_file = labels with open(txt_file, 'r') as file: content = file.read() # 返回结果 return content7. 得到返回结果
(客户端)得到服务端返回的识别结果
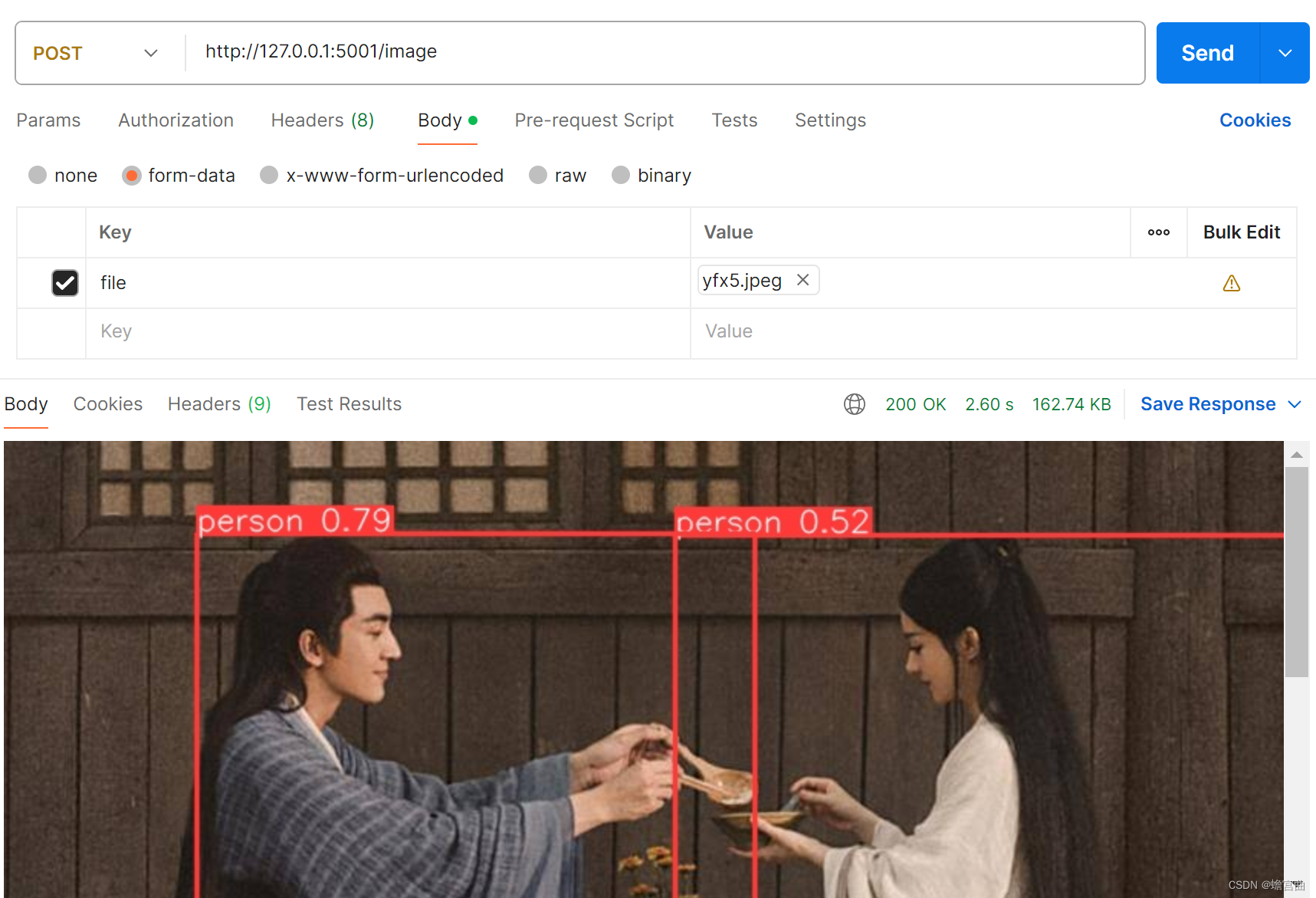
图片结果
我们可以用上面写的HTML文件来进行测试,双击运行,选择文件,然后上传即可。
这里为了呈现结果更加直观,所以使用了Postman来测试,如图所示。
注意:测试图片素材来源于网络,仅用于测试演示。
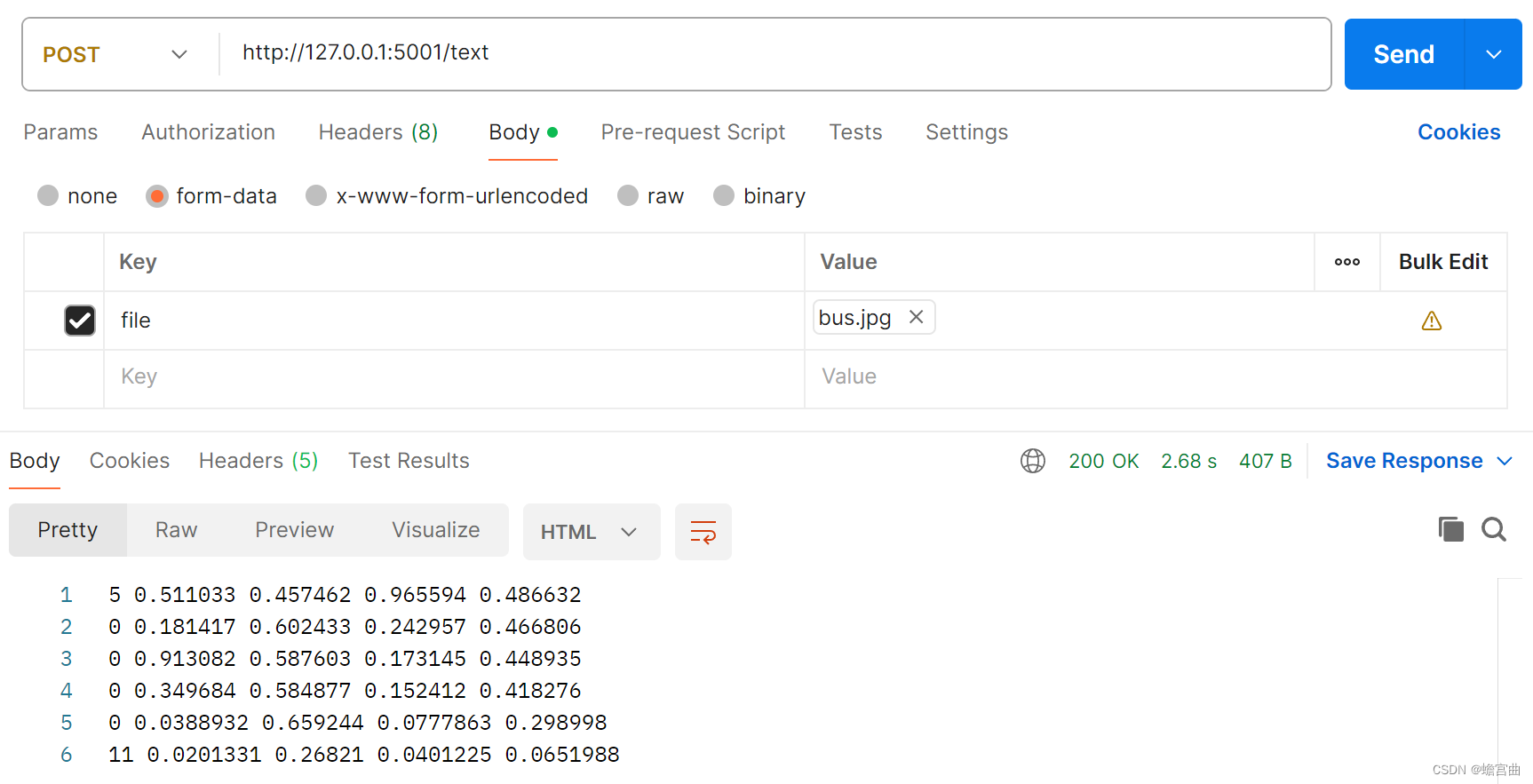
文本结果
如图所示,返回识别目标的类型,以及它们在图片中的坐标、大小等信息。
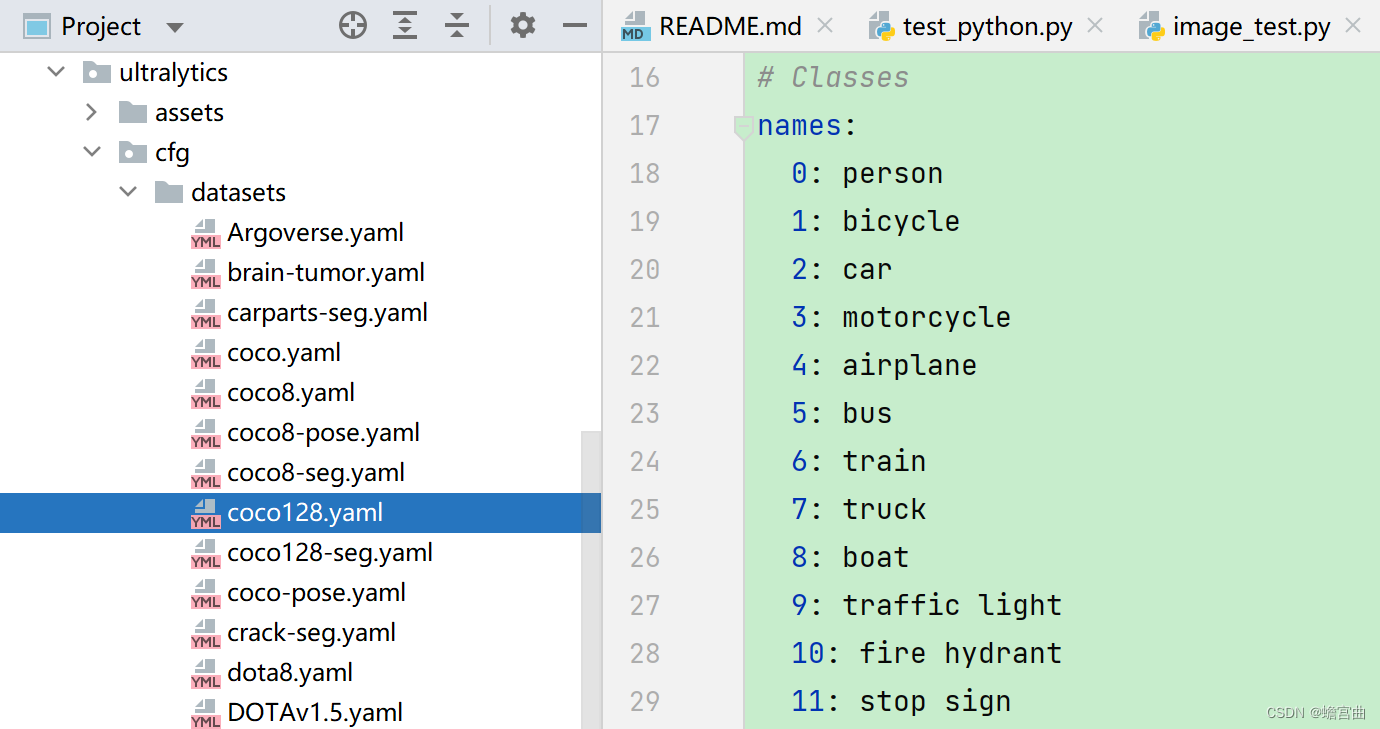
下面对YOLOv8标签文件label中的内容进行解释:
- 如图,在项目中打开一个模型训练文件进行查看
- 以第一行标签为例,首个数字5代表的是names中的第五类,即bus
- 后面的四个参数分别是bus在图片中的纵横坐标,以及它的长宽
- 通过这些参数,我们就可以确定识别目标的类型,以及它在图片中的位置啦
四、详细完整版测试代码
1. 得到图片目标版本
image_test.py
# Ultralytics YOLO 🚀, AGPL-3.0 license import contextlib from copy import copy from pathlib import Path import cv2 import numpy as np import pytest import torch import yaml from PIL import Image from torchvision.transforms import ToTensor from ultralytics import RTDETR, YOLO from ultralytics.cfg import TASK2DATA from ultralytics.data.build import load_inference_source from ultralytics.utils import ( ASSETS, DEFAULT_CFG, DEFAULT_CFG_PATH, LINUX, MACOS, ONLINE, ROOT, WEIGHTS_DIR, WINDOWS, Retry, checks, is_dir_writeable, ) from ultralytics.utils.downloads import download from ultralytics.utils.torch_utils import TORCH_1_9, TORCH_1_13 from flask import Flask, request, send_file MODEL = WEIGHTS_DIR / "path with spaces" / "yolov8n.pt" # test spaces in path CFG = "yolov8n.yaml" SOURCE = ASSETS / "bus.jpg" TMP = (ROOT / "../tests/tmp").resolve() # temp directory for test files IS_TMP_WRITEABLE = is_dir_writeable(TMP) app = Flask(__name__) @app.post('/image') def return_image(): # 1. 获取上传的图片资源 # 文件作为参数传递,其 id为 file # 如果没有接收到这个请求,返回 No file part if 'file' not in request.files: return "No file part" # 获取图片文件 file = request.files['file'] # 获取文件名 if file.filename == '': return "No selected file" filename = file.filename # 2. 保存到指定位置 file.save(TMP / 'upload' / filename) # 3. 使用 YOLOv8模型对该图片进行预测 model = YOLO(MODEL) # Define path to the image file source = TMP / 'upload' / filename # 4. 保存结果 results = model.predict(source, save=True, imgsz=320, conf=0.5) # 获取文件保存的路径 save_path = Path(results[0].save_dir) image_path = save_path / filename # 5. 返回结果 return send_file(image_path) if __name__ == '__main__': app.run(host='0.0.0.0', port=5001)2. 得到文本参数版本
text_test.py
# Ultralytics YOLO 🚀, AGPL-3.0 license import contextlib from copy import copy from pathlib import Path import cv2 import numpy as np import pytest import torch import yaml from PIL import Image from torchvision.transforms import ToTensor from ultralytics import RTDETR, YOLO from ultralytics.cfg import TASK2DATA from ultralytics.data.build import load_inference_source from ultralytics.utils import ( ASSETS, DEFAULT_CFG, DEFAULT_CFG_PATH, LINUX, MACOS, ONLINE, ROOT, WEIGHTS_DIR, WINDOWS, Retry, checks, is_dir_writeable, ) from ultralytics.utils.downloads import download from ultralytics.utils.torch_utils import TORCH_1_9, TORCH_1_13 from flask import Flask, request, send_file MODEL = WEIGHTS_DIR / "path with spaces" / "yolov8n.pt" # test spaces in path CFG = "yolov8n.yaml" SOURCE = ASSETS / "bus.jpg" TMP = (ROOT / "../tests/tmp").resolve() # temp directory for test files IS_TMP_WRITEABLE = is_dir_writeable(TMP) app = Flask(__name__) @app.post('/text') def return_text(): # 1. 获取上传的图片资源 # 文件作为参数传递,其 id为 file # 如果没有接收到这个请求,返回 No file part if 'file' not in request.files: return "No file part" # 获取图片文件 file = request.files['file'] # 获取文件名 if file.filename == '': return "No selected file" filename = file.filename # 2. 保存到指定位置 file.save(TMP / 'upload' / filename) # 3. 使用 YOLOv8模型对该图片进行预测 model = YOLO(MODEL) # Define path to the image file source = TMP / 'upload' / filename # 4. 保存结果 results = model.predict(source, save_txt=True) # 获取文件保存的路径 save_path = Path(results[0].save_dir) # 获取label标签文件 for r in results: im_name = Path(r.path).stem labels = save_path / f"labels/{im_name}.txt" # 读取标签文件中的内容 txt_file = labels with open(txt_file, 'r') as file: content = file.read() # 5. 返回结果 return content if __name__ == '__main__': app.run(host='0.0.0.0', port=5001)五、总结
本文在Python中将YOLOv8模型封装成API接口进行使用,通过调用封装好的API接口来实现自定义测试图片的上传,并返回识别结果。识别结果有两种:一种是完成识别后的图片;另一种是识别目标的类型,以及它们在图片中的坐标、大小,以文本形式返回。
一些参考资料
YOLOv8官方文档:https://docs.ultralytics.com/zh/
YOLOv8模型仓库地址:https://github.com/ultralytics/ultralytics
PyCharm官网:https://www.jetbrains.com/pycharm/download/?section=windows



