
基于python 面向豆瓣电影的知识图谱的设计与实现。该设计是一个集爬虫、GUI、多线程、知识图谱、NLP 基础文本分析的多功能应用 附完整代码 毕业设计



摘要:
本文介绍了 python 面向豆瓣电影的知识图谱的设计与实现。该设计是一个集爬虫、GUI、多线程、知识图谱、NLP 基础文本分析的多功能应用。本文介绍了用面向对象软件工程方法对其进行分析、设计、编码、测试的过程,以及对设计的评估。并提供了相关文档及部分源代码。
关键字:
软件工程,面向对象,爬虫,知识图谱,文本分析
个人的工作及体会在“六.小结”部分
项目概述
该软件技术课程设计目的在于将所学的专业技能转化为实践的能力。学会快速获取和处理海量的数据并从中得到有价值的信息是信息时代的一项重要技能。通过完成本课程设计,将加深对网络爬虫、数据挖掘及软件编程技术的理解,同时锻炼其软件编程与解决实际问题的能力。
本课设通过爬取豆瓣 top250 电影排行榜的信息,利用 neo4j 实现豆瓣 top250 电影的信息可视化,同时自行拓展完成一些附加功能。
考虑到脚本的实时操作性,本项目主要采用面向对象的思想并且采用多线程并发的方法进行程序设计,以满足以上功能的实时性与并发性,从而有较流畅的 GUI 可视化界面操作。
完整代码:https://download.csdn.net/download/qq_38735017/87430482
项目设计
需求分析
第一,从用户的角度来看,此项目需要提供一个可视化的图形用户界面以方便用户根据界面按钮与说明书文档进行操作,并且该程序应该可以根据用户的需求从互联网上进行搜集与爬取,将相关内容最终返回到图形用户界面,即完成程序与用户的交互;
第二,从爬虫开发者角度考虑,程序应该可以进行网页爬虫和资源下载,这里使用 request 库可以实现,但也要从开发者的角度考虑频繁访问页面时的代理池的问题;另一方面,由于爬取数据较多,应该可以实现多线程或者多进程并发进行,达到高效率;
第三, 从数据库开发角度考虑,数据库应该可以在导入数据后进行数据节点与关系的建立;
第四,爬取的数据除了具有关系之外,也可以对文本进行一定的分析,比如词频统计、情感分析等 NLP 的基础内容,对文本数据做出数据分析并且图形显示,实现可视化。
下面从用户的角度具体分析需求:
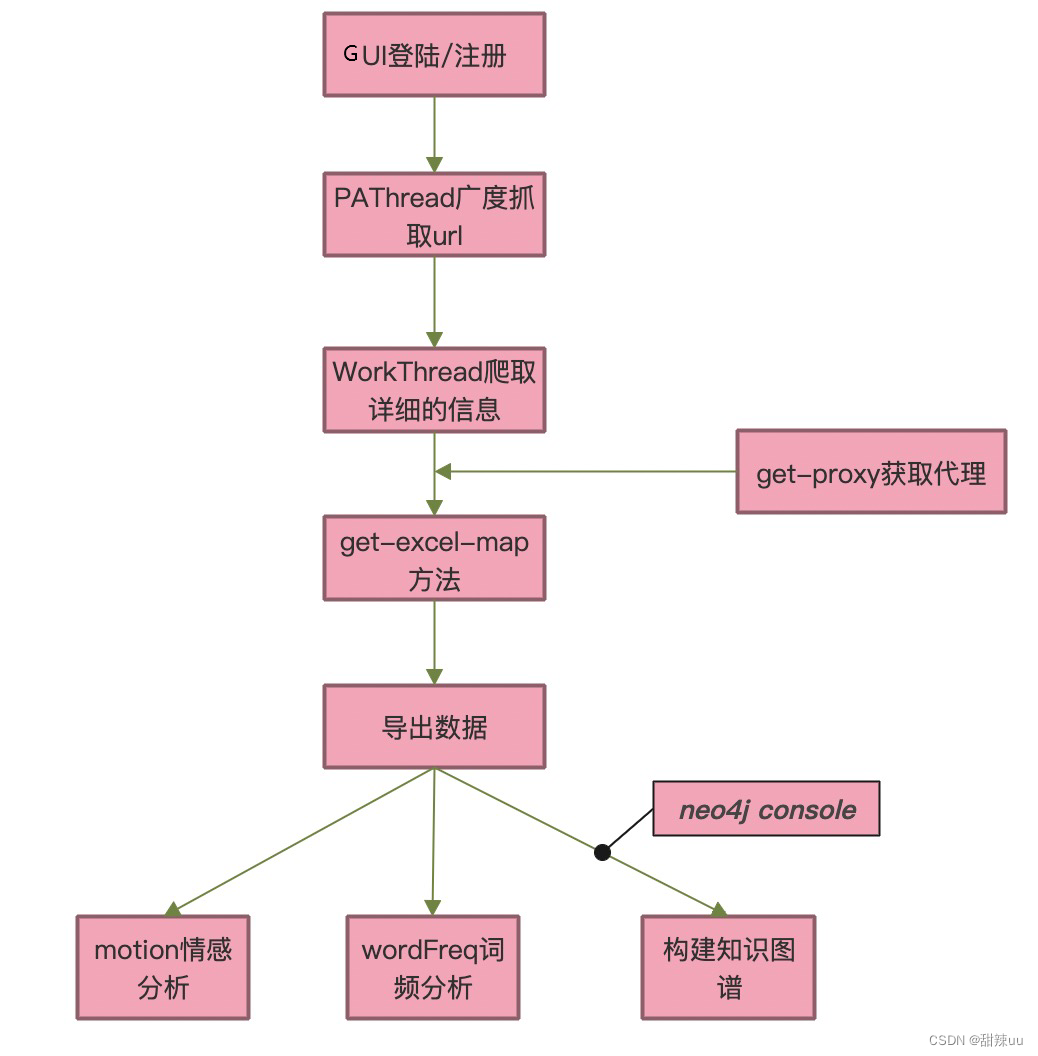
程序启动后有可视化的 GUI 界面,可以支持用户的登录与注册操作;
登录完成时可选择记住用户名/记住密码/自动登录等功能
登录完成后可以进入主窗口,选择“加载豆瓣电影信息”可以实现豆瓣 top250 的爬取
爬取完毕后可点击“导出数据构建知识图谱”进行本地数据库知识图谱构建(知识图谱需提前打开)
执行词频统计按钮可实现多种不同选项的词频统计分析
执行情感分析按钮可实现对需要进行情感分析的电影的热门评论的情感分析与结果可视化
执行返回登录界面按钮可退出主窗口重新登录
执行退出按钮可安全退出程序
以上便是此项目的所有需求,基本实现界面的可交互功能,满足用户的易操作性,并且符合当前 GUI 的主流设计模式,可行,方便,可视化程度高。
设计
面向对象设计将现实世界的 OOA 模型转换为可以用软件实现的 OOD 模型。
设计分为两个阶段:总体设计阶段与详细设计阶段。在总体设计阶段,决定如何解决需求问题,确定解决问题的策略以及目标系统需要的程序,并设计软件的结构。在详细设计阶段,决定怎样具体地实现系统,并设计出程序的详细规格说明。
在总体设计阶段,首先确定了环境,即操作系统以及编译器。这样,就可以以需求分析说明书为依据,针对环境进行有针对性的设计。
环境说明如下:
使用环境:
Windows 操作系统:
此操作系统界面友好,且有较成熟的文件查询,传递等机制可供利用。
开发环境:
Python3.8 发行版 anaconda3
Neo4j-community-4.3.8
编写代码环境:
Pycharm2021.2.2
IDEA 开发工具,可以实现 Python 的自动补全,纠错,解释直至运行,为 Python 代码的编写和录入提供方便。
概要设计:
根据需求分析,将系统划分成 3 个子模块:
电影信息爬虫模块
知识图谱构建模块
附加功能模块
然后,依据 “类——责任——协作者”模型,在各子系统中确定出类。
电影信息爬虫模块:
根据广度优先搜索的要求,将该模块分为两个类,一是爬取所有电影的 url 的 PAThread 类,二是通过 url 爬取详细电影数据的 WordThread 类,对数据进行解析。

知识图谱构建模块:
主要包括 neo4j_test.py 模块,定义了相关结点与关系的方法,实现本
地知识图谱数据库构建
环境配置:
下载 neo4j-community 并安装;
在安装好的文件夹里找到 bin 文件夹并打开;
打开 bin 文件,cmd 终端打开;
打开终端后,输入./neo4j console 即可启动连接,打开得到的网址:
打开后,即可看到 neo4j 界面:
注:用户连接前需在代码 neo4j_test.py 中修改登录用户名及密码
graph=Graph('http://localhost:7474', auth=("neo4j", "密码"))
附加功能模块:
包括 GUI 界面(登录窗口 LoginPage()、注册窗口 RegisterPage()、主窗口 MainPage()、词频统计窗口 WordFreq()、情感分析窗口 Motion())、词频统计模块(针对电影的年份、时长、得分、地区、类型等的统计)、情感分析模块(热门评论情感分析);PAThread 与 WordThread 爬取继承多线程 QThread 类;代理池 get_proxy()函数
具体要求如下:
可视化 GUI 界面
实现 GUI 图形用户界面的构建,对爬虫和 neo4j 数据库操作的部分功能进行封装搭建,在 GUI 界面上为二者提供接口(例如利用 GUI 界面按钮来控制爬虫的开始与中断,知识图谱的构建展示以及关键词检索等功能),同时也为其他附加功能提供接口,为用户提供友好的可视化操作界面。
代理池数据库
搭建代理池主要分为存储、获取、检测、接口四个模块。此处由于现有免费代理较差,采用芝麻代理 API 函数进行构建代理池。
多线程
在爬取许多网页或者爬取图片的时候,采用单线程方式下载访问会导致程序运行缓慢。多线程是为了同步完成多项任务,通过提高资源使用效率来提高系统的效率。采用多个线程同步爬取多个网页。尤其是结合 GUI 的 QThread 多线程。
词频统计
词频统计模块分为读取、分词统计、写入三个模块,是自然语言处理的基础。可以利用现有的分词工具包(例如 jieba、等)对想要词频统计的信息进行分词,先将文本进行分词和词性标注,实现关键词提取。
情感分析
情感分析在自然语言处理中,情感分析一般指判断一段文本所表达的情绪状态,属于文本分类问题。针对电影的情感分析,是通过对电影评论的文本进行分词及词性标注,将电影的评论情感分为积极的,消极的或者中性。
设计主流程图:
详细设计:
电影信息爬虫模块:
爬取的两个类均是继承 QThread 类,可使用 start()方法进行多线程执行
PAThread 类:
# 线程:广度爬取TOP250的电影详情信息页urlclassPAThread(QThread)
模块流程图:
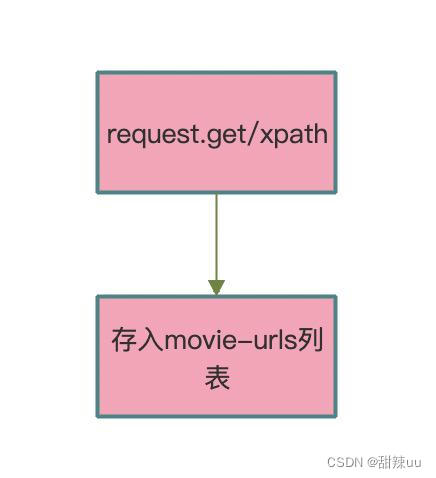
resp=requests.get(url=self.url,headers=headers,proxies=proxies)html=etree.HTML(resp.text)lis=html.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li')
通过获得的 url,利用封装好的 run 函数。利用 xpath 解析 HTML。同时获取所以电影的 url 做好类型转换。
movie_urls.append(movie_url)
最后添加到 movie_urls 列表中
Package 解释:
1.1 requests 是一个简单的请求库,其中的 get 方法可以像指定服务器发送 get 请求
1.2 headers 参数。作为请求的请求头。
proxies 参数。作为用户代理,访问服务器会以该代理的 ip 访问服务器,可掩盖本机 ip.
1.2.1 etree.HTML 函数
etree.HTML()可以用来解析字符串格式的 HTML 文档对象,将传进去的字符串转变成_Element 对象。作为_Element 对象,可以方便的使用 getparent()、remove()、xpath()等方法
html.xpath 函数
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
在爬虫中主要用于对 HTML 进行解析
WorkThread 类:
模块流程图:

# 线程:解析每个电影的url,将详细数据存到缓存列表classWorkThread(QThread):movie=[]ifresp.status_code==200:soup=BeautifulSoup(resp.text,features='lxml')tree=fromstring(resp.text)title_tmp=''.join(tree.xpath('//*[@id="content"]/h1/span[1]/text()'))# 分割中文与英文名称title_tmp=re.split(' ',title_tmp,1)movie.append(title_tmp[0])movie.append(title_tmp[1])movie.append(''.join(tree.xpath('//*[@id="content"]/div[1]/span[1]/text()')))movie.append(re.search('(?


