
【大数据】Flink SQL 语法篇(八):集合、Order By、Limit、TopN



《Flink SQL 语法篇》系列,共包含以下 10 篇文章:
- Flink SQL 语法篇(一):CREATE
- Flink SQL 语法篇(二):WITH、SELECT & WHERE、SELECT DISTINCT
- Flink SQL 语法篇(三):窗口聚合(TUMBLE、HOP、SESSION、CUMULATE)
- Flink SQL 语法篇(四):Group 聚合、Over 聚合
- Flink SQL 语法篇(五):Regular Join、Interval Join
- Flink SQL 语法篇(六):Temporal Join
- Flink SQL 语法篇(七):Lookup Join、Array Expansion、Table Function
- Flink SQL 语法篇(八):集合、Order By、Limit、TopN
- Flink SQL 语法篇(九):Window TopN、Deduplication
- Flink SQL 语法篇(十):EXPLAIN、USE、LOAD、SET、SQL Hints
😊 如果您觉得这篇文章有用 ✔️ 的话,请给博主一个一键三连 🚀🚀🚀 吧 (点赞 🧡、关注 💛、收藏 💚)!!!您的支持 💖💖💖 将激励 🔥 博主输出更多优质内容!!!
Flink SQL 语法篇(八):集合、Order By、Limit、TopN
- 1.集合操作
- 2.Order By、Limit 子句
- 2.1 Order By 子句
- 2.2 Limit 子句
- 3.TopN 子句
1.集合操作
集合操作支持 Batch / Streaming 任务。
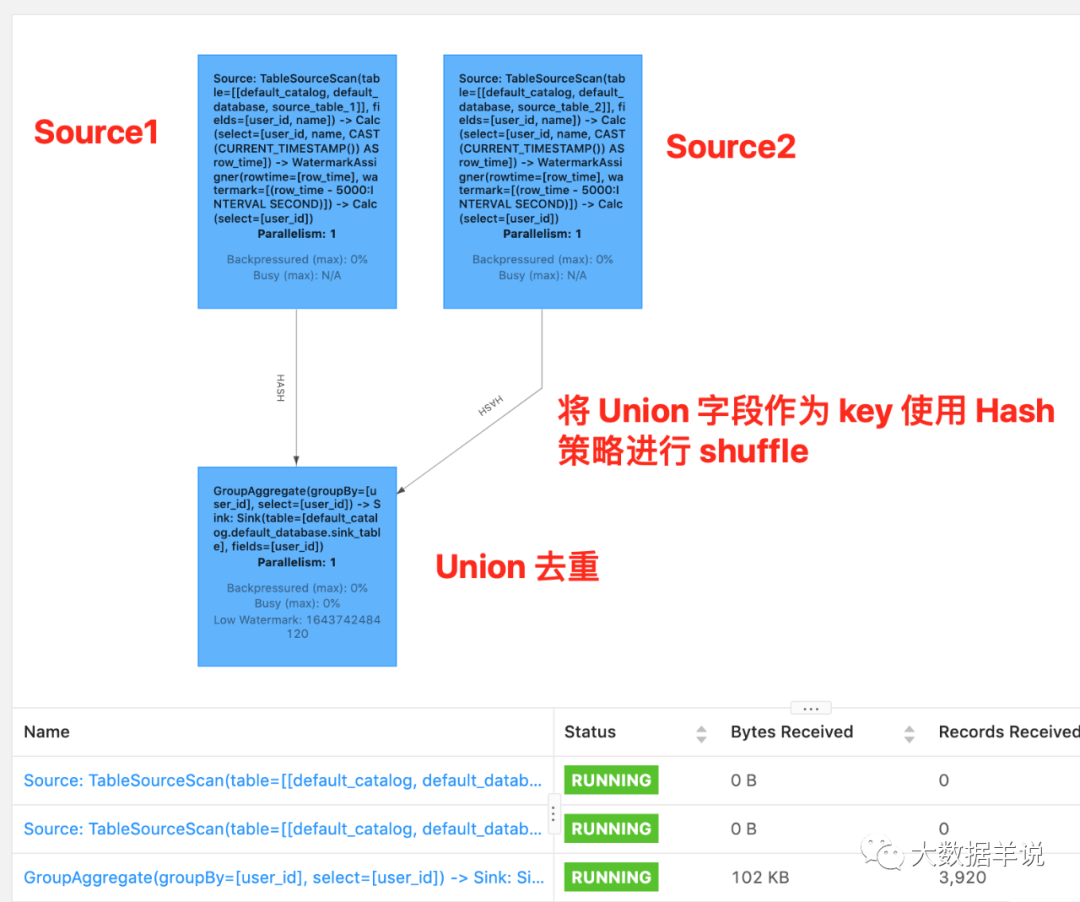
- UNION:将集合合并并且去重。
- UNION ALL:将集合合并,不做去重。
Flink SQL> create view t1(s) as values ('c'), ('a'), ('b'), ('b'), ('c'); Flink SQL> create view t2(s) as values ('d'), ('e'), ('a'), ('b'), ('b'); Flink SQL> (SELECT s FROM t1) UNION (SELECT s FROM t2); +---+ | s| +---+ | c| | a| | b| | d| | e| +---+ Flink SQL> (SELECT s FROM t1) UNION ALL (SELECT s FROM t2); +---+ | c| +---+ | c| | a| | b| | b| | c| | d| | e| | a| | b| | b| +---+- Intersect:交集并且去重。
- Intersect ALL:交集不做去重。
Flink SQL> create view t1(s) as values ('c'), ('a'), ('b'), ('b'), ('c'); Flink SQL> create view t2(s) as values ('d'), ('e'), ('a'), ('b'), ('b'); Flink SQL> (SELECT s FROM t1) INTERSECT (SELECT s FROM t2); +---+ | s| +---+ | a| | b| +---+ Flink SQL> (SELECT s FROM t1) INTERSECT ALL (SELECT s FROM t2); +---+ | s| +---+ | a| | b| | b| +---+- Except:差集并且去重。
- Except ALL:差集不做去重。
Flink SQL> (SELECT s FROM t1) EXCEPT (SELECT s FROM t2); +---+ | s | +---+ | c | +---+ Flink SQL> (SELECT s FROM t1) EXCEPT ALL (SELECT s FROM t2); +---+ | s | +---+ | c | | c | +---+
上述 SQL 在流式任务中,如果一条左流数据先来了,没有从右流集合数据中找到对应的数据时会直接输出,当右流对应数据后续来了之后,会下发回撤流将之前的数据给撤回。这也是一个回撤流。
- In 子查询:这个大家比较熟悉了,但是注意,In 子查询的结果集只能有一列。
SELECT user, amount FROM Orders WHERE product IN ( SELECT product FROM NewProducts )上述 SQL 的 In 子句其实就和之前介绍到的 Inner Join 类似。并且 In 子查询也会涉及到大状态问题,大家注意设置 State 的 TTL。
2.Order By、Limit 子句
2.1 Order By 子句
支持 Batch / Streaming,但在实时任务中一般用的非常少。
实时任务中,Order By 子句中 必须要有时间属性字段,并且时间属性必须为 升序 时间属性,即 WATERMARK FOR rowtime_column AS rowtime_column - INTERVAL '0.001' SECOND 或者 WATERMARK FOR rowtime_column AS rowtime_column。
举例:
CREATE TABLE source_table_1 ( user_id BIGINT NOT NULL, row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)), WATERMARK FOR row_time AS row_time ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '10', 'fields.user_id.min' = '1', 'fields.user_id.max' = '10' ); CREATE TABLE sink_table ( user_id BIGINT ) WITH ( 'connector' = 'print' ); INSERT INTO sink_table SELECT user_id FROM source_table_1 Order By row_time, user_id desc2.2 Limit 子句
支持 Batch / Streaming,但实时场景一般不使用,但是此处依然举一个例子。
CREATE TABLE source_table_1 ( user_id BIGINT NOT NULL, row_time AS cast(CURRENT_TIMESTAMP as timestamp(3)), WATERMARK FOR row_time AS row_time ) WITH ( 'connector' = 'datagen', 'rows-per-second' = '10', 'fields.user_id.min' = '1', 'fields.user_id.max' = '10' ); CREATE TABLE sink_table ( user_id BIGINT ) WITH ( 'connector' = 'print' ); INSERT INTO sink_table SELECT user_id FROM source_table_1 Limit 3结果如下,只有 3 条输出:
+I[5] +I[9] +I[4]
3.TopN 子句
TopN 定义(支持 Batch / Streaming):TopN 其实就是对应到离线数仓中的 row_number(),可以使用 row_number() 对某一个分组的数据进行排序。
应用场景:根据 某个排序 条件,计算 某个分组 下的排行榜数据。
SQL 语法标准:
SELECT [column_list] FROM ( SELECT [column_list], ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]] ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownum FROM table_name) WHERE rownum
- In 子查询:这个大家比较熟悉了,但是注意,In 子查询的结果集只能有一列。
文章版权声明:除非注明,否则均为主机测评原创文章,转载或复制请以超链接形式并注明出处。







