
第十四天-网络爬虫基础



目录
1.什么是爬虫
2.网络协议
OSI七层参考模型
TCP/IP模型
1.应用层
2.传输层
3.网络层
3.HTTP协议
1.介绍
2.http版本:
3.请求格式
4.请求方法
5.HTTP响应
状态码:
6.http如何连接
4.Python requests模块
1.安装
2.使用get/post
3.响应response
4.发送自定义请求头
5.请求超时
7.设置代理
8.ssl证书效验
9.异常
10.demo
1.什么是爬虫
1.爬虫(又被称为网页蜘蛛,网络机器人),是按照一定规则,自动的抓取万维网中的程序或者脚本,是搜索引擎的重要组成;比如:百度、
2.爬虫应用:1.搜索引擎,2.数据分析,3.人工智能,4.薅羊毛(抢车票)
3.常见爬虫产品:神箭手、八爪鱼、造数、后裔采集器
4.什么事是爬虫工程师:我们不生成数据我们是数据的搬运工
5.爬虫工程师的基础
1.python编程基础
2.linux系统操作
3.http协议
4.数据库的增删改查
2.网络协议
1. 协议可以理解为“规则”,是数据传输和数据的解释和规则

OSI七层参考模型


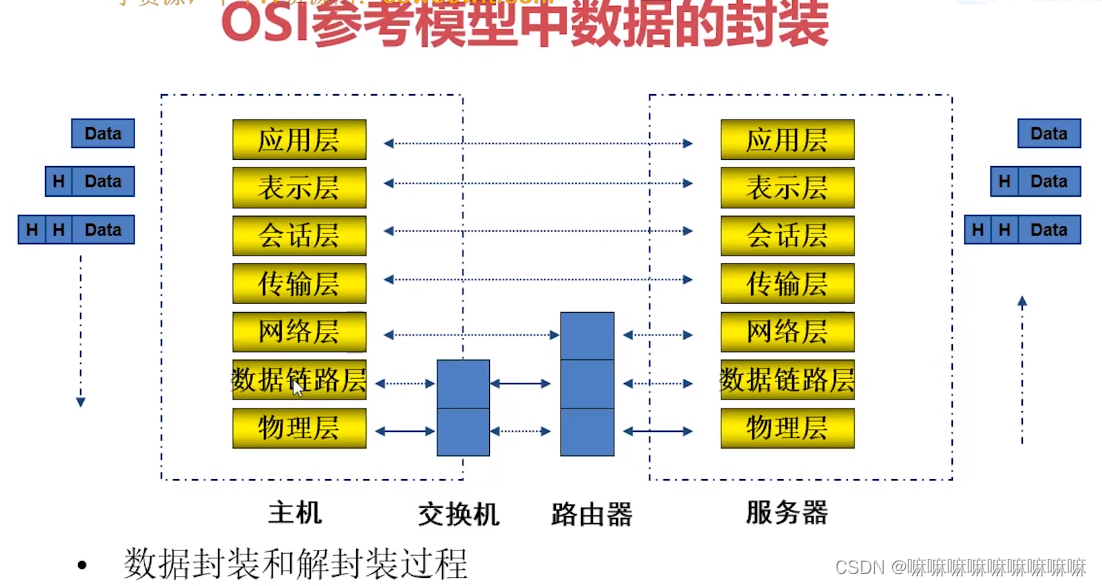
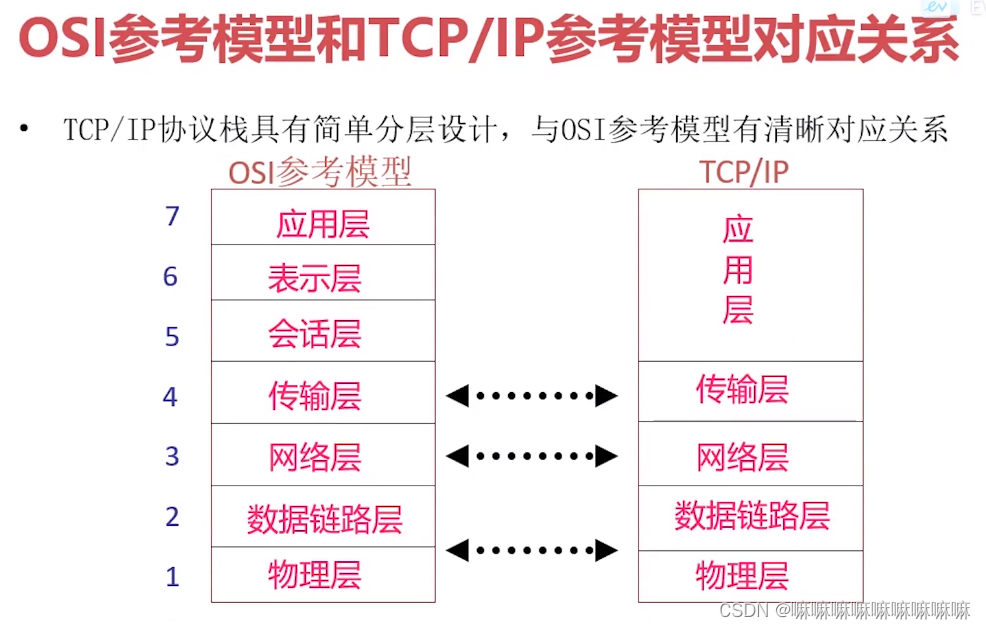
TCP/IP模型
1. 1974年诞生,5层协议

1.应用层
基于tcp和udp
1.http:超文本传输协议,基于tcp,使用80端口号,适用于从www服务器传输超文本到本地浏览器的传输协议
2.SMTP:用于简单的邮件传输协议,基于tcp,使用25端口号,是一组2用于由源地址到目的地传送邮件的规则,用来控制信件的发送,中转。
3.FTP:文件传送协议,基于tcp,一般上传下载用FTP服务,数据端口20,控制端口21
4.telnet:远程登录协议,基于tcp,使用23端口,是internet远程登录服务的标准协议和主要方式。为用户提供了本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用telnet程序链接到服务器。使用明码传送,保密性差,简单方便。
5.dns:域名解析,基于UDP,使用53端口,提供域名到ip之间的转换
6.SSH:安全外壳协议,基于tcp,使用端口22,为建立在应用层和传输层基础上的安全协议,SSH是目前比较可靠,专门为远程登录会话和其他网络服务提供安全性的协议
2.传输层
1. TCP: 传输控制协议,一种面向链接的可靠的,基于字节流的传输层通信协议。
2.UDP:用户数据报协议,一种无链接的通信协议,不可靠,基于报文的传输层通信协议;
3.SCTP: 流量传输控制协议,一种面向连接的流传输协议,是tcp的升级改善tcp的不足
4.MPTCP:多路径传输协议。
3.网络层
1. IP:Internet协议。通过路由选择将下一条ip封装后交给接口层。ip数据报是无连接服务。
2. ICMP:Internet控制报文协议,是网络层的补充。用于在P主机、路由器之间传递控制消息,检测网络通不通,主机是否可达,路由是否可用等网络本身的消息;如:ping ip地址 就是使用本协议
3.ARP: 地址解析协议,是通过目标设备的ip地址,查询目标设备的mac地址,以保证通信的顺利进行;
4.RARP:反向地址解析协议。
3.HTTP协议
1.介绍
HTTP(HyperText Transfer Protocol,超文本传输协议)是互联网上应用最广泛的一种网络协议,他基于TCP的应用层协议,客户端和服务端进行通信的一种规则,他的模式非常简单,就是客户端发起请求,服务器响应请求;
2.http版本:
目前使用最多的是HTTP/1.1

3.请求格式

4.请求方法


5.HTTP响应


状态码:




6.http如何连接
1.dns域名解析
2. 建立链接-tcp三次握手

3.发送http请求
如:post、get请求等
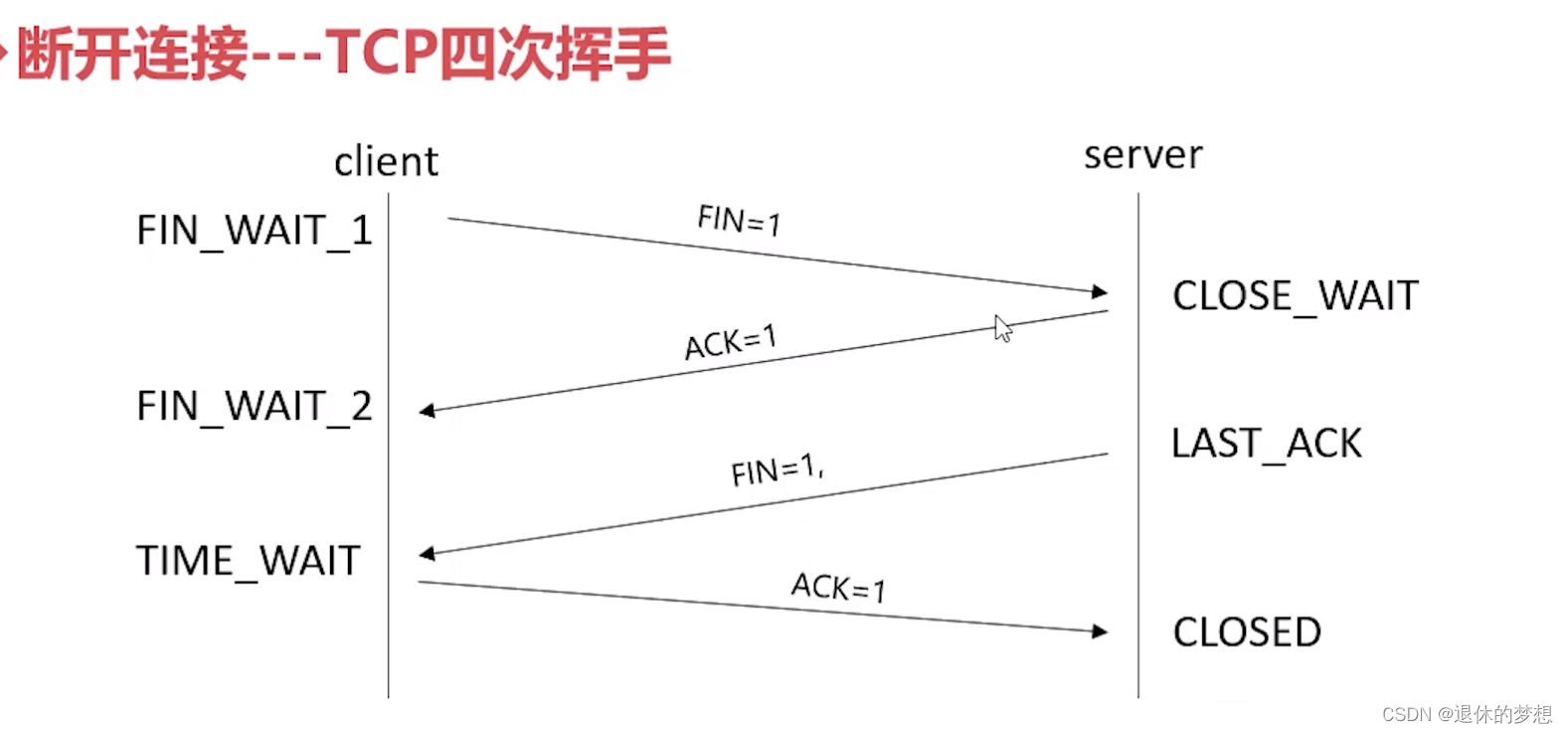
4.断开连接-tcp四次挥手
4.Python requests模块
1. request是一个简单的python HTTP库
2.英文文档:Requests: HTTP for Humans™ — Requests 2.31.0 documentation
1.安装
pip install requests
import requests
2.使用get/post
1. get:
response=requests.get(url="网址")
#构造get 参数 #返回 网址?key=value
data={"key":"value"}
response=requests.get(url="网址",params=data)
print(response.url)
2.post
data={}
response=request.post("网址",data=data)
3.响应response
1. 获取访问头
response.headers
2.获取返回体
response.text
3.获取json
response.json()
4.获取字节码:content
与text两者区别在于,content中间存的是字节码,而text中存的是Beautifulsoup根据猜测的编码方式将content内容编码成字符串
response.content
5.响应状态码:status_code
1. 200:为成功
response.status_code

6.获取请求头
response.request.headers
7.查看cookies
cookies=response.cookies
cookies["获取值"]
4.发送自定义请求头
header={}
resposne.get(url="",headers=header)
5.请求超时
#timeout 默认单位:秒
resposne.get(url="",timeout=0.001)
6.设置cookies
#使用字典构建cookies
cookies=dict(key=value)
response=requests.get(url="网址",cookies=cookies)
7.设置代理
1. 解决封禁ip问题
2.伪装真实IP地址,隐藏请求
3.代理免费的不好用,一般推荐付费代理iP;大家自行寻找
4.ip池和隧道代理的区别

5.使用:
proxy={
"http":"代理地址",
"https":"代理地址"
}
response=requests.get(url="",proxies=proxy)
8.ssl证书效验
1. Requests可以为https请求验证ssl证书,就像web浏览器一样
2.参数verify:默认开启True, ,如ssl验证不通过则会报错
response=requests.get(url="",verify=True)

9.异常


10.demo
1. 下载图片
#下载图片
response_img=requests.get("https://p.qqan.com/up/2024-2/17091001248368361.jpg")
with open("17091001248368361.jpg","wb") as f:
f.write(response_img.content)
2.保存登录凭证
使用requests.session() 自动化记录登录信息
#定义session()
session=requests.session()
#登录
login_response=session.post("登录接口",data=data)
#访问
data_response=session.post("业务页面",data=data)



