【风格迁移】pix2pixHD:高分辨率图像生成



pix2pixHD:高分辨率图像生成
- 提出背景
- 问题1: 如何提高生成图像的照片级真实感和分辨率?
- 问题2: 如何利用实例级别的对象语义信息进一步提高图像质量?
- 问题3: 如何实现图像合成的多模态性,允许交互式对象编辑?
- pix2pixHD = 粗到细的生成器 + 多尺度鉴别器 + 改进的对抗学习目标 + 实例地图的使用 + 实例级特征嵌入学习
- 递进式细节增强(Progressive Detail Enhancement, PDE)
- 粗到细的生成器
- 多尺度鉴别器
- 改进的对抗学习目标
- 实例地图的使用
- 实例级特征嵌入学习
- HD 对比 pix2pix
- 全流程优化
提出背景
论文:https://arxiv.org/pdf/1711.11585.pdf
代码:https://github.com/NVIDIA/pix2pixHD
官网:https://tcwang0509.github.io/pix2pixHD/
pix2pixHD 通过使用条件生成对抗网络(Conditional GANs)解决了以往(pix2pix)在图像合成领域遇到的两个主要问题:
-
生成高分辨率图像的困难:以往的方法在尝试生成高分辨率(如2048×1024)的图像时,会遇到稳定性差和图像质量不佳的问题。这主要是因为在高分辨率条件下,细节的丢失更为明显,而且模型训练的稳定性也难以保证。
-
缺乏细节和真实质感:即便能生成高分辨率图像,以前的技术往往无法捕捉到真实世界中物体表面的细节和质感,导致生成的图像看起来不够真实。
为了解决这些问题,论文提出了以下几个关键的技术创新:
-
稳定的对抗学习目标:通过引入一种新的学习目标,使得在对抗训练过程中,模型能够更稳定地学习,从而有效提高生成图像的稳定性和质量。
-
多尺度生成器及鉴别器架构:采用了一种新的网络架构设计,可以同时考虑图像的不同尺度(即不同大小的视觉细节),帮助模型更好地捕捉和再现图像中的细节和质感。
-
感知损失:在一些情况下,通过引入预训练网络(如VGGNet)计算的感知损失,可以进一步提升生成图像的细节和真实感。感知损失是基于高层次特征的差异计算的,能够帮助模型更好地理解和模仿真实图像的视觉质感。
此外,为了让用户能更自由地编辑和定制图像,论文还提出了两项扩展功能:
-
实例级对象分割信息:通过引入实例级的分割信息,模型可以区分同一类别内不同的对象实例。这样,用户就可以更灵活地进行图像编辑操作,比如添加、删除或更改图像中的特定对象。
-
生成多样化结果:提出了一种方法,可以根据同一输入的标签图生成多种不同的图像结果。这意味着用户可以交互式地编辑同一对象的外观,为创造性使用提供了更多的可能性。
先前的工作,如传统的GANs和条件GANs,已经为我们提供了生成图像的基本工具和框架。
它们像是探索图中的重要路标和营地,指示了图像合成领域的基本方向和可能性。
然而,这些方法在面对高分辨率图像合成时遇到了重大挑战,比如训练的不稳定性、优化问题,以及生成的图像缺乏细节和真实感。
pix2pixHD的提出,就像是在这张探索图上找到了一条新道路。
通过引入新的多尺度生成器和鉴别器架构,以及一个改进的对抗学习目标,pix2pixHD不仅解决了高分辨率图像合成过程中的稳定性和优化问题,还成功地提升了生成图像的细节和真实感。
这条新道路让探险者能够更加顺畅地接近宝藏,即实现高质量的高分辨率图像合成。
同时,pix2pixHD还注重于用户交互和语义编辑的功能,允许用户以前所未有的灵活性和细粒度控制图像的生成过程。
这就好比在这条新道路上,不仅铺设了平稳的路面,还设置了指引标志和休息站,使得旅程更加丰富和个性化。
基础框架:pix2pix
pix2pixHD的发展始于对其基线模型pix2pix的检讨。
pix2pix采用条件GAN框架进行图像到图像的翻译,其核心在于通过一个生成器和一个鉴别器的对抗训练,将语义标签图转换为逼真的图像。
然而,当尝试直接应用pix2pix框架以生成高分辨率图像时,研究者发现训练过程不稳定,且生成图像的质量不尽人意。
这促使他们思考如何改进pix2pix框架以适应高分辨率图像的生成。
提升照片级真实感和分辨率
为了克服这一挑战,pix2pixHD采用了一种粗到细的生成器和多尺度鉴别器架构,以及一个稳健的对抗学习目标函数。
通过将生成器分解为全局生成器网络和局部增强网络,pix2pixHD能够有效整合全局与局部信息,显著提高生成图像的细节和真实感。
多尺度鉴别器进一步确保了在不同尺度上对图像的真实性进行判断,从而在维持高分辨率的同时提高图像质量。
利用实例级别的对象语义信息
pix2pixHD还引入了实例级别的对象语义信息来进一步提升图像质量。
与传统的语义标签图相比,实例级别的语义标签图包含了每个独立对象的唯一标识符,从而为区分同一类别中的不同对象提供了可能。
通过计算实例边界图并将其与语义标签图结合,pix2pixHD能够更精确地处理对象边界,进一步提高了生成图像的真实性。
实现多模态图像合成
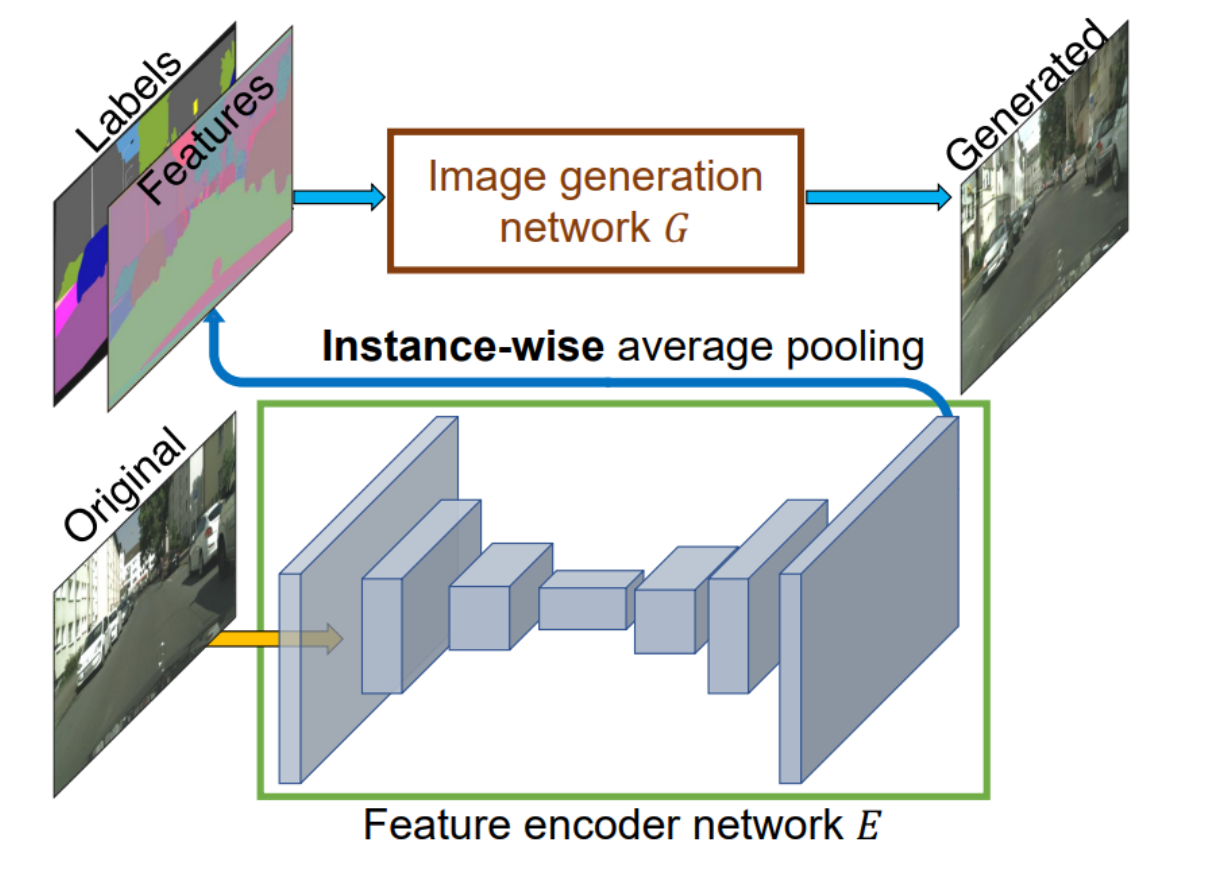
最后,为了解决图像合成的多模态性问题并允许用户进行交互式对象编辑,pix2pixHD提出了一种学习实例级特征嵌入的方法。
通过为每个对象实例训练一个编码器网络来寻找对应的低维特征向量,pix2pixHD允许用户通过操作这些特征来灵活控制图像合成过程。
这种方法不仅使得生成的图像多样化,而且还允许对生成内容进行实例级控制,为用户提供了前所未有的编辑能力。
问题1: 如何提高生成图像的照片级真实感和分辨率?
-
子特征1:粗到细的生成器 (Coarse-to-fine generator)
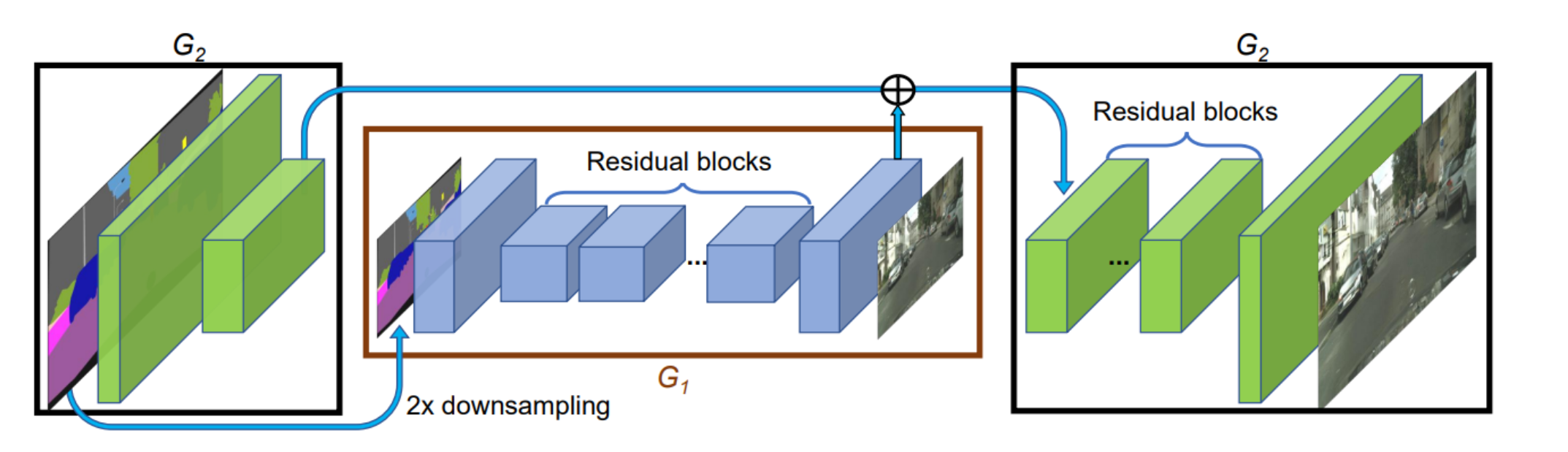
- 解决方案:将生成器分解为全局生成器网络(G1)和局部增强网络(G2)。
- 原因:这样做是因为直接生成高分辨率图像会导致训练不稳定和图像质量不佳。分层次逐步细化可以有效整合全局与局部信息,提高图像的细节和真实感。
-
子特征2:多尺度鉴别器 (Multi-scale discriminator)
- 解决方案:采用三个不同尺度上操作的具有相同网络结构的鉴别器(D1, D2, D3)。
- 原因:这是因为高分辨率图像合成对鉴别器设计提出了挑战,需要大的感受野以区分真实和合成图像。多尺度鉴别器能够在不同尺度上捕捉图像的全局一致性和细节特征。
-
子特征3:改进的对抗学习目标 (Improved adversarial loss)
- 解决方案:引入基于鉴别器的特征匹配损失来稳定训练,使生成器必须在多个尺度上产生自然统计量。
- 原因:这是因为仅使用传统的对抗损失可能导致生成图像缺乏多样性和细节。特征匹配损失能够促进生成图像在不同层次上与真实图像更相似。
问题2: 如何利用实例级别的对象语义信息进一步提高图像质量?
- 子特征:实例地图的使用 (Using Instance Maps)
- 解决方案:计算实例边界图,并将其与语义标签图一起输入生成器网络。
- 原因:这是因为实例地图提供了语义标签图所不具备的对象边界信息,有助于区分同一类别中的不同对象,尤其是在对象紧密排列时。
问题3: 如何实现图像合成的多模态性,允许交互式对象编辑?
- 子特征:实例级特征嵌入学习 (Learning an Instance-level Feature Embedding)
- 解决方案:训练一个编码器网络E来找到每个实例对应的低维特征向量,并允许通过操作这些特征来灵活控制图像合成过程。
- 原因:这是因为语义标签图到图像的映射是一对多的关系。通过引入低维特征通道作为生成器的输入,可以实现对生成图像的实例级控制,支持生成多样化的、真实的图像。
以城市街景图像合成为例:
-
粗到细的生成器:首先,使用全局生成器网络(G1)生成低分辨率的城市街景图。
这一步捕捉了整个场景的布局和主要元素,如建筑物、道路和天空。
然后,局部增强网络(G2)对这个低分辨率图像进行细化,添加细节如窗户的反射、路面的纹理和行人的细节,从而产生高分辨率、细节丰富的图像。
-
多尺度鉴别器:在生成图像的同时,三个不同尺度的鉴别器(D1, D2, D3)评估生成图像的真实性。
小尺度鉴别器关注细节如窗户和门的质感,中尺度鉴别器评估建筑物和车辆的形状,而大尺度鉴别器确保整个场景的布局和光照条件的自然性。
-
改进的对抗学习目标:使用基于鉴别器的特征匹配损失来指导生成器,在不同尺度上产生更自然的图像。这种方法鼓励生成的城市街景在全局布局和局部细节上都与真实图像相似。
-
实例地图的使用:通过计算城市街景中每个对象(如车辆、行人和树木)的实例边界图,并将这些边界图与语义标签图一起输入生成器,可以在细节丰富的街景图像中准确地区分和渲染每个对象。
-
实例级特征嵌入学习:通过训练一个编码器网络E来为街景中的每个对象(如特定的车辆或行人)生成一个低维特征向量。
通过调整这些特征向量,可以实现对生成图像中对象的位置、外观和类型的交互式编辑。
例如,可以改变一辆车的颜色,或者将行人移动到不同的位置。
这种方法结合了粗到细的图像生成、多尺度鉴别、实例边界信息和实例级控制,使得生成的城市街景图像不仅具有高度的真实感和分辨率,而且可以根据用户的具体需求进行个性化编辑,支持创造出符合特定视觉要求的图像。
pix2pixHD = 粗到细的生成器 + 多尺度鉴别器 + 改进的对抗学习目标 + 实例地图的使用 + 实例级特征嵌入学习
在讨论pix2pixHD及其对高分辨率图像合成的贡献时,我们发现了一个重要但未明确定义的关键步骤,即递进式细节增强。
递进式细节增强(Progressive Detail Enhancement, PDE)
定义:递进式细节增强是一种图像生成策略,通过分阶段逐步提升图像的分辨率和细节,每个阶段都在前一个阶段生成的基础上进一步细化图像的局部细节和全局一致性。
这种策略包括两个核心元素:粗到细的生成器(Coarse-to-fine Generator)和多尺度鉴别器(Multi-scale Discriminator),它们共同作用于逐步提升生成图像的质量和真实感。
工作机制:
- 分阶段生成:首先使用全局生成器(G1)在较低分辨率上创建图像的粗略轮廓,然后通过局部增强网络(G2,G3,…)逐步提高图像的分辨率和细节,每一步都在前一步的基础上增加更多的细节。
- 尺度敏感评估:通过在不同尺度上部署鉴别器(D1, D2, D3),在每个分辨率阶段评估生成图像的真实性和细节,确保在全局一致性和局部细节上均达到高质量标准。
- 递进式学习目标:结合使用传统的对抗学习目标和特征匹配损失,以稳定训练过程并在不同层次上优化生成图像的质量。
粗到细的生成器
- 子解法:首先使用全局生成器网络(G1)生成低分辨率图像,然后通过局部增强网络(G2)增加细节。
- 原因:之所以采用这种方法,是因为直接生成高分辨率图像容易导致训练不稳定和图像质量下降。
- 通过分阶段生成,可以有效整合全局布局和局部细节,从而提高图像的真实感和分辨率。
问题:粗到细的生成器是怎么设计的?
采用了层级化的网络结构,包括全局生成器(Global Generator)和一个或多个局部增强网络(Local Enhancer Networks)。
全局生成器(Global Generator, G1)
- 目的:构建图像的基本框架和大致轮廓,设定整体风格和色调。
- 结构:通常包括一个卷积层前端(用于提取特征),一系列残差块(用于处理和传输深层特征),以及一个转置卷积层后端(用于上采样,增加分辨率)。
- 分辨率:操作在较低的分辨率上(例如,1024×512),足以捕获图像的全局信息但不足以细化局部细节。
局部增强网络(Local Enhancer Networks, G2, G3, …)
- 目的:在全局生成器的基础上增加局部细节,提高图像的分辨率和质量。
- 结构:每个局部增强网络也由卷积层前端、残差块和转置卷积层后端组成。与全局生成器相比,局部增强网络专注于更高分辨率的图像部分,以细化细节和纹理。
- 分辨率:每个局部增强网络都将输出的分辨率增加到前一网络的两倍(即,分辨率翻倍,例如从1024×512到2048×1024,再到4096×2048,依此类推)。
- 级联操作:局部增强网络可以级联使用,每一级都在前一级的基础上进一步提升图像的细节和分辨率。通过这种方式,可以根据需要生成更高分辨率的图像。
设计原理
- 分层处理:通过分层处理图像,从粗略到细致,使网络能够更有效地学习和生成图像的不同层次的特征。
- 逐步细化:从全局信息的粗略捕获开始,逐步向图像添加更多的局部细节,这种逐步细化的过程有助于生成更加真实和详细的图像。
- 效率与质量的平衡:通过这种粗到细的生成方式,模型可以在保证生成效率的同时,逐步提升生成图像的质量和真实感。
它是一个两阶段的生成器,具有一个残差网络G1,在较低分辨率下生成图像,然后是另一个残差网络G2,在更高分辨率下细化输出。
输入到G2的是G2的特征图与G1的最后一个特征图的逐元素和,结合全局结构和局部细节,以产生高分辨率的图像。
多尺度鉴别器
- 子解法:使用三个不同尺度的鉴别器(D1, D2, D3)来评价生成图像的真实性。
- 原因:之所以采用这种方法,是因为高分辨率图像合成需要在不同尺度上捕捉图像的全局一致性和细节特征,多尺度鉴别器可以更好地区分真实和合成图像。
- 适用场景: 在需要同时考虑全局结构和局部细节的图像生成任务中,特别是在生成高分辨率图像时,使用多尺度鉴别器是一个有效的解决策略。
问题:多尺度鉴别器是怎么设计的?
三个尺度:典型的多尺度鉴别器包括三个鉴别器(D1, D2, D3),分别在原始尺度、下采样一次(2倍降低分辨率)和下采样两次(4倍降低分辨率)的图像上工作。这样的设置允许模型同时关注图像的不同层次的细节。
- D1(原始尺度):负责评估图像在最高分辨率下的真实性,关注图像的细微细节,如纹理、边缘等。
- D2(中等尺度):在降低一次分辨率后评估图像,平衡全局结构和局部细节的真实性。
- D3(最低尺度):在进一步降低的分辨率下工作,主要关注图像的全局一致性和布局。
改进的对抗学习目标
- 子解法:引入基于鉴别器的特征匹配损失,以及使用VGG网络进行感知损失计算。
- 原因:之所以采用这种方法,是因为传统的对抗损失可能导致生成图像缺乏多样性和细节。
- 特征匹配损失和感知损失能够促进生成图像在不同层次上与真实图像更为相似,提高训练的稳定性和生成图像的质量。
实例地图的使用
- 子解法:在生成过程中引入实例边界图。
- 原因:之所以采用这种方法,是因为实例地图提供了额外的对象边界信息,有助于在生成图像时更精确地区分和渲染同一类别中的不同对象,尤其是在对象紧密排列的场景中。
- 实例地图的使用是为了解决传统的语义标签图在处理紧密相连的同类对象时界限不清的问题。
- 通过向生成网络添加边界信息,可以在生成具有相同语义标签的多个对象时,保持它们之间的界限更加清晰和明确。
这个图比较了仅使用语义标签(a)与添加边界图(b)用于图像生成的情况。
语义标签可能会给连接在一起的物体(如汽车)赋予相同的标签,使得难以区分它们。
边界图有助于识别和分离同一类别中的个别物体,这对于生成具有清晰和明确物体边界的图像至关重要。
实例级特征嵌入学习
- 子解法:训练编码器网络E为每个对象实例生成低维特征向量,允许通过调整这些特征向量来控制图像合成过程。
- 原因:之所以采用这种方法,是因为它支持在生成图像的过程中实现对对象的交互式编辑,如改变颜色、纹理或位置。
- 这种方法利用了语义标签图到图像映射的一对多关系,允许用户创造多样化且符合个性化需求的图像。
在图像生成框架中,特征编码器网络E的作用是为图像中的每个对象实例提取特征,这些特征随后用于指导图像生成网络G生成更为精细和逼真的图像。
实例级特征嵌入学习允许生成网络理解和控制图像中每个实例的特定属性,如形状、纹理和风格等。
这样可以在保持图像整体一致性的同时,实现对个别对象的细粒度编辑和调整。
在整个图像生成流程中,内容说明了如何将实例级特征与语义标签相结合,以提升最终生成图像的质量和真实感。
比如你正在组织一场大型的主题派对,这个派对不仅要在整体上营造出令人印象深刻的氛围,还要关注到每个小角落的装饰细节。
-
粗到细的生成器:首先,你确定派对的总体主题,比如是海洋主题。
这就像全局生成器(G1),设定了整个图像(或者说派对)的基调。
接下来,你会细化主题,为不同区域(如入口区、餐饮区、舞池)添加特定的装饰,这类似于局部增强网络(G2,G3…),它们在全局基础上进一步增加细节,让每个区域都有其独特风格。
-
多尺度鉴别器:在准备过程中,你需要从不同的角度(整体布局和每个小角落的装饰)检查派对的布置,确保从大环境到小细节都符合主题,没有遗漏或不协调的地方。
这就相当于使用多尺度鉴别器在不同尺度上评估生成图像的真实性和细节,以确保整体和局部都达到预期效果。
-
改进的对抗学习目标:在装饰的过程中,你可能会发现某些元素与主题不够契合或者效果不如预期,因此需要不断调整。
这种调整过程就像是通过特征匹配损失来改进训练目标,确保每个元素都能贡献于整体氛围的营造,提高派对的整体质量。
-
实例地图的使用:在布置场地时,你需要确保每个装饰元素(如气球、海洋生物模型)都有其特定的位置和作用,避免重复或混乱。
这相当于在图像合成中使用实例地图,明确每个对象的边界和属性,提高场景的清晰度和真实感。
-
实例级特征嵌入学习:最后,为了让派对更加个性化和多样化,你可能会为每个区域甚至每个装饰项目提供几种设计方案供选择,比如不同颜色和样式的桌布和餐具。
这就像实例级特征嵌入学习,允许对生成图像的每个部分进行细粒度的控制和定制,使得整个场景更加丰富和多元。
HD 对比 pix2pix
pix2pix模型主要关注于图像到图像的转换任务,它采用了条件生成对抗网络(Conditional Generative Adversarial Networks, cGANs)的框架。
在pix2pixHD中提到的组件中,pix2pix最接近于“粗到细的生成器”的概念,但是它并没有直接采用分层或粗到细的方法来生成图像。
相反,pix2pix利用一个单一的生成器(通常是基于U-Net的架构)和一个鉴别器来实现从输入到输出图像的直接映射。
pix2pix的核心贡献是在条件生成对抗网络中引入了配对的训练数据(例如,语义标签图和对应的真实图像),使模型能够学习如何将输入图像转换为输出图像。
它使用传统的GAN损失和L1损失来训练模型,以促进生成图像的真实性和与目标图像的相似度。
将pix2pixHD的组成部分与pix2pix进行对比,pix2pix可以被视为实现了这些高级特性的基础版本,主要集中在通过一个简化的生成对抗网络框架进行图像到图像的转换,而没有涉及到多尺度鉴别器、实例地图的使用或实例级特征嵌入学习等高级特性。
全流程优化
在进行对比分析时,我们将考虑将多尺度鉴别器(如pix2pixHD中使用的)替换为基于自注意力机制的鉴别器(如SAGAN)。
- 自注意力机制(Self-Attention Mechanism)到生成对抗网络GAN
我们从以下几个维度进行详细的对比分析:性能、计算效率、适用性、以及实现复杂度。
性能
- 多尺度鉴别器:通过在不同尺度上评估生成图像,能够有效地捕捉图像的全局结构和局部细节。这种方法在提高生成图像的真实感和细节丰富度方面表现良好,尤其是在高分辨率图像生成中。
- 基于自注意力的鉴别器:自注意力机制允许模型捕获长距离依赖,更灵活地关注图像中的关键特征和细节。这可能会在某些情况下,如细节纹理或复杂模式的识别上,提供更好的性能。
计算效率
- 多尺度鉴别器:虽然引入了多个鉴别器,但每个鉴别器都在较低分辨率的图像上操作,相对节省计算资源。这种设计在保持效率的同时,能够处理高分辨率图像的生成。
- 基于自注意力的鉴别器:自注意力模块增加了额外的计算负担,特别是在处理大尺寸图像时。虽然它提供了更灵活的特征学习能力,但也导致了更高的计算成本和内存需求。
适用性
- 多尺度鉴别器:特别适合于需要细致控制图像的不同尺度(全局结构和局部细节)的真实感的任务,如高分辨率图像合成。
- 基于自注意力的鉴别器:对于需要模型捕获复杂的内部结构和长距离依赖的图像生成任务更为合适,例如生成具有复杂纹理或细节的图像。
实现复杂度
- 多尺度鉴别器:需要设计和训练多个独立的鉴别器网络,但每个网络可以相对简单,因为它们只负责特定尺度的图像。这种方法的设计和优化相对直接。
- 基于自注意力的鉴别器:自注意力机制的引入增加了模型的设计和训练复杂度。需要精心设计自注意力模块以及调整训练策略,以确保模型的学习效率和效果。
结论
多尺度鉴别器在处理高分辨率图像和平衡全局与局部真实感方面具有优势,而基于自注意力的鉴别器则在捕获图像细节和复杂模式上可能更为出色。
假设我们要生成一幅高分辨率的森林景观图像:
-
多尺度鉴别器:能够确保整个森林景观的全局一致性,比如从远处看整个森林的布局和密度分布。同时,它也关注于局部的真实性,比如树木的排列和小路的弯曲。这种方法特别适合于确保生成图像在不同观察尺度下都保持真实感和一致性。
-
基于自注意力的鉴别器(SAGAN):在生成森林景观图像时,自注意力机制能够帮助模型更细致地捕捉到树叶的纹理、树木之间的相互遮挡关系,甚至是远处山峰的轮廓。这种方法在处理图像中的复杂细节和深层结构时更为出色。
综合两种方法的优势,我们可以在生成高分辨率图像的框架中同时使用多尺度鉴别器和基于自注意力的鉴别器:
- 在全局和中尺度层面,使用多尺度鉴别器来确保图像的整体布局和中尺度细节(如森林的整体布局、树木的大致排列)的一致性和真实感。
- 在细节层面,引入基于自注意力的鉴别器(SAGAN),专注于图像的高分辨率细节(如树叶纹理、光影效果),以捕捉和优化这些复杂模式和细节。
通过这种结合,生成的森林景观图像不仅在全局布局和中尺度结构上真实一致,而且在细节纹理和深层结构上也更为精细和丰富。
这种结合策略充分利用了多尺度鉴别器在处理全局一致性和局部真实感方面的优势,以及基于自注意力鉴别器在捕捉细节和复杂模式上的出色能力,实现了在不同层次上优化生成图像的质量和真实感。
-
-
-
- 子特征:实例级特征嵌入学习 (Learning an Instance-level Feature Embedding)
- 子特征:实例地图的使用 (Using Instance Maps)
-
-
-