
HiveSQL题——聚合函数(sum/count/max/min/avg)



目录
一、窗口函数的知识点
1.1 窗户函数的定义
1.2 窗户函数的语法
1.3 窗口函数分类
聚合函数
排序函数
前后函数
头尾函数
1.4 聚合函数
二、实际案例
2.1 每个用户累积访问次数
0 问题描述
1 数据准备
2 数据分析
3 小结
2.2 各直播间最大的同时在线人数
0 问题描述
1 数据准备
2 数据分析
3 小结
2.3 历史至今每个小时内同时在线人数
0 问题描述
1 数据准备
2 数据分析
3 小结
2.4 某个时间段、每个小时内同时在线人数
0 问题描述
1 数据准备
2 数据分析
3 小结
2.5 学生各学科的成绩
0 问题描述
1 数据准备
2 数据分析
3 小结
2.6 商品销售
0 问题描述
1 数据准备
2 数据分析
3 小结
2.7 商品复购率
0 问题描述
1 数据准备
2 数据分析
3 小结
一、窗口函数的知识点
1.1 窗户函数的定义
窗口函数可以拆分为【窗口+函数】。窗口函数官网指路:
LanguageManual WindowingAndAnalytics - Apache Hive - Apache Software Foundation![]() https://cwiki.apache.org/confluence/display/Hive/LanguageManual%20WindowingAndAnalytics
https://cwiki.apache.org/confluence/display/Hive/LanguageManual%20WindowingAndAnalytics
- 窗口:限定函数的计算范围(窗口函数:针对分组后的数据,从逻辑角度指定计算的范围,并没有从物理上真正的切分,只有group by 是物理分组,真正意义上的分组)
- 函数:定义函数计算逻辑
- sql 执行顺序:
from -> join -> on -> where -> group by-> with (可以在分组后面加上 with rollup,在分组之后对每个组进行全局汇总) -> select 后面的普通字段,聚合函数-> having(having中可以使用select 字段别名) -> distinct -> order by -> limit
- 窗口函数执行顺序:窗口函数是作用于select后的结果集。select 的结果集作为窗口函数的输入,但是位于 distcint 之前。窗口函数的执行结果只是在原有的列中单独添加一列,形成新的列,它不会对已有的行或列做修改
1.2 窗户函数的语法
window_name over ( [partition by 字段...] [order by 字段...] [窗口子句] )
- window_name:给窗口指定一个别名。
- over:用来指定函数执行的窗口范围,如果后面括号中什么都不写,即over() ,意味着窗口包含满足where 条件的所有行,窗口函数基于所有行进行计算。
- 符号[] 代表:可选项; | : 代表二选一
- partition by 子句: 窗口按照哪些字段进行分组,窗口函数在不同的分组上分别执行。分组间互相独立。
- order by 子句:每个partition内部按照哪些字段进行排序,如果没有partition ,那就直接按照最大的窗口排序,且默认是按照升序(asc)排列。
- 窗口子句:显示声明范围(不写窗口子句的话,会有默认值)。常用的窗口子句如下:
rows between unbounded preceding and unbounded following; -- 上无边界到下无边界(一般用于求 总和) rows between unbounded preceding and current row; --上无边界到当前记录(累计值) rows between 1 preceding and current row; --从上一行到当前行 rows between 1 preceding and 1 following; --从上一行到下一行 rows between current row and 1 following; --从当前行到下一行ps: over()里面有order by子句,但没有窗口子句时 ,即: over ( partition by 字段... order by 字段... ),此时窗口子句是有默认值的 --> rows between unbounded preceding and current row (上无边界到当前行)。
此时窗口函数语法: over ( partition by 字段... order by 字段... ) 等价于
over ( partition by 字段... order by 字段... rows between unbounded preceding and current row)
需要注意有个特殊情况:当order by 后面跟的某个字段是有重复行的时候, over ( partition by 字段... order by 字段... ) 不写窗口子句的情况下,窗口子句的默认值是:range between unbounded preceding and current row(上无边界到当前相同行的最后一行)。
因此,遇到order by 后面跟的某个字段出现重复行,且需要计算【上无边界到当前行】,那就需要手动指定窗口子句 rows between unbounded preceding and current row ,偷懒省略窗口子句会出问题~
总结如下:
1、窗口子句不能单独出现,必须有order by子句时才能出现。 2、当省略窗口子句时: a) 如果存在order by则默认的窗口是unbounded preceding and current row --当前组的第一行到当前行,即在当前组中,第一行到当前行 b) 如果没有order by则默认的窗口是unbounded preceding and unbounded following --整个组
ps: 窗口函数的执行顺序是在where之后,所以如果where子句需要用窗口函数作为条件,需要多一层查询,在子查询外面进行。
【例如】求出登录记录出现间断的用户Id
select id from ( select id, login_date, lead(login_date, 1, '9999-12-31') over (partition by id order by login_date) next_login_date --窗口函数 lead(向后取n行) --lead(column1,n,default)over(partition by column2 order by column3) 查询当前行的后边第n行数据,如果没有就为null from (--用户在同一天可能登录多次,需要去重 select id, date_format(`date`, 'yyyy-MM-dd') as login_date from user_log group by id, date_format(`date`, 'yyyy-MM-dd') ) tmp1 ) tmp2 where datediff(next_login_date, login_date) >=2 group by id;1.3 窗口函数分类
哪些函数可以是窗口函数呢?(放在over关键字前面的)
-
聚合函数
sum(column) over (partition by .. order by .. 窗口子句); count(column) over (partition by .. order by .. 窗口子句); max(column) over (partition by .. order by .. 窗口子句); min(column) over (partition by .. order by .. 窗口子句); avg(column) over (partition by .. order by .. 窗口子句); collect_list (column) over (partition by .. order by .. 窗口子句); collect_set (column) over (partition by .. order by .. 窗口子句);
需要注意:
1.count(*)操作时会统计null值,count(column)会过滤掉null值; 2.事实上除了count(*)计算,剩余的聚合函数例如: max(column),min(column),avg(column),count(column) 函数会过滤掉null值
ps : 高级聚合函数:
collect_list 收集并形成list集合,结果不去重;
collect_set 收集并形成set集合,结果去重;
举例:
--每个月的入职人数以及姓名 select month(replace(hiredate,'/','-')), count(*) as cnt, collect_list(name) as name_list from employee group by month(replace(hiredate,'/','-')); /* 输出结果 month cn name_list 4 2 ["宋青书","周芷若"] 6 1 ["黄蓉"] 7 1 ["郭靖"] 8 2 ["张无忌","杨过"] 9 2 ["赵敏","小龙女"] */高级聚合函数collect_set()/collect_list()的用法见:
HiveSQL题——collect_set()/collect_list()聚合函数-CSDN博客文章浏览阅读1.1k次,点赞20次,收藏20次。HiveSQL题——collect_set()/collect_list()聚合函数
https://blog.csdn.net/SHWAITME/article/details/136011647?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170762720816800226594415%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170762720816800226594415&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-2-136011647-null-null.nonecase&utm_term=%E8%81%9A%E5%90%88%E5%87%BD%E6%95%B0&spm=1018.2226.3001.4450
-
排序函数
-- 顺序排序——1、2、3 row_number() over(partition by .. order by .. ) -- 并列排序,跳过重复序号——1、1、3(横向加) rank() over(partition by .. order by .. ) -- 并列排序,不跳过重复序号——1、1、2(纵向加) dense_rank() over(partition by .. order by .. )
-
前后函数
-- 取得column列的前n行,如果存在则返回,如果不存在,返回默认值default lag(column,n,default) over(partition by order by) as lag_test -- 取得column列的后n行,如果存在则返回,如果不存在,返回默认值default lead(column,n,default) over(partition by order by) as lead_test
-
头尾函数
---当前窗口column列的第一个数值,如果有null值,则跳过 first_value(column,true) over (partition by ..order by.. 窗口子句) ---当前窗口column列的第一个数值,如果有null值,不跳过 first_value(column,false) over (partition by ..order by.. 窗口子句) --- 当前窗口column列的最后一个数值,如果有null值,则跳过 last_value(column,true) over (partition by ..order by.. 窗口子句) --- 当前窗口column列的最后一个数值,如果有null值,不跳过 last_value(column,false) over (partition by ..order by.. 窗口子句)
1.4 聚合函数
sum() /count() /max() /min() /avg() 函数,一般用于开窗求累积汇总值。
sum(column) over (partition by .. order by .. 窗口子句); count(column) over (partition by .. order by .. 窗口子句); max(column) over (partition by .. order by .. 窗口子句); min(column) over (partition by .. order by .. 窗口子句); avg(column) over (partition by .. order by .. 窗口子句);
二、实际案例
2.1 每个用户累积访问次数
0 问题描述
统计每个用户累积访问次数
1 数据准备
create table if not exists table6 ( userid string comment '用户id', visitdate string comment '访问时间', visitcount int comment '访问次数' ) comment '用户访问次数';2 数据分析
select userid, visit_date, vc1, --再求出用户历史至今的累积访问次数 sum(vc1) over (partition by userid order by visit_date ) as vc2 from ( --先求出用户每个月的累积访问次数 select userid, date_format(visitdate, 'yyyy-MM') as visit_date, sum(visitcount) as vc1 from table6 group by userid, date_format(visitdate, 'yyyy-MM') ) tmp1;3 小结
2.2 各直播间最大的同时在线人数
0 问题描述
根据直播间的用户访问记录,统计各直播间最大的同时在线人数。
1 数据准备
create table if not exists table7 ( room_id int comment '直播间id', user_id int comment '用户id', login_time string comment '用户进入直播间时间', logout_time string comment '用户离开直播间时间' ) comment '直播间的用户访问记录'; INSERT overwrite table table7 VALUES (1,100,'2021-12-01 19:00:00', '2021-12-01 19:28:00'), (1,100,'2021-12-01 19:30:00', '2021-12-01 19:53:00'), (2,100,'2021-12-01 21:01:00', '2021-12-01 22:00:00'), (1,101,'2021-12-01 19:05:00', '2021-12-01 20:55:00'), (2,101,'2021-12-01 21:05:00', '2021-12-01 21:58:00'), (1,102,'2021-12-01 19:10:00', '2021-12-01 19:25:00'), (2,102,'2021-12-01 19:55:00', '2021-12-01 21:00:00'), (3,102,'2021-12-01 21:05:00', '2021-12-01 22:05:00'), (1,104,'2021-12-01 19:00:00', '2021-12-01 20:59:00'), (2,104,'2021-12-01 21:57:00', '2021-12-01 22:56:00'), (2,105,'2021-12-01 19:10:00', '2021-12-01 19:18:00'), (3,106,'2021-12-01 19:01:00', '2021-12-01 21:10:00');2 数据分析
select room_id, max(num) from ( select room_id, sum(flag) over (partition by room_id order by dt) as num from ( select room_id, user_id, login_time as dt, --对登入该直播间的人,标记 1 1 as flag from table7 union select room_id, user_id, logout_time as dt, --对退出该直播间的人,标记 -1 -1 as flag from table7 ) tmp1 ) tmp2 --求出直播间最大的同时在线人数 group by room_id;3 小结
该题的关键点在于:对每个用户进入/退出直播间的行为进行打标签,再利用sum()over聚合函数计算最终的数值。
2.3 历史至今每个小时内同时在线人数
由案例2.2 引申出来的案例 2.3和 案例2.4
0 问题描述
根据直播间用户访问记录,不限制时间段,统计历史至今的各直播间每个小时内的同时在线人数
1 数据准备
create table if not exists table7 ( room_id int comment '直播间id', user_id int comment '用户id', login_time string comment '用户进入直播间时间', logout_time string comment '用户离开直播间时间' ) comment '直播间的用户访问记录'; INSERT overwrite table table7 VALUES (1,100,'2021-12-01 19:00:00', '2021-12-01 19:28:00'), (1,100,'2021-12-01 19:30:00', '2021-12-01 19:53:00'), (2,100,'2021-12-01 21:01:00', '2021-12-01 22:00:00'), (1,101,'2021-12-01 19:05:00', '2021-12-01 20:55:00'), (2,101,'2021-12-01 21:05:00', '2021-12-01 21:58:00'), (1,102,'2021-12-01 19:10:00', '2021-12-01 19:25:00'), (2,102,'2021-12-01 19:55:00', '2021-12-01 21:00:00'), (3,102,'2021-12-01 21:05:00', '2021-12-01 22:05:00'), (1,104,'2021-12-01 19:00:00', '2021-12-01 20:59:00'), (2,104,'2021-12-01 21:57:00', '2021-12-01 22:56:00'), (2,105,'2021-12-01 19:10:00', '2021-12-01 19:18:00'), (3,106,'2021-12-01 19:01:00', '2021-12-01 21:10:00');2 数据分析
完整代码如下:
with temp_data as ( select room_id, user_id, login_time, logout_time, hour(login_time) as min_time, -- hour('2021-12-01 19:30:00') = 19 hour(logout_time) as max_time, length(space(hour(logout_time) - hour(login_time))) as lg, split(space(hour(logout_time) - hour(login_time)), '') as dis from table7 ) select room_id, on_time, count(1) as cnt from ( select distinct room_id, user_id, min_time, max_time, dis, dis_index, (min_time + dis_index) as on_time from temp_data lateral view posexplode(dis) n as dis_index,dis_data order by user_id, min_time, max_time, dis, dis_index ) tmp1 group by room_id, on_time order by room_id, on_time;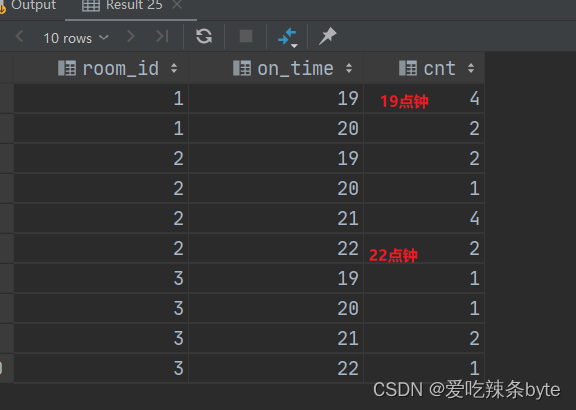
代码拆解分析:
--以一条数据为例, room_id user_id login_time logout_time 1 100 '2021-12-01 19:00:00' '2021-12-01 21:28:00' (1)上述数据取时间hour(login_time) as min_time 、hour(logout_time)as max_time 1(room_id),100(user_id),19(min_time),21(max_time) (2)split(space(hour(logout_time) - hour(login_time)), '') 的结果: 根据[21-19]=2,利用space函数生成长度是2的空格字符串,再用split拆分 1(room_id),100(user_id),19(min_time),21(max_time),['','',''] (3)用posexplode经过转换增加行(列转行,炸裂),通过下角标index来获取 on_time时间, 根据数组['','',''],得到index的取值是0,1,2 炸裂得出下面三行数据(一行变三行) 1(room_id),100(user_id),19(min_time),19 = 19+0 (on_time = min_time+index) 1(room_id),100(user_id),19(min_time),20 = 19+1 (on_time = min_time+index) 1(room_id),100(user_id),19(min_time),21 = 19+2 (on_time = min_time+index) 炸裂的目的:将用户在线的时间段[19-21] 拆分成具体的小时,19,20,21; (4)根据room_id,on_time进行分组,求出每个直播间分时段的在线人数3 小结
上述代码中用到的函数有:
一、字符串函数 1、空格字符串函数:space 语法:space(int n) 返回值:string 说明:返回值是n的空格字符串 举例:select length (space(10)) --> 10 一般space函数和split函数结合使用:select split(space(3),''); --> ["","","",""] 2、split函数(分割字符串) 语法:split(string str,string pat) 返回值:array 说明:按照pat字符串分割str,会返回分割后的字符串数组 举例:select split ('abcdf','c') from test; -> ["ab","df"] 3、repeat:重复字符串 语法:repeat(string A, int n) 返回值:string 说明:将字符串A重复n遍。 举例:select repeat('123', 3); -> 123123123 一般repeat函数和split函数结合使用:select split(repeat(',',4),','); --> ["","","","",""] 二、炸裂函数 explode 语法:lateral view explode(split(a,',')) tmp as new_column 返回值:string 说明:按照分隔符切割字符串,并将数组中内容炸裂成多行字符串 举例:select student_score from test lateral view explode(split(student_score,',')) tmp as student_score posexplode 语法:lateral view posexploed(split(a,',')) tmp as pos,item 返回值:string 说明:按照分隔符切割字符串,并将数组中内容炸裂成多行字符串(炸裂具备瞎下角标 0,1,2,3) 举例:select student_name, student_score from test lateral view posexplode(split(student_name,',')) tmp1 as student_name_index,student_name lateral view posexplode(split(student_score,',')) tmp2 as student_score_index,student_score where student_score_index = student_name_index2.4 某个时间段、每个小时内同时在线人数
0 问题描述
根据直播间用户访问记录,统计某个时间段的各直播间每个小时内的同时在线人数,假设时间段是['2021-12-01 19:00:00', '2021-12-01 23:00:00']
1 数据准备
create table if not exists table7 ( room_id int comment '直播间id', user_id int comment '用户id', login_time string comment '用户进入直播间时间', logout_time string comment '用户离开直播间时间' ) comment '直播间的用户访问记录'; INSERT overwrite table table7 VALUES (1,100,'2021-12-01 19:00:00', '2021-12-01 19:28:00'), (1,100,'2021-12-01 19:30:00', '2021-12-01 19:53:00'), (2,100,'2021-12-01 21:01:00', '2021-12-01 22:00:00'), (1,101,'2021-12-01 19:05:00', '2021-12-01 20:55:00'), (2,101,'2021-12-01 21:05:00', '2021-12-01 21:58:00'), (1,102,'2021-12-01 19:10:00', '2021-12-01 19:25:00'), (2,102,'2021-12-01 19:55:00', '2021-12-01 21:00:00'), (3,102,'2021-12-01 21:05:00', '2021-12-01 22:05:00'), (1,104,'2021-12-01 19:00:00', '2021-12-01 20:59:00'), (2,104,'2021-12-01 21:57:00', '2021-12-01 22:56:00'), (2,105,'2021-12-01 19:10:00', '2021-12-01 19:18:00'), (3,106,'2021-12-01 19:01:00', '2021-12-01 21:10:00'); 2 数据分析
完整代码如下:
with temp_data1 as ( select room_id, user_id, login_time, logout_time, hour(login_time) as min_time, hour(logout_time) as max_time, split(space(hour(logout_time) - hour(login_time)), '') as dis from table7 where login_time >= '2021-12-01 19:00:00' and login_time = 100) tmp1 group by sku_id, sub having count(1) >= 3;3 小结
上述解题方法用到了“连续登陆”的思想,该题型的解决步骤:
(1)计算 date_sub(create_date,row_number() over (partition by sku_id oder by create_date)) as sub(差值)
(2)group by sku_id,sub 分组;
(3)count(1) >= 3的商品sku_id就是销售额连续3天以上多超过xx;
更多“连续登陆”的案例 见文章:
HiveSQL题——用户连续登陆-CSDN博客文章浏览阅读803次,点赞21次,收藏9次。HiveSQL题——用户连续登陆
2.7 商品复购率
零食类商品中复购率top3高的商品_牛客题霸_牛客网商品信息表tb_product_info。题目来自【牛客题霸】
 https://www.nowcoder.com/practice/9c175775e7ad4d9da41602d588c5caf3?tpId=268
https://www.nowcoder.com/practice/9c175775e7ad4d9da41602d588c5caf3?tpId=2680 问题描述
求解零食类商品中复购率top3高的商品

1 数据准备
create table if not exists tb_order_overall( order_id int comment '订单号', uid int comment '用户ID', event_time string comment '下单时间', total_amount double comment '订单总金额', total_cnt int comment '订单商品总件数', `status` int comment '订单状态' ) comment '订单总表'; insert overwrite table tb_order_overall values (301001, 101, '2021-09-30 10:00:00', 140, 1, 1), (301002, 102, '2021-10-01 11:00:00', 235, 2, 1), (301011, 102, '2021-10-31 11:00:00', 250, 2, 1), (301003, 101, '2021-11-02 10:00:00', 300, 2, 1), (301013, 105, '2021-11-02 10:00:00', 300, 2, 1), (301005, 104, '2021-11-03 10:00:00', 170, 1, 1); create table if not exists tb_product_info ( product_id int comment '商品ID', shop_id int comment '店铺ID', tag string comment '商品类别标签', in_price double comment '进货价格', quantity int comment '进货数量', release_time string comment '上架时间' ) comment '商品信息表'; insert overwrite table tb_product_info values (8001, 901, '零食', 60, 1000, '2020-01-01 10:00:00'), (8002, 901, '零食', 140, 500, '2020-01-01 10:00:00'), (8003, 901, '零食', 160, 500, '2020-01-01 10:00:00'); drop table tb_order_detail create table if not exists tb_order_detail ( order_id int comment '订单号', product_id int comment '商品ID', price double comment '商品单价', cnt int comment'下单数量' ) comment '订单明细表'; insert overwrite table tb_order_detail values (301001, 8002, 150, 1), (301011, 8003, 200, 1), (301011, 8001, 80, 1), (301002, 8001, 85, 1), (301002, 8003, 180, 1), (301003, 8002, 140, 1), (301003, 8003, 180, 1), (301013, 8002, 140, 2), (301005, 8003, 180, 1);2 数据分析
注:复购率指用户在一段时间内对某商品的重复购买比例,复购率越大,则反映出消费者对品牌的忠诚度就越高,也叫回头率. 此处我们定义:某商品复购率 = 近90天内购买它至少两次的人数 / 购买它的总人数 近90天 指包含 最大日期(记为当天)在内的近90天。 要求:结果的复购率保留3位小数,并按复购率倒序、商品ID升序排序展示
select product_id, --步骤2:购买次数大于2的代表复购,复购的标识为1,再求累积值 :sum(if(buy_times >= 2, 1, 0)) -- 步骤3:复购率保留3位小数:round(result,3) round(sum(if(buy_times >= 2, 1, 0)) / count(*), 3) as repurchase_rate from (select pi.product_id, too.uid, count(1) as buy_times -- 步骤1:某商品某用户的购买次数 from tb_product_info pi join (select max(date(event_time)) as max_date from tb_order_overall) too1 left join tb_order_detail tod on pi.product_id = tod.product_id left join tb_order_overall too on tod.order_id = too.order_id where pi.tag = '零食' -- 零食类商品 and too.status = 1 --成功购买的 and datediff(too1.max_date ,date(too.event_time))
-
-
-
-
- 窗口函数执行顺序:窗口函数是作用于select后的结果集。select 的结果集作为窗口函数的输入,但是位于 distcint 之前。窗口函数的执行结果只是在原有的列中单独添加一列,形成新的列,它不会对已有的行或列做修改



