
【Linux】进程



本文主要介绍了进程的相关理解:查看进程、进程状态、进程的优先级、环境变量、进程地址空间、Linux内核进程调度队列。
目录
冯诺依曼体系结构
操作系统
进程
查看进程
几点预备小知识
进程创建的代码方式
为什么要创建子进程
样例代码:依次创建多个进程
进程状态
Linux的进程状态
僵尸进程和孤儿进程
进程的运行、阻塞和挂起
进程的优先级
概念
Linux的优先级的特点&&查看方式
其他概念
命令行参数
环境变量
常见环境变量
整体理解环境变量和系统
获取环境变量代码实现
环境变量再理解
进程地址空间
从代码看现象
地址空间细节理解
如何理解地址空间
为什么要有地址空间
如何理解虚拟地址
Linux内核进程调度队列
优先级
活动队列
过期队列
active指针和expired指针
冯诺依曼体系结构
截止目前,我们所认识的计算机,都是由诸多硬件组成:
输入设备:键盘、显示器、摄像头、话筒、磁盘、网卡
输出设备:显示器、声卡、磁盘、网卡
CPU:运算器、控制器
存储器:内存
关于冯诺依曼体系结构,有这样的经典示意图:

图中的箭头可以看做数据的流向,数据是要在计算机的体系结构中进行流动的,在流动过程中,进行数据的加工处理,数据从一个设备到另一个设备,在本质上是一种拷贝!
数据设备间的拷贝效率,决定了计算机整机的效率。
关于冯诺依曼结构,需要强调几点:
1.CPU不和外设打交道,只和内存打交道。
2.外设输入输出的数据,不是直接给CPU,而是先要放到内存中
操作系统
操作系统就是一款软件,对软硬件资源进行管理。
对操作系统广义的认识:操作系统的内核+操作系统的外壳周边程序(给用户提供使用操作系统的方式)
对操作系统狭义的认识:只是操作系统的内核
为什么要有操作系统?
提供对软硬件资源进行管理(手段),为用户提供一个良好(稳定、安全、高效)的运行环境(目的)。
这里要引入一个非常重要的理念,任何管理(包括操作系统)都要遵循:
先描述,再组织!
这里的描述是指对管理对象进行描述,例如,在之前写通讯录时,先要定义一个包括各种联系人信息的结构体,然后使用数组这种数据结构进行组织。

在上图中,可以看到,操作系统为上面用户操作提供了系统调用接口,用户不能直接改变操作系统里的内容。
系统调用和库函数概念
在开发角度,操作系统对外会表现为一个整体,但是会暴露自己的部分接口,供上层开发使用,这部分由操作系统提供的接口,叫做系统调用。
系统调用在使用上,功能比较基础,对用户的要求相对也比较高,所以,有心的开发者可以对部分系统调用进行适度封装,从而形成库,有了库,就很有利于更上层用户或者开发者进行二次开发。
操作系统管理硬件
1.使用struct结构体对硬件描述
2.使用链表或其他数据结构组织起来
进程
所谓进程,是程序执行的一个实例,正在执行的程序。从内核观点看,进程是担当分配系统资源(CPU时间,内存)的实体。
进程信息被放在一个叫做进程数据块的数据结构中,是进程属性的集合。一般称之为PCB(process control block),Linux操作系统下的PCB是:task_struct。
当加载一个程序时,对应的代码和数据被加载到内存中,但是代码和数据不是进程,只是进程的一部分,进程还包括对应的PCB。
存在PCB的原因是:OS要对进程进行管理,先描述,再组织。这样对进程的管理,就变成了对链表的增删查改!
总结一下,进程=PCB+自己的代码和数据,对Linux操作系统来说,进程=内核task_struct结构体+程序的代码和数据。
理解一个概念:如何理解系统动态运行?
调度运行进程,本质就是让进程控制块task_struct进行排队!
查看进程
几点预备小知识
a)./xxxx,本质就是让系统创建进程并运行,我们自己写的代码形成的可执行文件=系统命令=可执行文件,在linux中的大部分执行操作,本质都是运行进程!
b)每一个进程都要有自己的唯一标识符,叫做进程pid
有myprocess.c这样一个文件,运行后生成myprocess的可执行文件。
#include
#include
int main()
{
while(1)
{
printf("I am a process!\n");
sleep(1);
}
return 0;
}
复制当前窗口,在一个窗口运行myprocess可执行程序(./myprocess),在另一个窗口输入下面的指令:
ps ajx | head -1 && ps ajx | grep myprocess
这条指令由&&两边的两条指令组成,&&的意思是执行两条指令,其左边:
ps ajx | head -1
这句代码是打印出进程的标题行,
其右边:
ps ajx | grep myprocess
打印出包含‘myprocess’关键字的进程。

第二列就是进程的pid,pid的类型是unsigned int pid。
c)可以使用getpid()得到进程的pid
如果不想通过ps ajx命令去查进程的pid,那么还可以使用getpid()函数去查,
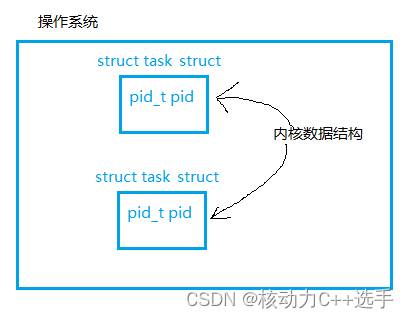
如上图所示,每个进程都有自己对应的pid。pid属于内核数据结构中的数据,因此用户不用直接获得,需要调用系统接口。
d)Ctrl+C是在用户层面终止进度,kill -9 pid可以用来直接杀掉进程
进程创建的代码方式
首先看一个指令:
pid getppid(void); ---获取当前进程的父进程id
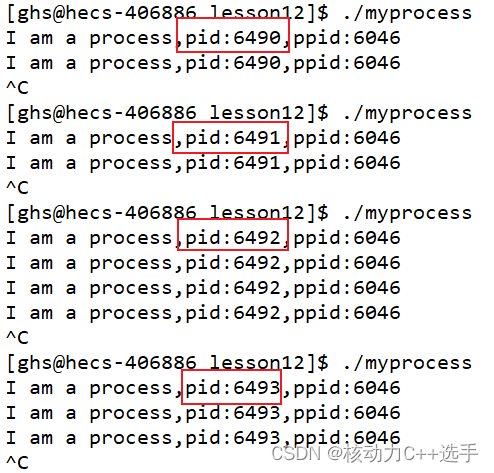
从上图发现,每次启动进程后,对应地 pid都不一样,这是正常的,但是对应的ppid(父进程)是一样的!上图的父进程都是6046,于是我们很好奇谁是6046啊?
我们可以通过如下的代码查到:
ps ajx | head -1 && ps ajx | grep 6046

原来6046是bash,bash就是父进程,是命令行解释器!
接下来,我们在代码中创建子进程:使用fork()命令。
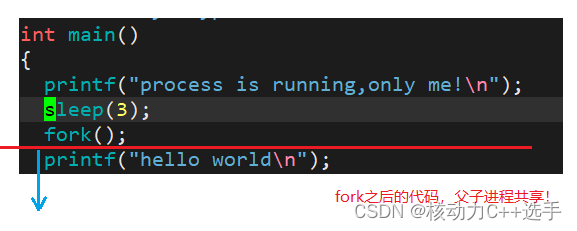
fork后的指令由父子进程共享!

1.创建一个进程,本质就是系统中多了一个进程;多了一个进程,就是多了1和内核task_struct。
2.多了的一个进程,有自己的代码和数据,父进程的代码和数据是从磁盘加载来的,而子进程的代码和数据默认情况继承父进程的代码和数据(代码由于是只读的,所以父子共用一份代码,而数据可读可写,父子各自独立,原则上要分开!)。
为什么要创建子进程
想让子进程和父进程执行不一样的代码!
看下面这段代码:
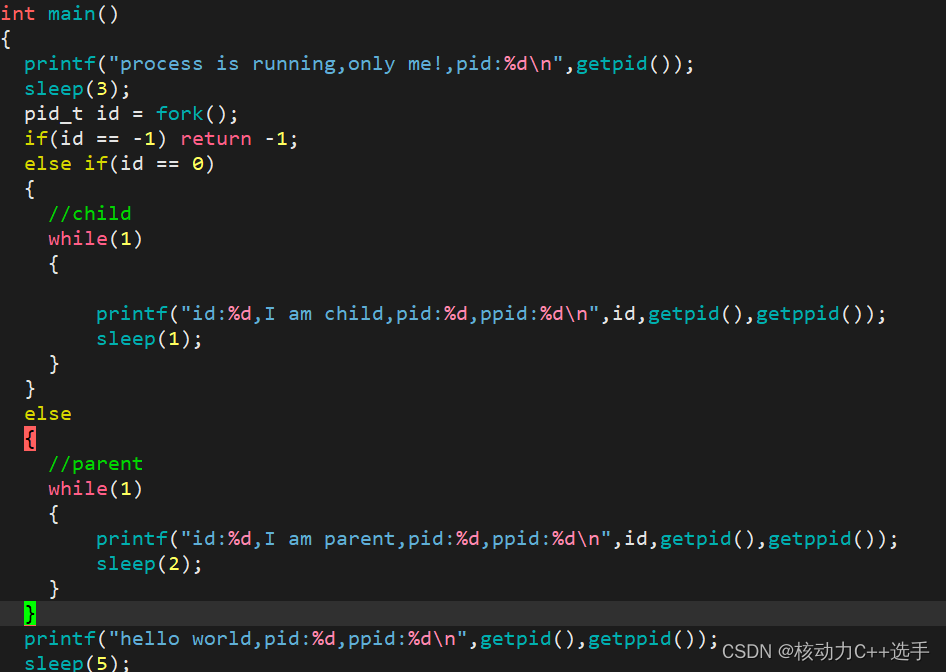

可以看到,当id不同时,进入不同的代码,这就是多进程情况。其中,fork是一个函数,由操作系统提供,fork会返回两次。为什么会fork返回两次呢?前面说到,fork后的代码由父子进程共享,其实这样说并不准确,在fork函数内部的return语句前,子进程已经被创建,因此,return语句也是由父子进程共享,会被父子进程各执行一次,会返回两次!
需要注意的是,进程间一定要做到:进程具有独立性!杀掉父进程不会影响子进程,杀掉子进程不会影响父进程!
样例代码:依次创建多个进程
#include
#include
#include
void RunChild()
{
while(1)
{
printf("I am child,pid:%d,ppid:%d\n",getpid(),getppid());
sleep(1);
}
}
int main()
{
const int num = 5;
int i=0;
for(i=0;i






