
自然语言处理技术及处理框架学习



最近正在着手研究知识图谱建设及应用方面工作,我们知道,做知识图谱首先涉及到的问题就是自然语言处理,简称NLP。一般用于构建知识图谱的数据源大概有两类:结构化数据和非结构化数据,这两类数据都需要做以下的自然语言处理工作,本文重点阐述自然语言处理的相关技术,以及与处理有关的开源框架学习。
一、常见的自然语言处理流程:
文本抽取--》数据加载--》数据清洗--》构建用户自定义分词--》构建同义词列表--》去除停用词--》文档分词--》获得每条信息或每篇文档的分词列表--》形成图谱--》分词列表转化为向量
1.文本抽取:一般采取OCR,office或pdf转txt或csv格式。
2.数据加载:单个txt或csv文件的加载,批量文件夹的文件递归加载。
3.数据清洗:一般采用正则表达式或字符串替换,简体繁体转换,缺失值处理等等。
4.构建自定义分词列表和同义词列表:形成行业或专业分词库,主要是一些内部的公共关联名词、专业名词或动词。
5.去除停用词:去掉常见的停用词,比如的,地,得,代词,形容词,程度词等。
6.文档分词:结合专业的分词处理框架,实现信息的分词,并且获的词性数据,有些还能获的关系数据。
7.形成图谱:结合开源的行业知识词库(如有),再结合上下文的分级分类关系,得到每条信息或每篇文档的图谱,并在总体图谱中关联,未来融入的总体图谱中。
8.分词列表转化为向量:结合开源的词向量模型,实现分词列表转化为词向量矩阵,如tfidf、word2vec,bow/cbow,bert2vec等)。
一般上述前6步骤会反复循环开展。
二、常见的自然语言处理框架推荐
1.jieba分词:支持三种分词模式(精确,全模式和搜索引擎),自定义分词,词典调整,关键词提取,词性标注等。
2.HanLP分词:相当于利用python调用jvm程序(jar),支持四种分词模式(标准、NLP、索引和极速),自定义分词,实体识别和词性标注等。
3.spacy框架:支持句子分割,实体识别,依赖关系识别,词性识别与还原等。
4.NLTK词频特征统计:实现特征词的频率分布图。
5.tfidf值特征统计:实现不同分类下的词频矩阵,引入sklearn实现多分类情况下的TF/IDF特征值计算。
6.Gensim库:实现自然语言处理(支持前6步工作),支持不同的文本矢量化模型,包括TF/IDF,LSA,LDA,RP,word2vec等。
7.Tensorflow:机器学习框架,支持各种自然语言处理的开源的词向量模型,灵活搭建各种AI模型。
8.SKlearn:机器学习类库,支持多种自然语言处理的开源的词向量模型,机器学习模型。
三、自然语言处理技术体系:
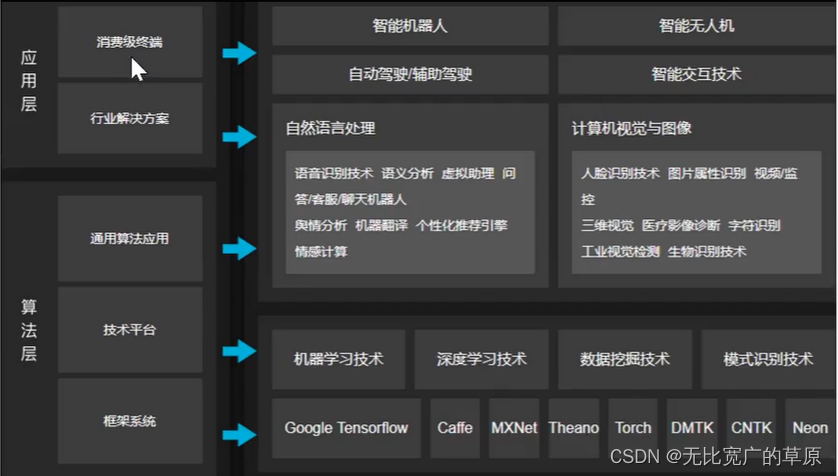
四、第二部分处理框架内容的代码汇总
import jieba,os
import jieba.posseg
import jieba.analyse
# 1 全模式,扫描所有可以成词的词语, 速度非常快,不能解决歧义.
seg_list = jieba.cut("我来到北京的清华大学", cut_all=True)
print("\nFull Mode: " + "/ ".join(seg_list))
# 2 加载自定义分词词典
jieba.load_userdict("../dataSet/StopWord/user_dict.txt")
seg_list1 = jieba.cut("今天很高兴在csdn和大家交流学习自然语言处理及知识图谱相关知识")
print('\n\n加载自定义分词词典:\n'+"/ ".join(seg_list1))
# 3 关键词提取
s ='今天很高兴在csdn和大家交流学习自然语言处理及知识图谱相关知识'
for x, w in jieba.analyse.extract_tags(s,10, withWeight=True):
print('%s %s' % (x, w))
# 4 词性标注
words = jieba.posseg.cut("我爱北京的历史文化")
for word, flag in words:
print('%s %s' % (word, flag))
from jpype import *
# 启动JVM,Linux需替换分号;为冒号:
startJVM(getDefaultJVMPath(), "-Djava.class.path=D:\dev\hanlp\hanlp\hanlp-1.8.3.jar;D:\dev\hanlp\hanlp", "-Xms1g", "-Xmx1g")
# 1 NLP分词NLPTokenizer会执行全部命名实体识别和词性标注
print("="*30+"NLP分词"+"="*30)
NLPTokenizer = JClass('com.hankcs.hanlp.tokenizer.NLPTokenizer')
print(NLPTokenizer.segment(paraStr1))
#2 自定义分词
paraStr2 = '攻城狮逆袭单身狗,迎娶白富美,走上人生巅峰'
CustomDictionary = JClass('com.hankcs.hanlp.dictionary.CustomDictionary')
CustomDictionary.add('攻城狮')
CustomDictionary.add('单身狗')
HanLP = JClass('com.hankcs.hanlp.HanLP')
print(HanLP.segment(paraStr2))
#3 命名实体识别与词性标注
NLPTokenizer = JClass('com.hankcs.hanlp.tokenizer.NLPTokenizer')
print(NLPTokenizer.segment(paraStr2))
shutdownJVM()
import spacy
nlp = spacy.load('en_core_web_sm')
with open("./data/FINAL_WELL_REPORT.txt",encoding='utf-8') as f:
text1 = f.read()
# 创建nlp对象
doc = nlp(text1)
#1 词性标注
print([(w.text, w.pos_) for w in doc])
print(spacy.explain("VERB"))
#nlp.tokenizer(doc)
# 2 依赖关系分析
for token in doc:
print(token.text, "-->", token.dep_)


