
can‘t find model ‘zh



成功解决[E050] Can’t find model ‘en_core_web_sm’. It doesn’t seem to be a Python package or a valid path to a data directory.
直接上解决方案
步骤一:
豆瓣源安装spacy包
pip install spacy -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
步骤二:下载en_core_web_sm或者zh_core_web_sm包,缺哪个下载哪个
zh_core_web_sm
en_core_web_sm
spacy中文模型官网
spacy官网
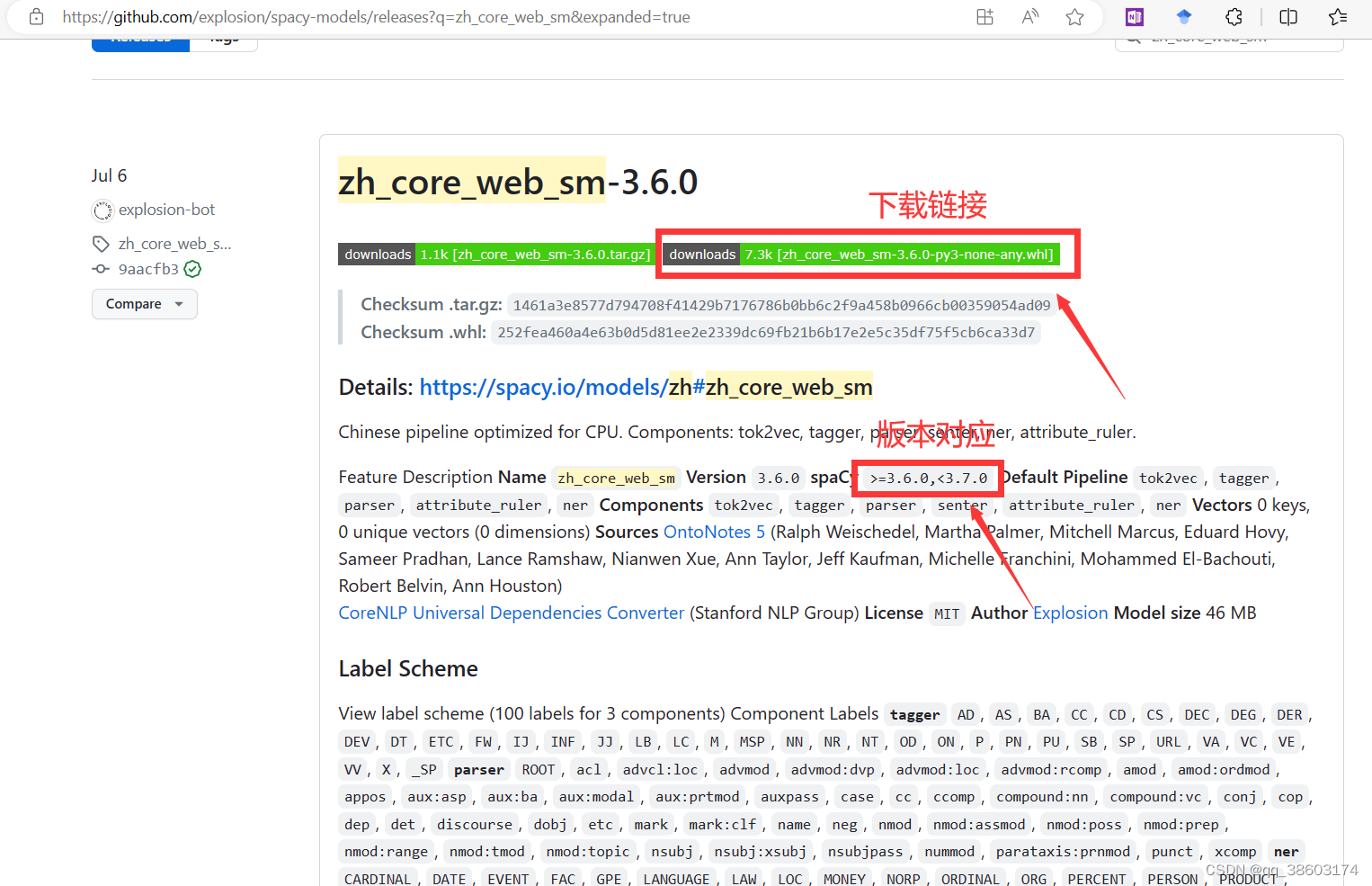
注意根据对应版本下载
步骤三:终端pip安装whl
pip install + whl文件地址
pip install C:\Users\Zz\zh_core_web_sm-3.6.0-py3-none-any.whl
接下来就可以使用啦,给出两个小栗子
import spacy
# 加载英文模型
nlp = spacy.load("en_core_web_sm")
# 示例文本
text = "Apple is planning to build a new factory in China."
# 定义句式
pattern = [{"POS": "PROPN"}, {"LEMMA": "be"}, {"POS": "VERB"}]
# 处理文本
doc = nlp(text)
# 匹配句式
matcher = spacy.matcher.Matcher(nlp.vocab)
matcher.add("CustomPattern", None, pattern)
matches = matcher(doc)
# 提取匹配的数据并进行标注
for match_id, start, end in matches:
span = doc[start:end]
print("Matched:", span.text)
span.merge()
# 打印标注后的文本
print("Tagged Text:", doc.text)
import spacy
# 加载中文模型
nlp = spacy.load("zh_core_web_sm")
text = "写入历史了:苹果是美国第一家市值超过一万亿美元的上市公司。"
# 处理文本
doc = nlp(text)
for token in doc:
# 获取词符文本、词性标注及依存关系标签
token_text = token.text
token_pos = token.pos_
token_dep = token.dep_
# 规范化打印的格式
print(f"{token_text:token_pos:token_dep:
文章版权声明:除非注明,否则均为主机测评原创文章,转载或复制请以超链接形式并注明出处。



