
知识图谱最简单的demo实现



一、简介
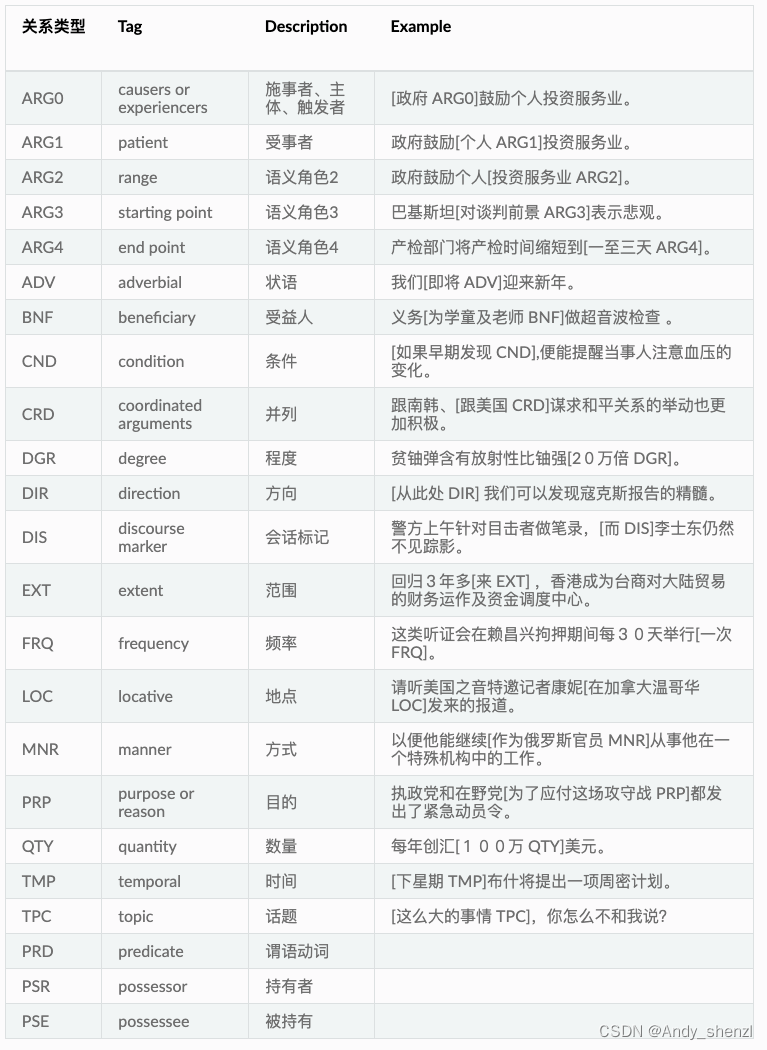
知识图谱整个建立过程可以分为以下几点:
其中:
- 数据预处理:分词、命名实体识别、语义角色识别、句法依存分析等
- 创建三元组:需要根据命名实体识别、语义角色识别结果进行处理,建立规则生成三元组
- 用用图数据库或者接触可视化工具进行展示
二、数据预处理
这里我们使用哈工大的开源工具包LTP进行展示
本文主要介绍整体流程,中间的技术细节,会在后面分章节展开
2.1 数据
我们自己创建一段文本
当然也可以导入文本,或者批量导入csv等格式的数据,为了简便我们使用一段话来展示。
text="苏轼是宋朝的著名文学家,黄庭坚是他的好朋友。苏轼擅长写词,而黄庭坚擅长写诗。他在常州去世。"
2.2 数据处理
LTP支持将全部处理流程进行pipeline执行,当然我们也可以选择分布执行,在后面技术章节会详细展开
# 分词 cws、词性 pos、命名实体标注 ner、语义角色标注 srl、依存句法分析 dep、语义依存分析树 sdp、语义依存分析图 sdpg output = ltp.pipeline(text, tasks=["cws", "pos", "ner", "srl", "dep", "sdp", "sdpg"])
我们把output展开看一下
output
LTPOutput(cws=['苏轼', '是', '宋朝', '的', '著名', '文学家', ',', '黄庭坚', '是', '他', '的', '好', '朋友', '。', '苏轼', '擅长', '写', '词', ',', '而', '黄庭坚', '擅长', '写', '诗', '。', '他', '在', '常州', '去世', '。'], pos=['nh', 'v', 'nt', 'u', 'a', 'n', 'wp', 'nh', 'v', 'r', 'u', 'a', 'n', 'wp', 'nh', 'v', 'v', 'n', 'wp', 'c', 'nh', 'v', 'v', 'n', 'wp', 'r', 'p', 'ns', 'v', 'wp'], ner=[('Nh', '苏轼'), ('Nh', '黄庭坚'), ('Nh', '苏轼'), ('Nh', '黄庭坚'), ('Ns', '常州')], srl=[{'predicate': '是', 'arguments': [('A0', '苏轼'), ('A1', '宋朝的著名文学家')]}, {'predicate': '是', 'arguments': [('A0', '黄庭坚'), ('A1', '他的好朋友')]}, {'predicate': '擅长', 'arguments': [('A0', '苏轼'), ('A1', '写词')]}, {'predicate': '写', 'arguments': [('A1', '词')]}, {'predicate': '擅长', 'arguments': [('A0', '黄庭坚'), ('A1', '写诗')]}, {'predicate': '写', 'arguments': [('A1', '诗')]}, {'predicate': '去世', 'arguments': [('A0', '他'), ('ARGM-LOC', '在常州')]}], dep={'head': [2, 0, 6, 3, 6, 2, 2, 9, 2, 13, 10, 13, 9, 2, 16, 2, 16, 17, 16, 22, 22, 16, 22, 23, 2, 29, 29, 27, 2, 2], 'label': ['SBV', 'HED', 'ATT', 'RAD', 'ATT', 'VOB', 'WP', 'SBV', 'COO', 'ATT', 'RAD', 'ATT', 'VOB', 'WP', 'SBV', 'COO', 'VOB', 'VOB', 'WP', 'ADV', 'SBV', 'COO', 'VOB', 'VOB', 'WP', 'SBV', 'ADV', 'POB', 'COO', 'WP']}, sdp={'head': [2, 0, 6, 3, 6, 2, 2, 9, 2, 13, 10, 13, 9, 9, 16, 9, 16, 17, 16, 22, 22, 16, 22, 23, 22, 29, 28, 29, 22, 29], 'label': ['EXP', 'Root', 'TIME', 'mDEPD', 'FEAT', 'LINK', 'mPUNC', 'EXP', 'eSUCC', 'FEAT', 'mDEPD', 'FEAT', 'LINK', 'mPUNC', 'AGT', 'eSUCC', 'dCONT', 'CONT', 'mPUNC', 'mRELA', 'AGT', 'eCOO', 'dCONT', 'CONT', 'mPUNC', 'EXP', 'mRELA', 'LOC', 'eSUCC', 'mPUNC']}, sdpg=[(1, 2, 'EXP'), (2, 0, 'Root'), (3, 6, 'TIME'), (4, 3, 'mDEPD'), (5, 6, 'FEAT'), (6, 2, 'LINK'), (7, 2, 'mPUNC'), (8, 9, 'EXP'), (8, 10, 'eCOO'), (9, 2, 'eSUCC'), (10, 13, 'FEAT'), (11, 10, 'mDEPD'), (12, 13, 'FEAT'), (13, 9, 'LINK'), (14, 9, 'mPUNC'), (15, 16, 'AGT'), (16, 9, 'eSUCC'), (17, 16, 'dCONT'), (18, 17, 'CONT'), (19, 16, 'mPUNC'), (20, 22, 'mRELA'), (21, 22, 'AGT'), (22, 16, 'eCOO'), (23, 22, 'dCONT'), (24, 23, 'CONT'), (25, 22, 'mPUNC'), (26, 29, 'EXP'), (27, 28, 'mRELA'), (28, 29, 'LOC'), (29, 22, 'eSUCC'), (30, 22, 'mPUNC'), (30, 29, 'mPUNC')])当然,我们也可以使用字典分别返回其结果
# 使用字典格式作为返回结果 print(output.cws) # print(output[0]) / print(output['cws']) # 也可以使用下标访问 print(output.pos) print(output.sdp) print(output.ner) print(output.srl)
我们这里创建知识图谱主要使用命名实体识别和语义角色标注的结果
2.3 实体创建
实体创建主要是命名实体识别的结果
print(output.cws) print(output.ner) ['苏轼', '是', '宋朝', '的', '著名', '文学家', ',', '黄庭坚', '是', '他', '的', '好', '朋友', '。', '苏轼', '擅长', '写', '词', ',', '而', '黄庭坚', '擅长', '写', '诗', '。', '他', '在', '常州', '去世', '。'] [('Nh', '苏轼'), ('Nh', '黄庭坚'), ('Nh', '苏轼'), ('Nh', '黄庭坚'), ('Ns', '常州')]LTP目前可以识别的实体类别主要有三种:
标记 含义 Nh 人名 Ni 机构名 Ns 地名 当然如果是复杂项目的数据,这个明显是不能支持的,后面我们会介绍如果训练自己的命名实体识别模型
从上面的结果我们可以看到,目前识别的结果只有人名和地名
正常来讲,北宋作为时间,应该也需要进行识别
接下来我们创建实体:
def entity_extraction(ner_result): ner_list_Nh=[] ner_list_Ni=[] ner_list_Ns=[] for i in range(len(ner_result)): if output.ner[i][0] == "Nh": ner_list_Nh.append(ner_result[i][1]) elif output.ner[i][0] == "Ni": ner_list_Ni.append(ner_result[i][1]) elif output.ner[i][0] == "Ns": ner_list_Ns.append(ner_result[i][1]) return list(set(ner_list_Nh)),list(set(ner_list_Ni)),list(set(ner_list_Ns))根据不同的识别标签创建三个list,并且用set去重,最后得到实体
ner_list_Nh,ner_list_Ni,ner_list_Ns (['苏轼', '黄庭坚'], [], ['常州'])
最终的实体有三个,两个人名,一个地名
2.4 三元组构建
我们使用角色标注的结果创建三元组
实际情况下,只使用角色标注创建是不行的,需要根据依存句法、语义依存等一起来进行构建,这样会更好的理解上下文和全局
print(output.cws) print(output.srl) ['苏轼', '是', '宋朝', '的', '著名', '文学家', ',', '黄庭坚', '是', '他', '的', '好', '朋友', '。', '苏轼', '擅长', '写', '词', ',', '而', '黄庭坚', '擅长', '写', '诗', '。', '他', '在', '常州', '去世', '。'] [{'predicate': '是', 'arguments': [('A0', '苏轼'), ('A1', '宋朝的著名文学家')]}, {'predicate': '是', 'arguments': [('A0', '黄庭坚'), ('A1', '他的好朋友')]}, {'predicate': '擅长', 'arguments': [('A0', '苏轼'), ('A1', '写词')]}, {'predicate': '写', 'arguments': [('A1', '词')]}, {'predicate': '擅长', 'arguments': [('A0', '黄庭坚'), ('A1', '写诗')]}, {'predicate': '写', 'arguments': [('A1', '诗')]}, {'predicate': '去世', 'arguments': [('A0', '他'), ('ARGM-LOC', '在常州')]}]为了更好的展示,我们分别打印一下
for i in range(len(output.srl)): #if srl[i] print(output.srl[i]){'predicate': '是', 'arguments': [('A0', '苏轼'), ('A1', '宋朝的著名文学家')]} {'predicate': '是', 'arguments': [('A0', '黄庭坚'), ('A1', '他的好朋友')]} {'predicate': '擅长', 'arguments': [('A0', '苏轼'), ('A1', '写词')]} {'predicate': '写', 'arguments': [('A1', '词')]} {'predicate': '擅长', 'arguments': [('A0', '黄庭坚'), ('A1', '写诗')]} {'predicate': '写', 'arguments': [('A1', '诗')]} {'predicate': '去世', 'arguments': [('A0', '他'), ('ARGM-LOC', '在常州')]}语义角色类型可以在LTP官网上查看
我们这里筛选有A0角色的进行创建
从一般的结果看,一般A0会对应到命名实体识别的实体上,当然我个人觉得这里是有优化空间的
kg_list=[] for i in range(len(output.srl)): judge_for_a0=[] for j in range(len(output.srl[i]["arguments"])): judge_for_a0.append(output.srl[i]["arguments"][j][0]) #print((judge_for_a0)) if "A0" in judge_for_a0: index_a0 = judge_for_a0.index("A0") if "A1" in judge_for_a0: index_a1 = judge_for_a0.index("A1") elif "ARGM-LOC" in judge_for_a0: index_a1 = judge_for_a0.index("ARGM-LOC") kg_list.append([output.srl[i]["arguments"][index_a0][1],output.srl[i]["predicate"],output.srl[i]["arguments"][index_a1][1]])生成的结果就是:
[['苏轼', '是', '宋朝的著名文学家'], ['黄庭坚', '是', '他的好朋友'], ['苏轼', '擅长', '写词'], ['黄庭坚', '擅长', '写诗'], ['他', '去世', '在常州']]
2.5 数据整理
- 如果在三元组中的A0没有在实体中的话我们直接去掉;
- 对于三元组中的第三列,我们这里单独将其定义为一类实体为标签
#实体清洗,与ner结果匹配 def kg_list_rule(kg_list,ner_list_Nh): for i in range(len(kg_list)): for j in ner_list_Nh:#如果A0角色,包含ner识别的实体,将其替换为实体名称 if j in kg_list[i][0]: kg_list[i][0]=j for i in range(len(kg_list)):#如果语义角色识别的角色不再ner结果中则删除,此处需要优化 if kg_list[i][0] in ner_list_Nh: continue del kg_list[i] predicate = [] for i in range(len(kg_list)):#提取谓语 predicate.append(kg_list[i][2]) return kg_list,predicate最终结果如下:
([['苏轼', '是', '宋朝的著名文学家'], ['黄庭坚', '是', '他的好朋友'], ['苏轼', '擅长', '写词'], ['黄庭坚', '擅长', '写诗']], ['宋朝的著名文学家', '他的好朋友', '写词', '写诗'])
3、创建图谱–neo4j
目前neo4j应该是最容易使用的图数据库,所以我们使用neo4j进行创建,如果大家不想用图数据库,我们下一节介绍一个工具来进行可视化
3.1 链接neo4j
from py2neo import Node, Graph, Relationship, NodeMatcher graph = Graph("bolt://localhost:7687", user="neo4j", password='1qa2ws3ed', name="demo" )3.2 创建节点
def node_create(ner_list_Nh,ner_list_Ni,ner_list_Ns,predicate): if len(ner_list_Nh)!=0: for i in range(len(ner_list_Nh)): graph.create(Node('人名', name=ner_list_Nh[i])) if len(ner_list_Ni)!=0: for i in range(len(ner_list_Ni)): graph.create(Node('机构名', name=ner_list_Ni[i])) if len(ner_list_Ns)!=0: for i in range(len(ner_list_Ns)): graph.create(Node('地名', name=ner_list_Ns[i])) if len(predicate)!=0: for i in range(len(predicate)): graph.create(Node('标签', name=predicate[i]))将所有实体,包括标签进行创建
3.3 创建边
def relationship_create(kg_list): for m in range(len(kg_list)): try: rel = Relationship(matcher.match("人名").where("_.name=" + "'" + kg_list[m][0] + "'").first(), kg_list[m][1], matcher.match("标签").where("_.name=" + "'" + kg_list[m][2] + "'").first()) graph.create(rel) except AttributeError as e: print(e, m)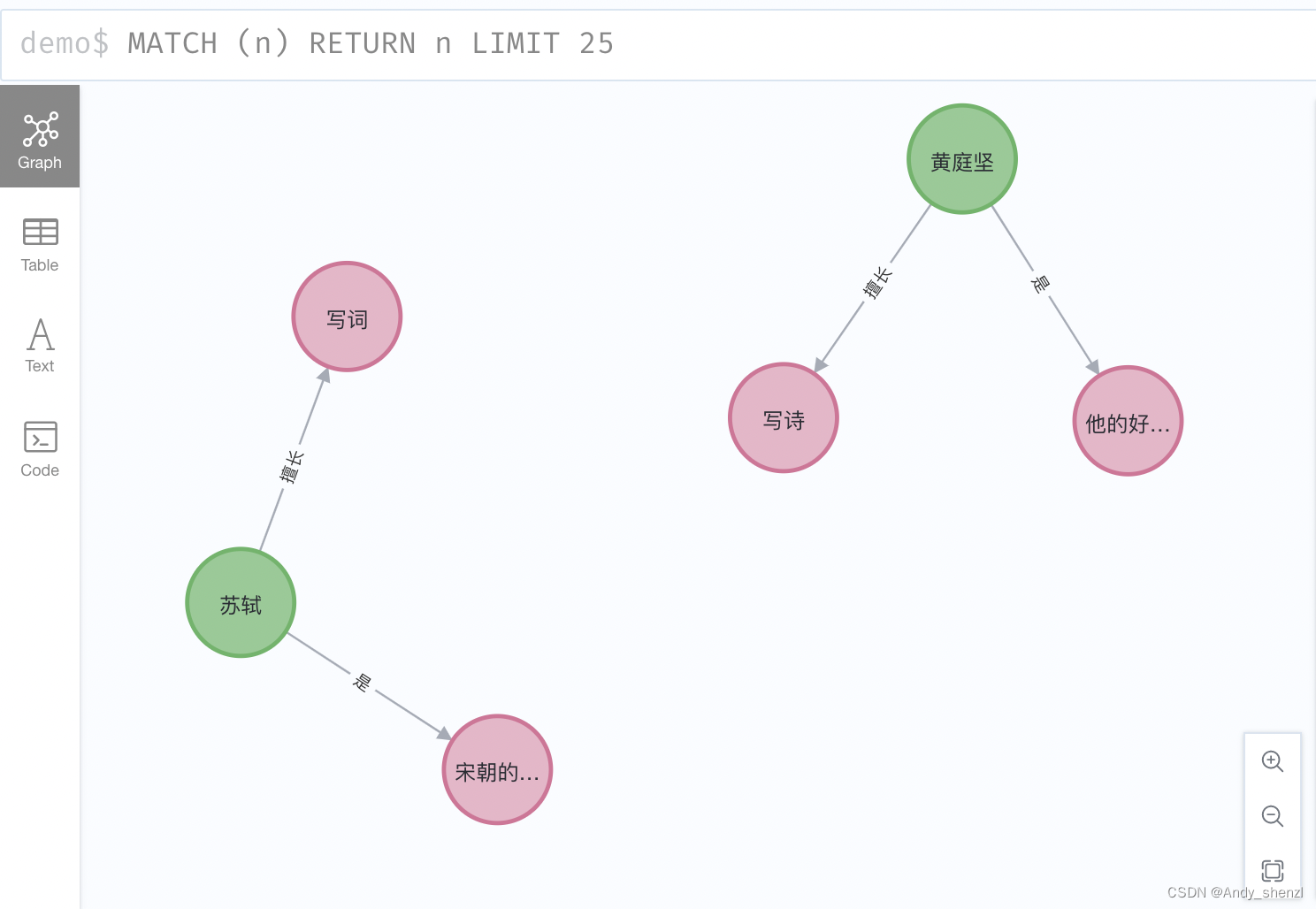
这里可以看到,其实这个结果有点不太理想,就是苏轼和黄庭坚之间没有建立关系,其实这个就是我们前面提到的,只使用语义角色标注创建三元组是不行的,后面我们可以结合其他方法进行优化。







