
数据结构—基础知识:哈夫曼树
温馨提示:这篇文章已超过429天没有更新,请注意相关的内容是否还可用!
文章目录
- 数据结构—基础知识:哈夫曼树
- 哈夫曼树的基本概念
- 哈夫曼树的构造算法
- 哈夫曼树的构造过程
- 哈夫曼算法的实现
- 算法:构造哈夫曼树
数据结构—基础知识:哈夫曼树
哈夫曼树的基本概念
哈夫曼(Huffman)树又称最优树,是一类带权路径长度最短的树,在实际中有广泛的用途。哈夫曼树的定义,涉及路径、路径长度、权等概念,下面先给出这些概念的定义,然后再介绍哈夫曼树
- 路径:从树中一个结点到另一个结点之间的分支构成这两个结点之间的路径。
- 路径长度:路径上的分支数目称作路径长度。
- 树的路径长度:从树根到每一结点的路径长度之和。
- 权:赋予某个实体的一个量,是对实体的某个或某些属性的数值化描述。在数据结构中,实体有结点(元素)和边(关系)两大类,所以对应有结点权利边权结点权或边权具体代表什么意义,由具体情况决定。如果在一棵树中的结点上带有权值,则对应的就有带权树等概念。
- 结点的带权路径长度:从该结点到树根之间的路径长度与结点上权的乘积。
- 树的带权路径长度:树中所有叶子结点的带权路径长度之和,通常记作WPL。
- 哈夫曼树:设有m个权值{w1,w2,…wm},可以构造一棵含n个叶子结点的二叉树,每个叶子结点的权为w,则其中带权路径长度WPL最小的一叉树称做最优二叉树或哈夫曼树。
例如,下图中所示的3棵二叉树,都含4个叶子结点a、b、c、d,分别带权7、5、2、4,他们的带权路径长度分别为
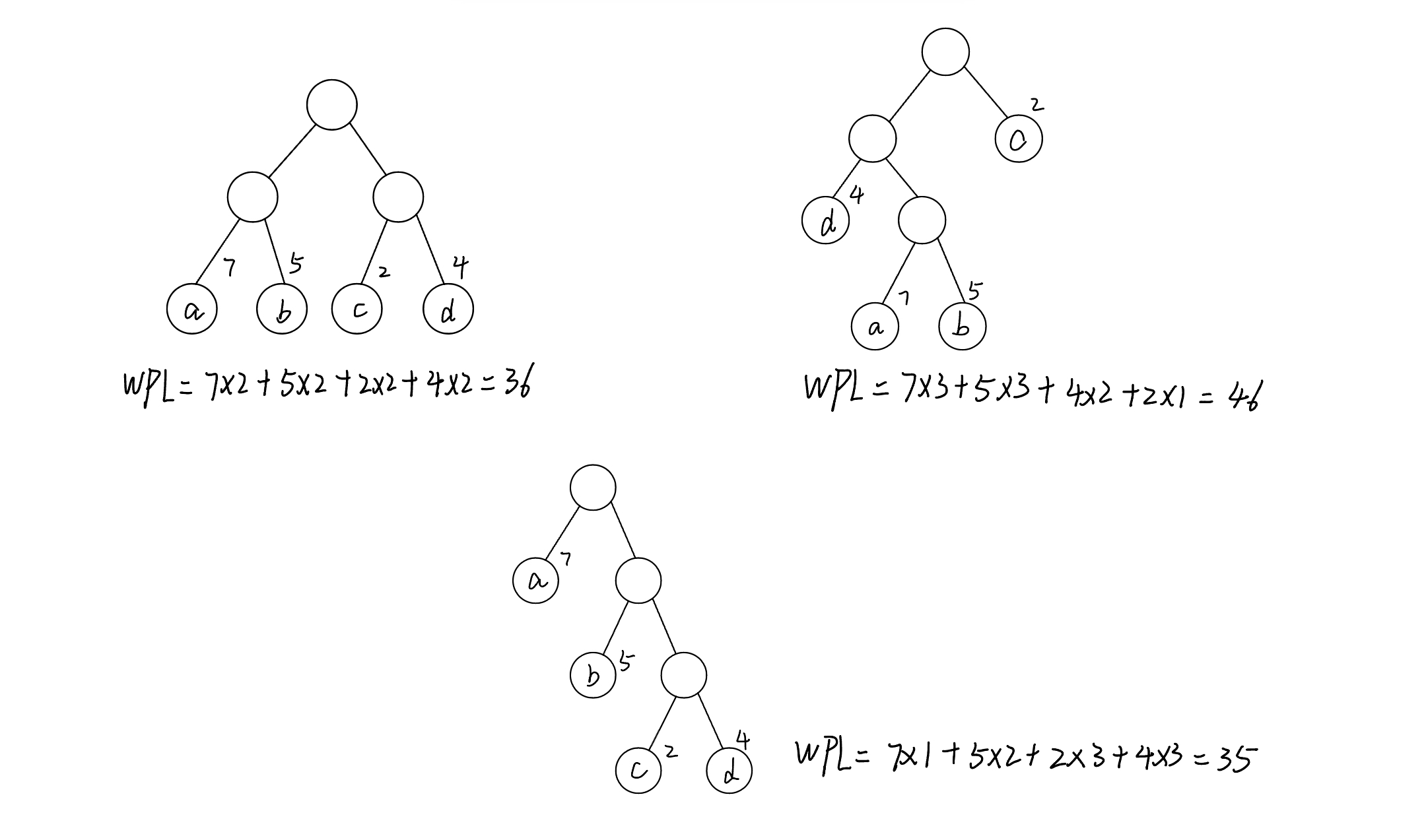
哈夫曼树的构造算法
哈夫曼树的构造过程
- 根据给定的n个权值{w1,w₂,…,wn},构造n棵只有根结点的二叉树,这n棵二叉树构成一个森林F。
- 在森林F中选取两棵根结点的权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根结点的权值为其左、右子树上根结点的权值之和。(选用两小造新树)
- 在森林F中删除这两棵树,同时将新得到的二叉树加人F中。(删除两小添新人)
- 重复(2)和(3),直到F只含一棵树为止。这棵树便是哈夫曼树。(重复(2)(3)剩单根)
在构造哈夫曼树时,首先选择权小的,这样保证权大的离根较近,这样一来,在计算树的带权路径长度时,自然会得到最小带权路径长度,这种生成算法是一种典型的贪心法。
注:哈夫曼树的结点的度数为0或2,没有度为1的结点。
哈夫曼算法的实现
//-------哈夫曼树的存储表示------- typedef struct{ int weight;//结点的权值 int parent,lchild,rchild;//结点的双亲、左孩子、右孩子的下标 }HTNode,*HuffmanTree;//动态分配数组存储哈夫曼树权值 双亲 左孩子 右孩子 weight parent lchild rchild 包含n棵树的森林经过n-1次合并才能形成哈夫曼树,共产生n-1个新结点
算法:构造哈夫曼树
【算法步骤】
- 初始化:首先动态申请2n个单元;然后循环 2n-1次,从1号单元开始,依次将1至2n-1所有单元中的双亲、左孩子、右孩子的下标都初始化为0;最后再循环n次,输入前n个单元中叶子结点的权值。
- 创建树:循环n-1次,通过n-1次的选择、删除与合并来创建哈夫曼树。选择是从当前森林中选择双亲为0且权值最小的两个树根结点s1和 s2;删除是指将结点s1 和s2白的双亲改为非 0;合并就是将s1 和 s2的权值和作为一个新结点的权值依次存入到数组的第n+1之后的单元中,同时记录这个新结点左孩子的下标为s1,右孩子的下标为 s2。
void CreateHuffmanTree(HuffmanTree &HT,int n) { if(n HT[i].parnt=0;HT[i].lchild=0;HT[i].rchild=0; } for(i=1;i//通过n-1次的选择、删除、合并来创建哈夫曼树 Select(HT,i-1,s1,s2); //在HT[k](1≤k≤i-1)中选择两个其双亲域0且权值最小的结点,并返回它们在HT中的序号s1和s2(最小结点下标) HT[s1].parent=i;HT[s2].parent=i;//修改HT[s1][s2]的parent值 HT[i].lchild=s1;HT[i].rchild=s2;//s1,s2分别作为i的左右孩子 HT[i].weight=HT[s1].weight+HT[s2].weight;//i的权值为左右孩子之和 } }
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



