
特斯拉掀起「端到端」风暴,自动驾驶持续开卷



作者 |三少爷
编辑 |祥威

最近,特斯拉向在美用户推送了版本号为V12.1.2 Beta的端到端FSD,版本推送后,海外的特斯拉车主和视频博主上传了一些测试视频,测评视频本身没有太多好说的,真正值得关注的是「端到端」。
自马斯克首秀基于端到端的FSD以来,自动驾驶行业的从业者以及消费者群体中,有很多人对端到端的自动驾驶解决方案表现出了极大的讨论热情。小鹏、小米汽车等已经开卷「端到端」技术。
那么,到底应该怎么理解特斯拉FSD的端到端呢?
一、理解FSD的端到端
我们可以通过结构、形式、原理、开发范式几个不同的剖面,理解特斯拉FSD的端到端大模型。
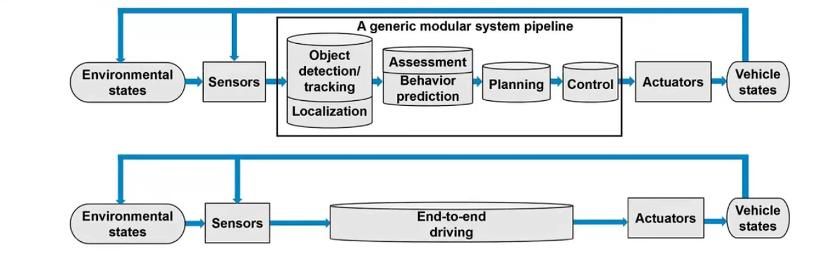
结构上,主流的自动驾驶系统会采取分模块方案,将AD系统按照感知、规划和控制进行划分,先对周围的动静态交通参与者和路网结构进行准确感知,再规划自车的行车轨迹,最后通过执行机构对车辆进行闭环控制。
在分模块方案中,模块与模块之间仿照人类的认知步骤,设计了清晰的接口和界面。
而特斯拉FSD的端到端大模型,则消除了自动驾驶系统的感知和定位、决策和规划、控制和执行之间的断面,将三大模块合在一起,形成了一个大的神经网络。
 (图片来自网络)
(图片来自网络)
形式上,分模块方案的软件采取人工编码和神经网络相结合的形式,且人工编码存在较高的占比,尤其是规控环节,大部分车企还依赖规则驱动、传统算法和手工编码。
相比之下,特斯拉FSD的端到端方案采用全栈神经网络实现,直接输入传感器数据,输出转向、制动和加速信号,全程没有任何编码。
当然,技术的深海里隐藏着很多秘密,FSD端到端的全栈神经网络也许只是一种营销上的说法,并不一定整个自动驾驶软件里不存在任何代码。
毕竟,马斯克在自动驾驶方面向来嘴 都比较大,去年第一次展示端到端FSD时就宣称消除了所有代码(30多万行),但他旁边的助手(听口音是那位印度裔的自动驾驶部门负责人Ashok Elluswamy)提醒道,FSD里头还埋着3000多行C++代码呢!
 (图片来自网络)
(图片来自网络)
从原理层面看,端到端大模型是对海量驾驶视频片段的压缩。
最近,前特斯拉自动驾驶部门负责人Andrej Karpathy做了一期LLM的科普视频,AK表示,本质上,基于大语言模型LLM的生成式GPT是将互联网级别TB或PB级的数据压缩到了GB级别的参数文件里。
类比一下,也可以认为特斯拉端到端的FSD是将上千万个视频片段里包含的人类驾驶知识压缩到了端到端神经网络的参数里。
或许,我们可以从人类自身得到更加贴近的类比。
想想我们的一生,吹过那么多的风,淋过那么多的雨,品尝过一次次的欢笑、泪水、幸福、痛苦,经历过一个又一个难眠的夜晚,人生的经验不也在一次次的经历中被升华、提炼,并最终刻入了脑袋的神经元和突触里了吗?
在开发范式上,全栈神经网络化的FSD是软件2.0时代的产物,完全基于数据驱动。
即,在神经网络层数、结构、权重、参数、激活函数、损失函数固定下来后,训练数据(质量和规模)便成了决定端到端神经网络性能表现的唯一因素。
分模块方案介于软件1.0和2.0之间,除却采用神经网络的那部分,采用人工编码的另一部分依然依赖于设计规则的优劣和传统算法的性能。
到这里,想必大家对端到端已经有了一定的概念。接下来,同样结合结构、形式、原理,开发范式,谈一谈它的优缺点。
二、端到端的优缺点
特斯拉推翻了用在分模块方案下的开发、仿真、测试、迭代手段,重构了工具链,收集并整理了大量训练视频片段,付出了巨大的沉没成本,新增投入了巨大的资源。那么,以逐利为天性的资本家的卓越代表马斯克,到底看上了端到端的什么优点?
 (图片来自广汽研究院)
(图片来自广汽研究院)
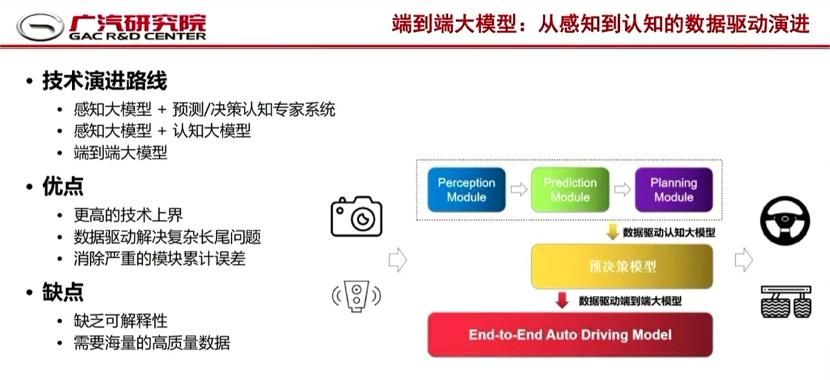
我们可以借用广汽研究院这张PPT,它很好地总结了端到端大模型相较于分模块方案的优缺点。
优点有三:
- 具备更高的技术上界;
- 数据驱动解决复杂长尾问题;
- 消除严重的模块累计误差;
缺点有二:
- 缺乏可解释性;
- 需要海量的高质量数据。
「具备更高的技术上界」是因为可以进行整体优化。端到端的一体化结构方便进行联合优化、寻求整体最优解。
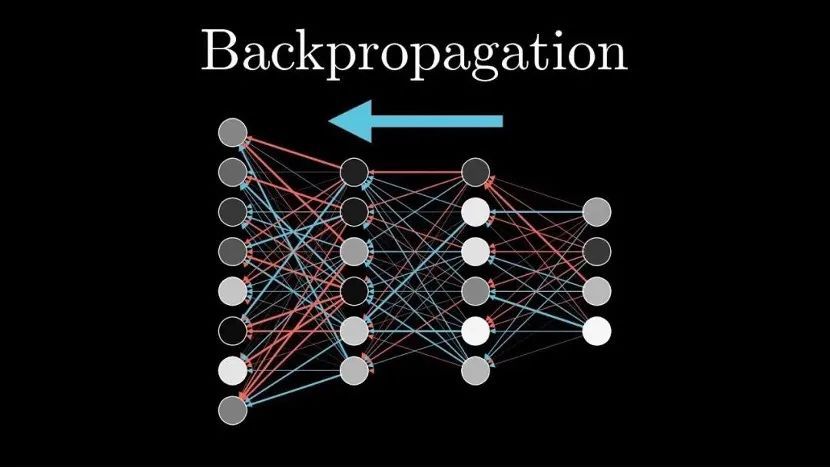
端到端大模型能够服务于整体目标、实现全局最优,和它的全栈神经网络形式息息相关。一个大一统的感知、预测、规划和控制网络,可以使用链式法则无障碍地从输出层(横纵向控制)向输入层(传感器)逐层反向传播误差,以最小化整体损失函数为目标,更加准确地更新每个网络层中的参数。
这显然是分模块自动驾驶方案无法实现的,在分模块方案里,模块与模块之间存在「梯度断开」现象。
看看下面这张图就知道了,想一层层地反向传播,必须保证中间链条不能断,只要神经网络中间有一层出现了中断,反向传播就只能望河兴叹了。
 (图片来自网络)
(图片来自网络)「消除严重的模块累计误差」同样来自于全栈神经网络的贡献。
大家可以把具备多层结构的神经网络的前向传播理解为进行多次函数计算,上一层和下一层之间能否传递全量信息是运算是否准确的关键。
对于分模块方案来说,模块和模块之间无法传递全量信息,导致了「累计误差」,相较之下,全栈神经网络上下层之间可以传递全量信息,从而消除了模块累计误差。
「数据驱动解决复杂长尾问题」这个表述可能会让很多人蒙圈,毕竟,建立数据闭环,以数据驱动覆盖更多的corner case,是过去一两年里国内车企的宣传重点。其实没有矛盾,本土车企着力宣传的BEV、Transformer、占用网络面向的是基于数据驱动的感知,但在规控层面,大部分车企还是基于规则。
和感知一样,规控同样面临长尾问题。
基于规则和数据驱动都是解决复杂长尾问题的方式。算法、算力、数据是驱动人工智能发展的三要素,在这个框架下,可以认为Rule based是「算法驱动」,端到端大模型是「数据驱动」。
与其针对层出不穷的复杂长尾问题,手工编码规控策略,不如设计规控神经网络,通过长尾场景下的训练数据更新模型参数,从理论上来说这是更加一劳永逸的做法。
端到端「缺乏可解释性」确实是客观存在的缺点。不过,不只是FSD端到端,互联网巨头正在搞的GPT和生成式AI的可解释性也非常差,科学家到现在也没有研究明白大模型突现的行为和涌现的能力到底来自哪儿。
GPT和端到端FSD遵循的都是大算力+海量数据的暴力美学,能力来源和机制目前还难以精确地解答。
不过,虽然解释性差,互联网巨头们还是头也不回地加码大模型赛道,消费者们也把它们用出了花。很多事情要知其然知其所以然,端到端和生成式大模型的机制,也许科学家们会在未来给出解答。
「需要海量的高质量数据」与其说是一个缺点,倒不如说是门槛。
在自动驾驶技术的世界,训练算力、数据、AI人才、资金都需要门槛,而在这些要素中,数据是最重要的。
Andrej Karpathy曾经在一次访谈中表示过,特斯拉自动驾驶部门将3/4的精力用在采集、清洗、分类、标注高质量的数据上面,只有1/4的工作用于算法探索和模型创建,这种精力分配,足以说明数据在特斯拉自动驾驶技术栈中的地位。
尤其是端到端这种完全数据驱动的大模型,数据的规模和质量比参数量更能决定模型本身的表现。
三、端到端的训练投入
2023年7月的特斯拉Q2财报电话会议上,马斯克曾经介绍过端到端FSD的训练规模:
「特斯拉花了大约一个季度的时间完成了1000万个视频片段的训练。训练了100万个视频case,勉强可以工作;200万个,稍好一些;300万个,就会感到Wow;到了1000万个,它的表现就变得难以置信了。”
训练视频片段当然不会止步于1000万。
事实上,训练工作是一直源源不断进行的,特斯拉一方面继续收集高质量的视频片段,一方面继续加大训练算力的投入,以提高训练效率、缩短训练时间。
2023年的特斯拉投资者日上,马斯克公开表示,到2025年底,特斯拉会将训练算力推高到100E。和国内厂商1-2E(华为最近的公开数据为2.8E)的训练算力相比,100E是一个相当惊人的数字。
最近这段时间,Dojo负责人离职,大概率会影响「道场」的部署,而且,那么多厂商在抢英伟达的A100/H100,特斯拉未必能如愿买到那么多芯片,所以,特斯拉的训练算力能推高到什么程度,也许比马斯克的预言稍微保守一些(在自动驾驶上,马斯克的预言一向是夸张的)。
即便如此,相比国内厂商,特斯拉的训练算力依然高出一个数量级,这也是为何特斯拉可以训练端到端大模型,而国内车企还停留在「预研」阶段的缘故。
以上讲了端到端和分模块方案的区别、端到端的优缺点和门槛,再说回视频表现,如果不知道FSD采用了端到端,想必本土头部车企会把特斯拉打得找不着东了,或者像少年闰土那样眼里闪着光,将特斯拉当成叉子下的猹一样扎去了。但是一旦冠以了端到端的名义,很多人就像中年的闰土见到鲁迅那样恭恭敬敬地喊起老爷来了。
其实大可不必,笔者看了几个测试视频,端到端FSD并没有在体验上超出国内头部车企,结合与几位行业内人士的交流,大家一致认为特斯拉目前并没有从实践上证明端到端真的100%确定是一个值得追随的路线。
而且,正如前文提到的,端到端的可解释性差,万一也存在天花板呢,目前笃定端到端路线会超过分模块方案还早了一点。
大模型也是这样,周鸿祎最近不还说原以为是个原子弹,现在才发现是个茶叶蛋嘛!
最稳妥的方式是一边预研,一边观察看看FSD一年内的表现和进展,也可以在特斯拉即将举行的AI Day上研究一下端到端大模型的技术细节。
不过,在2023年第四季度财报电话会议上,预测特斯拉将在今年第一季度举办AI Day的分析师问马斯克,可不可以对AI Day抱有期待时,老马直接表示:「我们发现,特斯拉举办AI Day以后,友商们会一帧帧地观摩我们的PPT,所以我们必须小心谨慎地披露我们的秘籍。」
现在就盼着马斯克不要那么小气吧!







