
设计模式学习笔记 - 设计原则 - 10.实战:针对非业务的通用框架开发,如何做需求分析和设计及如何实现一个支持各种统计规则的性能计数器



前言
接下来我们在结合一个支持各种统计规则的性能计数项目,学习针对一个非业务的通用框架开发,如何来做需求分析、设计和实现,同时学习如何灵活应用各种设计原则。
项目背景
设计开发一个小的框架,能够获取接口调用的各种统计信息,比如,响应时间的最大值(max)、最小值(min)、平均值(avg)、百分位值(percentile)、接口调用次数(count)、频率(tps)等,并且支持将统计结果以各种显示格式(比如:JSON、网页格式、自定义显示格式等)输出到终端(Console、HTTP 网页、Email、日志文件、自定义输出终端等),以方便查看。
如果让你来负责开发这样一个通用的框架,应用到各种业务系统中,支持实时计算、查看数据统计信息,你会如何设计和实现呢?
1.针对非业务的通用框架开发,如何做需求分析和设计
1.1需求分析
性能计数器作为一个跟业务无关的功能,完全可以把它开发成一个独立的框架或者类库,集成到很多业务系统中。而作为可被复用的框架,除了功能性需求外,非功能性需求也非常重要。所以,接下来,我们从这两个方面做需求分析。
1.1.1功能性需求
相对于一长串的文字描述,我们更容易理解短的、罗列的比较完整、分门别类的列表信息。我们把上面的需求拆解成一个个的干条条。拆解之后如下所示,是不是看起来更加清晰、有条理了?
- 接口统计信息: 包括接口响应时间的统计信息,以及接口的调用次数的统计信息。
- 统计信息类型:max、min、avg、percentile、count、tps。
- 统计信息显示格式:JSON、HTML、自定义显示格式。
- 统计信息显示终端:Console、HTTP 网页、Email、日志文件、自定义输出终端。
此外,还可以借助产品设计的时候,经常用到的线框图,把最终数据的显示样式画出来,会更加一目了然。具体的线框图如下所示:
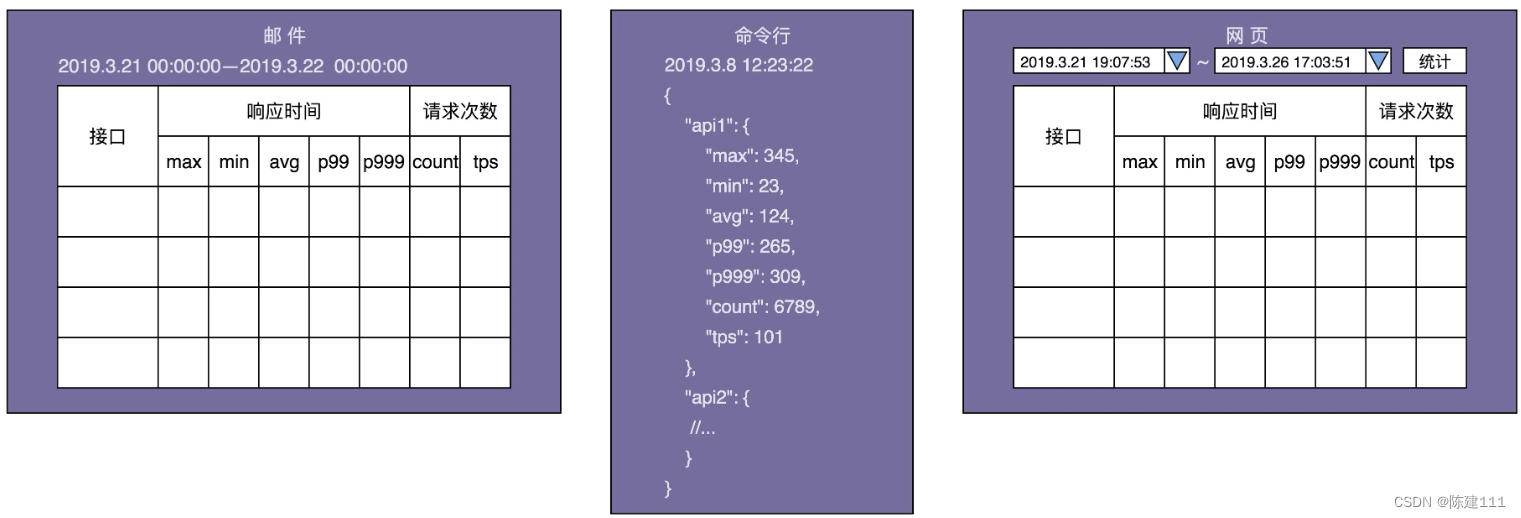
实际上,从线框图中,我们还能挖掘出下面几个隐藏的需求。
- 统计的触发方式:包括主动和被动。
- 主动表示以一定的频率定时统计数据,并主动推送到显示终端,比如邮件推送。
- 被动表示用户触发统计,比如用户在网页中选择要统计的时间区间,触发统计,并将结果显示给用户。
- 统计时间区间:框架需要支持自定义统计时间区间,比如统计最近 10 分钟的某接口 tps、访问次数,或者统计 3 月 7 日 00 点到 3 月 8 日 00 点之间某接口响应的最大值、最小值、平均值等。
- 统计时间间隔:对于主动触发统计,我们还要支持指定统计时间间隔,也就是多久触发一次统计显示。比如,每隔 10s 统计一次接口信息并显示到命令行中,每隔 24 小时发送一封统计信息邮件。
1.1.2 非功能性需求
对于这样一个通用的框架的开发,我们还需要考虑很多非功能性的需求。我总结了一下几个比较重要的方面。
易用性
易用性更像是一个评判产品的标准。我们在开发这样一个技术框架时,也要有产品意识。框架是否易集成、易插拔、跟业务代码是否松耦合、提供的接口是否够灵活等等,都是我们应该花心思去思考和设计的。有的时候,文档写的好坏甚至可能决定一个框架是否受欢迎。
性能
对于需要继承到业务系统的框架来说,我们不希望框架本身的代码执行效率,对业务系统有太多性能上的影响。对于性能计数器这个框架来说,一方面,我们希望它是低延迟的,也就是统计代码不影响或者很少影响接口本身的响应时间;另一方面,我们希望框架本身对内存的消耗不大。
扩展性
这里说的扩展性和之前讲的代码的扩展性有点类似,都是在不修改或者少修改代码的情况下添加新功能。但是这两种也有区别。之前讲的扩展是从框架代码开发者的角度来说的。这里所说的扩展性是从框架使用者的角度来说的,特指使用者可以不修改框架源码,甚至不拿到框架源码的情况下,扩展新的功能。这就有点类似开发插件。关于这个,举个例子来解释下。
feign 是一个 HTTP 客户端框架,我们可以在不修改框架源码的情况下,用如下方式来扩展自己的编码方式、日志、拦截器等。
Feign feign = Feign.builder() .logger(new CustomizedLogger()) .encoder(new FormEncoder(new JacksonEncoder())) .decoder(new JacksonDecoder()) .errorDecoder(new ResponseErrorDecoder()) .requestInterceptor(new RequestHeadersInterceptor()) .build(); public class RequestHeadersInterceptor implements RequestInterceptor { @Override public void apply(RequestTemplate template) { template.header("appid", "..."); template.header("version", "..."); template.header("timestamp", "..."); template.header("token", "..."); template.header("idempotent", "..."); template.header("sequence-id", "..."); } } public class CustomizedLogger extends Feign.Logger { // ... } public class ResponseErrorDecoder implements ErrorDecoder { @Override public Exception decode(String methodKey, Response response) { // ... } }容错性
这一点也非常重要。对于性能计数器框架来说,不能因为框架本身的异常导致接口请求出错。所以,我们要对框架可能的各种异常情况都考虑全面,对外暴露的接口抛出所有的运行时、非运行时异常都进行捕获处理。
通用性
为了提高框架的复用性,能够灵活应用到各种场景中。框架在设计的时候,要尽可能通用。我们要多去思考一下,除了接口统计这样一个需求,还可以适用到其他哪些场景中,比如是否可以处理其他事件的统计信息,比如 SQL 请求时间的统计信息、业务统计信息(比如支付成功率)等。
1.2前面讲了需求分析,现在看看如何针对需求做框架设计。
前面讲了需求分析,现在看下如何针对需求做框架设计。
对于稍微复杂系统的开发,很多人觉得不知从何开始。我个人喜欢借鉴 TDD(测试驱动开发)和Prototype(最小原型)的思想,先聚焦于一个简单的应用场景,基于此设计实现一个简单的原型。
对于性能计数器这个框架的开发来说,我们可以先聚焦于非常具体、简单的应用场景,比如统计用户注册、登录这两个接口的响应时间的最大值、平均值、接口调用次数,并将统计结果以 JSON 的格式输出到命令行中。
现在这个需求简单、具体、明确,设计起来难度降低了很多。
我们先给出应用场景的代码,如下所示:
// 应用场景:统计下面两个接口(注册和登录)的响应时间和访问次数 public class UserController { public void register(UserVo user) { // ... } public UserVo login(String telephone, String password) { //... } }要输出接口的响应时间的最大值、平均值和接口调用次数,我们首先要采集每次接口请求的响应时间,并且存储起来,然后按照某个时间间隔做聚合统计,最后才将结果输出。在原型系统的代码实现中,我们可以把所有的代码都塞到一个类中,暂时不用考虑任何代码质量、线程安全、性能、扩展性等问题,怎么简单怎么来。
最小原型实现的代码如下。其中, recordResponseTime() 和 recordTimestamp() 两个函数分别用来记录接口请求的响应时间和访问时间。startRepeatedReport() 函数以指定的频率统计数据并输出结果。
public class Metrics { // Map的key是接口名称,value对应请求接口的响应时间和时间戳 private Map responseTimes = new HashMap(); private Map timestamps = new HashMap(); private ScheduledExecutorService executor = Executors.newSingleThreadScheduledExecutor(); public void recordResponseTime(String apiName, double responseTime) { responseTimes.putIfAbsent(apiName, new ArrayList()); responseTimes.get(apiName).add(responseTime); } public void recordTimestamp(String apiName, double timestamp) { timestamps.putIfAbsent(apiName, new ArrayList()); timestamps.get(apiName).add(timestamp); } public void startRepeatedRepost(long period, TimeUnit unit) { executor.scheduleAtFixedRate(new Runnable() { @Override public void run() { Gson gson = new Gson(); Map stats = new HashMap(); for (Map.Entry entry : responseTimes.entrySet()) { String apiName = entry.getKey(); List apiRespTimes = entry.getValue(); stats.putIfAbsent(apiName, new HashMap()); stats.get(apiName).put("max", max(apiRespTimes)); stats.get(apiName).put("min", min(apiRespTimes)); } for (Map.Entry entry : timestamps.entrySet()) { String apiName = entry.getKey(); List apiTimestamps = entry.getValue(); stats.putIfAbsent(apiName, new HashMap()); stats.get(apiName).put("count", (double) apiTimestamps.size()); } System.out.println(gson.toJson(stats)); } }, 0 , period, unit); } private double max(List list) { /*省略代码实现*/ } private double min(List list) { /*省略代码实现*/ } }我们通过 50 行代码就实现了最小原型。接下来,我们再来看看,如何用它来统计注册、登录接口的响应时间和访问次数。
// 应用场景:统计下面两个接口(注册和登录)的响应时间和访问次数 public class UserController { private Metrics metrics = new Metrics(); public UserController() { this.metrics.startRepeatedRepost(60, TimeUnit.SECONDS); } public void register(UserVo user) { long startTimestamp = System.currentTimeMillis(); metrics.recordTimestamp("register", startTimestamp); // ... long respTimestamp = System.currentTimeMillis(); metrics.recordResponseTime("register", startTimestamp); } public UserVo login(String telephone, String password) { long startTimestamp = System.currentTimeMillis(); metrics.recordTimestamp("login", startTimestamp); //... long respTimestamp = System.currentTimeMillis(); metrics.recordResponseTime("login", startTimestamp); } }最小原型的代码实现虽然简陋,但它却帮我们将思路理顺了很多,我们现在就基于它做最终的框架设计。下面是我针对性能计数器框架画的一个粗略的系统设计图。图可以非常直观地体现设计思想,并且能有效地帮助我们释放更多的脑空间,来思考其他细节问题。
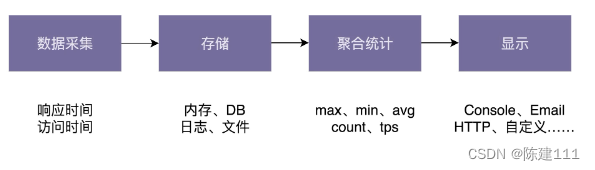
我们把系统整个框架分为四个模块:数据采集、存储、聚合统计、显示。每个模块负责的工作简单罗列下:
- 数据采集:负责打点采集原始数据,包括记录每次接口请求的响应时间和请求时间。数据采集过程要高度容错,不能影响到接口本身的可用性。此外,因为这部分功能是暴露给框架使用的,所以在设计数据采集 API 的时候,也要尽量考虑易用性。
- 存储:负责将数据采集的原始数据保存下来,以便后面做聚合统计。数据的存储方式有很多种,比如:Redis、MySQL、HBASE、日志、文件、内存等。数据库比较耗时,为了尽量减少对接口性能(比如响应时间)的影响,采集和存储的过程异步完成。
- 聚合统计:负责将原始数据聚合为统计数据,比如:max、min、avg、pencentile、count、tps 等。为了支持更多的聚合统计规则,代码希望尽可能灵活、可扩展。
- 显示:负责将统计数据以某种格式显示到终端,比如:输出到命令行、邮件、网页、自定义显示中断等。
前面讲过面向对象分析、设计和实现的时候,讲到设计阶段最终输出的是类的设计,同时也讲到,软件设计开发是一个迭代的过程,分析、设计和实现这三个阶段的界限划分并不明显。所以,在本节只给出了比较粗糙的模块划分,第二小节我们会将更加详细的设计来讲解。
1.3简单总结下分析和设计
对于非业务通用框架的开发,在做需求分析的时候,除了功能性的需求分析之外,还需要考虑框架的非功能性需求。比如,框架的易用性、性能、扩展性、容错性、通用性等。
对于复杂框架的设计,很多人往往会觉得无从下手。本小节给出了一些小技巧,包括:
- 画产品线框图
- 聚焦简单的应用场景
- 设计实现最小原型
- 画系统设计图等。
这些方法的目的都是为了让问题更加简化、具体、明确,提供一个迭代设计开发的基础,逐步推进。
实际上,除了开发,其他任何事情,如果我们总是等所有的东西都想好了再开始,那这件事可能永远都开始不了。
完事开头难,所以先迈出第一步很重要。
2.如何实现一个支持各种统计规则的性能计数器
第一节,对计数器框架做了需求分析和粗略的模块划分。本节,我们利用面向对象设计、实现方法,并结合之前学过的设计思想、设计原则来看一下,如何编写灵活、可扩展的、高质量的代码实现。
2.1小步快跑、逐步迭代
第一节,我们将真个框架分为数据采集、存储、聚合统计、显示这四个模块。此外关于统计触发方式(主动、被动触发)、统计时间区间(统计哪一个时间段内的数据)、统计时间间隔(对于主动推送方法,多久统推送一次)也做了简单的设计。
虽然第一小节为我们奠定了迭代开发的基础,但离我们最终期望的框架的样子还有很大的距离。当我们视图去实现上面罗列的所有功能需求,希望写出一个完美的框架时,会有一种“脑子不够用”的感觉。这可能会产生很强挫败感,就会陷入自我否定的情绪中。
我们应该分多个版本逐步完善这个框架。第一个版本可以先实现一些基本功能,对于更高级、更复杂的功能,以及非功能性需求不做过高的要求,在后续的 v2.0、v3.0 …版本中继续迭代优化。
针对这个框架开发,我们在 1.0 版本中,暂时只实现下面这些功能。剩下的功能留在 v2.0、v3.0 版本,在后面章节再来优化。
- 数据采集:负责打点采集原始数据,包括记录接口每次请求的响应时间和请求时间。
- 存储:负责将采集的原始数据保存下来,以便之后做聚合统计。数据的存储方式有很多种,我们暂时只支持 Redis 这一种存储方式,并且,采集与存储两个过程同步执行。
- 聚合统计:负责将原始数据聚合为统计数据,包括响应时间的最大值、最小值、平均值、99.9 百分位值、99百分位值,以及接口请求的次数和 tps。
- 显示:负责将统计数据以某种格式显示到终端,暂时只支持主动推送命令行和邮件。命令行间隔 n 秒统计显示上 m 秒的数据(比如,间隔 60s 统计上 60s 的数据)。邮件每日统计上日的数据。
2.面向对象设计与实现
在 《面向对象 - 9.实践:如何进行面向对象分析、设计与编码》中,我们把面向对象设计和实现分开来讲解,界限划分的明显。在实际的软件开发中,这两个过程往往是交叉进行的。一般是现有粗糙的设计,然后着手实现,实现的过程发现问题,再回过头来补充修改设计。所以,对于这个框架的开发来说,需要把设计和实现放到一块来讲解。
上一小节中的最小原型实现,所有的代码都耦合在一个类中,这显然是不合理的。接下来,我们就按照面向对象设计的几个步骤,来重新划分、设计类。
2.1 划分职责进而识别出有哪些类
根据需求描述,我们先大致识别出下面几个接口或类。
这一步不难,完全就是翻译需求。
- MetricsCollector 类负责 API,来采集接口请求的原始数据。我们可以为 MerticsCollector 抽象出一个接口,但这并不是必须的,因为暂时我们只能想到一个 MerticsCollector 的实现方式。
- MetricsStorage 接口负责原始数据存储,RedisMetricStorage 实现 MetricsStorage 接口。这样做是为了今后灵活地扩展存储方法,比如用 HBase 来存储。
- Aggregator 类负责根据原始数据计算统计数据。
- ConsoleReporter 类、EmailReporter 类分别负责以一定的频率统计并发送数据到命令行和邮件。置于 ConsoleReporter 和 EmailReporter 是否可以抽象出复用的抽象类,或者抽象出一个公共的接口,我们暂时不确定。
2.2 定义类与类之间的关系
接下来就是定义属性和方法,定义类与类之间的关系。这两步没办法分的很开,所以将它们合在一起讲解。
大致识别出几个核心类之后,我习惯的做法是,现在 IDE 中创建好这几个类,然后开始试着定义它们的属性和方法。在设计类、类与类之间的交互的时候,我会不断地用之前学过的设计原则和思想来审视设计是否合理,比如,是否满足单一职责原则、开闭原则、依赖注入、KISS 原则、DRY 原则、迪米特法则,是否符合基于接口而非实现编程,代码是否高内聚、低耦合,是否可以抽象出可复用的代码等等。
MetricsCollector 类的定义非常简单,具体代码如下所示。对比第一节代码,MetricsCollector 通过引入 RequestInfo 类来封装原始数据信息,用一个采集函数代替了之前的两个函数。
public class MetricsCollector { private MetricsStorage metricsStorage; // 基于接口而非实现编程 // 依赖注入 public MetricsCollector(MetricsStorage metricsStorage) { this.metricsStorage = metricsStorage; } // 用一个函数代替了最小原型中的两个函数 public void recordRequest(RequestInfo requestInfo) { if (requestInfo == null || StringUtils.isBlank(requestInfo.getApiName())) { return; } metricsStorage.saveRequestInfo(requestInfo); } } public class RequestInfo { private String apiName; private double responseTime; private long timestamp; // 省略构造函数、getter、setter方法... }MetricsStorage 接口和 RedisMetricsStorage 类的熟悉和方法也比较明确。具体实现代码如下所示。
注意,一次性取太长时间区间的数据,可能会导致拉取太多的数据到内存中,有可能会撑爆内存。对于 Java 来说,就有可能出发 OOM(Out of Memory)。而且,即便不出现 OOM,内存还够用,但也会因为内存吃紧,导致频繁的 Full GC,进而导致系统接口请求处理变慢,甚至超时。这个问题解决起来也并不难,先给你自己思考后,在后面会进行解答。
public interface MetricsStorage { void saveRequestInfo(RequestInfo requestInfo); List getRequestInfos(String apiName, long startTimeInMillis, long endTimeInMillis); Map getRequestInfos(long startTimeInMillis, long endTimeInMillis); } public class RedisMetricsStorage implements MetricsStorage{ // 省略构造函数、属性等... @Override public void saveRequestInfo(RequestInfo requestInfo) { // ... } @Override public List getRequestInfos(String apiName, long startTimeInMillis, long endTimeInMillis) { // ... } @Override public Map getRequestInfos(long startTimeInMillis, long endTimeInMillis) { // ... } }MetricsCollector 和 MetricsStorage 类的设计思路比较简单,不同的人给出的设计结果应该大差不差。但是,统计和结果显示这两个功能就不一样了,可以有多种设计思路。实际上,如果我们把显示所要完成的功能逻辑细分一下的话,主要包含下面 4 点:
- 根据给定的时间区间,从数据库中拉取数据;
- 根据原始数据,计算得到统计数据;
- 将统计数据显示到终端(命令行或邮件);
- 定时触发以上 3 个过程。
面向对象设计和实现要做的事情,就是把合适的代码到合适的类中。所以,我们现在要做的工作就是,把以上的 4 个功能逻辑划分到几个类中。划分的方法有很多种,比如,可以把前两个逻辑放到一个类中,第 3 个逻辑放到另外一个类中,第 4 个逻辑作为上地类(God Class)组合前面两个类来触发前 3 个逻辑的执行。当然,我们也可以把第 2 个逻辑单独放到一个类中,第 1、3、4 都放到另一个类中。
置于到底如何选择,判定的标准是,让代码尽量地满足高内聚、低耦合、单一职责、开闭原则等之前讲到的各种设计原则和思想,尽量地让设计满足代码易复用、易读、易扩展、易维护。
暂时选择把 1、3、4 都放到 ConsoleReporter 或 EmailReporter 类中,把第二个逻辑放到 Aggregator 类中。其中 Aggregator 类的逻辑比较简单,我们把它设计成只包含静态方法的工具类。具体代码实现如下:
public class Aggregator { public static RequestStat aggregate(List requestInfos, long durationInMills) { double maxRespTime = Double.MIN_VALUE; double minRespTime = Double.MAX_VALUE; double avgRespTime = -1; double p999RespTime = -1; double p99RespTime = -1; double sumRespTime = 0; long count = 0; for (RequestInfo requestInfo : requestInfos) { ++count; double respTime = requestInfo.getRespTime(); if (maxRespTime respTime) { minRespTime = respTime; } sumRespTime += respTime; } if (count != 0) { avgRespTime = sumRespTime / count; } long tps = count / durationInMills * 100; Collections.sort(requestInfos, new Comparator() { @Override public int compare(RequestInfo o1, RequestInfo o2) { double diff = o1.getRespTime() - o2.getRespTime(); if (diff 0.0) { return 1; } else { return 0; } } }); int idx999 = (int) (count * 0.999); int idx99 = (int) (count * 0.99); if (count != 0) { p99RespTime = requestInfos.get(idx99).getRespTime(); p999RespTime = requestInfos.get(idx999).getRespTime(); } RequestStat requestStat = new RequestStat(); requestStat.setMaxRespTime(maxRespTime); requestStat.setMinRespTime(minRespTime); requestStat.setAvgRespTime(avgRespTime); requestStat.setP999RespTime(p999RespTime); requestStat.setP99RespTime(p99RespTime); requestStat.setCount(count); requestStat.setTps(tps); return requestStat; } } public class RequestStat { private double maxRespTime; private double minRespTime; private double avgRespTime; private double p999RespTime; private double p99RespTime; private double sumRespTime; private long count; private long tps; // 省略构造函数、setter、getter }ConsoleReporter 相当于上帝类,定时根据给定的时间区间,从数据库中取出数据,借助 Aggregator 类完成统计工作,并将统计结果输出到命令行。具体实现代码如下所示:
public class ConsoleReporter { private MetricsStorage metricsStorage; private ScheduledExecutorService executor; public ConsoleReporter(MetricsStorage metricsStorage) { this.metricsStorage = metricsStorage; this.executor = Executors.newSingleThreadScheduledExecutor(); } // 第4个代码逻辑:定义触发第1、2、3代码逻辑的执行 public void startRepeatedReport(long periodInSeconds, long durationInSeconds) { executor.scheduleAtFixedRate(new Runnable() { @Override public void run() { long durationInMillis = durationInSeconds * 1000; long endTimeMillis = System.currentTimeMillis(); long startTimeMillis = endTimeMillis - durationInMillis; Map requestInfos = metricsStorage.getRequestInfos(startTimeMillis, endTimeMillis); Map stats = new HashMap(); for (Map.Entry entry : requestInfos.entrySet()) { String apiName = entry.getKey(); List requestInfosApi = entry.getValue(); // 第2个代码逻辑:根据原始数据,计算得到统计数据 RequestStat requestStat = Aggregator.aggregate(requestInfosApi, durationInMillis); stats.put(apiName, requestStat); } // 第3个代码逻辑:将统计数据显示到终端(命令行获邮件) System.out.println("Time Span: [" + startTimeMillis + ", " + endTimeMillis + "]"); Gson gson = new Gson(); System.out.println(gson.toJson(stats)); } }, 0, periodInSeconds, TimeUnit.SECONDS); } } public class EmailReporter { private static final Long DAY_HOURS_IN_SECONDS = 86400L; private MetricsStorage metricsStorage; private EmailSender emailSender; private List toAddresses = new ArrayList(); public EmailReporter(MetricsStorage metricsStorage) { this.metricsStorage = metricsStorage; this.emailSender = new EmailSender(/*省略参数*/); } public EmailReporter(MetricsStorage metricsStorage, EmailSender emailSender) { this.metricsStorage = metricsStorage; this.emailSender = emailSender; } public void addToAddress(String toAddress) { toAddresses.add(toAddress); } public void startRepeatedReport(long periodInSeconds, long durationInSeconds) { Calendar calendar = Calendar.getInstance(); calendar.add(Calendar.DATE, 1); calendar.set(Calendar.HOUR_OF_DAY, 0); calendar.set(Calendar.MINUTE, 0); calendar.set(Calendar.SECOND, 0); calendar.set(Calendar.MILLISECOND, 0); Date firstTime = calendar.getTime(); Timer timer = new Timer(); timer.schedule(new TimerTask() { @Override public void run() { long durationInMillis = DAY_HOURS_IN_SECONDS * 1000; long endTimeMillis = System.currentTimeMillis(); long startTimeMillis = endTimeMillis - durationInMillis; Map requestInfos = metricsStorage.getRequestInfos(startTimeMillis, endTimeMillis); Map stats = new HashMap(); for (Map.Entry entry : requestInfos.entrySet()) { String apiName = entry.getKey(); List requestInfosApi = entry.getValue(); // 第2个代码逻辑:根据原始数据,计算得到统计数据 RequestStat requestStat = Aggregator.aggregate(requestInfosApi, durationInMillis); stats.put(apiName, requestStat); } // 格式化为html格式,并发送邮件 } }, firstTime, DAY_HOURS_IN_SECONDS * 1000); } }2.3 将类组装起来并提供执行入口
因为这个框架稍微有些特殊,有两个执行入口:一个是 MetricsCollector 类,提供了一组 API 来采集原始数据;另外一个是 ConsoleReporter 和 EmailReporter,用来触发统计显示。框架具体事宜方式如下:
public class Demo { public static void main(String[] args) { MetricsStorage storage = new RedisMetricsStorage(); ConsoleReporter consoleReporter = new ConsoleReporter(storage); consoleReporter.startRepeatedReport(60, 60); EmailReporter emailReporter = new EmailReporter(storage); emailReporter.addToAddress("test@qq.com"); emailReporter.startRepeatedReport(); MetricsCollector collector = new MetricsCollector(storage); collector.recordRequest(new RequestInfo("register", 123, 10234)); collector.recordRequest(new RequestInfo("register", 123, 10234)); collector.recordRequest(new RequestInfo("register", 123, 10234)); collector.recordRequest(new RequestInfo("login", 123, 10234)); collector.recordRequest(new RequestInfo("login", 123, 10234)); try { Thread.sleep(100000); } catch (InterruptedException e) { e.printStackTrace(); } } }3.Review 设计与实现
现在来看下,上面的代码实现是否符合这些设计原则和思想。
MetricsCollector
MetricsCollector 负责采集和存储数据,职责相对来说还算单一。它基于接口而非实现编程,通过依赖注入的方式来传递 MetricsStorage 对象,可以在不修改代码的情况下,灵活地替换不同的存储方式,满足开闭原则。
MetricsStorage 和 RedisMetricsStorage
MetricsStorage 和 RedisMetricsStorage 的设计比较简单。当我们需要实现新的存储方式时,只需要实现 MetricsStorage 接口即可。因为所有用到 MetricsStorage 和 RedisMetricsStorage 的地方,都是基于相同的接口函数来编程的,所以,除了在组装类的地方有所改动(从 RedisMetricsStorage 改为新的存储实现类),其他接口函数调用的地方都不需要改动,满足开闭原则。
Aggregator
Aggregator 是一个工具类,里面只有一个镜头函数,有 50 行左右的代码量,负责各种统计数据的计算。当需要扩展新的统计功能的时候,需要修改 aggregate() 函数代码,并且一旦越来越多的统计功能添加进来之后,这个函数的代码量会持续增加,可读性、可维护性就变差了。所以,从刚刚的分析来看,这个类的设计可能存在职责不单一、不易扩展等问题,需要在之后的版本中,对其结构做优化。
ConsoleReporter、EmailReporter
ConsoleReporter 和 EmailReporter 中存在代码重复的问题。在这两个类中,从数据库中取数据、做统计的逻辑都是相同的,可以抽取出来复用,否则就违背 DRY 原则。而且整个类负责的事情比较多,职责不是太单一。特别是显示部分的代码,可能会比较复杂(比如 Email 的展示方式),最好是将展示部分的代码逻辑拆分成独立的类。此外,因为代码中涉及线程操作,并且调用了 Aggregator 的镜头函数,所以代码的可测试性不好。
今天给出的代码实现还是有很多问题的,在后面章节会慢慢优化,给你展示设计的演进过程(这比直接给最终的方案要有意义得多)。实际上优秀的代码都是重构出来的,复杂的代码都是慢慢堆砌出来的。毕竟罗马不是一天建成的,优秀的代码也是靠几年的时间慢慢迭代出来的。
- 统计的触发方式:包括主动和被动。







