
知识图谱入门



为什么需要知识图谱?什么是知识图谱?
为什么需要知识图谱?什么是知识图谱?——KG的前世今生 - 知乎 (zhihu.com)
计算机一直面临者无法获取网络文本地语义信息。如,假设给机器一个文本信息,机器反应与我们看一个不认识的语言所描述的文本信息一样,简单说就是机器无法理解文本背后的含义。
为了让机器能够理解文本背后的含义,需要对可描述的事务(实体)进行建模,填充它的属性,扩展它和其他事物的联系,也就是构建机器的先验知识。
一、知识从哪里来?
知识库的构建方法:众包、专家协作和互联网挖掘。
众包是通过向大量网络用户提出问题或任务,收集和整理它们的知识经验,从而创建一个共享的知识资源。人工众包是获取高质量知识图谱的重要手段。
专家协作是通过邀请领域内专业人士,共同贡献它们的专业知识,以构建高质量的知识库。适用于领域知识库的构建。
互联网挖掘是通过自动化工具和算法从互联网上的大量数据源中提取和组织信息,构建知识库。
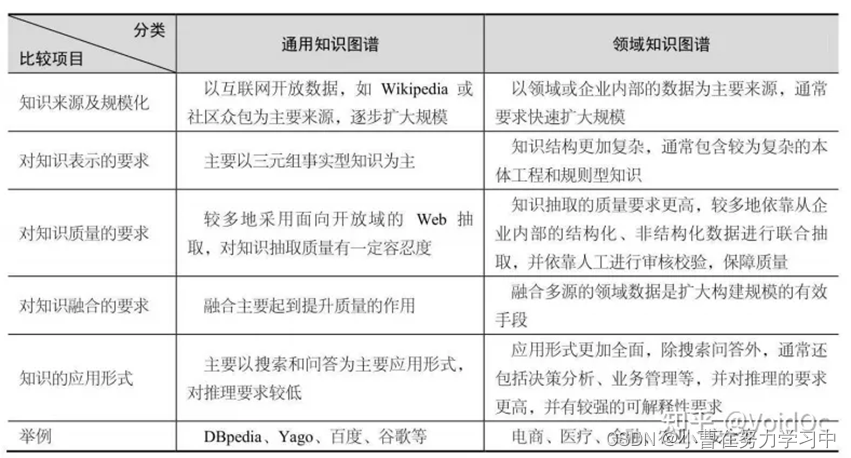
通用知识库和领域知识库的比较:
NELL知识库主要采用互联网挖掘的方法从Web中自动抽取三元组(SPO)知识。NELL的基本理念是:给定一个初始的本体(少量类和关系的定义)和少量样本,让机器能够通过自学习的方式不断地从Web中学习和抽取新的知识。目前,NELL已经抽取了300多万条三元组知识。
三元组是一种基本的知识表示方式,用于表达实体之间关系的信息。
一个三元组由三个部分组成:主语(Subject)、谓语(Predicate)、宾语(Object)。
如:爱好者喜欢电影。
三元组
S:爱好者 P:喜欢 O:电影
知识表示
知识表示是指用计算机符号描述和表示人脑中的知识,以支持机器模拟人的心智进行推理的方法与技术。
早期专家在知识表示采用的方法有:语义网、逻辑描述、一阶谓词逻辑和霍恩子句和霍恩逻辑等。
语义网:由万维网联盟(W3C)推动的一项技术。通过为Web上的信息添加语义标记,使机器能够更好地理解和处理信息。它提倡使用统一的标准和格式,以提高数据地可解释性和互操作性。
逻辑描述、一阶谓词逻辑:在知识表示中,专家们通常使用逻辑描述来刻画显示和离散的知识。一阶谓词逻辑是一种常用的逻辑形式,它允许对对象、关系和属性进行明确的描述,提供了一种形式化的表示方式。
霍恩子句和霍恩逻辑:霍恩子句(Horn Clause)和霍恩逻辑是一种逻辑形式,它强调了逻辑规则的简洁性。霍恩子句具有头部和体部,其中头部是单一的目标,而体部包含了前提条件。这种形式有助于逻辑推理的进行。
虽然上述方法具有可解释性,但也存在一些挑战,如知识不完备性、缺乏鲁棒性等。
常见的知识图谱的知识表示框架
Freebase:主要包含如下几个要素:对象-Object、事实-Facts、类型-Types和属性-Properties。“Object”代表实体。每一个“Object”有唯一的 ID,称为 MID (Machine ID)。一个“Object”可以 有一个或多个“Types”。“Properties”用来描述“Facts”。
Wikidata 的知识表示框架主要包含如下要素:页面-Pages、实体Entities、条目-Items、属性-Properties、陈述-Statements、修饰Qualifiers、引用-Reference 等。
知识抽取、挖掘
知识抽取按任务可以分为实体识别、关系抽取、事件抽取和规则抽取等。
3.1 知识抽取
知识抽取指自动化地从文本中发现和抽取相关信息。
知识抽取的数据源可以分为:结构化数据(如链接数据、数据库)、半结构化数据(如网页中的表格、列表)、非结构化数据(纯文本数据)。
知识抽取步骤:
- NER命名实体识别(实体抽取):从文本中检测命名实体,并将其分类到预定义的类别,如人物、组织、地点、时间等。
- 关系抽取:从文本中识别抽取实体及实体之间的关系。如:句子“[王思聪]是万达集团董事长[王健林]的独子”。在该句子中实体有“王健林”和“王思聪”,它们之间的关系是“父子”关系。
- 事件抽取:识别文本中关于事件的信息,并以结构化的形式呈现。如从恐怖袭击事件的新闻报道中识别袭击发生的地点、时间、袭击目标和受害人等信息。
此外,一些工作中可以通过多任务学习等方法将实体和关系做联合抽取。
在日常生活中,大多数数据以非结构化数据(纯文本)的形式存在,
面向文本数据的知识抽取的主要技术和方法:
3.1.1实体抽取
实体抽取又称命名实体识别,目的是从文本中抽取实体信息元素。想要从文本中进行实体抽取,首先需要从文本中识别和定位实体,然后再将识别的实体分类到预定义的类别中去。
如,给定一个句子“北京时间10月25日,骑士后来居上,在主场以 119∶112击退公牛”。实体抽取目的是为了获取如下图所示的结果。

例句中 的“北京”“10月25日”分别为地点和时间类型的实体,而“骑士”和“公 牛”均为组织实体。
实体抽取总体上可以分为基于规则的方法、基于统计模型的方法和基于深度学习的方法。
- 基于规则的方法
早期采用的人工编写规则的方式,比如正则匹配。一般由具有一定领域知识的专家手工构建。然后,将规则与文本字符串进行匹配,识别命名实体。这种实体抽取方式在小数据集上可以达到很高的准确率和召回率, 但随着数据集的增大,规则集的构建周期变长,并且移植性较差。
-
基于统计模型的方法
基于统计模型的方法需要完全标注或部分标注的语料进行模型训练,主要采用的模型包括隐马尔可夫模型、条件马尔可夫模型、最大熵模型以及条件随机场模型。该类方法将命名实体识别作为序列标注问题处理。与普通的分类问题相比,序列标注问题中当前标签的预测不仅与当前的输入特征相关,还与之前的预测标签相关,即预测标签序列是有相互依赖关系的。从自然文本中识别实体是一个典型的序列标注问题。基于统计模型构建命名实体识别方法主要涉及训练语料标注、特征定义和模型训练三个方面。
训练语料标注
为了构建统计模型的训练语料,人们一般采用 **Inside–Outside–Beginning(IOB)**或 **Inside–Outside(IO)**标注体系对文本进行人工标注。
在IOB标注体系中,文本中的每个词被标记为实体名称的起始词(B),实体名词的后续词(I)或实体名称的外部词(O)。
在IO标注体系中,文本中的词被标记为实体名词内部词(I)或实体名称外部词(O)。如下表给出了IOB和IO实体标注实例。

特征定义
在训练模型之前,统计模型需要计算每个词的一组特征作为模型的输入。这些特征具体包括单词级别特征、词典特征和文档级特征等。
单词级别特征包括是否首字母大写、是否以句点结尾、 是否包含数字、词性、词的 n-gram 等。
词典特征依赖外部词典定义, 例如预定义的词表、地名列表等。
文档级特征基于整个语料文档集计算,例如文档集中的词频、同现词等。
- 基于深度学习的方法
与传统统计模型相比,基于深度学习的方法直接以文本中词的向量为输入,通过神经网络实现端到端的命名实体识别,不再依赖人工定义的特征。
目前, 用于命名实体识别的神经网络主要有卷积神经网络*(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)以及引入注意力机制(Attention Mechanism)的神经网络*。一般地,不同的神经网络结构在命名实体识别过程中扮演编码器的角色,它们基于初始输入以及词的上下文信息,得到每个词的新向量表示;最后再通过CRF模型输出对每个词的标注结果。
条件随机场(CRF)是自然语言处理中的基础模型, 广泛用于分词, 实体识别和词性标注等场景。
3.2 关系抽取
关系抽取是知识抽取的重要子任务之一,面向非结构化文本数据, 关系抽取是从文本中抽取出两个或者多个实体之间的语义关系。关系抽取与实体抽取密切相关,一般在识别出文本中的实体后,再抽取实体之间可能存在的关系,也有很多联合模型同时将这两个任务一起做了的;
关系抽取的几大主要方法:基于模板的关系抽取方法、基于监督学习的关系抽取方法、基于深度学习的方法、基于弱监督学习的关系抽取方法。
基于模板的关系抽取方法
例句:[徐峥]老婆[陶虹]晒新写真。
可以简单将此例句中的实体替换为变量,从而得到如下能够获取“夫妻”关系的模板:
模板1:[X]与妻子[Y]…
模板2:[X]与老婆[Y]…
利用上述模板在文本中进行匹配,可以获得新的具有“夫妻”关系的 实体。 基于模板的关系抽取方法的优点是模板构建简单,可以比较快地在小规模数据集上实现关系抽取系统。同样的,当数据规模较大时,手工构建模板需要耗费领域专家大量的时间。此外,基于模板的关系抽取系统可移植性较差,当面临另一个领域的关系抽取问题时,需要重新构建模板。最后,由于手工构建的模板数量有限,模板覆盖的范围不够,基于模板的关系抽取系统召回率普遍不高。
召回率(Recall)是一个用于评估分类模型性能的指标,特别是在处理正类别(即真实情况为“是”)的情况下。召回率衡量了模型成功识别正例的能力,即在所有真实正例中,模型正确识别的比例。

基于监督学习的关系抽取方法
基于监督学习的关系抽取方法将关系抽取转化为分类问题,在大量标注数据的基础上,训练有监督学习模型进行关系抽取。利用监督学习方法进行关系抽取的一般步骤包括:预定义关系的类型,人工标注数据,涉及关系识别所需的特征(依赖特征工程),一般根据实体所在句子的上下文计算获得;选择分类模型(如支持向量机、神经网络和朴素贝叶斯等),基于标注数据训练模型;对训练的模型进行评估。
基于深度学习的方法
目前,已有的基于深度学习的关系抽取方法主要包括流水线方法和联合抽取方法两大类。
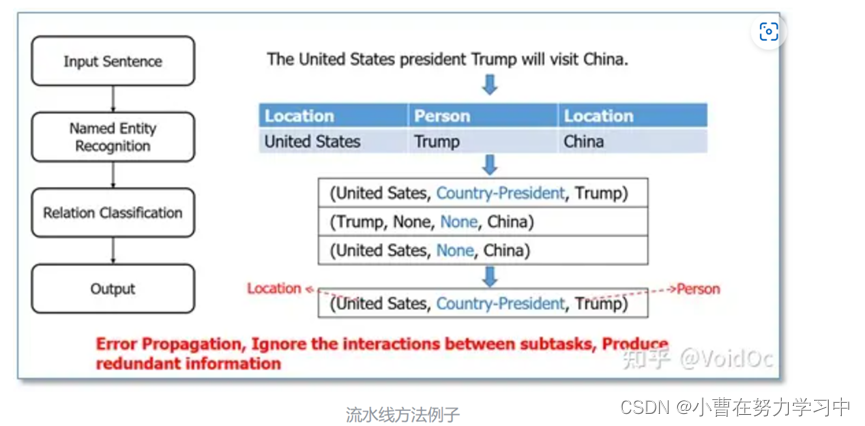
流水线方法将识别实体和关系抽取作为两个分离的过程进行处理,两者不会相互影响;但关系抽取在实体抽取结果的基础上进行,因此关系抽取的结果也依赖于实体抽取的结果,如CR-CNN、Att-Pooling-CNNs、Att-BLTSM。
输入一个句子,首先进行命名实体识别,然后对识别出来的实体进行两两组合,再进行关系分类,最后把存在实体关系的三元组作为输入。
流水线的方法存在的缺点有:
- 错误传播,实体识别模块的错误会影响到下面的关系分类性能;
2)忽视了两个子任务之间存在的关系,例如图中的例子,如果存在Country-President关系,那么我们可以知道前一个实体必然属于Location类型,后一个实体属于Person类型,流水线的方法没法利用这样的信息。
3)产生了没必要的冗余信息,由于对识别出来的实体进行两两配对,然后再进行关系分类,那些没有关系的实体对就会带来多余信息,提升错误率
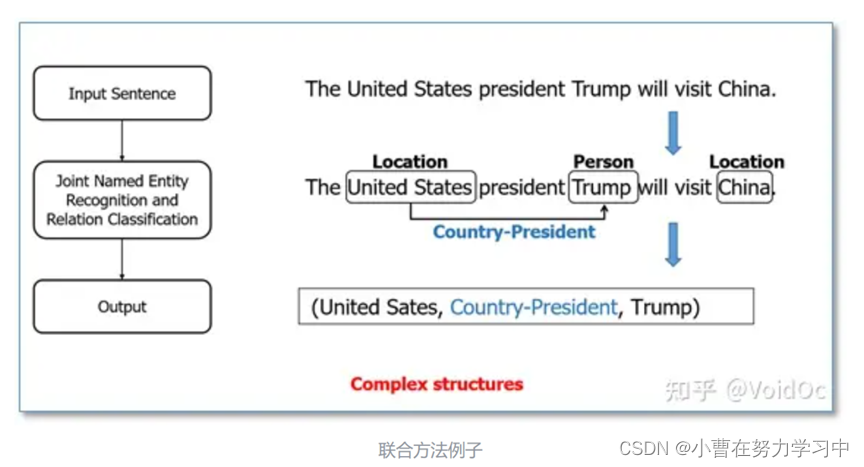
联合抽取方法将实体抽取和关系抽取相结合,输入一个句子,通过实体识别和关系抽取联合模型,直接得到有关系的实体三元组。这种可以克服上面流水线方法的缺点,但是可能会有更复杂的结构,如BERT[8]、LSTM-RNN[9]、DGCNN等。
基于弱监督学习的关系抽取方法
基于监督学习的关系抽取方法需要大量的训练语料,特别是基于深度学习的方法,模型的优化更依赖大量的训练数据。当训练语料不足时,弱监督学习方法可以只利用少量的标注数据进行模型学习。基于弱监督学习的关系抽取方法主要包括远程监督方法和Bootstrapping方法。
远程监督方法
通过将知识图谱与非结构化文本对齐的方式自动构建大量的训练数据,减少模型对人工标注数据的依赖,增强模型的跨领域适应能力。远程监督方法的基本假设是如果两个实体在知识图谱中存在某种关系,则包含两个实体的句子均表达了这种关系。
例如,在某知识图谱中存在实体关系创始人(乔布斯,苹果公司),则包含实体乔布斯和苹果公司的句子“乔布斯是苹果公司的联合 创始人和 CEO”则可被用作关系创始人的训练正例。
远程监督关系抽取方法的一般步骤为:
- 从知识图谱中抽取存在目标关系的实体对;
- 从非结构化文本中抽取含有实体对的句子作为训练样例;
- 训练监督学习模型进行关系抽取。
关于远程监督学习比较好的论文有2017年提出的PCNNS(Piecewise Convolutional Neural Networks),针对噪声处理,于2018提出的基于强化学习的CNN-RL[11]等。
Bootstrapping 方法起源于统计学中的自主抽样方法,它利用少量的实例作为初始种子集合,然后在种子集合上学习获得关系抽取的模板,再利用模板抽取更多的实例,加入种子集合中。通过不断地迭代,Bootstrapping 方法可以从文本中抽取关系的大量实例。
有很多实体关系抽取系统都采用了Bootstrapping方法, 如DIPER, Snowball和NELL,但都比较老了。 Bootstrapping 方法的优点是关系抽取系统构建成本低,适合大规模的关系抽取任务,并且具备发现新关系的能力。但对初始种子较为敏感、存在语义漂移问题、结果准确率较低等因素也使得Bootstrapping 方法逐渐淡出人们的视野。
3.3 事件抽取
事件抽取是指从自然语言文本中抽取出用户感兴趣的事件信息,并以结构化的形式呈现出来,例如事件发生的时间、地点、发生原因、参与者等。跟关系抽取有重叠的地方,同样也可以分为流水线方法和联合抽取方法。
3.4 知识挖掘介绍
知识挖掘是从已有的实体及实体关系出发挖掘新的知识,具体包括知识内容挖掘和知识结构挖掘。
内容挖掘包括实体链接(同义词发现、消歧)等相关技术。
知识结构挖掘包括规则挖掘技术。
3.4.1规则挖掘
归纳逻辑程序设计(Inductive Logic Programming,ILP)一阶逻辑归纳为理论基础,并以一阶逻辑为表达语言的符号规则学习算法[。知识图谱中的实体关系可看作是二元谓词描述的事实。
通过ILP方法从知识图谱中学习一阶逻辑规则。 给定背景知识和目标谓词(知识图谱中即为关系), ILP 系统可以学习获得描述目标谓词的逻辑规则集合。
3.5 总结
知识抽取是构建大规模知识图谱的重要环节,而知识挖掘则是在已有知识图谱的基础上发现其隐藏的知识。知识抽取和知识挖掘技术于NLP领域也有许多共同之处,业界每年有非常多(通用/专业领域的)知识抽取任务的相关竞赛如百度的语言与智能技术竞赛、CCKS 还有国外的MUC(Message Understanding Conference), ACE((Automatic Content Extraction), SemEval等。
知识存储
和传统数据一样,知识也需要数据库来进行存放与管理工作。由于传统关系数据库无法有效适应知识图谱的图数据模型, 知识图谱领域形成了负责存储RDF图(RDF graph)数据的三元组库(Triple Store),和管理属性图(Property Graph)的图数据库(Graph Database)。
4.1 RDF图
在 RDF 三元组集合中,每个 Web 资源具有一个 HTTP URI 作为其唯一的 id;一个 RDF图定义为三元组(s, p, o)的有限集合;每个三元组代表一个陈述句,其中s是主语,p是谓语,o是宾语; (s, p, o)表示资源s与资源o之间具有联系p,或表示资源s具有属性p且其 取值为o。实际上,RDF三元组集合即为图中的有向边集合。
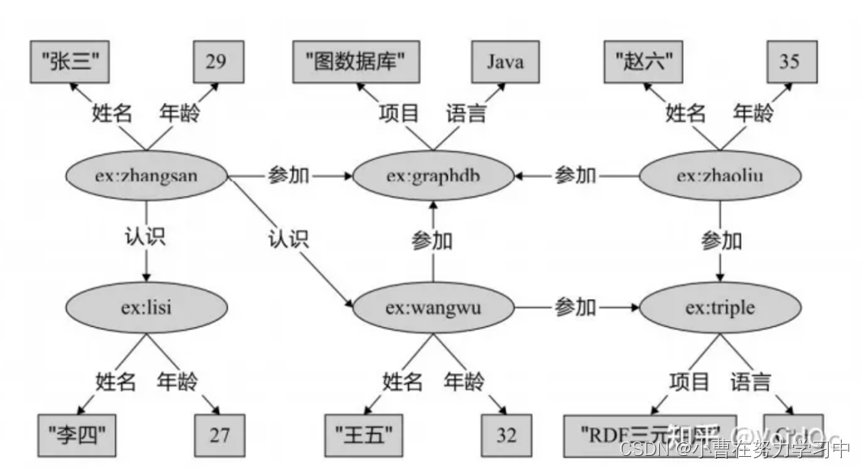
RDF 图对于节点和边上的属性没有内置的支持。节点属性可用三元组表示,这类三元组的宾语称为字面量,即图中的矩形。边上的属性表示起来稍显烦琐,最常见的是利用 RDF 中一种叫 作“具体化”(reification)的技术[13],需要引入额外的点表示整个三元组,将边属性表示为以该节点为主语的三元组。例如在图3-2中,引入节点ex:participate 代表三元组(ex:zhangsan, 参加, ex:graphdb),该节点通过 RDF 内置属性rdf:subject、rdf:predicate 和 rdf:object 分别与代表 的三元组的主语、谓语和宾语建立起联系,这样三元组(ex:participate, 权重, 0.4)就实现了为原三元组增加边属性的效果。
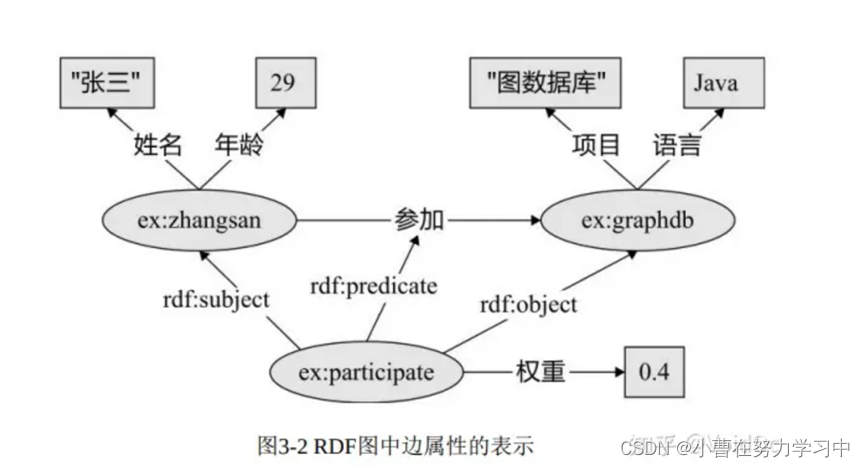
4.2 属性图
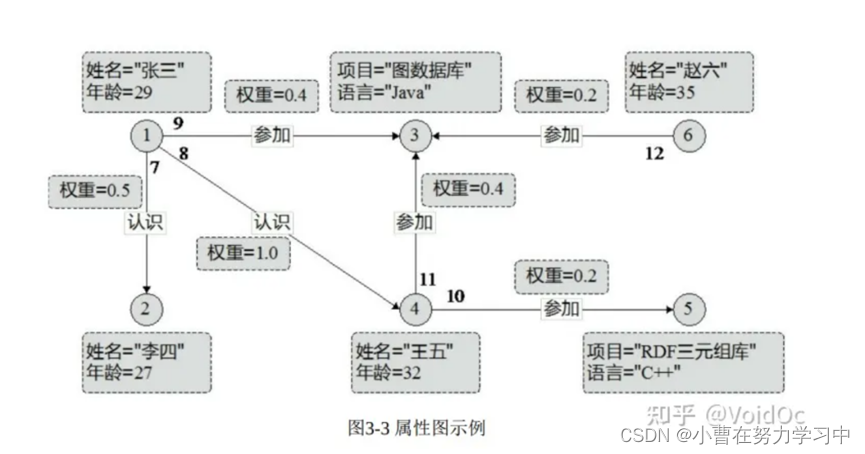
属性图是目前被图数据库应用最广的一种图数据模型。由节点集和边集组成,且满足以下性质:
(1)每个节点具有唯一的id;
(2)每个节点具有若干条出边;
(3)每个节点具有若干条入边;
(4)每个节点具有一组属性,每个属性是一个键值对;
(5)每条边具有唯一的id;
(6)每条边具有一个头节点;
(7)每条边具有一个尾节点;
(8)每条边具有一个标签,表示联系;
(9)每条边具有一组属性,每个属性是一个键值对。
知识图谱查询语言可分为声明式和导航式两类。
图数据库上的声明式查询语言有: Cypher、PGQL 和 G-Core。
Cypher 是开源图数据库 Neo4j 中实现的图查询语言。PGQL 是 Oracle 公司开发的图查询语言。G-Core是由 LDBC(Linked Data Benchmarks Council)组织设计的图查询语言。
4.3 常见的知识图谱存储方法
基于三元组库和图数据库能够提供的知识图谱数据存储方案可分为三类:
- 基于关系数据库的存储方案:包括三元组表、水平表、属性表、垂直划分、六重索引和DB2RDF等。
- 三元组(SPO)表是将知识图谱中的每条三元组存储为一行具有三列的记录 (主语,谓语,宾语)。三元组表存储方案虽然简单明了,但三元组表的行数与知识图谱的边数一样,其问题是将知识图谱查询翻译为SQL后会产生大量三元组表的自连接操作,影响效率。

-
水平表存储方案的每行记录存储知识图谱中一个主语的所有谓语和宾语,相当于知识图谱的邻接表。但其缺点在于所需列数目过多,表中产生大量空值,无法存储多值宾语等。
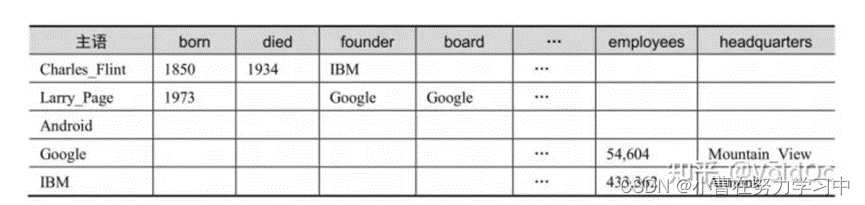
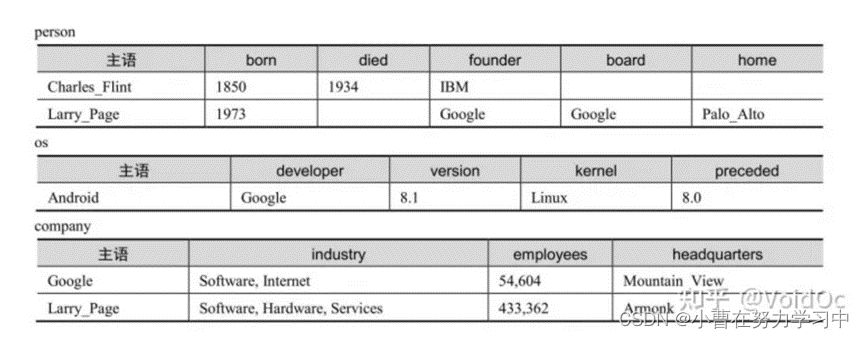
-
属性表存储方案将同一类主语分配到一个表中,是对水平表存储方案的细化。属性表解决了三元组表的自连接问题和水平表的列数目过多问题。但对于真实大规模知识图谱,属性表的问题包括:所需属性表过多,复杂查询的多表连接效率,空值问题和多值宾语问题。
4.垂直划分存储方案为知识图谱中的每种谓语建立一张两列的表(主语,宾语),表中存放由该谓语连接的主语和宾语,支持“主语-主语”作为连接条件的查询操作的快速执行。垂直划分有效解决了空值问题和多值宾语问题;但其仍有缺点,包括:大规模知识图谱的谓语表数目过多、复杂查询表连接过多、更新维护代价大等。
(2)面向 RDF 的三元组数据库:主要的 RDF 三元组库包括:商用的 Virtuoso、AllegroGraph、GraphDB和BlazeGraph,开源系统Jena、RDF4J、 RDF-3X和gStore。
(3)原生图数据库:主要包括开源的Neo4j、Nebula(国内自研)、JanusGraph和商用的OrientDB等。
知识融合
在构建知识图谱时,可以从第三方知识库产品或已有结构化数据中获取知识输入。
当多个知识图谱进行融合,或者将外部关系数据库合并到本体知识库时,需要处理两个层面的问题:
模式层的融合,将新得到的本体融入已有的本体库中,以及新旧本体的融合;
数据层的融合,包括实体的指称、属性、关系以及所属类别等,主要的问题是如何避免实例以及关系的冲突问题,造成不必要的冗余。
数据层的融合是指实体和关系(包括属性)元组的融合,主要是实体对齐,由于知识库中有些实体含义相同但是具有不同的标识符,因此需要对这些实体进行合并处理。此外,还需要对新增实体和关系进行验证和评估,以确保知识图谱的内容一致性和准确性,通常采用的方法是在评估过程中为新加入的知识赋予可信度值,据此进行知识的过滤和融合。
实体对齐的任务包括实体消歧(Disambiguation)、实体统一(Entity Resolution)和指代消解(Co-reference Resolution):实体消歧的本质是在于一个词很有可能有多个意思,比如“苹果”可以指水果也可以指Apple Inc. 结合上下文需要做出表征的分类,通常采用聚类方法;实体统一的本质是判断多个不同的词是否指向统一实体;指代消解就是搞明白文本里的she,he,it到底指代的什么,给出超链接关联到对应指代的实体。
实体对齐任务不单在知识融合过程中被涉及,其实在知识表示的过程中就会去做相应工作。因为实体增量也是图谱融合(自身融合自身)的一种形式。
六、知识推理
推理是指基于已知的事实或知识推断得出未知的事实或知识的过程。传统的推理包括演绎推理(Deductive Reasoning)、归纳推理 (Inductive Reasoning)等。而面向知识图谱的推理主要围绕关系(链接)的推理展开,即基于图谱中已有的事实或关系推断出未知的事实或关系,一般着重考察实体、关系和 图谱结构三个方面的特征信息。
知识图谱推在知识图谱中,推理主要用于对知识图谱进行补全(Knowledge Base Completion,KBC)和知识图谱质量的校验。 知识图谱中的知识可分为概念层和实体层。知识图谱推理的任务是根据知识图谱中已有的知识推理出新的知识或识别出错误的知识。其中,概念层的推理主要包括概念之间的包含关系推理,实体层的推理主要包括链接预测与冲突检测,实体层与概念层之间的推理主要包括实例检测。理主要能够辅助推理出新的事实、新的关系、新的公理以及新的规则等。
面向知识图谱的推理方法主要分为基于逻辑规则的推理、基于分布式表示的推理、基于图的推理、基于神经网络的推理以及混合推理。
七、应用
KBQA问答
搜索引擎+推荐算法
逻辑决策辅助
关联挖掘+根因分析







