
利用GPT开发应用001:GPT基础知识及LLM发展



文章目录
- 一、惊艳的GPT
- 二、大语言模型LLMs
- 三、自然语言处理NLP
- 四、大语言模型LLM发展
一、惊艳的GPT
想象一下,您可以与计算机的交流速度与与朋友交流一样快。那会是什么样子?您可以创建哪些应用程序?这正是OpenAI正在助力构建的世界,他们的GPT模型为我们的设备带来了类似人类对话能力的功能。
GPT的全称,是Generative Pre-Trained Transformer(生成式预训练Transformer模型)是一种基于互联网的、可用数据来训练的、文本生成的深度学习模型。GPT与专注于下围棋或机器翻译等某一个具体任务的“小模型”不同,AI大模型更像人类的大脑。它兼具“大规模”和“预训练”两种属性,可以在海量通用数据上进行预先训练,能大幅提升AI的泛化性、通用性、实用性。
作为人工智能(AI)领域的最新进展,GPT-4(Generative Pre-trained Transformer - 4)和ChatGPT(Chat Generative Pre-trained Transformer)是基于大量数据训练的大型语言模型(Large Language Models - LLMs),使它们能够以非常高的准确性识别和生成类似人类的文本。
这些人工智能模型的影响远不止于简单的语音助手。得益于OpenAI的模型,开发者现在可以利用自然语言处理(Natural Language Processing - NLP)的力量创建了解我们需求的应用程序,这在过去曾是科幻小说。从学习并适应的创新客户支持系统到理解每个学生独特学习风格的个性化教育工具,GPT-4和ChatGPT打开了一个全新的可能性世界。
但GPT-4和ChatGPT究竟是什么?我们需要深入探讨这些AI模型的基础知识、起源和关键特征。通过理解这些模型的基本原理,您将为基于这些新强大技术构建下一代应用程序迈出重要的一步。
二、大语言模型LLMs
作为大语言模型(Large Language Models - LLMs),GPT-4和ChatGPT是自然语言处理(Natural Language Processing - NLP)领域最新的模型类型,而NLP本身是机器学习(Machine Learning - ML)和人工智能(AI)的一个子领域。因此,在我们深入了解GPT-4和ChatGPT之前,让我们快速了解一下NLP和其他相关领域。
对于人工智能有不同的定义,但其中一个更多或少得到共识的说法是,人工智能指的是开发能够执行通常需要人类智能的任务的计算机系统。根据这个定义,许多算法都属于人工智能范畴。比如,在GPS应用中的交通预测任务或者战略视频游戏中使用的基于规则的系统。从外部看,这些例子中,机器似乎需要智能来完成这些任务。
机器学习(Machine Language - ML)是人工智能(AI)的一个子集。在机器学习中,我们不试图直接实现人工智能系统所使用的决策规则。相反,我们尝试开发算法,让系统能够通过示例自我学习。自从上世纪50年代开始进行机器学习研究以来,许多机器学习算法已经在科学文献中被提出。其中,深度学习(Deep Learning - DL)算法是机器学习模型的著名示例,而GPT-4和ChatGPT是基于一种称为transformers的特定类型深度学习算法。下图展示了这些术语之间的关系。
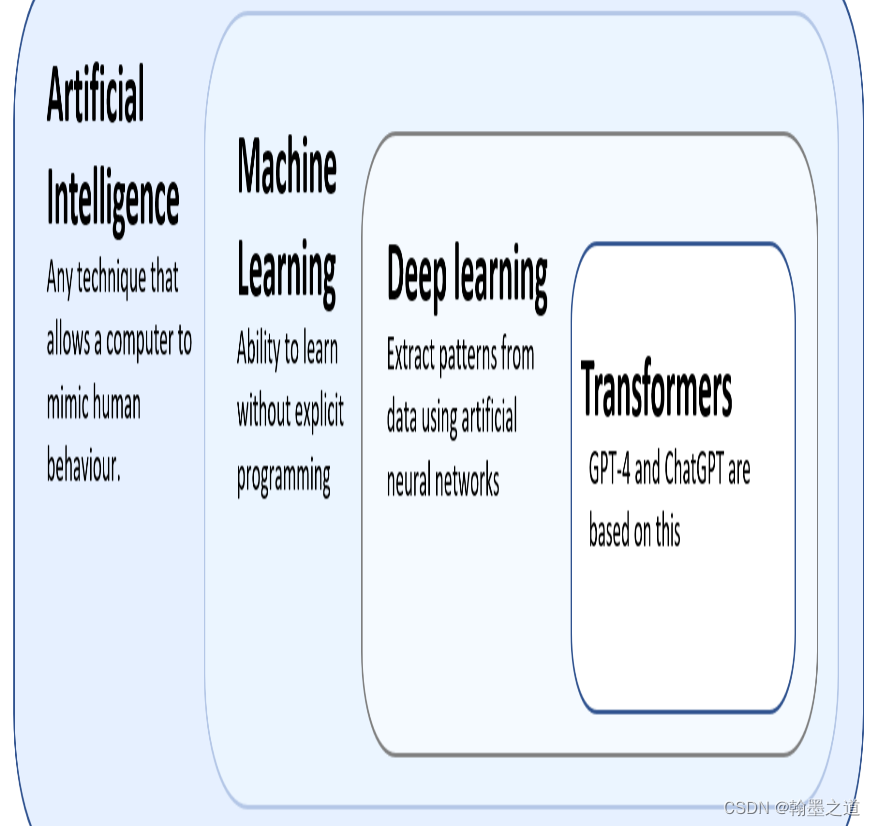
三、自然语言处理NLP
自然语言处理(Natural Language Processing - NLP)是一种人工智能应用,专注于计算机与自然人类语言文本之间的交互。现代NLP解决方案基于机器学习算法。NLP的目标是让计算机理解自然语言文本。这一目标涵盖了广泛的任务:
-
文本分类
将输入的文本划分为预定义的组别。例如,包括情感分析和主题分类等任务。
-
自动翻译
将文本从一种语言自动翻译成另一种语言。
-
问答
根据给定的文本回答问题。
-
文本生成
基于给定的输入文本(称为提示),模型生成连贯和相关的输出文本。
四、大语言模型LLM发展
正如前面提到的,大语言模型(Large Language Models - LLM)是一种试图解决文本生成任务的机器学习模型。LLMs使计算机能够理解、解释和生成人类语言,从而实现更加有效的人机交流。为了做到这一点,LLMs分析或训练大量的文本数据,从而学习句子中单词之间的模式和关系。通过给定输入文本,这种学习过程使LLMs能够对最有可能出现的下一个单词进行预测,并以此方式生成对文本输入有意义的回应。最近几个月发布的现代语言模型非常庞大,并且经过了大量的文本训练,它们现在可以直接执行大多数NLP任务,如文本分类、机器翻译、问答等。GPT-4和ChatGPT模型是两种在文本生成任务上表现优异的现代LLMs。
LLMs的发展可以追溯到数年前。它始于简单的语言模型,比如n-gram模型,它试图基于前面的单词来预测句子中的下一个单词。n-gram模型使用频率来实现这一点。预测的下一个单词是在它训练过的文本中跟随前面单词最频繁出现的单词。虽然这种方法是一个良好的开端,但它需要在理解上下文和语法方面有所改进,以避免生成不一致的文本。
为了提高这些n-gram模型的性能,引入了更先进的学习算法,包括循环神经网络(Recurrent Neural Networks - RNN)和长短期记忆网络(long short term memory networks - LSTM)。这些模型能够学习更长的序列并比n-gram模型更好地分析上下文,但它们仍然需要帮助以高效处理大量数据。这些类型的循环模型长时间以来一直是最高效的模型,因此在自动机器翻译等工具中被广泛使用。
-



