
【WebJs 爬虫】逆向进阶技术必知必会
前言
在数字化时代,网络爬虫已成为一种强大的数据获取工具,广泛应用于市场分析、竞争对手研究、舆情监测等众多领域。爬虫技术能够帮助我们快速、准确地获取网络上的海量信息,为决策提供有力支持。然而,随着网络环境的日益复杂和网站反爬虫机制的加强,传统的爬虫技术已难以满足需求。因此,掌握逆向爬虫技术、应对反爬虫策略,成为了爬虫开发者必备的技能。

通过本文的学习,希望能帮助你掌握WebJs爬虫技术,提升爬虫开发的效率和成功率。相信无论是初学者还是有一定经验的开发者,都能从中受益,为自己的爬虫项目提供有力的技术支持。让我们一同探索WebJs爬虫的世界,开启数据获取的新篇章!
文章目录
- 前言
- 一、什么是爬虫技术
- 二、WebJs爬虫基础知识
- 1. 爬虫原理
- 2. 爬虫工作流程简介
- 3. 浏览器与服务器交互过程
- 4. HTTP请求与响应
- 5. 常用工具与库
- 三、爬虫逆向技术
- 1. 反爬虫机制分析
- 2. 应对反爬虫策略
- 四、代码示例与实践
- 1. 基本爬虫实现
- 2. 逆向爬虫实战
- 五、高级技巧与注意事项
- 1. 动态内容爬取
- 2. 数据清洗与存储
- 3. 遵守爬虫道德与法规
- 六、总结与展望
- 七、获取免费代理IP
一、什么是爬虫技术
在互联网时代,数据已经成为了重要的资源。Web爬虫作为一种自动化获取数据的工具,在数据分析、市场调研、价格监控等领域发挥着越来越重要的作用。简单来说,Web爬虫是一种程序,它模拟人类在浏览器中的行为,自动访问网站并抓取所需的数据。通过爬虫,我们可以快速、高效地收集大量信息,为决策提供有力支持。
然而,随着网站对爬虫的限制和反爬虫技术的不断发展,传统的爬虫方法已经难以满足需求。逆向爬虫技术应运而生,它通过对目标网站的反爬虫机制进行深入分析,并采取相应的对策,从而成功获取数据。因此,掌握WebJs爬虫逆向技术对于Web开发者来说至关重要。
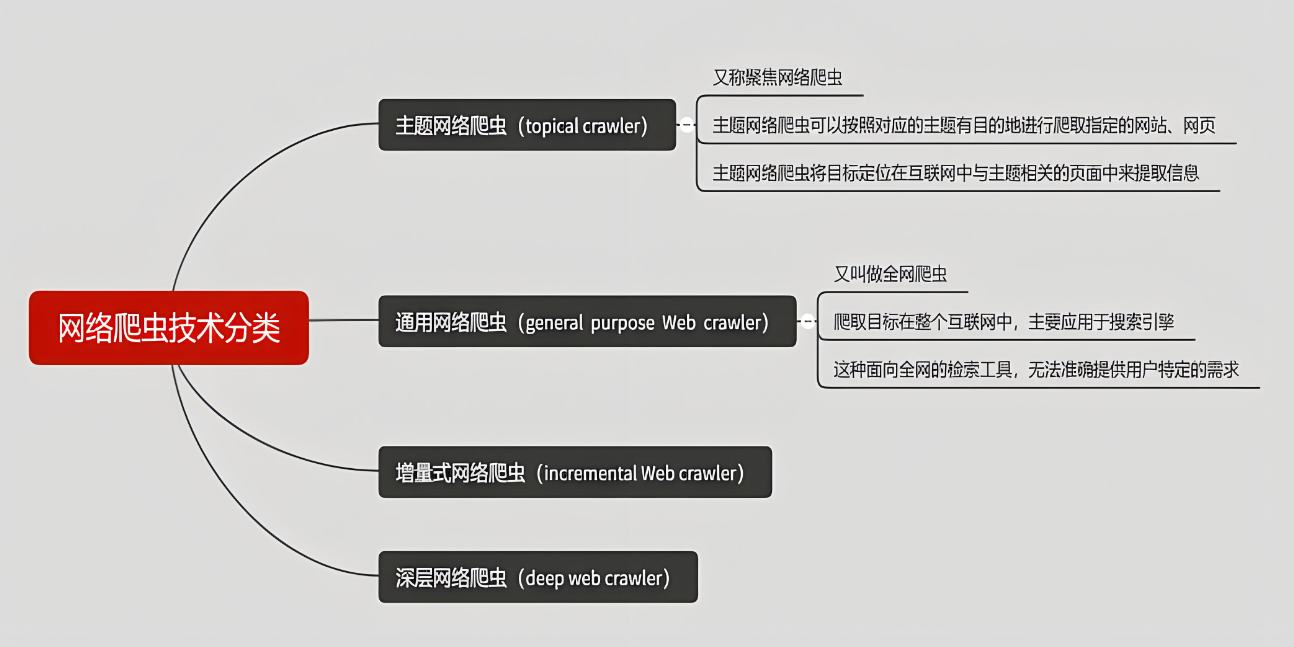
本文将详细介绍WebJs爬虫的基础知识、爬虫逆向技术、代码示例与实践,以及高级技巧与注意事项。通过本文的学习,读者将能够掌握WebJs爬虫逆向的核心技术,提升爬虫开发能力。
二、WebJs爬虫基础知识
1. 爬虫原理
爬虫的工作原理基于HTTP协议。当我们在浏览器中输入一个网址并按下回车键时,浏览器会向服务器发送一个HTTP请求。服务器接收到请求后,会返回相应的HTML、CSS、JavaScript等文件,浏览器则负责解析这些文件并渲染出网页内容。爬虫就是模拟这个过程,自动发送HTTP请求并获取服务器返回的数据。
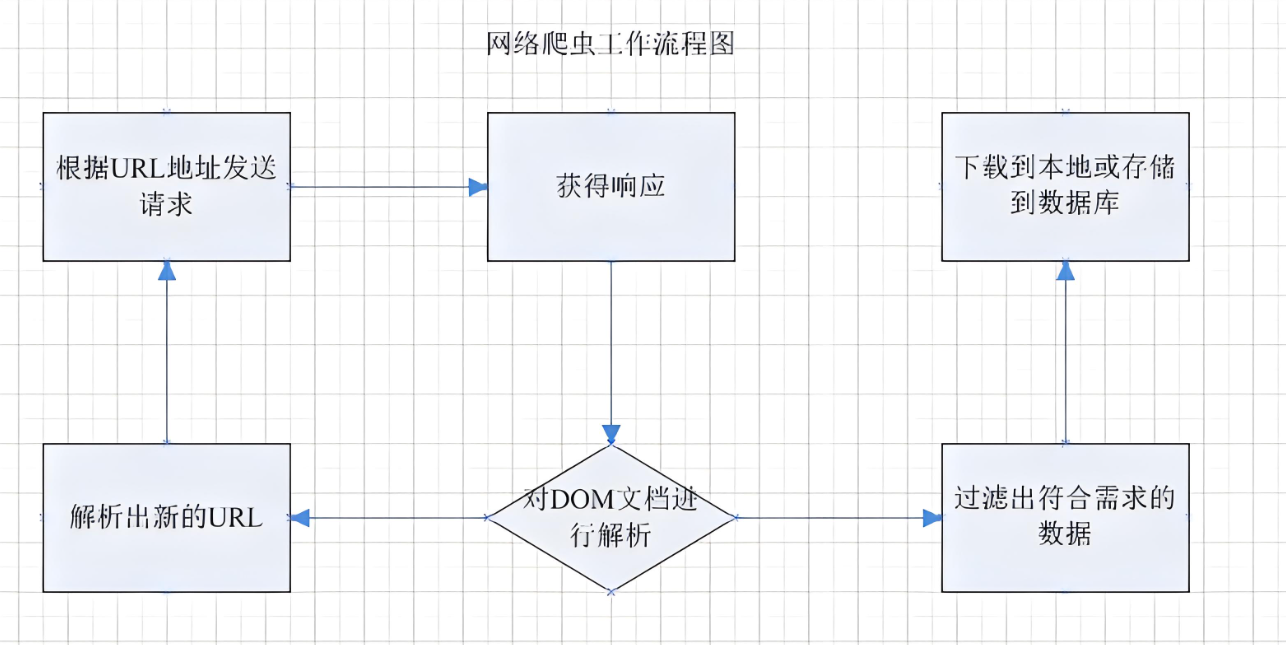
2. 爬虫工作流程简介
Web爬虫的工作流程大致可以分为以下几个步骤:
(1)发送HTTP请求:爬虫程序根据目标URL向服务器发送HTTP请求,请求类型通常为GET或POST。
(2)接收响应:服务器接收到请求后,会返回相应的响应。响应中包含了网页的HTML代码、状态码等信息。
(3)解析HTML:爬虫程序使用HTML解析器对返回的HTML代码进行解析,提取出所需的数据。
(4)存储数据:将提取出的数据存储到本地文件、数据库或其他存储介质中。
(5)循环爬取:根据需要,爬虫程序可以设置循环爬取机制,不断从新的URL中获取数据。
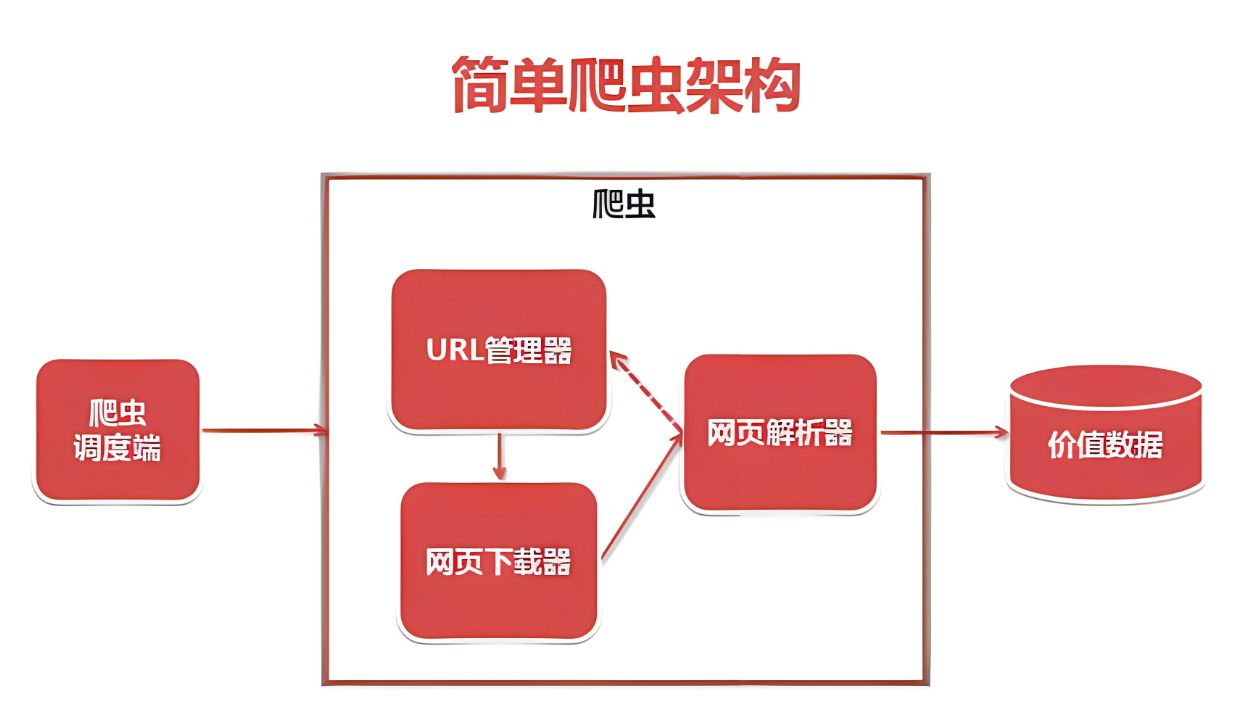
3. 浏览器与服务器交互过程
在爬虫过程中,理解浏览器与服务器之间的交互过程至关重要。浏览器通过发送HTTP请求与服务器进行通信,服务器则返回相应的HTTP响应。这个过程涉及到多个HTTP头部字段和状态码,它们对于爬虫程序来说具有重要意义。例如,User-Agent字段用于标识请求的来源(即浏览器类型),Cookie字段用于保持会话状态等。爬虫程序需要正确设置这些字段,以模拟真实的浏览器行为并绕过服务器的反爬虫机制。
4. HTTP请求与响应
HTTP请求和响应是爬虫工作的基础。HTTP请求由请求行、请求头部和请求体组成,其中请求行包含了请求方法(如GET、POST)、URL和协议版本等信息。请求头部则包含了各种元数据,如User-Agent、Accept-Language等。响应则由状态行、响应头部和响应体组成,其中状态行包含了状态码和状态消息等信息。爬虫程序需要构造合适的HTTP请求,并解析服务器返回的HTTP响应以获取所需数据。
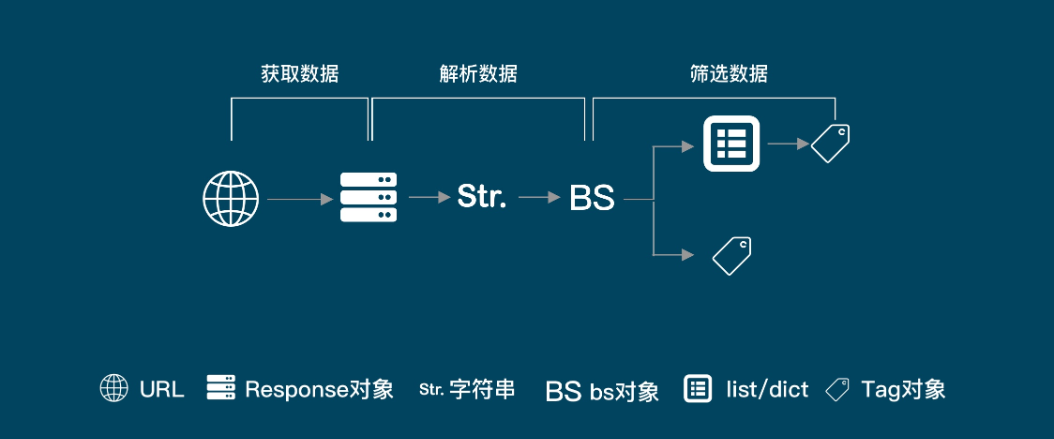
5. 常用工具与库
在Node.js环境下,有许多强大的爬虫库可供使用。其中,axios是一个基于Promise的HTTP客户端,用于浏览器和node.js。它可以方便地发送GET、POST等类型的HTTP请求,并处理响应数据。puppeteer则是一个无头浏览器库,它提供了完整的浏览器环境,可以模拟真实用户的操作,适用于爬取需要JavaScript渲染的网页。此外,cheerio是一个快速、灵活且简洁的jQuery核心实现,用于解析和操作HTML文档。
除了Node.js环境下的库外,还有一些浏览器自动化工具如Selenium也常被用于爬虫开发。Selenium可以模拟用户在浏览器中的操作,如点击、输入等,适用于爬取需要用户交互的网页。

通过掌握这些常用工具与库的使用方法,我们可以更加高效地进行WebJs爬虫开发。
三、爬虫逆向技术
1. 反爬虫机制分析
随着网络爬虫技术的普及,越来越多的网站开始实施反爬虫策略,以保护其数据资源不被滥用。常见的反爬虫手段包括:
- 验证码机制:当检测到异常访问频率或行为时,网站会要求用户输入验证码,以确保访问者是真实用户而非爬虫。
- 频率限制:对单位时间内访问次数进行限制,超过限制则拒绝服务或进行降速处理。
- 用户代理检测:通过分析HTTP请求中的User-Agent字段,判断是否为常见的浏览器标识,以识别并拦截爬虫。
理解这些反爬虫机制的工作原理对于开发有效的爬虫至关重要。爬虫开发者需要分析目标网站的反爬虫策略,并制定相应的应对策略。

2. 应对反爬虫策略
为了绕过网站的反爬虫机制,我们可以采取以下策略:
- 伪装用户代理:在发送HTTP请求时,设置合适的User-Agent字段,模拟常见浏览器的标识,以避免被识别为爬虫。
- 使用代理IP:通过代理服务器发送请求,隐藏真实的IP地址,防止因频繁访问而被目标网站封禁。
- 处理验证码:当遇到验证码时,可以使用图像识别技术(如OCR)自动识别验证码并输入,或者通过第三方打码平台解决。
- 控制请求频率:合理设置爬虫的访问频率,避免触发网站的反爬虫机制。可以通过设置延时、限制并发量等方式来实现。
- 使用浏览器自动化技术模拟真实用户行为:利用puppeteer等浏览器自动化工具,模拟真实用户在浏览器中的操作,如滚动页面、点击按钮等,以绕过反爬虫机制。
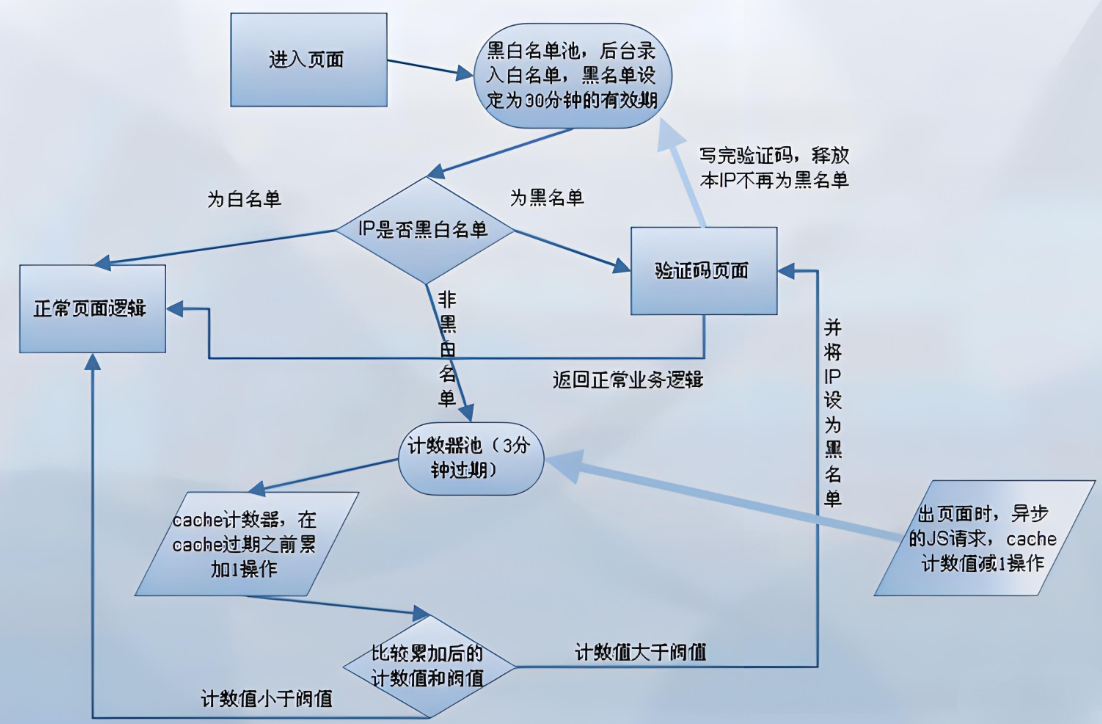
四、代码示例与实践
1. 基本爬虫实现
以下是一个使用axios和cheerio实现的基本爬虫示例,用于获取网页内容并提取所需数据:
const axios = require('axios'); const cheerio = require('cheerio'); async function fetchData(url) { try { // 发起HTTP请求获取网页内容 const response = await axios.get(url); const html = response.data; // 使用cheerio解析HTML const $ = cheerio.load(html); // 提取所需数据,这里以提取页面标题为例 const title = $('title').text(); // 返回提取到的数据 return { title }; } catch (error) { console.error('Error fetching data:', error); return null; } } // 使用示例 const targetUrl = 'https://example.com'; fetchData(targetUrl).then(data => { if (data) { console.log('Title:', data.title); } });2. 逆向爬虫实战
以某电商网站为例,假设该网站实施了反爬虫策略,包括频率限制和验证码机制。以下是一个逆向爬虫的示例代码,用于绕过这些反爬虫措施并获取商品数据:
const axios = require('axios'); const cheerio = require('cheerio'); const puppeteer = require('puppeteer'); async function fetchProductData(url) { // 使用puppeteer模拟真实用户行为 const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(url, { waitUntil: 'networkidle2' }); // 处理可能出现的验证码 const captchaElement = await page.$('#captcha-input'); if (captchaElement) { // 这里假设我们有一个处理验证码的函数 await handleCaptcha(page); } // 获取页面内容 const html = await page.content(); await browser.close(); // 解析HTML并提取商品数据 const $ = cheerio.load(html); const productData = []; $('.product').each((index, element) => { const title = $(element).find('.title').text(); const price = $(element).find('.price').text(); // ...提取其他所需字段 productData.push({ title, price, /* 其他字段 */ }); }); return productData; } // 处理验证码的示例函数(具体实现根据验证码类型而定) async function handleCaptcha(page) { // 这里可以使用OCR技术或第三方打码平台来处理验证码 // ...处理验证码的逻辑 } // 使用示例 const targetUrl = 'https://example.com/products'; fetch五、高级技巧与注意事项
1. 动态内容爬取
许多现代网站使用JavaScript来动态生成页面内容,这意味着仅通过简单的HTTP请求无法获取到完整的数据。对于这类网站,我们需要分析JavaScript渲染的动态内容,并采取相应的技术来爬取。
使用puppeteer或Selenium等浏览器自动化工具,可以模拟浏览器环境并执行JavaScript代码,从而获取到动态渲染后的页面内容。这些工具允许我们等待页面加载完成后再提取数据,确保数据的完整性。
2. 数据清洗与存储
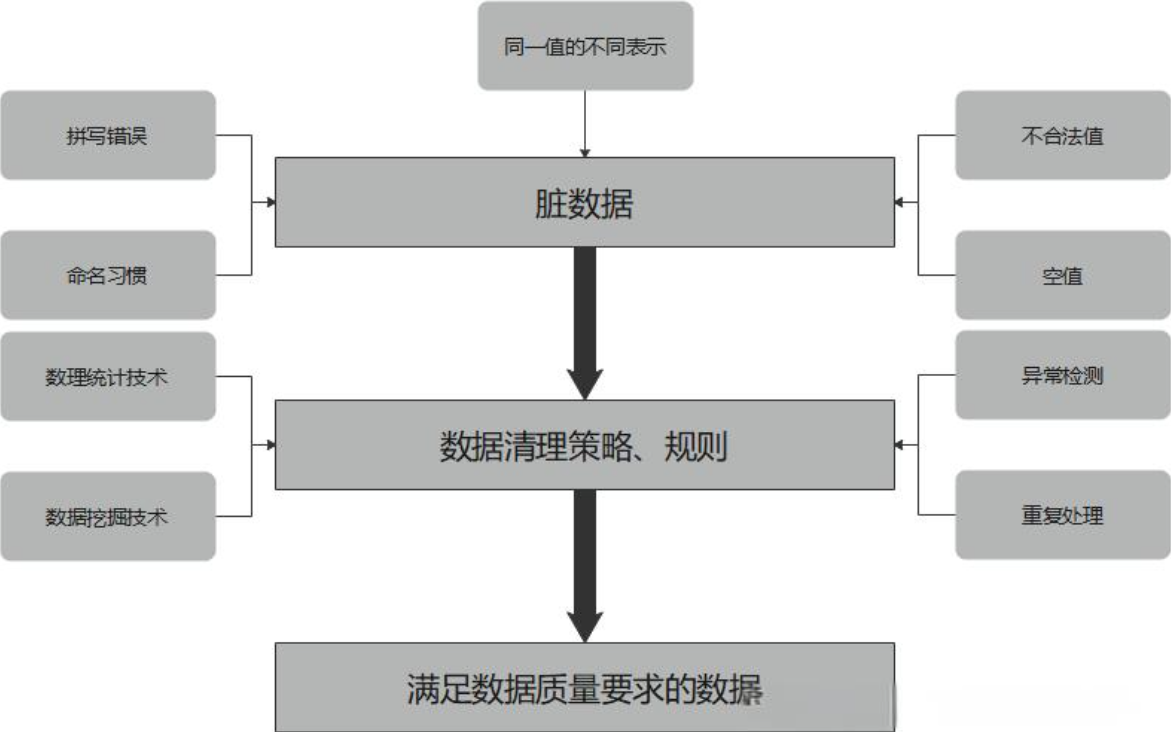
从网站爬取的数据往往包含大量的噪音和无关信息,因此需要进行数据清洗和预处理。这包括去除HTML标签、处理特殊字符、转换数据类型等操作。
对于清洗后的数据,我们需要选择合适的存储方式。常见的存储方式包括数据库(如MySQL、MongoDB等)和文件(如CSV、JSON等)。根据数据的规模和访问需求,可以选择适合的存储方案。
3. 遵守爬虫道德与法规
在进行爬虫开发时,我们必须遵守相关的道德和法规要求。首先,我们需要了解爬虫使用的法律风险,确保自己的行为合法合规。其次,我们应该尊重网站的Robots.txt文件,这是网站告诉爬虫哪些页面可以访问、哪些页面不能访问的协议。此外,我们还应该遵守网站的使用协议,不得进行恶意爬取、破坏网站正常运营等行为。

六、总结与展望
本文中我们深入了解了WebJs爬虫的基础知识、爬虫逆向技术、代码示例与实践以及高级技巧与注意事项。掌握了这些知识后,我们可以更加高效地进行爬虫开发,获取所需的数据。但随着技术的不断发展,反爬虫机制也在不断更新和升级。因此,我们需要不断学习和探索新的爬虫技术。未来,爬虫技术将更加智能化、自动化,能够更好地适应各种复杂的网站结构和反爬虫策略。
同时我们也应该意识到爬虫技术的双刃剑性质。在合法合规的前提下,合理利用爬虫技术可以为数据分析和决策提供有力支持;但如果不当使用,则可能给他人造成损失或侵犯隐私。
七、获取免费代理IP





