Neo4j详细介绍及使用教程



文章目录
- 一、Neo4j介绍
- 1.Neo4j简介
- 2.图数据库简介
- 3.Neo4j的优缺点
- 4.Neo4j的常见应用场景
- 二、使用教程
- 1.下载安装
- 2.数据插入和查询
- (1)基本概念
- (2)基本语法
- Ⅰ.CREATE操作——创建
- Ⅱ.MERGE——创建或更新
- Ⅲ.Match操作——查找指定的图数据
- Ⅳ.DELETE操作——删除节点
- 3.JAVA实战
一、Neo4j介绍
1.Neo4j简介
Neo4j是一个高性能的,NOSQL图形数据库。它是一个嵌入式的、高性能(基于磁盘的)、具备完全的事务特性的Java持久化引擎,该引擎具有成熟数据库的所有特性,它在图(网络)中而不是表中存储数据。
2.图数据库简介
(1)特点:它的数据模型主要是以节点和关系(边)来体现,也可处理键值对。它的优点是快速解决复杂的关系问题。
(2)特征:
①包含节点和边;
②节点上有属性(键值对);
③边有名字和方向,并总是有一个开始节点和一个结束节点;
④边也可以有属性。
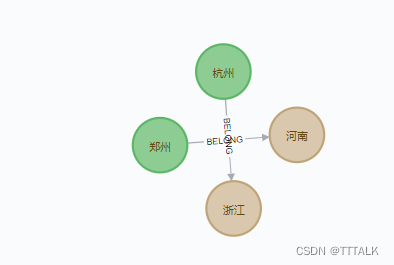
如下图的反洗钱模型:
(3)图计算
基本的数据结构表达就是:
G=(V, E)
V=vertex(节点)
E=edge(边)
3.Neo4j的优缺点
(1)优点
①底层数据存储专门针对图形数据的特点进行了优化,在处理关系数据方面比其他数据库有更高的性能。
②专门为关系数据设计的查询语言更便于关系数据的操作。
③没有表结构的概念,它比SQL更灵活。
④自动为数据建立合适的索引(根据数据的标签),避免索引管理的麻烦。
⑤支持高可用主从集群部署。
⑥借助图形平台等辅助工具帮助开发人员快速构建完整的关系数据平台。
(2)neo4j的缺点
①图数据结构导致写入性能差。
②只支持java和基于jvm的语言,社区版不能使用集群。
③社区不够活跃,资料不丰富。
(3)为什么选用Neo4j
Neo4j发布时间早,产品较为成熟稳定,目前是市场使用率最高的图数据库,文档和各种技术博客较多
4.Neo4j的常见应用场景
(1)金融行业的反洗钱模型
(2)社交网络图谱
(3)企业关系图谱
二、使用教程
1.下载安装
(1)下载
需要jdk环境:Neo4j v4 需使用 jdk11以上版本;v5需要jdk17以上版本。我本地是jdk1.8版本,所以选择v3的版本。
v4、v5下载可以到官网:https://neo4j.com/download-center/,但是官网找不到v3版本。
这里放上v3.5.5版本的资源:链接:https://pan.baidu.com/s/1Wx4MwHRCRKUOXUcUvWctmA 提取码:0g30
(2)配置环境变量
新建用户变量NEO4J_HOME,值为D:\tools\neo4j\neo4j-community-3.5.5-windows\neo4j-community-3.5.5,
然后在系统变量Path中添加%NEO4J_HOME%\bin。
(3)启动
在cmd中运行D:\tools\neo4j\neo4j-community-3.5.5-windows\neo4j-community-3.5.5\bin>neo4j console
然后进入http://localhost:7474/browser/就可以访问了
然后会提示你输入用户名密码 默认是neo4j/neo4j
2.数据插入和查询
(1)基本概念
Nodes:节点,用于图形数据记录
Relationships:关系,用于连接节点
Properties:属性,用于命名数据值
(2)基本语法
首先我们找到创建图的入口,然后再在最上方运行命令即可
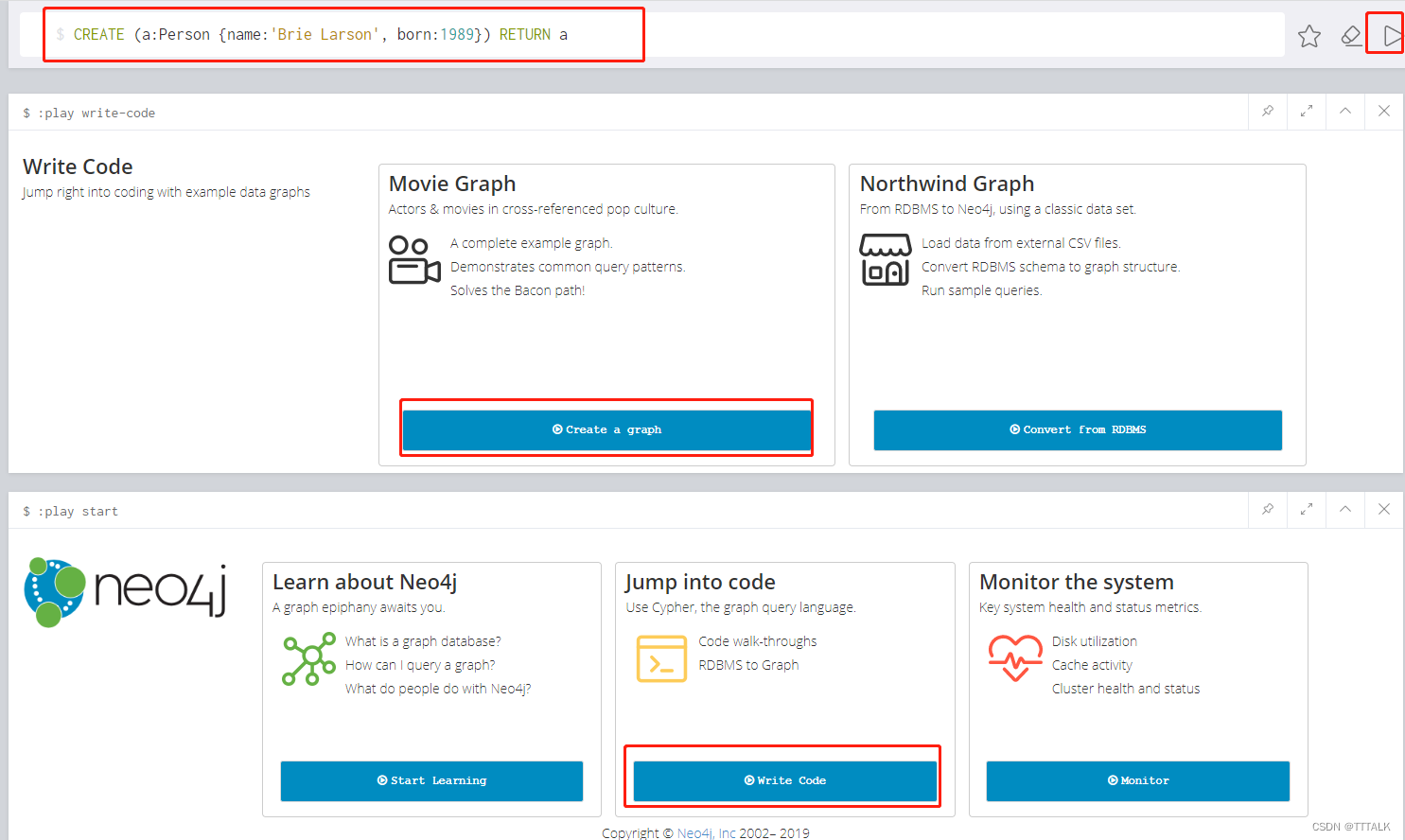
Ⅰ.CREATE操作——创建
①添加节点:
CREATE (n:Person {name:‘小李’, born:1989}) RETURN n;
注:CREATE是创建操作,n代表该节点,相当于一个只在当前语句生效的局部变量,Person是标签,代表节点的类型。花括号{}代表节点的属性。RETURN 代表返回该数据,也可以不return直接插入
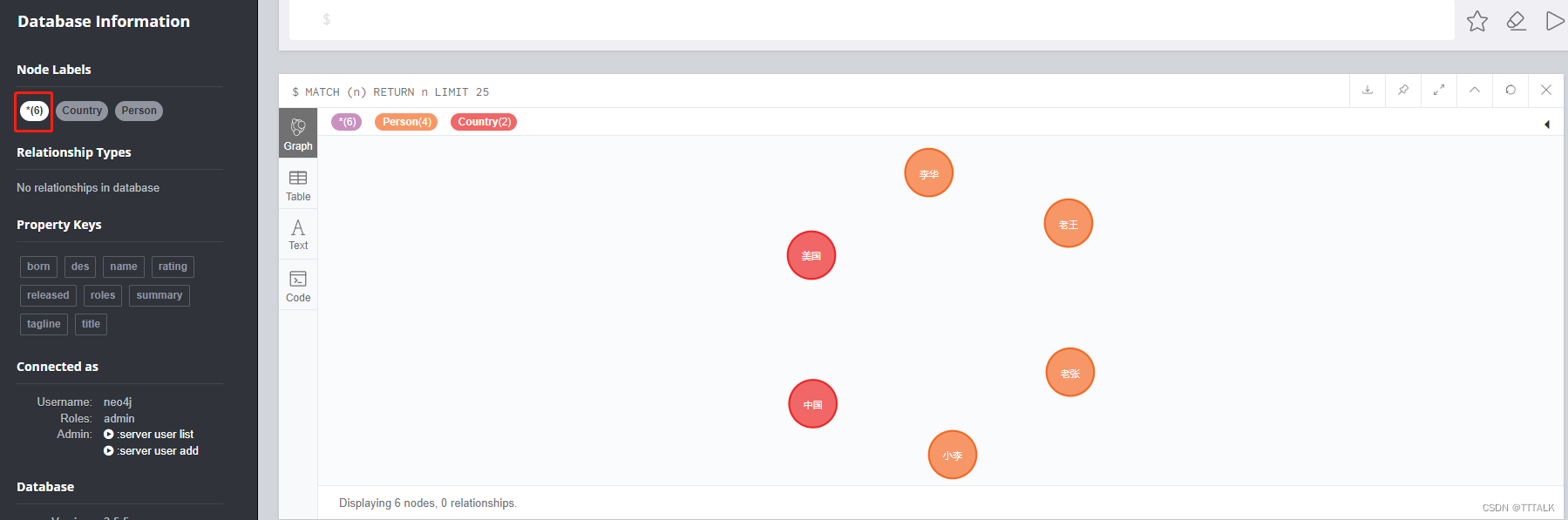
批量操作:
CREATE (a:Person {name:‘老张’, born:1990})
CREATE (b:Person {name:‘老王’, born:1995})
CREATE (c:Person {name:‘李华’, born:1993})
CREATE (d:Country {name:‘美国’, des:‘美利坚共和国’})
CREATE (n:Country {name:‘中国’, des:‘中华人民共和国’})
此时我们的图:
②创建关系:
CREATE (a:Person {name:‘小李’, born:1989})-[r:所属国家]->(b:Country {name:‘中国’, des:‘中华人民共和国’}) return a,r,b
在一个Person与Country之间建立一个“所属国家”关系,并且这个关系是有方向的
Ⅱ.MERGE——创建或更新
merge等于是create+match,如果节点中有重复数据,就不会添加进去
①创建节点:
MERGE (n:Person {name:‘小胡’, born:1990})
②创建关系:
MATCH (a:Person {name:‘李华’, born:1993}), (b:Country {name:‘美国’, des:‘美利坚共和国’})
MERGE (a)-[r:所属国家]->(b)
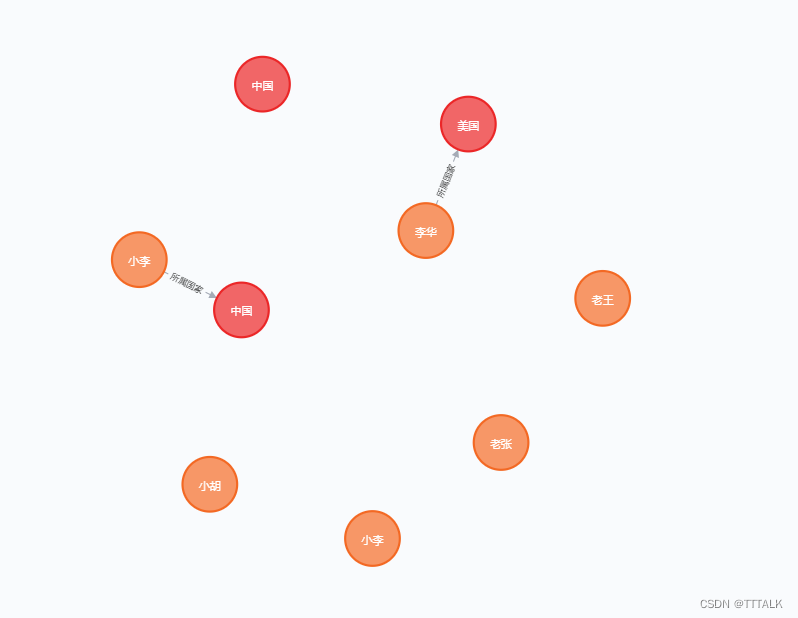
③更新操作:
MERGE (n:Person {name:‘老王’})
ON MATCH SET n.born = 2023
RETURN n
Ⅲ.Match操作——查找指定的图数据
①普通查询:
MATCH (n:Person {born:1990}) RETURN n
指查询一个标签(Label)为Person、born为1990的节点。
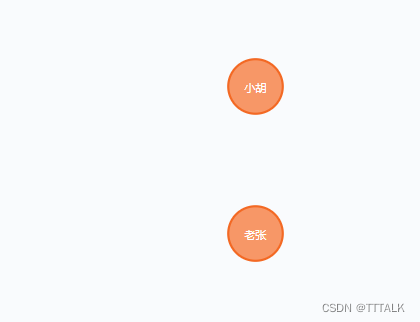
②查询所有对外有关系的节点(注意这里箭头的方向)
MATCH (a)–>() RETURN a
③查询所有有关系的节点
MATCH (a)–() RETURN a
④修改操作
MATCH (a:Person {name:‘老王’}) SET a.born=1988 RETURN a
⑤删除属性
MATCH (a:Country {name:‘美国’}) REMOVE a.des RETURN a
Ⅳ.DELETE操作——删除节点
①删除
MATCH (a:Person {name:‘李华’}) DETACH DELETE a
Delete操作会删除节点与关系。
②删除全部:
MATCH (n) DETACH DELETE n
3.JAVA实战
(1)首先引入maven包
org.neo4j neo4j 3.5.5(2)使用嵌入式的方式访问Neo4j(还有服务的方式,可以自行了解)
package com.example.user.dal; import org.neo4j.graphdb.*; import org.neo4j.graphdb.factory.GraphDatabaseFactory; import java.io.File; ///neo4j使用--嵌入式 public class neo4jRepository { //创建节点的标签枚举 public enum MyLabels implements Label { //城市 CITY, //省会 CAPITAL; } //创建关系的标签枚举 public enum MyRelation implements RelationshipType { //所属 BELONG } //全局只创建一个GraphDatabaseService实例 GraphDatabaseService graphDb; //创建file 指明我们想要操作的neo4j数据库的数据文件的路径 private static final File databaseDirectory = new File("D:\\tools\\neo4j\\neo4j-community-3.5.5-windows\\neo4j-community-3.5.5\\data\\databases\\graph.db"); public static void main(String[] args) { neo4jRepository repository = new neo4jRepository(); /*repository.createDb(); repository.shutDown();*/ //repository.searchCapital("浙江"); repository.searchProvince("郑州"); } void createDb() { System.out.println( "打开数据库 ..." ); //创建graphDb实例, 参数是我们想要操作的neo4j数据库的数据文件的路径, 以打开一个数据库 graphDb = new GraphDatabaseFactory().newEmbeddedDatabase(databaseDirectory); //创建事务 try ( Transaction tx = graphDb.beginTx() ) { Node city1 = graphDb.createNode(new CaseLabel(String.valueOf(MyLabels.CITY))); city1.setProperty("name", "浙江"); city1.setProperty("abbreviation", "浙"); Node city2 = graphDb.createNode(new CaseLabel(String.valueOf(MyLabels.CITY))); city2.setProperty("name", "河南"); city2.setProperty("abbreviation", "豫"); Node cap1 = graphDb.createNode(new CaseLabel(String.valueOf(MyLabels.CAPITAL))); cap1.setProperty("name", "杭州"); Node cap2 = graphDb.createNode(new CaseLabel(String.valueOf(MyLabels.CAPITAL))); cap2.setProperty("name", "郑州"); cap1.createRelationshipTo(city1,MyRelation.BELONG); cap2.createRelationshipTo(city2,MyRelation.BELONG); //提交事务 tx.success(); } } //根据省份查省会 void searchCapital(String provinceName) { graphDb = new GraphDatabaseFactory().newEmbeddedDatabase( databaseDirectory ); try ( Transaction tx = graphDb.beginTx()) { Node startNode = graphDb.findNode(new CaseLabel(String.valueOf(MyLabels.CITY)), "name", provinceName); //Direction介绍:从起始节点来看,它是一个传出关系OUTGOING;从结束节点看是传入关系INCOMING;方向不重要时使用BOTH=OUTGOING+INCOMING Iterable iterable = startNode .getRelationships(MyRelation.BELONG, Direction.INCOMING); for (Relationship r : iterable) { Node node = r.getStartNode(); long id = node.getId(); String name = (String)node.getProperty("name"); System.out.println(id + " " + name+ " "); } tx.success(); tx.close(); tx.success(); } } //根据省会查省份 void searchProvince(String capitalName) { graphDb = new GraphDatabaseFactory().newEmbeddedDatabase( databaseDirectory ); try ( Transaction tx = graphDb.beginTx()) { Node startNode = graphDb.findNode(new CaseLabel(String.valueOf(MyLabels.CAPITAL)), "name", capitalName); //Direction介绍:从起始节点来看,它是一个传出关系OUTGOING;从结束节点看是传入关系INCOMING;方向不重要时使用BOTH=OUTGOING+INCOMING Iterable iterable = startNode .getRelationships(MyRelation.BELONG, Direction.OUTGOING); for (Relationship r : iterable) { //注意这里使用EndNode Node node = r.getEndNode(); long id = node.getId(); String name = (String)node.getProperty("name"); String abbreviation = (String)node.getProperty("abbreviation"); System.out.println(id + " " + name+ " "+abbreviation); } tx.success(); tx.close(); tx.success(); } } void shutDown() { System.out.println( "关闭数据库 ..." ); // 关闭数据库 graphDb.shutdown(); } private static void registerShutdownHook( final GraphDatabaseService graphDb ) { // 用来确保数据库正确关闭的 一个回调方法 Runtime.getRuntime().addShutdownHook( new Thread() { @Override public void run() { graphDb.shutdown(); } } ); } }(3)测试,这里需要关闭neo4j的cmd窗口。这里三块代码按顺序执行,调用时需要把其他步骤的代码注释掉:
第一步是插入数据,第二步是查省会,第三步是查省份。
/*repository.createDb(); repository.shutDown();*/ //repository.searchCapital("浙江"); repository.searchProvince("郑州");最后的图大概长这样