
spark 少量key倾斜的join优化
温馨提示:这篇文章已超过387天没有更新,请注意相关的内容是否还可用!
背景
在使用spark join时,我们经常遇到少量key拥有大量的数据而导致的数据倾斜的问题,这导致了task任务数据处理非常不均匀而影响最终时效
少量key数据倾斜的join优化
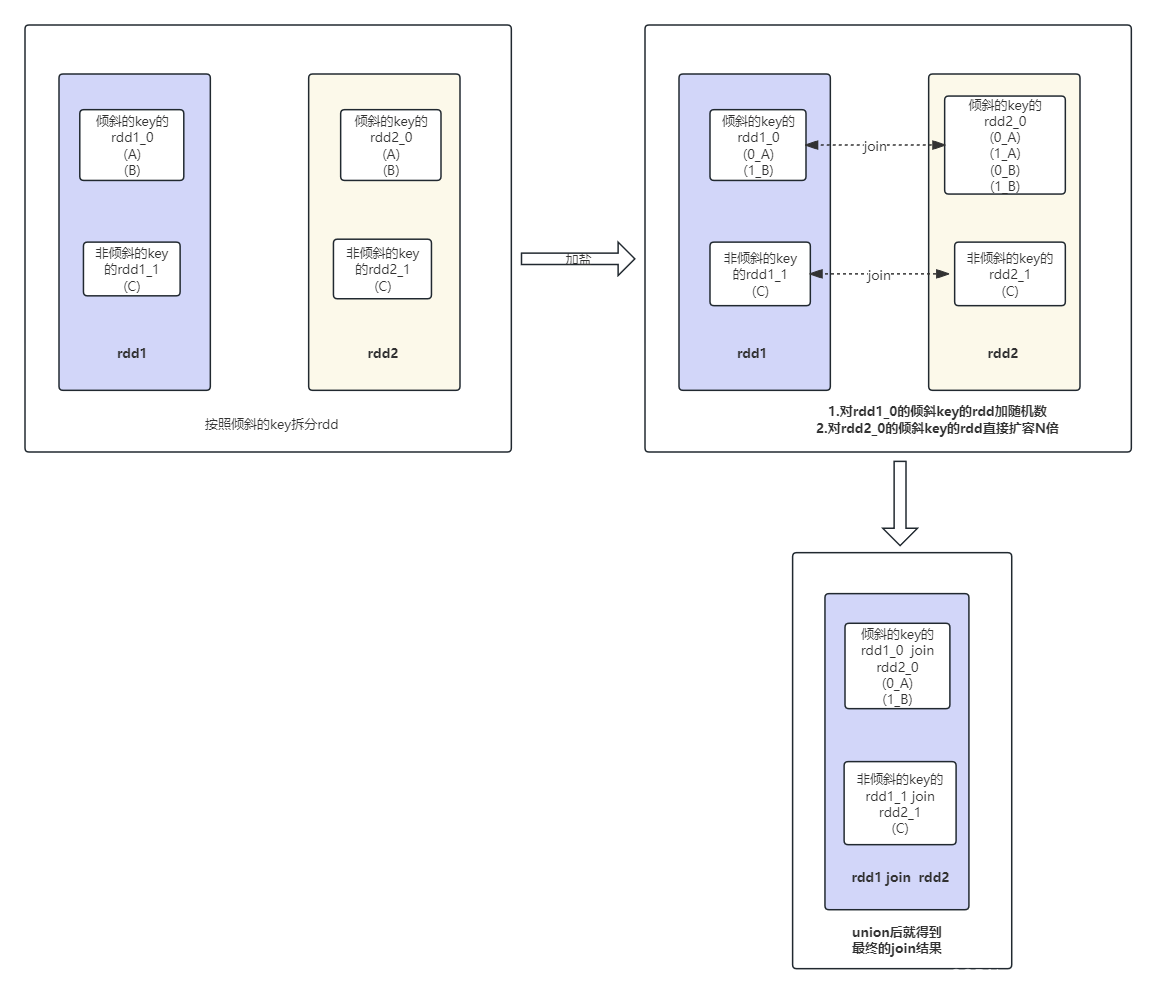
这里有一个前提,join的另一边的表没有数据倾斜问题,也就是rdd2没有数据倾斜,然后处理的主要思路还是把这些倾斜的key单独抽取出来形成一个单独的rdd1_0,join的另一边也是把这些倾斜的key单独的抽取出来形成一个单独的rdd2_0,对于剩下的非倾斜的rdd1_1和rdd2_1,直接join即可,然后我们再来看怎么处理倾斜的rdd1_0,我们这里可以对rdd1_0加上一个随机数(0~n),然后对另一边的rdd2_0扩容n倍,由于rdd2_0只包含倾斜的key的数据,所以扩容n倍的内存消耗可以接受。
详细流程图如下所示:
参考文献: https://zhuanlan.zhihu.com/p/22024169
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



