
zookeeper分布式协调系统的架构设计与源码剖析



目录
001_我们一般到底用ZooKeeper来干什么事儿?
002_有哪些开源的分布式系统中使用了ZooKeeper?
003_为什么我们在分布式系统架构中需要使用ZooKeeper集群?
004_ZooKeeper为了满足分布式系统的需求要有哪些特点
005_为了满足分布式系统的需求,ZooKeeper的架构设计有哪些特点?
006_ZooKeeper集群的三种角色:Leader、Follower、Observer
007_客户端与ZooKeeper之间的长连接和会话是什么?
008_ZooKeeper的数据模型:znode和节点类型
009_ZooKeeper最核心的一个机制:Watcher监听回调
012_从zk集群启动到数据同步再到崩溃恢复的ZAB协议流程
013_采用了2PC两阶段提交思想的ZAB消息广播流程
014_停一下脚步:ZooKeeper到底是强一致性还是最终一致性?
015_ZAB协议下两种可能存在的数据一致性问题
二、使用步骤
1.引入库
2.读入数据
总结
001_我们一般到底用ZooKeeper来干什么事儿?
ZooKeeper顶尖高手课程:从实战到源码
Kafka里面大量使用了ZooKeeper进行元数据管理、Master选举、分布式协调,Canal也是一样,ZooKeeper进行元数据管理,Master选举实现HA主备切换
HDFS,HA也是基于ZK来做的
6周的,zk核心原理,zk集群部署、运维和管理,zk实战开发,zk在hdfs、kafka、canal源码中的运用的分析,两周的时间研究zk的核心的内核源码和底层原理
《001_我们一般到底用ZooKeeper来干什么事儿?》
Java架构的课,分布式架构中,分布式锁,Redis分布式锁,ZooKeeper分布式锁
分布式锁:运用于分布式的Java业务系统中
元数据管理:Kafka、Canal,本身都是分布式架构,分布式集群在运行,本身他需要一个地方集中式的存储和管理分布式集群的核心元数据,所以他们都选择把核心元数据放在zookeeper中的
分布式协调:如果有人对zk中的数据做了变更,然后zk会反过来去通知其他监听这个数据的人,告诉别人这个数据变更了,kafka有多个broker,多个broker会竞争成为一个controller的角色
如果作为controller的broker挂掉了,此时他在zk里注册的一个节点会消失,其他broker瞬间会被zk反向通知这个事情,继续竞争成为新的controller
这个就是非常经典的一个分布式协调的场景,有一个数据,一个broker注册了一个数据,其他broker监听这个数据
Master选举 -> HA架构
HDFS,NameNode HA架构,部署主备两个NameNode,只有一个人可以通过zk选举成为Master,另外一个backup
Canal,HA
ZooKeeper,分布式协调系统,封装了分布式架构中所有核心和主流的需求和功能,分布式锁、分布式集群的集中式元数据存储、Master选举、分布式协调和通知
002_有哪些开源的分布式系统中使用了ZooKeeper?
《002_有哪些开源的分布式系统中使用了ZooKeeper?》
Canal、Kafka、HDFS,学习过的这些技术都用了ZooKeeper,元数据管理,Master选举
ZooKeeper,他主要是提供哪些功能,满足哪些需求,使用在哪些场景下,最后一句话总结,ZooKeeper到底是为什么而生的,定位是什么?
三类系统
第一类:分布式Java业务系统,分布式电商平台,大部分的Java开发的互联网平台,或者是传统架构系统,都是分布式Java业务系统,Dubbo、Spring Cloud把系统拆分成很多的服务或者是子系统,大家协调工作,完成最终的功能
ZooKeeper,用的比较少,分布式锁的功能,而且很多人会选择用Redis分布式锁
第二类:开源的分布式系统
Dubbo,HBase,HDFS,Kafka,Canal,Storm,Solr
分布式集群的集中式元数据存储、Master选举实现HA架构、分布式协调和通知
Dubbo:ZooKeeper作为注册中心,分布式集群的集中式元数据存储
HBase:分布式集群的集中式元数据存储
HDFS:Master选举实现HA架构
Kafka:分布式集群的集中式元数据存储,分布式协调和通知
Canal:分布式集群的集中式元数据存储,Master选举实现HA架构
第三类:自研的分布式系统
HDFS,面向的超大文件,切割成一个一个的小块儿,分布式存储在一个大的集群里
分布式海量小文件系统:NameNode的HA架构,仿照HDFS的NameNode的HA架构,做主备两个NameNode,进行数据同步,然后自动基于zk进行热切换
在很多,如果你自己研发类似的一些分布式系统,都可以考虑,你是否需要一个地方集中式存储分布式集群的元数据?是否需要一个东西辅助你进行Master选举实现HA架构?进行分布式协调通知?
如果你在自研分布式系统的时候,有类似的需求,那么就可以考虑引入ZooKeeper来满足你的需求
003_为什么我们在分布式系统架构中需要使用ZooKeeper集群?
003_为什么我们在分布式系统架构中需要使用ZooKeeper集群?》
ZooKeeper,功能和定位,满足的需求
使用ZooKeeper去满足自己需求的项目都有哪些
分布式集群的集中式元数据存储,Master选举实现HA架构,分布式协调和通知
我们写一个类似ZK的系统,单机版本,就是部署在一台机器上面,里面提供了一些功能,比如说允许你在里面存储一些元数据,支持你进行Master选举,支持你分布式协调和通知,也可以做到
单机版本的系统,万一挂掉了怎么办?
集群部署,部署一个集群出来,多台机器,保证高可用性,挂掉一台机器,都可以继续运行下去
3台机器
我现在要进行元数据的存储,我向机器01写了一条数据,机器01应该怎么把数据同步给其他的机器02和机器03呢?
自己写一个类似ZK的系统?不可能单机版本吧?肯定得集群部署保证高可用吧?一旦集群了之后,数据一致性怎么保证?多麻烦!
你的分布式架构中有需求,干脆就直接用工业级,久经考验的zookeeper就可以了,bug很少,功能很全面,运用在很多工业级的大规模的分布式系统中,HDFS、Kafka、HBase
004_ZooKeeper为了满足分布式系统的需求要有哪些特点
ZooKeeper肯定是一套系统,这个系统可以存储元数据,支持Master选举,可以进行分布式协调和通知
集群部署:不可能单机版本
顺序一致性:所有请求全部有序
原子性:要么全部机器都成功,要么全部机器都别成功
数据一致性:无论连接到哪台ZK上去,看到的都是一样的数据,不能有数据不一致
高可用:如果某台机器宕机,要保证数据绝对不能丢失
实时性:一旦数据发生变更,其他人要实时感知到
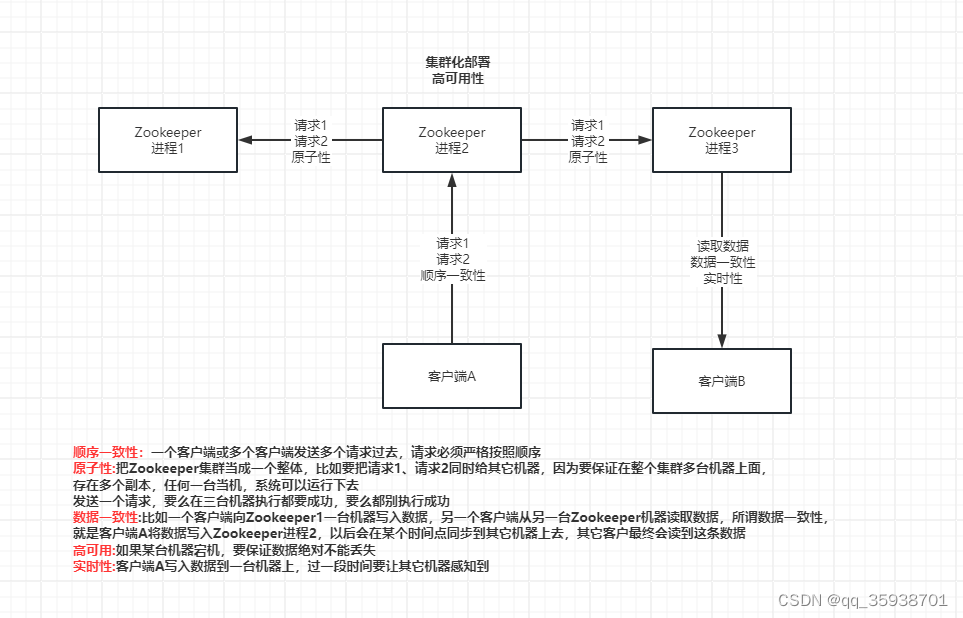
005_为了满足分布式系统的需求,ZooKeeper的架构设计有哪些特点?
《005_为了满足分布式系统的需求,ZooKeeper的架构设计有哪些特点?》
为了实现需要的一些特性,ZooKeeper的架构设计需要有哪些特点?
集群化部署:3~5台机器组成一个集群,每台机器都在内存保存了zk的全部数据,机器之间互相通信同步数据,客户端连接任何一台机器都可以
树形结构的数据模型:znode,树形结构,数据模型简单,纯内存保存
数据结构就跟我们的文件系统是类似的,是有层级关系的树形的文件系统的数据结构
znode可以认为是一个节点而已
create /usr/local/uid
create /usr/local/test_file
uid:可以写入一些数据的值,比如说hello world
test_file:也可以写入一些数据的值
顺序写:集群中只有一台机器可以写,所有机器都可以读,所有写请求都会分配一个zk集群全局的唯一递增编号,zxid,保证各种客户端发起的写请求都是有顺序的
数据一致性:任何一台zk机器收到了写请求之后都会同步给其他机器,保证数据的强一致,你连接到任何一台zk机器看到的数据都是一致的
高性能:每台zk机器都在内存维护数据,所以zk集群绝对是高并发高性能的,如果你让zk部署在高配置物理机上,一个3台机器的zk集群抗下每秒几万请求没有问题
高可用:哪怕集群中挂掉不超过一半的机器,都能保证可用,数据不会丢失,3台机器可以挂1台,5台机器可以挂2台
高并发:高性能决定的,只要基于纯内存数据结构来处理,并发能力是很高的,只有一台机器进行写,但是高配置的物理机,比如16核32G,写入几万QPS,读,所有机器都可以读,3台机器的话,起码可以支撑十几万QPS
https://www.processon.com/v/6597671165d15f64a981eb02
006_ZooKeeper集群的三种角色:Leader、Follower、Observer
https://www.processon.com/v/659b4ac89dab311b9590f194
007_客户端与ZooKeeper之间的长连接和会话是什么?
zk集群启动之后,自己分配好角色,然后客户端就会跟zk建立连接,是TCP长连接
把我们的Java架构课程里的网络那块的东西,自研的分布式海量小文件存储系统的项目,我们手写了大量的底层的网络通信的代码
也就建立了一个会话,就是session,可以通过心跳感知到会话是否存在,有一个sessionTimeout,意思就是如果连接断开了,只要客户端在指定时间内重新连接zk一台机器,就能继续保持session,否则session就超时了
008_ZooKeeper的数据模型:znode和节点类型
核心数据模型就是znode树,平时我们往zk写数据就是创建树形结构的znode,里面可以写入值,就这数据模型,都在zk内存里存放
有两种节点,持久节点和临时节点,持久节点就是哪怕客户端断开连接,一直存在
临时节点,就是只要客户端断开连接,节点就没了
还有顺序节点,就是创建节点的时候自增加全局递增的序号
大家去看一下,之前Java架构的分布式锁里,有一个zk锁的源码分析,curator框架,zk分布式锁的实现,在里面就是基于zk的临时顺序节点来实现的,加锁的时候,是创建一个临时顺序节点
zk会自动给你的临时节点加上一个后缀,全局递增的,编号
如果你客户端断开连接了,就自动销毁这个你加的锁,此时人家会感知到,就会尝试去加锁
如果你是做元数据存储,肯定是持久节点
如果你是做一些分布式协调和通知,很多时候是用临时节点,就是说,比如我创建一个临时节点,别人来监听这个节点的变化,如果我断开连接了,临时节点消失,此时人家会感知到,就会来做点别的事情
顺序节点,在分布式锁里用的比较经典
每个znode还有一个Stat用来存放数据版本,version(znode的版本),cversion(znode子节点的版本),aversion(znode的ACL权限控制版本)12144
009_ZooKeeper最核心的一个机制:Watcher监听回调
ZooKeeper最核心的机制,就是你一个客户端可以对znode进行Watcher监听,然后znode改变的时候回调通知你的这个客户端,这个是非常有用的一个功能,在分布式系统的协调中是很有必要的
支持写和查:只能实现元数据存储,Master选举,部分功能
分布式系统的协调需求:分布式架构中的系统A监听一个数据的变化,如果分布式架构中的系统B更新了那个数据/节点,zk反过来通知系统A这个数据的变化
/usr/local/uid
使用zk很简单,内存数据模型(不同节点类型);写数据,主动读取数据;监听数据变化,更新数据,反向通知数据变化
实现分布式集群的集中式的元数据存储、分布式锁、Master选举、分布式协调监听
012_从zk集群启动到数据同步再到崩溃恢复的ZAB协议流程
zk集群启动的时候,进入恢复模式,选举一个leader出来,然后leader等待集群中过半的follower跟他进行数据同步,只要过半follower完成数据同步,接着就退出恢复模式,可以对外提供服务了
只要有超过一半的机器,认可你是leader,你就可以被选举为leader
3台机器组成了一个zk集群,启动的时候,只要有2台机器认可一个人是Leader,那么他就可以成为leader了
3台可以容忍不超过一半的机器宕机,1台
剩余的2台机器,只要2台机器都认可其中某台机器是leader,2台 大于 一半,就可以选举出来一个leader了
zk的leader选举算法,我们可以在后面的zk核心源码剖析的时候
1台机器时没有办法自己选举自己的
5台机器,3台机器认可某个人是leader;可以允许2台机器宕机,3台机器,leader选举,只要是5台机器,一半2.5,3台机器都认可某个人是leader,此时3 > 2.5,过半,leader是可以选举出来的
2台机器,小于一半,没有办法选举新的leader出来了
当然还没完成同步的follower会自己去跟leader进行数据同步的
此时会进入消息广播模式
只有leader可以接受写请求,但是客户端可以随便连接leader或者follower,如果客户端连接到follower,follower会把写请求转发给leader
leader收到写请求,就把请求同步给所有的follower,过半follower都说收到了,就再发commit给所有的follower,让大家提交这个请求事务
如果突然leader宕机了,会进入恢复模式,重新选举一个leader,只要过半的机器都承认你是leader,就可以选举出来一个leader,所以zk很重要的一点是主要宕机的机器数量小于一半,他就可以正常工作
因为主要有过半的机器存活下来,就可以选举新的leader
新leader重新等待过半follower跟他同步,完了重新进入消息广播模式,leader就会把自己的数据开始同步,因为有一种可能之前有些follower没有从leader那边完全同步过来,这个时候一定要保证一个数据的同步,leader会去检查自己磁盘里的文件,去看看哪些数据是哪些follower的,哪些follower还没有同步的,leader要保证自己的数据和其它的follower要保证全部同步,同步守他会进入消息广播模式,leader就会接受写请求了
2PC是什么,两阶段提交,Java架构里的分布式事务的课程,好好去看一下
集群启动:恢复模式,leader选举(过半机器选举机制) + 数据同步
消息写入:消息广播模式,leader采用2PC模式的过半写机制,给follower进行同步
崩溃恢复:恢复模式,leader/follower宕机,只要剩余机器超过一半,集群宕机不超过一半的机器,就可以选举新的leader,数据同步
013_采用了2PC两阶段提交思想的ZAB消息广播流程
每一个消息广播的时候,都是2PC思想走的,先是发起事务Proposal的广播,就是事务提议,仅仅只是个提议而已,各个follower返回ack,过半follower都ack了,就直接发起commit消息到全部follower上去,让大家提交
发起一个事务proposal之前,leader会分配一个全局唯一递增的事务id,zxid,通过这个可以严格保证顺序
leader会为每个follower创建一个队列,里面放入要发送给follower的事务proposal,这是保证了一个同步的顺序性
每个follower收到一个事务proposal之后,就需要立即写入本地磁盘日志中,写入成功之后就可以保证数据不会丢失了,然后返回一个ack给leader,然后过半follower都返回了ack,leader推送commit消息给全部follower
leader自己也会进行commit操作
commit之后,就意味这个数据可以被读取到了
014_停一下脚步:ZooKeeper到底是强一致性还是最终一致性?
强一致性:只要写入一条数据,立马无论从zk哪台机器上都可以立马读到这条数据,强一致性,你的写入操作卡住,直到leader和全部follower都进行了commit之后,才能让写入操作返回,认为写入成功了
此时只要写入成功,无论你从哪个zk机器查询,都是能查到的,强一致性
明显,ZAB协议机制,zk一定不是强一致性
最终一致性:写入一条数据,方法返回,告诉你写入成功了,此时有可能你立马去其他zk机器上查是查不到的,短暂时间是不一致的,但是过一会儿,最终一定会让其他机器同步这条数据,最终一定是可以查到的
研究了ZooKeeper的ZAB协议之后,你会发现,其实过半follower对事务proposal返回ack,就会发送commit给所有follower了,只要follower或者leader进行了commit,这个数据就会被客户端读取到了
那么有没有可能,此时有的follower已经commit了,但是有的follower还没有commit?绝对会的,所以有可能其实某个客户端连接到follower01,可以读取到刚commit的数据,但是有的客户端连接到follower02在这个时间还没法读取到
所以zk不是强一致的,不是说leader必须保证一条数据被全部follower都commit了才会让你读取到数据,而是过程中可能你会在不同的follower上读取到不一致的数据,但是最终一定会全部commit后一致,让你读到一致的数据的
Leader接收写请求,follower有一半有ack响应,就代表发送成功了,发送commit给所有follower,写操作就直接返回了,说明已经成功了,但是如果你写操作成功了以后,有些follower可能commit还没有执行,这一瞬间可能从某个follower中查,查不到数据,只要没有执行commit,就没有在自己znode内存中,但是过一会,中要follower执行了commit之后,一定能从follower里边查到,最新更新的数据
Zk是最终一致性,就不是很准确,因为zk官方给自己的定义是顺序一致性,承认自己的数据不是强一致的,是最终保持一致,最终保持一致的过程中,是通过给每个follower建立一个对队,先进先出,来同步数据,另外给proposal:zxid来递增序号,然后能保证,所有数据的同步都是按照顺序来的,然后按照顺序同步了以后,最终这些数据一定会在各个follower上,然后保持一致这么一个状态,所以在最终一致性上,加入了顺序,面试和别人聊是:保持顺序一致性
zk官方给自己的定义:顺序一致性
因此zk是最终一致性的,但是其实他比最终一致性更好一点,出去要说是顺序一致性的,因为leader一定会保证所有的proposal同步到follower上都是按照顺序来走的,起码顺序不会乱
但是全部follower的数据一致确实是最终才能实现一致的
如果要求强一致性,可以手动调用zk的sync()操作
015_ZAB协议下两种可能存在的数据一致性问题
Leader收到了过半的follower的ack,接着leader自己commit了,还没来得及发送commit给所有follower自己就挂了,这个时候相当于leader的数据跟所有follower是不一致的,你得保证全部follower最终都得commit
另外一个,leader可能会自己收到了一个请求,结果没来得及发送proposal给所有follower之前就宕机了,此时这个Leader上的请求应该是要被丢弃掉的
所以在leader崩溃的时候,就会选举一个拥有事务id最大的机器作为leader,他得检查事务日志,如果发现自己磁盘日志里有一个proposal,但是还没提交,说明肯定是之前的leader没来得及发送commit就挂了
此时他就得作为leader为这个proposal发送commit到其他所有的follower中去,这个就保证了之前老leader提交的事务已经会最终同步提交到所有follower里去
然后对于第二种情况,如果老leader自己磁盘日志里有一个事务proposal,他启动之后跟新leader进行同步,发现这个事务proposal其实是不应该存在的,就直接丢弃掉就可以了
016_崩溃恢复时选举出来的Leader是如何跟其他Follower进行同步的、
新选举出来一个leader之后,本身人家会挑选已经收到的事务zxid里最大的那个follower作为新的leader。
5个机器,1leader + 4个follower
1个leader把proposal发送给4个follower,其中3个folower(过半)都收到了proposal返回ack了,第四个follower没收到proposal
此时leader执行commit之后自己挂了,commit没法送给其他的follower,commit刚发送给一个follower
剩余的4个follower,只要3个人投票一个人当leader,就是leader
假设那3个收到proposal的follower都投票第四台没有收到proposal的follower当心的leader?这条数据一定永久性丢失了
选择一个拥有事务zxid最大的机器作为新Leader
其他的follower就会跟他进行同步,他给每个follower准备一个队列,然后把所有的proposal都发送给follower,只要过半follower都ack了,就会发送commit给那个follower
所谓的commit操作,就是把这条数据加入内存中的znode树形数据结构里去,然后就对外可以看到了,也会去通知一些监听这个znode的人
如果一个follower跟leader完全同步了,就会加入leader的同步follower列表中去,然后过半follower都同步完毕了,就可以对外继续提供服务了
017_对于需要丢弃的消息是如何在ZAB协议中进行处理的?
每一条事务的zxid是64位的,高32位是leader的epoch,就认为是leader的版本吧;低32位才是自增长的zxid
老leader发送出去的proposal,高32位是1,低32位是11358
如果一个leader自己刚把一个proposal写入本地磁盘日志,就宕机了,没来得及发送给全部的follower,此时新leader选举出来,他会的epoch会自增长一位
proposal,高32位是2,低32位是继续自增长的zxid
然后老leader恢复了连接到集群是follower了,此时发现自己比新leader多出来一条proposal,但是自己的epoch比新leader的epoch低了,所以就会丢弃掉这条数据
启动的时候,过半机器选举leader,数据同步
对外提供服务的时候,2PC + 过半写机制,顺序一致性(最终的一致性)
崩溃恢复,剩余机器过半,重新选举leader,有数据不一致的情况,针对两种情况自行进行处理,保证数据是一致的(磁盘日志文件、zxid的高32位)
018_现在再来看看ZooKeeper的Observer节点是用来干什么的?
Observer节点是不参与leader选举的,他也不参与ZAB协议同步时候的过半follower ack的那个环节,他只是单纯的接收数据,同步数据,可能数据存在一定的不一致的问题,但是是只读的
leader在进行数据同步的时候,observer是不参与到过半写机制里去
所以大家思考一个问题了
zk集群无论多少台机器,只能是一个leader进行写,单机写入最多每秒上万QPS,这是没法扩展的,所以zk是适合写少的场景
但是读呢?follower起码有2个或者4个,读你起码可以有每秒几万QPS,没问题,那如果读请求更多呢?此时你可以引入Observer节点,他就只是同步数据,提供读服务,可以无限的扩展机器121440480
二、使用步骤
1.引入库
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。







