“目标检测”任务基础认识



“目标检测”任务基础认识
1.目标检测初识
目标检测任务关注的是图片中特定目标物体的位置。
目标检测最终目的:检测在一个窗口中是否有物体。
eg:以猫脸检测举例,当给出一张图片时,我们需要框出猫脸的位置并给出猫脸的大小,如下图所示。

2.一个检测任务包含两个子任务
- 一个是分类任务:输出这一目标的类别信息(分类标签);
- 另一个是定位任务:输出目标的具体位置信息(用矩形框表示,包含矩形框左上角或中间位置的x、y坐标和矩形框的宽度与高度)。
3.算法发展历程
与计算机视觉领域里大部分的算法一样,目标检测也经历了从传统的人工设计特征加浅层分类器的方案,到基于深度学习的端到端学习方案的演变。而在深度学习中,很多任务都是采用**端到端(end-to-end)**的方案,即输入一张图,输出最终想要的结果,算法细节和学习过程全部交给神经网络,这一点在目标检测领域体现得非常明显。
4.目标检测步骤
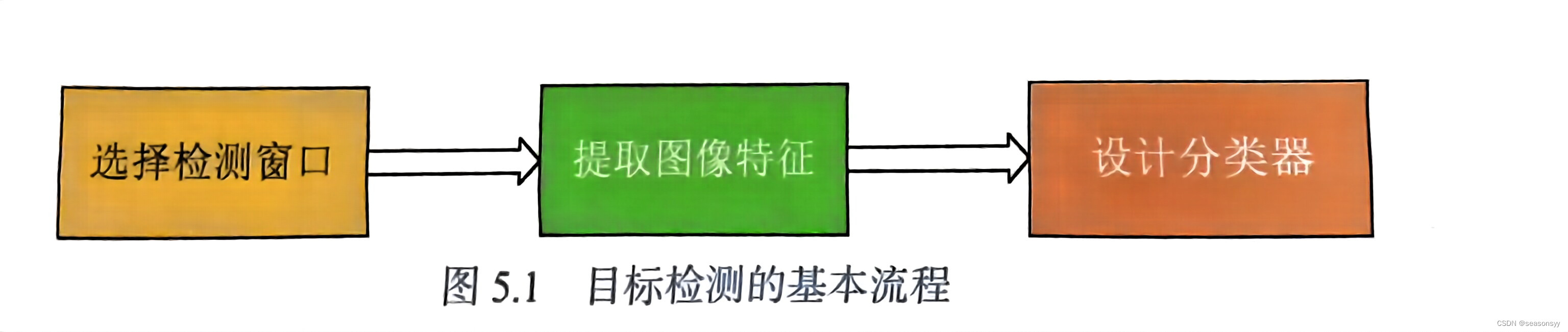
不管是用清晰的分步骤处理还是用深度学习的end-to-end方法完成一个目标检测任务,一个系统一定会遵循3个步骤。
如图5.1所示。
- 第一步选择检测窗口
- 第二步提取图像特征
- 第三步设计分类器
4.1检测窗口选择
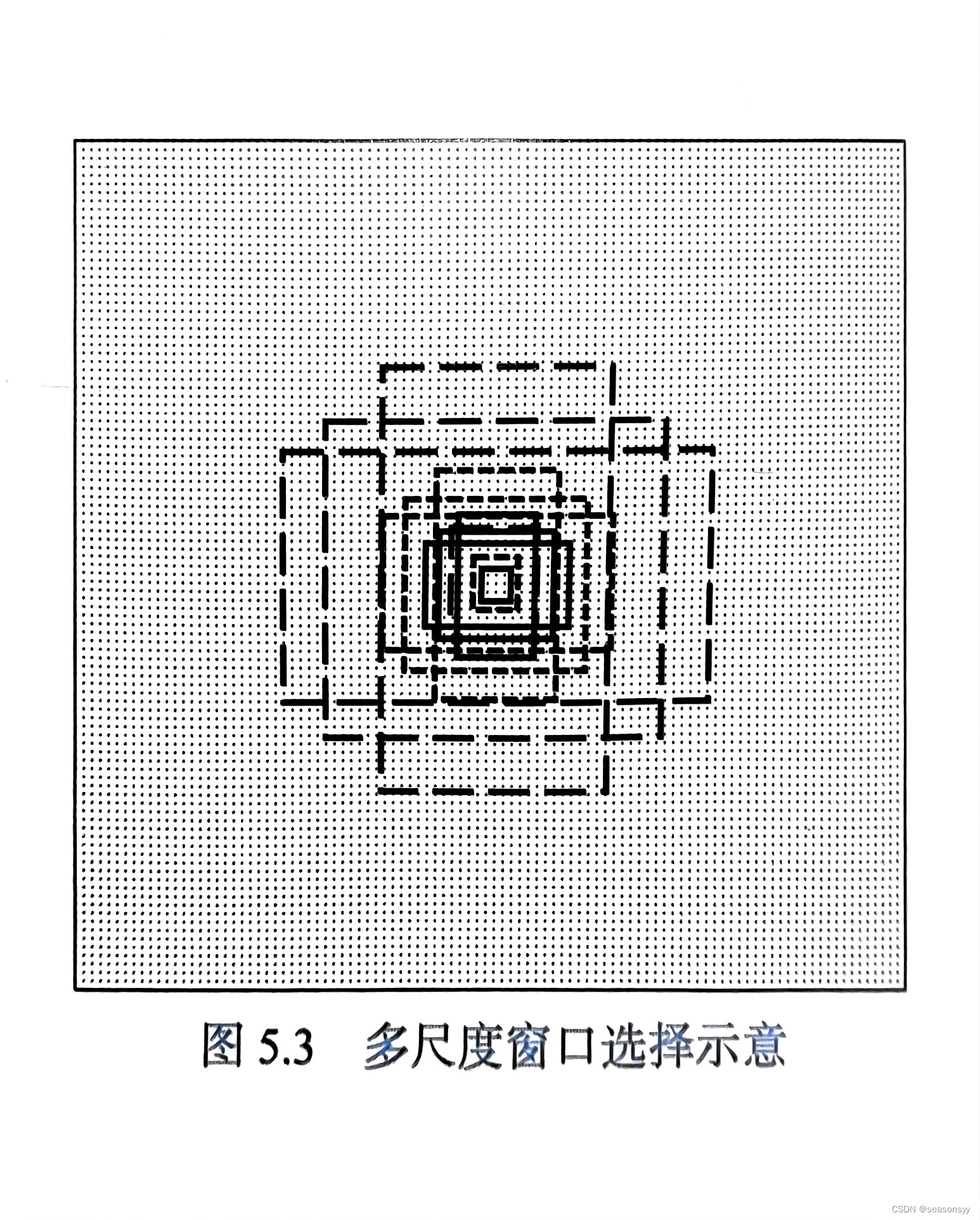
- 方法:当在不同的距离下检测不同大小的目标时,最简单也最直观的方法就是用图像金字塔+各种尺度比例的框进行暴力搜索:从左到右,从上到下滑动窗口,然后利用分类方法对目标框进行识别。
- 问题:如图5.3所示,在一个像素点处选择了长宽比例不同的框。这种利用窗口滑动来确定候选框的方法可以实现我们的预期目标,但是不难想到,这种方法在使用过程中会产生大量的无效窗口,浪费了很多计算资源,而且无法得到精确的位置。目标检测想要得到发展,必须优化这个步骤。
4.2特征提取
有了候选窗口后,需要提取图像的特征进行表达,传统的有监督方法和以CNN为代表的无监督特征学习方法都可以派上用场。
仍然以人脸检测算法为例,在传统的人脸检测算法中,有几类特征是经常被使用的。
Haar特征 LBP特征 HOG特征 定位 是经典的V-J框架使用的基本特征 是传统人脸检测算法中广泛使用的纹理特征 在物体检测领域应用非常广泛 表达 表征的是局部的明暗对比关系 可以表达物体丰富的纹理信息 特点 由于Haar 特征提取速度快,能够表达物体多个方向的边缘变化信息,并且可以利用积分图进行快速计算,因此得到了广泛应用 采用中心像素和边缘像素的灰度对比,可以表达物体丰富的纹理信息,同时因为使用的是相对灰度值,因此对均匀变化的光照有很好的适应性。 通过对物体边缘进行直方图统计来实现编码,相对于Haar 和LBP 两个特征,HOG 的特征表达能力更强、更加通用,被广泛用于物体检测、跟踪和识别等领域 - 除了以上常用的特征外,还有其他非常优秀的传统特征描述,包括SIFT 和SURF等,这些都是研究人员通过长时间的学术研究和实际项目验证得来的,虽然在比较简单的任务中可以取得很好的结果,但是设计成本很高。
- 传统的检测算法通过对不同的特征进行组合调优,从而增加表达能力。
- 其中以ACF为代表的行人检测方法,组合了20多种不同的传统图像特征。
4.3分类器
分类器是目标检测的最后一步,经常使用的分类器有Adaboost、SVM 和Decision Tree等。接下来对这些分类器进行简要介绍。
1. Adaboost分类器
- Adaboost是一种迭代的分类方法,在OpenCV开源库中使用的人脸检测框架的分类器正是Adaboost 分类器。
- 核心思想:在很多情况下,一个弱分类器的精度并不高,Adaboost算法的核心思想就是在很多分类器中,自适应地挑选其中分类精度更高的弱分类器,并将其进行组合,从而实现一个更强的分类器。
Eg:
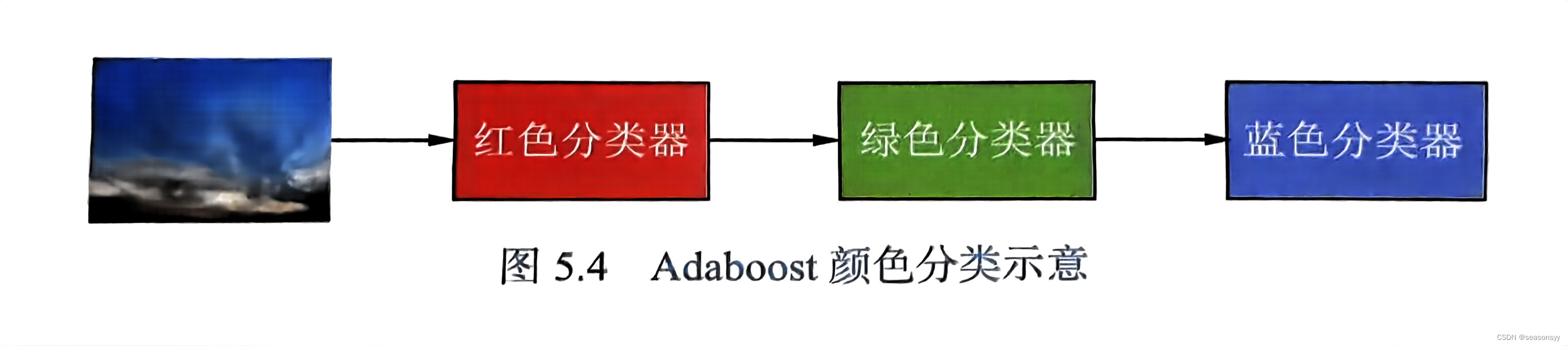
目标:当我们要检测一个纯红色的物体时,它的颜色为(255,0,0),但是现在只有3个灰度级别的分类器,各自对应RGB的3种颜色。我们知道,所要检测的物体必须满足3个条件,R 通道灰度值为255,G、B的通道灰度值为0。
问题:此时,使用任何一个灰度级别的分类器都无法完成这个任务,同时会出现很多的误检。例如红色分类器,在最理想的情况下就是学习到了R 的通道必须为255,但是G、B通道学习不到,因此它会检测到1×256×256种颜色,其中,256×256-1种为误检,检测精度为1/(256×256),等于0.0000152。
解决:当我们组合3种分类器,并使其各自达到最好的学习状态时,就可以完全学习到R=255、G=0、B=0这样的特征。我们在实际使用这3个分类器的时候,可以使用串联的方法让图片依次经过3个分类器进行分类过滤,如图5.4所示。
结果:这样虽然每一个弱分类器的检测精度不到万分之一,但最终的检测精度可以是100%,这就是Adaboost算法的核心思想。
总结:Adaboost通过弱弱联合实现了强分类器,在使用的时候通常采用顺序级连的方案。
- 在级联分类器的前端:是速度较快、性能较弱的分类器,它们可以实现将大部分负样本进行过滤。
- 在级联的后端:是速度较慢、性能较强的分类器,它们可以实现更大计算量,精度也更高的检测。
2. SVM分类器(简略介绍)
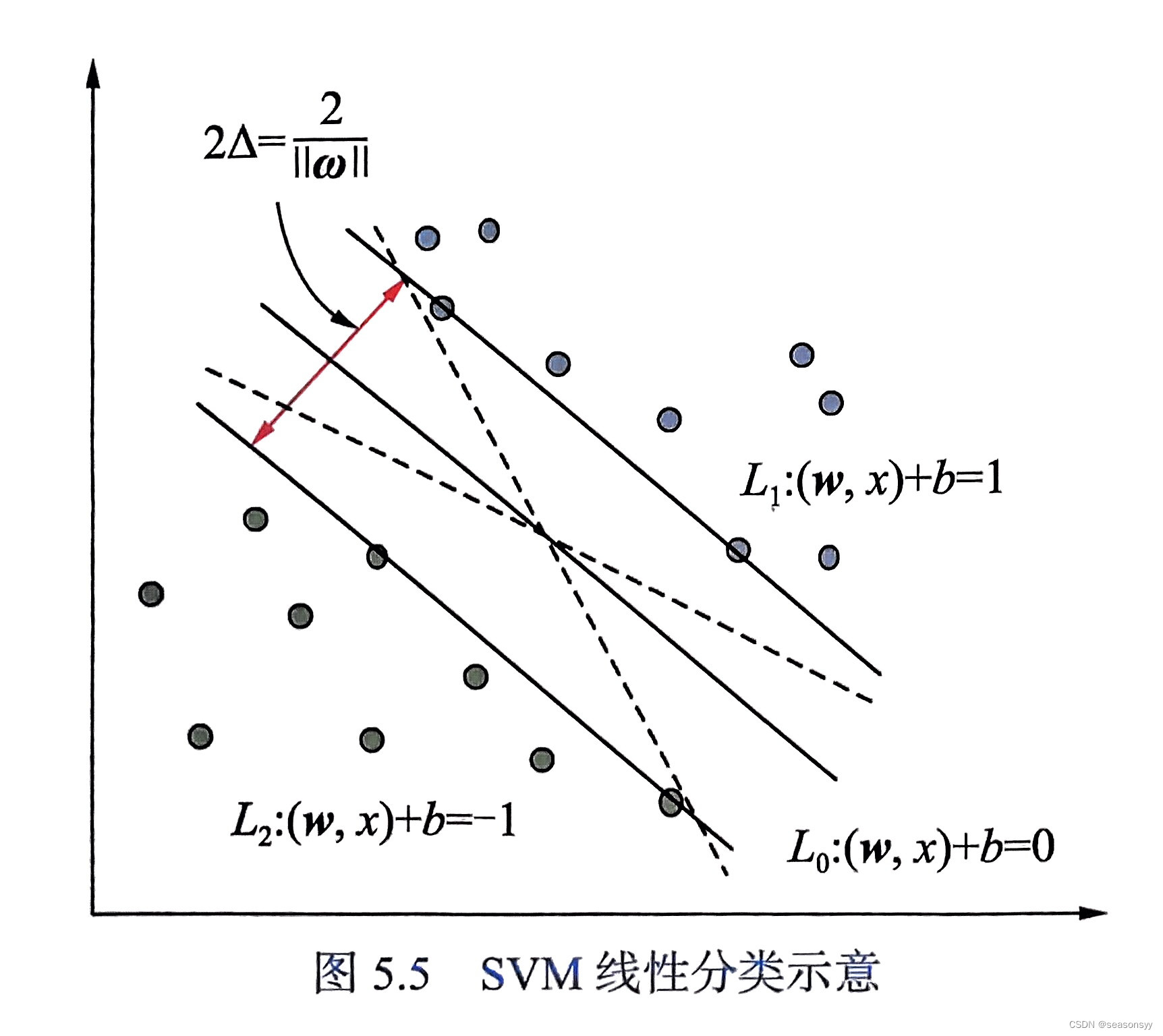
支持向量机(Support Vector Machine,SVM)是贝尔实验室的Vapnik 等研究人员在对统计学习理论进行了三十多年研究的基础上提出来的机器学习算法,它让统计学习理论第一次对实际应用产生了重大影响,具有非常重要的意义。
SVM 是基于统计学习VC理论与结构风险极小化原理的算法,它将基于最大化间隔获得的分类超平面思想与基于核技术的方法结合在一起,通过部分数据构建模型,对新的数据进行预测并作出分类决策,表现出了很好的泛化能力。
SVM还可以通过引入核函数将低维映射到高维,从而将很多线性不可分的问题转化为线性可分问题,这在图像分类领域中的应用非常广泛。以SVM 为分类器和HOG 为特征的行人检测系列算法是其中非常经典的算法。
3.Decision Tree决策树
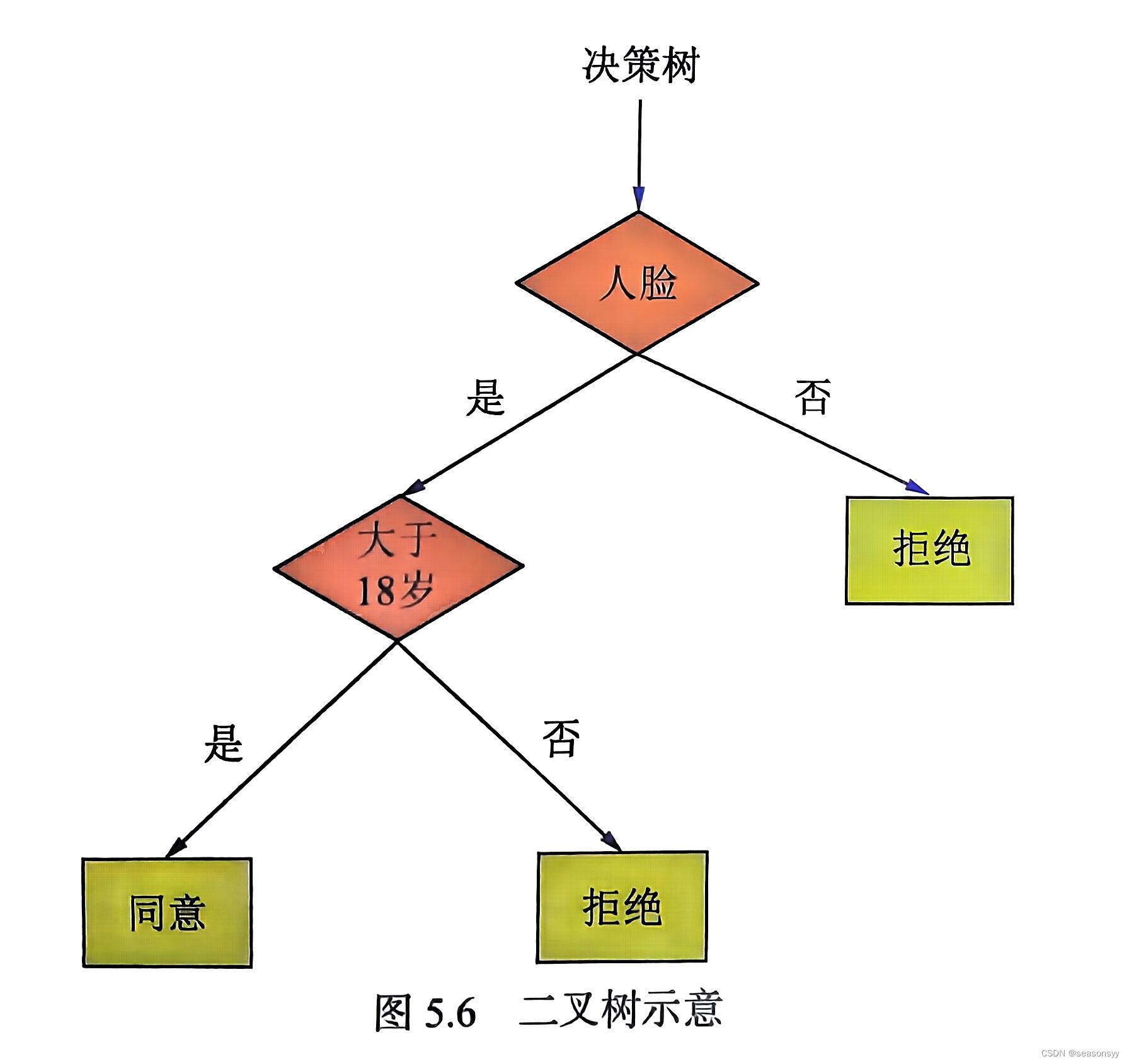
决策树是一种树形结构,每个内部节点都表示一个属性测试,每个分支都会输出测试结果,每个叶子节点代表一种类别。
Eg:以图5.6所示的二叉树为例,从树根开始分叉,区分是人脸或者非人脸,左边是人脸,右边是非人脸。当进入第一个二叉树分类器节点判断为非人脸时,则直接输出结果,结束任务;如果是人脸,则进入下一层再进行判断。二叉树通过学习每个节点的分类器来构造决策树,最终形成一个强分类器,总体的思路与级联分类器非常相似。
改进:为了提升决策树的能力,我们可以对决策树进行集成,也就是将其组合成随机森林。假设刚刚提到的决策树是一棵树,对于人脸检测这样的任务,分别学习10棵树,每棵树采用不同的输入或者特征,最终以10棵树的分类结果进行投票,获取多数表决的结果将作为最终的结果,这是一种非常简单但行之有效的方法。
在使用深度学习来完成各项任务尤其是参加各类比赛的时候,一定会使用不同的模型和不同的输入进行集成。例如,常见的是使用不同裁剪子区域进行预测,或者使用不同的基准模型进行预测,最后取平均概率的方法,测试结果相比之前可以得到很大的提升。
参考文献:
《深度学习之图像识别 核心算法与实战案例 (全彩版)》 言有三 著
出版社:清华大学出版社
出版时间:2023年7月第一版(第一次印刷)
ISBN:978-7-302-63527-7
- 其中以ACF为代表的行人检测方法,组合了20多种不同的传统图像特征。