
基于YOLOv8的人脸检测小目标识别算法:Gold-YOLO,信息聚集-分发(Gather-and-Distribute Mechanism)机制 | 华为诺亚NeurIPS23



🚀🚀🚀本文改进:全新的信息聚集-分发(Gather-and-Distribute Mechanism)GD机制,替代YOLOv8 Neck,实现创新
🚀🚀🚀Gold-YOLO在人脸检测小目标识别算法中, mAP@0.5从原始的0.929提升至0.935,mAP50-95从原始的0.43提升至0.435
🚀🚀🚀YOLOv8改进专栏:http://t.csdnimg.cn/hGhVK
学姐带你学习YOLOv8,从入门到创新,轻轻松松搞定科研;
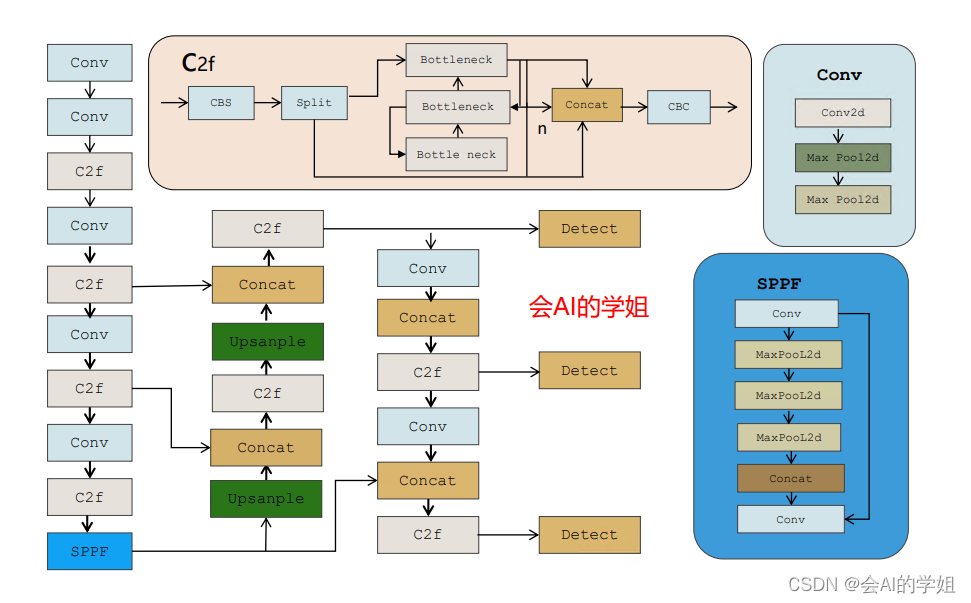
1.人脸识别小目标数据集介绍
数据集来源:GitHub - HCIILAB/SCUT-HEAD-Dataset-Release: SCUT HEAD is a large-scale head detection dataset, including 4405 images labeld with 111251 heads.
本文章主要通过小目标来进行优化,因此数据集只选择partA部分,总共 2000张,按照7:2:1随机进行分配;
下图可以看出都是小目标人脸识别
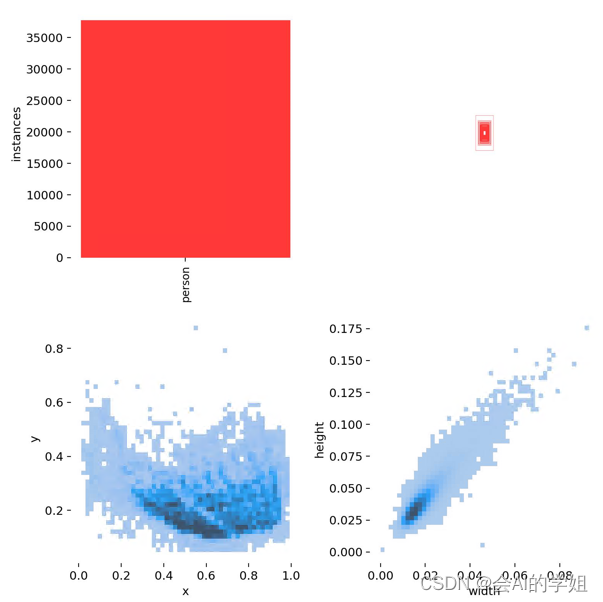

1.1 小目标检测难点
本文所指的小目标是指COCO中定义的像素面积小于32*32 pixels的物体。小目标检测的核心难点有三个:
- 由本身定义导致的rgb信息过少,因而包含的判别性特征特征过少。
- 数据集方面的不平衡。这主要针对COCO而言,COCO中只有51.82%的图片包含小物体,存在严重的图像级不平衡。具体的统计结果见下图。
2.YOLOv8介绍
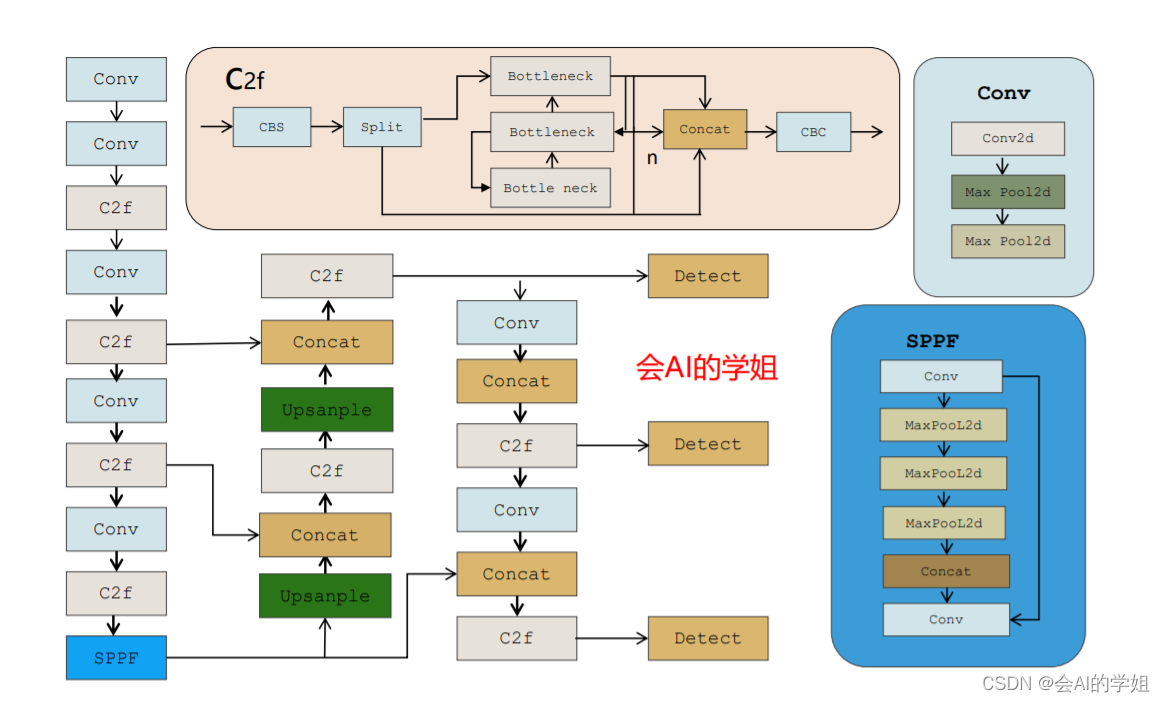
改进点:
- Backbone:使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
- PAN-FPN:毫无疑问YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的卷积结构删除了,同时也将C3模块替换为了C2f模块;
- Decoupled-Head:是不是嗅到了不一样的味道?是的YOLOv8走向了Decoupled-Head;
- YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
- 损失函数:YOLOv8使用VFL Loss作为分类损失,使用DFL Loss+CIOU Loss作为分类损失;
- 样本匹配:YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式。
2.1 C2f模块介绍
C2f模块就是参考了C3模块以及ELAN的思想进行的设计,让YOLOv8可以在保证轻量化的同时获得更加丰富的梯度流信息。
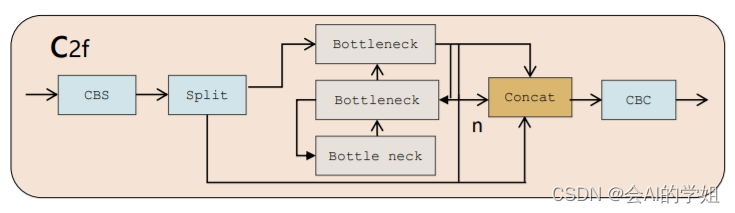
代码:
class C2f(nn.Module): # CSP Bottleneck with 2 convolutions def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion super().__init__() self.c = int(c2 * e) # hidden channels self.cv1 = Conv(c1, 2 * self.c, 1, 1) self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2) self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n)) def forward(self, x): y = list(self.cv1(x).split((self.c, self.c), 1)) y.extend(m(y[-1]) for m in self.m) return self.cv2(torch.cat(y, 1))3.Gold-YOLO

链接:https://arxiv.org/pdf/2309.11331.pdf
代码:https://github.com/huawei-noah/Efficient-Computing/tree/master/Detection/Gold-YOLO
单位:华为诺亚方舟实验室
理论部分可参考:超越YOLO系列!华为提出Gold-YOLO:高效实时目标检测器 - 知乎
传统YOLO的问题
在检测模型中,通常先经过backbone提取得到一系列不同层级的特征,FPN利用了backbone的这一特点,构建了相应的融合结构:不层级的特征包含着不同大小物体的位置信息,虽然这些特征包含的信息不同,但这些特征在相互融合后能够互相弥补彼此缺失的信息,增强每一层级信息的丰富程度,提升网络性能。
原始的FPN结构由于其层层递进的信息融合模式,使得相邻层的信息能够充分融合,但也导致了跨层信息融合存在问题:当跨层的信息进行交互融合时,由于没有直连的交互通路,只能依靠中间层充当“中介”进行融合,导致了一定的信息损失。之前的许多工作中都关注到了这一问题,而解决方案通常是通过添加shortcut增加更多的路径,以增强信息流动。
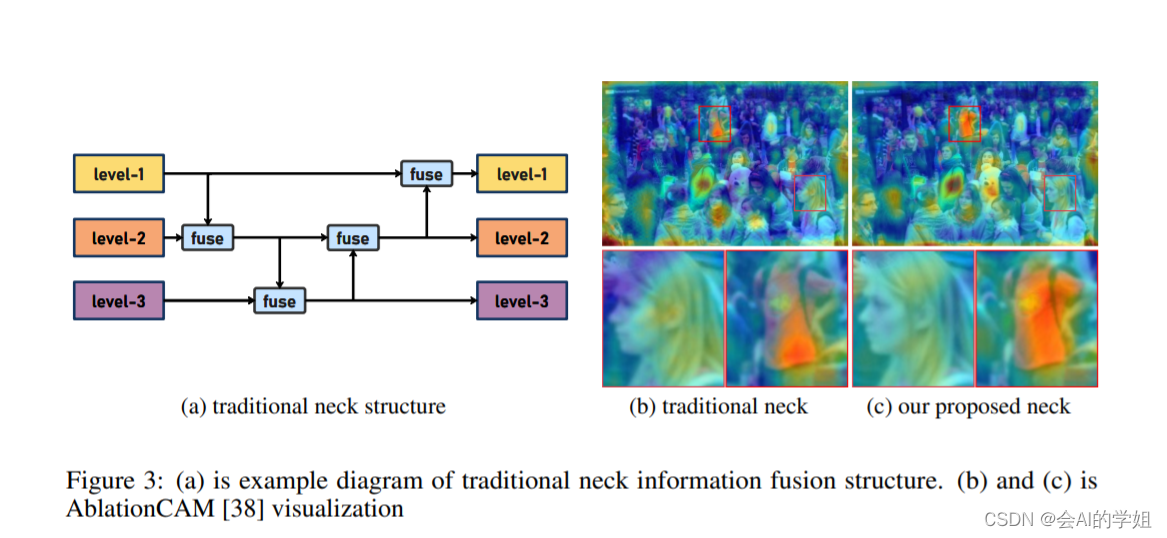
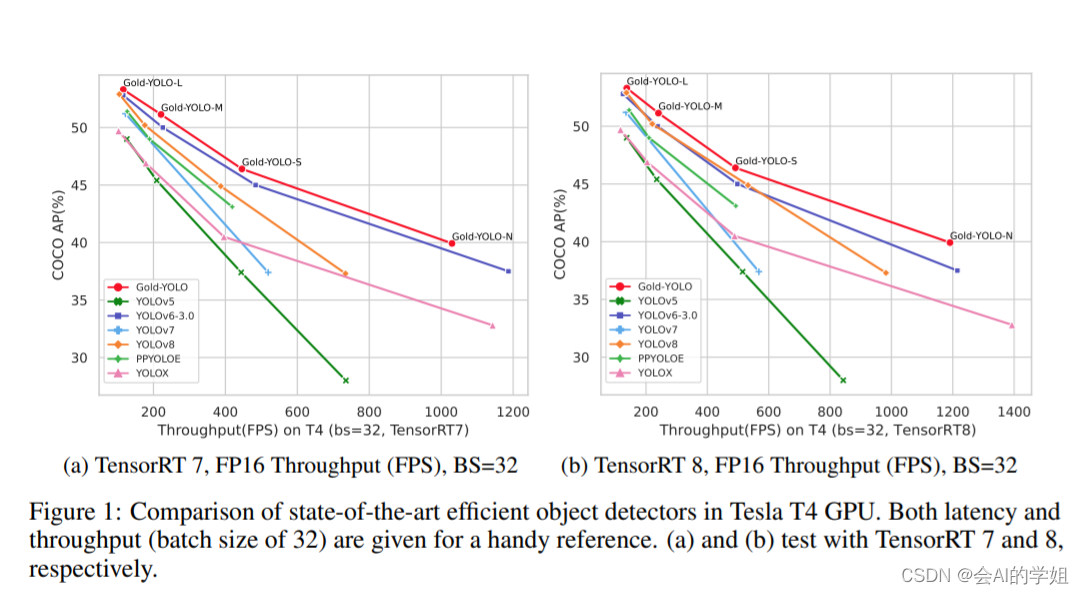
摘要:当前YOLO系列模型通常采用类FPN方法进行信息融合,而这一结构在融合跨层信息时存在信息损失的问题。针对这一问题,我们提出了全新的信息聚集-分发(Gather-and-Distribute Mechanism)GD机制,通过在全局视野上对不同层级的特征进行统一的聚集融合并分发注入到不同层级中,构建更加充分高效的信息交互融合机制,并基于GD机制构建了Gold-YOLO。在COCO数据集中,我们的Gold-YOLO超越了现有的YOLO系列,实现了精度-速度曲线上的SOTA。
提出了一种全新的信息交互融合机制:信息聚集-分发机制(Gather-and-Distribute Mechanism)。该机制通过在全局上融合不同层次的特征得到全局信息,并将全局信息注入到不同层级的特征中,实现了高效的信息交互和融合。在不显著增加延迟的情况下GD机制显著增强了Neck部分的信息融合能力,提高了模型对不同大小物体的检测能力。
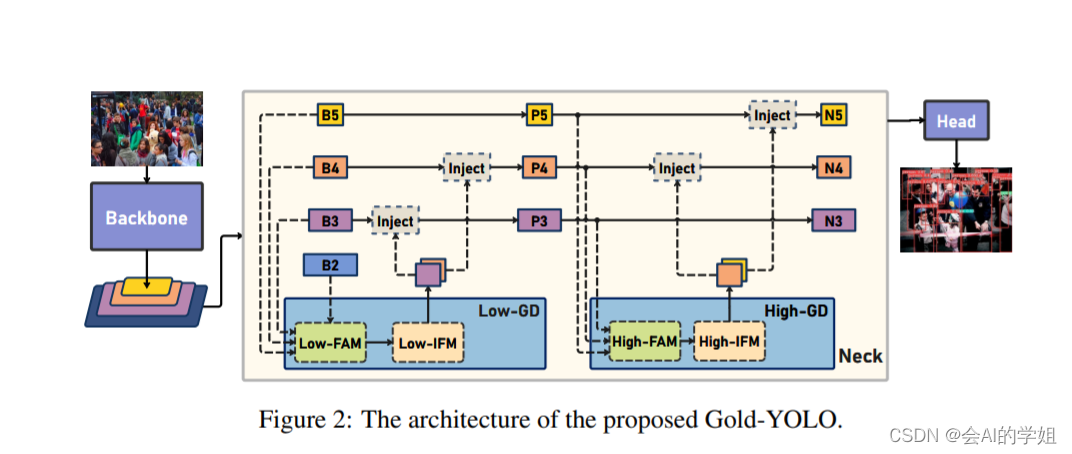
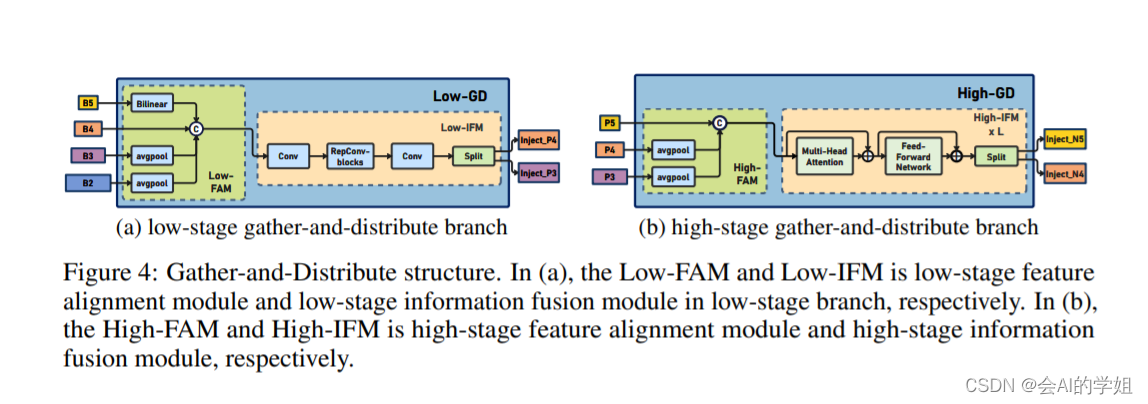
在Gold-YOLO中,针对模型需要检测不同大小的物体的需要,并权衡精度和速度,我们构建了两个GD分支对信息进行融合:低层级信息聚集-分发分支(Low-GD)和高层级信息聚集-分发分支(High-GD),分别基于卷积和transformer提取和融合特征信息。
源码:YOLOv8改进:Neck改进系列 | Gold-YOLO,信息聚集-分发(Gather-and-Distribute Mechanism)机制 | 华为诺亚NeurIPS23-CSDN博客
4.实验结果分析
mAP@0.5从原始的0.929提升至0.935,mAP50-95从原始的0.43提升至0.435
YOLOv8-goldYOLO summary: 359 layers, 6015123 parameters, 0 gradients, 11.9 GFLOPs Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 17/17 [00:28







