
【JavaEE初阶系列】——阻塞队列
温馨提示:这篇文章已超过402天没有更新,请注意相关的内容是否还可用!
目录
🚩阻塞队列的定义
🚩生产者消费者模型
🎈解耦性
🎈削峰填谷
🚩阻塞队列的实现
📝基础的环形队列
📝阻塞队列的形成
📝 内存可见性
📝阻塞队列代码
🚩阻塞队列的定义
阻塞队列是一种特殊的队列,也遵循“先进先出”的原则。
阻塞队列能是一种线程安全的数据结构 , 并且具有以下特性 :- 1.线程安全
- 2.带有阻塞特性
a) 如果队列为空,继续出队列,就会发生阻塞。阻塞到其他线程往队列里添加元素为止。
b)如果队列为满,继续入队列,就会发生阻塞。阻塞到其他线程往队列里添加元素为止。

阻塞队列,最大的意义,就是可以用来实现“生产者消费者模型”——一种常见的,多线程代码编写方式。
🚩生产者消费者模型
🎈解耦性
生产者消费者模式就是通过一个容器来 解决生产者和消费者的强耦合 问题。 耦合:俩个模块,联系越紧密,耦合越高!就比如就一个擀饺子皮杖,所以我们分配一个人擀饺子,剩下三个人包饺子。擀饺子皮就会不停的产出饺子皮,三个人负责包饺子,那三个人就不停的消耗饺子皮。我生产出来的饺子皮得有地方放,那就是放在板子上,而所谓的板子就是阻塞对列,进行来放入元素和放出元素。
生产者:把生产出来的内容,放到阻塞队列中
消费者:就会从阻塞队列中获取内容
如果我生产的慢,那么三个人就得等,就相当于从空的队列中获取元素就会阻塞
如果我生产的快,我就得等了,就相当于从满的队列中放入元素就会阻塞。
为什么要使用生产者消费者模型呢?给我们带来了什么好处呢?
解耦性:两个模块,联系越紧密,耦合就越高,尤其是分布式系统。
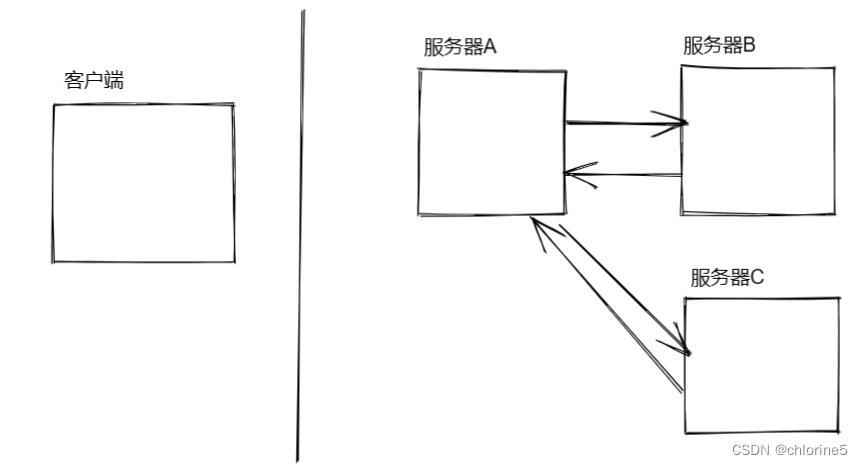
比如,考虑一个简单的分布式系统
如果A和B直接交互(A把请求发给B,B把响应返回到A)
彼此之间的耦合就是比较高的
- 1)如果B出现问题,很可能就把A也影响到了
- 2)如果未来再添加一个C,就需要对A这边的代码,做出一定的改动。
所以解决上述问题,使用生产者消费者模型,就可以有效的解决刚才的耦合问题。
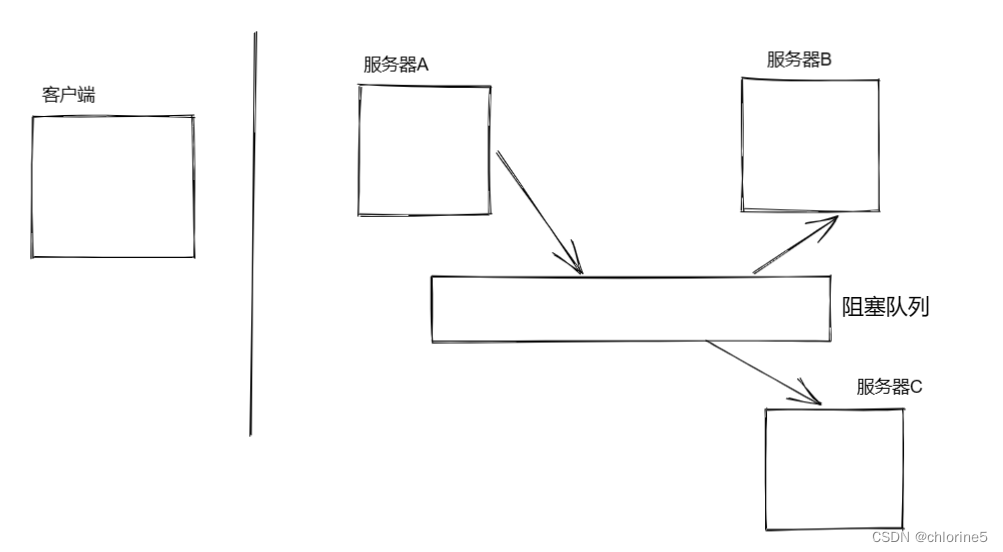
阻塞队列(当把阻塞队列封装成单独的 服务器程序部署到特定的机器上,这个时候就把这个队列,称为消息队列),此时的耦合度就会降低,如果B这边出现问题,就不会对A产生直接影响(A只是和对列交互,不知道B的存在)后续增加一个C,此时A不必进行任何修改,只需要C从队列中获取数据即可。
🎈削峰填谷
短时间内,(削峰)请求量比较多,(填谷)请求量比较少。
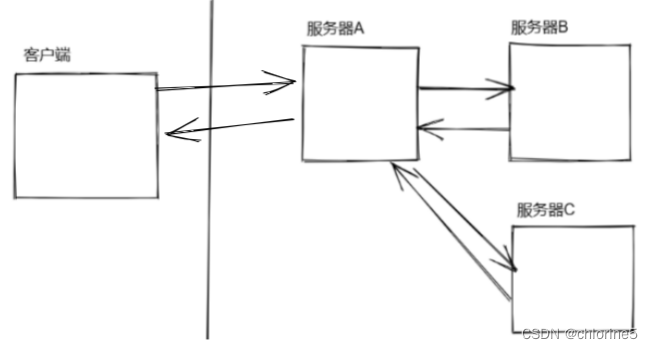
这个结构下,一旦客户端这边发起的请求非常多了,每个A收到的请求,都会立即发给B,A这边抗多少访问量B,B和A完全一样。但是在不同的服务器下,上面跑的业务不同,虽然访问量一样,单个访问,消耗的硬件资源不一样,可能A承担这些并发量就会挂了~~。比如B要操作数据库,数据库本身就是一个分布式系统,相对脆弱的环节。
引入生产者消费者模型,上述问题也会得到很大的改善。
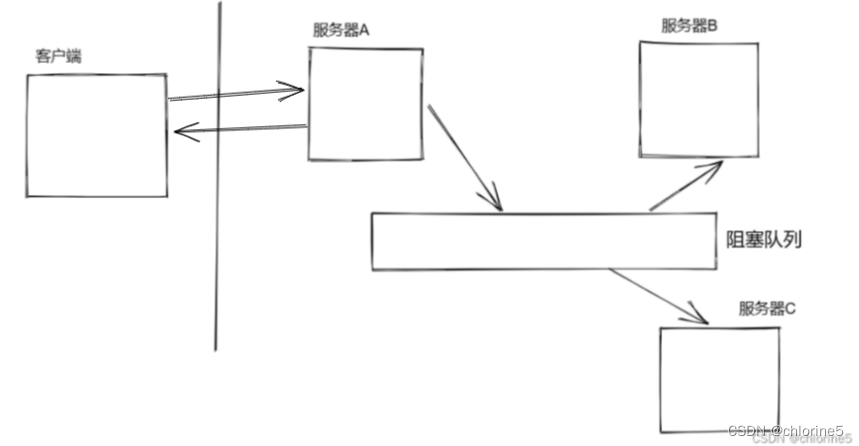
A这边收到较大的请求量,A会把对应的请求写入队列中,B仍然可以按照之前的节奏,来处理请求。 比如,正常情况下,A和B每秒处理1k请求,极端情况下,A这边每秒处理3K请求,如果让B也处理3k次,就要挂了。队列B承担了压力,B仍然可以按照1K次的节奏,处理请求。但是像上述的情况下不会一直持续的存在,只会短时间出现,过了峰值之后,A的请求就恢复正常了,B就可以逐渐的把积压的数据都给处理掉了。这就保证了整个系统在突发情况下,都能更好的控制。
就比如大坝中,如果上游水量增加,大坝关闸蓄水,把上游的压力分担很多,往下游去放水的时候,就有节奏的放,如果上游水量减少了,大坝开闸放水。
🚩阻塞队列的实现
在java标准库里,已经提供了线程的阻塞队列,让咱们直接使用。
标准库中,针对BlockingQueue提供了俩种重要的实现方式
- 1.基于数组
- 2.基于链表
了解标准库的阻塞队列怎么用,固然是一个环节,更重要的,是我们能够自己实现一个阻塞队列
阻塞队列包含三部分
- 基于一个普通的队列
- 线程安全——加锁(保证原子性)
- 阻塞 (队列空出元素,队列满入元素都会造成阻塞)
- 内存可见性 volatile关键字
普通队列,可以基于数组,也可以基于链表,基于数组其实是环形队列。
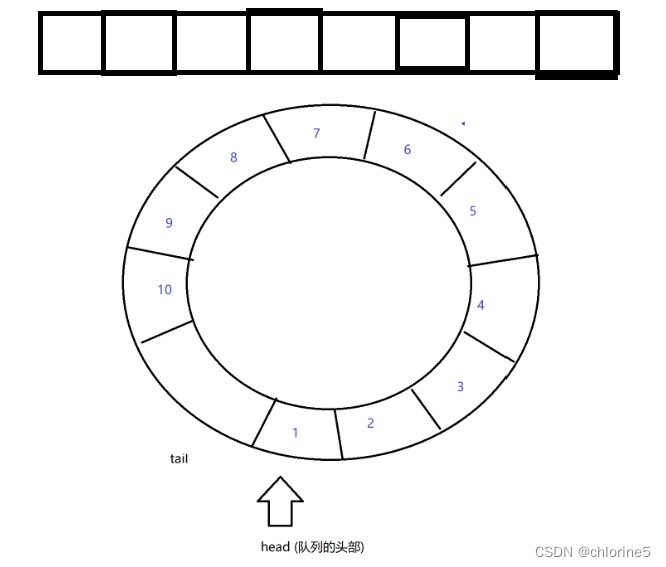
head指向的是队列的头部位置,tail是每插入一个元素tail都往后移一位,[head,tail)构成了一个区间,这个区间里的内容就是当前队列中的有效元素~,入队列,把新的元素,放到tail位置上,同时tail++,出队列,把head指向的元素给删除掉,head++;
但是初始情况下,队列为空的时候 head和tail重合,队列满了情况下,head和tail又重合了。
解决方案:
1.浪费一个格子,让tail指向head的前一个位置,就算满了。
2.专门搞一个变量size,来表示元素的个数,size为0是空,为数组最大值,就是满。(本次基于这种方法来写)
BlockingQueue阻塞队列中有俩个方法:
- put阻塞式的入队列
- tale阻塞式的出队列
📝基础的环形队列
首先定义三个变量,对头,队尾,有效元素的个数。- 入队列的时候,如果队列满了,普通队列就直接返回了,不满就插入元素,如果tail等于数组的最大长度了,那么就让tail设置成0.
- 如果队列为空,普通队列就直接返回了,不为空,就删除元素,如果head等于数组的最大长度,那么就让head=0即可
class MyBlockQueue{ //此处的最大长度,也可以指定构造方法,由构造方法来设定 private String[] data=new String[1000]; //队列的起始位置 private int head=0; //队列的结束位置的下一个位置 private int tail=0; //队列中有效元素的个数 private int size=0; //核心放大,入队列和出队列 public void put(String elem){ if(size==data.length){ //队列满了 //如果普通队列就直接return了 return; } //队列没满,真正的往里面添加元素 data[tail]=elem; tail++; //如果tail自增之后,到达了数组的末尾,这个时候就需要让它回到开头(环形队列) if(tail== data.length){ tail=0; } size++; } public String take(){ if(size==0){ return null; } //队列不为空,就队首元素就返回去,并且删除掉 String ret=data[head]; head++; if(head==data.length){ head=0; } size--; return ret; } }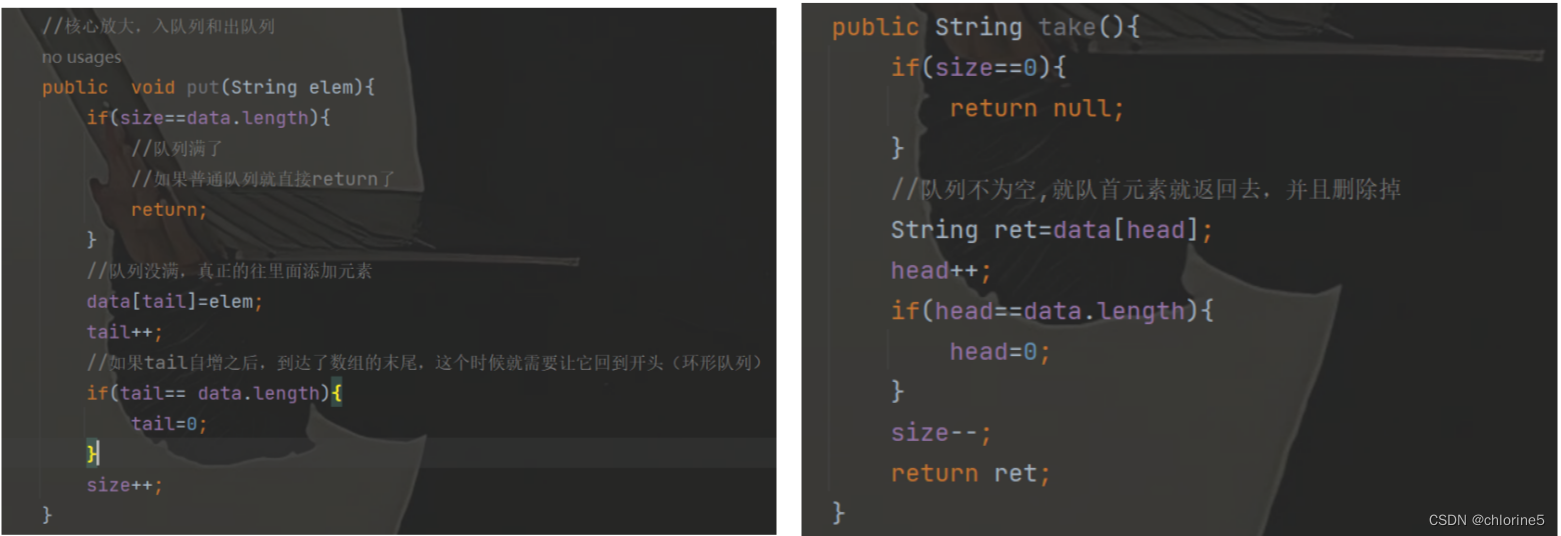 这很明显是线程不安全的情况,如果在多线程的情况,对一个变量修改,那是非常的不安全的。
这很明显是线程不安全的情况,如果在多线程的情况,对一个变量修改,那是非常的不安全的。📝阻塞队列的形成
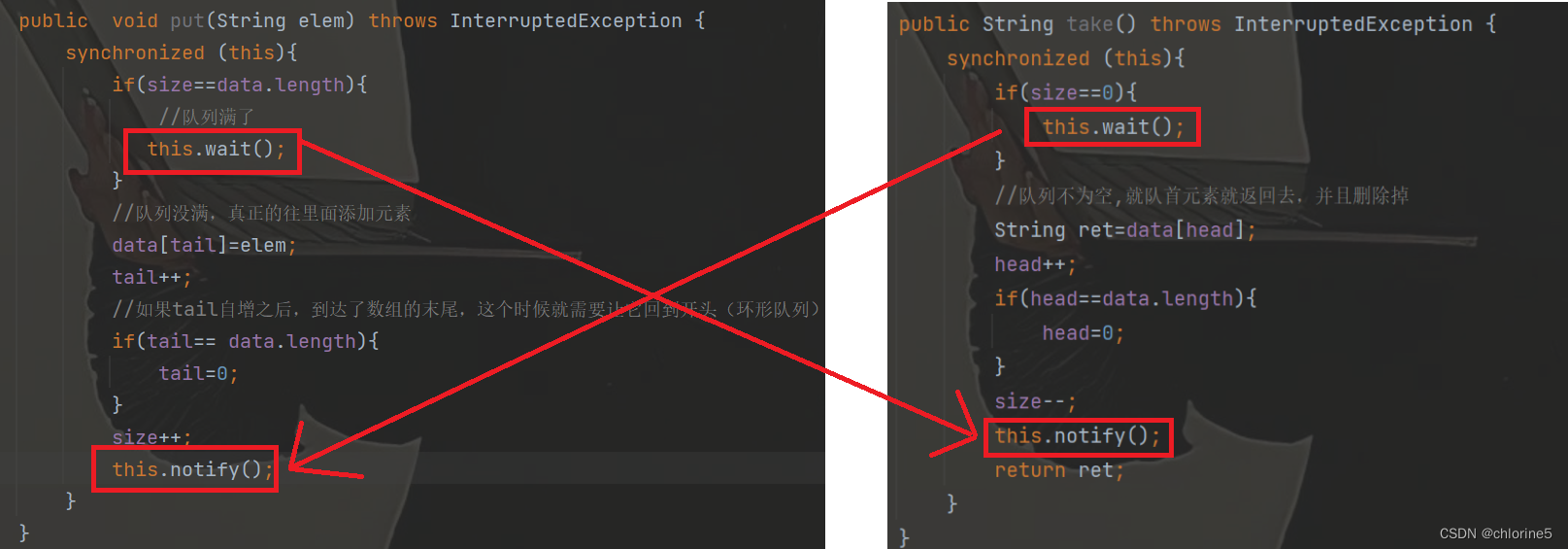
所以我们首先需要加锁。
我们直接将方法内部所有的代码段都加锁,因为里面涉及到多个变量修改,所以就要加锁来保证原子性和线程安全。
如何进行阻塞呢?
- a.如果队列为空,继续出队列,就会发生阻塞。阻塞到其他线程往队列里添加元素为止。
- b.如果队列为满,继续入队列,就会发生阻塞。阻塞到其他线程往队列里添加元素为止。
所以这里需要wait和notify机制。
一个队列,要么是空,要么是满。
take和put只有一边能阻塞。
- 如果put阻塞了,其他线程继续调用put也都会阻塞,只有靠take唤醒
- 如果take阻塞了,其他线程继续调用take也还是会阻塞,只有靠put唤醒。
当put方法,因为队列满了,进入wait之后,此时,wait返回(被唤醒的时候)队列一定是不满的嘛?wait除了notify之外,是否还有其他的方式唤醒呢?
interrupt是可以中断wait状态的,但是在用try catch捕捉异常的时候,如果没有throw抛出异常的话,代码会往下一直执行,那么下面的tail指向的元素给覆盖掉了,实际上此处队列是满着的,此时tail指向的元素,并非是无效元素(把一个有效元素给覆盖住了)

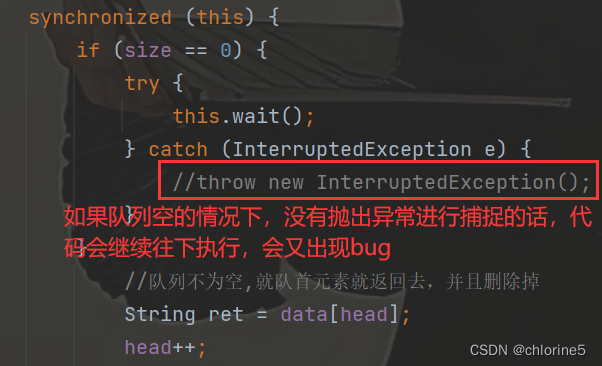
所以使用wait的时候,一定要注意,考虑当前wait唤醒,是通过notify唤醒,还是通过interrupt唤醒。
- notify唤醒说明其他线程调用了take,此时队列已经不满了,可以继续添加元素
- interrupt唤醒,此时队列还是满的,继续添加元素,肯定是会出现问题的。因为interrupt确实是可以让wait唤醒,1>如果try catch的捕获异常了后没有抛出异常的话,就会继续往下执行,2>如果try catch的捕获异常了后并且抛出异常,会终止了整个线程,代码没有什么问题。但是我们不能保证我们有没有抛出异常。
所以基于上述俩个情况,如果用notify唤醒的话,可以不用担心,因为唤醒了wait肯定是因为 调用了take删除元素才会唤醒的,但是如果用 interrupt唤醒之后,我们就要担心一下是否队列依旧是满的,因为interrupt调用之后,如果继续插入元素的话,就会出现问题。
关键要点,当wait返回的时候,需要进一步确认一下,看当前队列是不是满的(本来是因为队列满,进入阻塞,接触阻塞之后,再确定一下队列满不满,如果经过确定之后,队列还是满的,继续进行wait)
使用wait的时候,往往都是使用while作为条件判定的方式,目的就是为了让wait唤醒之后还能再确认一次,是否条件仍然满足。
对于interrupt的情况下,这样用while作为条件判定的方式,就会每次唤醒之后,还会继续判定一次,如果还是等于,就继续,这样就避免了有没有捕捉异常后是否有抛出异常了。
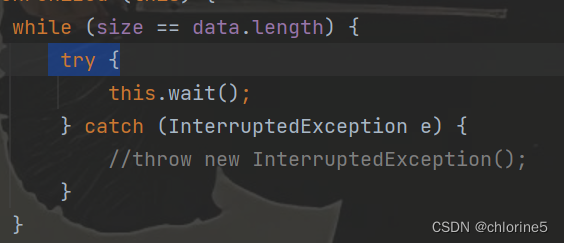
所以针对俩种情况,我们最好的情况下,都是用while来判定一下,防止出现bug现象。
本题主要针对的是wait() notify()情况下,也不排除用interrupt唤醒程序。
📝 内存可见性
内存可见性是指当我们对同一个资源进行多次大量的使用的时候,那么jvm就不会对这个资源的改变加载到主内存中去,而是加载到运行内存中,但是只有对一个值的改变加载到主内存才是真正得对这个资源得修改,内存可见性其实就是为了保证我们每一次对某个资源的修改都能加载到主内存中去,而不是因为这个资源可能在某个时间段内被多次使用,就被jvm选择,暂时不把它加载到主内存中去。 这样就会导致其他线程再读取当前变量值的时候,就会是原来的值。
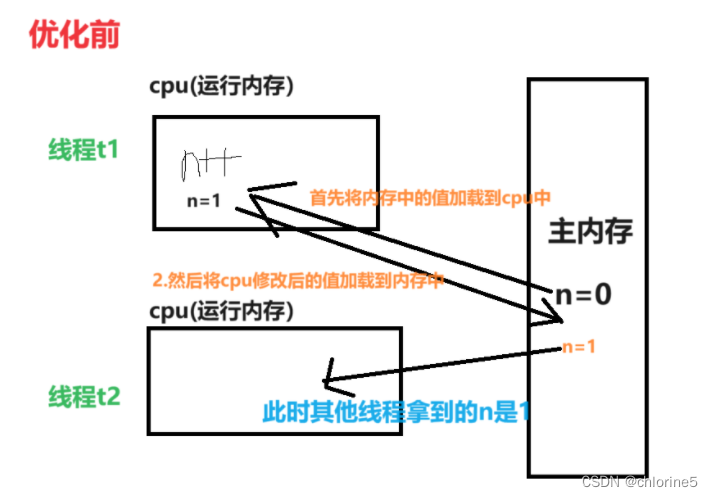
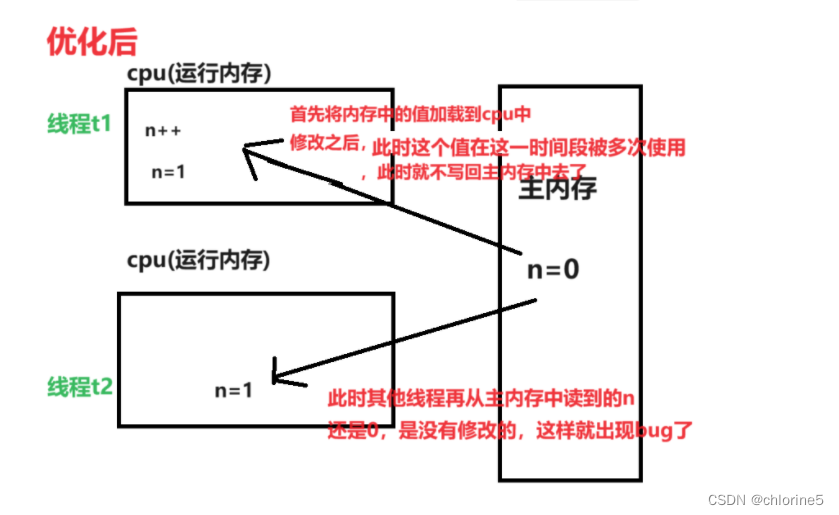
所以我们对于阻塞队列中,我们如果消费者和生产者每次都生产的很多或者消费的很多的话,那么可能会被jvm直接加载到运行内存中去,那么就会导致bug存在。所以避免内存可见性情况,我们用volatile来修饰变量。
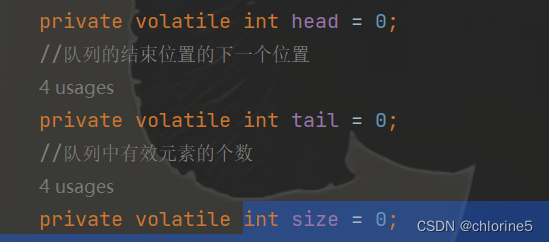
📝阻塞队列代码
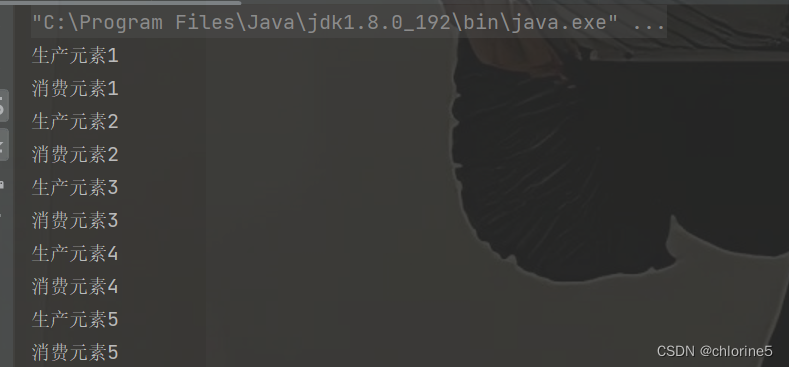
package BlockingQueue; import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.BlockingQueue; import java.util.concurrent.LinkedBlockingQueue; class MyBlockQueue { //此处的最大长度,也可以指定构造方法,由构造方法来设定 private String[] data = new String[1000]; //队列的起始位置 private volatile int head = 0; //队列的结束位置的下一个位置 private volatile int tail = 0; //队列中有效元素的个数 private volatile int size = 0; //核心放大,入队列和出队列 public void put(String elem) throws InterruptedException { synchronized (this) { while (size == data.length) { this.wait(); } //队列没满,真正的往里面添加元素 data[tail] = elem; tail++; //如果tail自增之后,到达了数组的末尾,这个时候就需要让它回到开头(环形队列) if (tail == data.length) { tail = 0; } size++; this.notify(); } } public String take() throws InterruptedException { synchronized (this) { while(size == 0) { this.wait(); } //队列不为空,就队首元素就返回去,并且删除掉 String ret = data[head]; head++; if (head == data.length) { head = 0; } size--; this.notify(); return ret; } } } public class Test { public static void main(String[] args) { MyBlockQueue queue=new MyBlockQueue(); //消费者 Thread t1=new Thread(()->{ while (true){ try { String result=queue.take(); System.out.println("消费元素"+result); //Thread.sleep(500);//生产慢 消费快 } catch (InterruptedException e) { throw new RuntimeException(e); } } }); //生产者 Thread t2=new Thread(()->{ int num=1; while (true){ try { queue.put(num+" "); System.out.println("生产元素"+num); num++; Thread.sleep(500);//生产快,消费慢 } catch (InterruptedException e) { throw new RuntimeException(e); } } }); t1.start(); t2.start(); } }我设定的是生产的慢,消费的快,每0.5s生产一个,我们可以看到,生产一个消费一个。
 如果设定的生产的快,消费的慢,那么此时我们设定的数组长度是1000,等一下功夫都生产到1000了,然后等消费1个,然后继续生产,消费一个生产一个这样的速度了。
如果设定的生产的快,消费的慢,那么此时我们设定的数组长度是1000,等一下功夫都生产到1000了,然后等消费1个,然后继续生产,消费一个生产一个这样的速度了。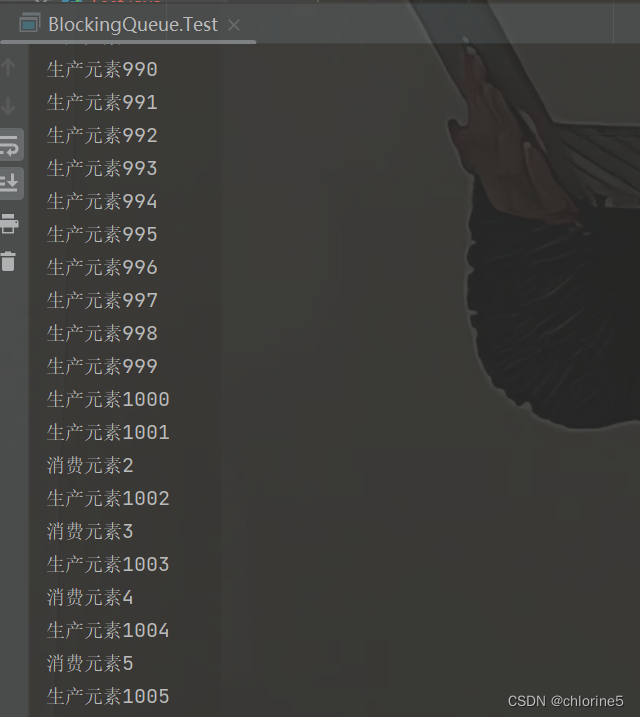
要努力成为自己想要的样子~



