
Python pandas 操作 excel 详解
温馨提示:这篇文章已超过438天没有更新,请注意相关的内容是否还可用!
文章目录
- 1 概述
- 1.1 pandas 和 openpyxl 区别
- 1.2 Series 和 DataFrame
- 2 常用操作
- 2.1 创建 Excel:to_excel()
- 2.2 读取 Excel:read_excel()
- 2.2.1 header:标题的行索引
- 2.2.2 index_col:索引列
- 2.2.3 dtype:数据类型
- 2.2.4 skiprows:跳过的行数
- 2.2.5 usercols:指定列数
- 2.2.6 head(n)、tail(n):读取前、后 n 行数据
- 2.3 读写数据
- 2.3.1 at():获取单元格
- 2.3.2 loc[]:数据筛选
- 2.3.3 sort_values():数据排序
- 3 实战
- 3.1 遍历 Excel
1 概述
1.1 pandas 和 openpyxl 区别
- Python 中的 pandas 和 openpyxl 库,均可以处理 excel 文件,其中主要区别:
- pandas:① 数据操作和分析方面表现优异。它提供了各种文件格式(包括 Excel)中读取数据的函数,在过滤数据、汇总数据、处理缺失值和执行其它数据转换任务方便,特别有用。② 使用方便。DataFrame 对象,使用快速方便,且功能十分强大。
- openpyxl:侧重单元格格式设置。这个库也允许我们直接处理 Excel 文件。pandas 快,但 pandas 做不了的事情,可以让 openpyxl 来做,例如:单元格注释、填充背景色 等等
1.2 Series 和 DataFrame
- Series:连续。可理解为 “一维数组”,由一行 或 一列 组成,具体是行,还是列,由 DataFrame 指定
- DataFrame:数据框。可理解为 “二维数组”,由行和列组成
import pandas as pd # Series 示例 s = pd.Series(['a', 'b', 'c'], index=[1, 2, 3], name='A') print(s) # 1 a # 2 b # 3 c # Name: A, dtype: object # DataFrame 示例 s1 = pd.Series(['a', 'b', 'c'], index=[1, 2, 3], name='A') s2 = pd.Series(['aa', 'bb', 'cc'], index=[1, 2, 3], name='B') s3 = pd.Series(['aaa', 'bbb', 'ccc'], index=[1, 2, 3], name='C') # 方式1:指定 Series 为行 df = pd.DataFrame([s1, s2, s3]) print(df) # 1 2 3 # A a b c # B aa bb cc # C aaa bbb ccc # 方式2:指定 Series 为列 df = pd.DataFrame({s1.name: s1, s2.name: s2, s3.name: s3}) print(df) # A B C # 1 a aa aaa # 2 b bb bbb # 3 c cc ccc2 常用操作
2.1 创建 Excel:to_excel()
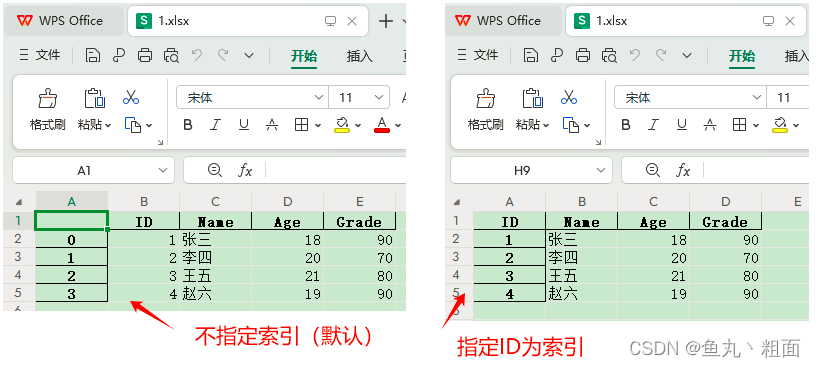
import pandas as pd # 测试数据 data = {'ID': [1, 2, 3], 'Name': ['张三', '李四', '王五']} # 1.创建 DataFrame 对象 df = pd.DataFrame(data=data) # 可选操作。将 ID 设为索引,若不设置,会使用默认索引 narray(n) df = df.set_index('ID') # 写法1 # df.set_index('ID', inplace=True) # 写法2 # 2.写入 excel 至指定位置(若文件已存在,则覆盖) df.to_excel(r'C:\Users\Administrator\Desktop\Temp\1.xlsx')指定索引前后,效果对比:
2.2 读取 Excel:read_excel()
import pandas as pd # 1.读取 excel。默认读取第一个 sheet student = pd.read_excel(r'C:\Users\Administrator\Desktop\Temp\1.xlsx') # 2.读取常用属性 print(student.shape) # 形状(行,列) print(student.columns) # 列名
读取指定 sheet:
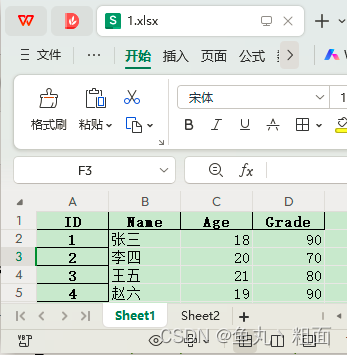
import pandas as pd # 1.读取指定 sheet 的 excel,以下两种方式等同 student = pd.read_excel(r'C:\Users\Administrator\Desktop\Temp\1.xlsx', sheet_name=1) # student = pd.read_excel(r'C:\Users\Administrator\Desktop\Temp\1.xlsx', sheet_name='Sheet2') # 2.读取常用属性 print(student.shape) # 形状(行,列) print(student.columns) # 列名
2.2.1 header:标题的行索引
场景1:默认。第一行为标题(行索引为 0,即:header=0)
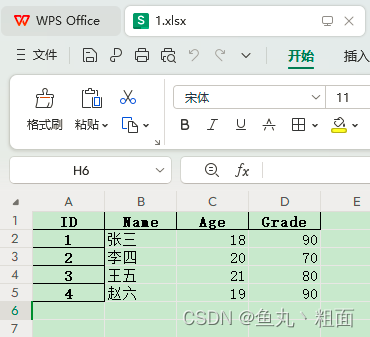
import pandas as pd # 文件路径 filePath = r'C:\Users\Administrator\Desktop\Temp\1.xlsx' # 1.读取 excel(默认第 1 行为标题,行索引为 0,即:header=0) student = pd.read_excel(filePath) print(student.columns) # Index(['ID', 'Name', 'Age', 'Grade'], dtype='object')
场景2:指定第 n 行为标题
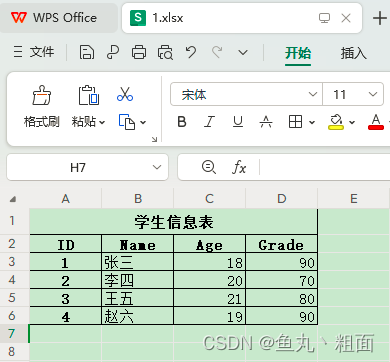
import pandas as pd # 文件路径 filePath = r'C:\Users\Administrator\Desktop\Temp\1.xlsx' # 场景2:excel 中第 2 行才是我们想要的标题(即:header=1) student = pd.read_excel(filePath, header=1) print(student.columns) # Index(['ID', 'Name', 'Age', 'Grade'], dtype='object')
场景3:没有标题,需要人为给定
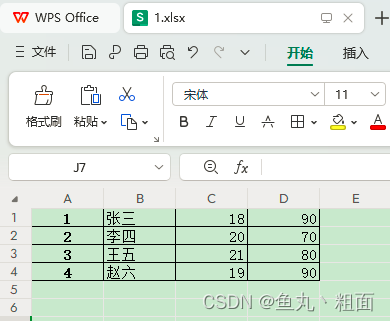
import pandas as pd # 文件路径 filePath = r'C:\Users\Administrator\Desktop\Temp\1.xlsx' # 场景3:excel 中没有标题,需要人为设定 student = pd.read_excel(filePath, header=None) student.columns = ['ID', 'Name', 'Age', 'Grade'] student.set_index('ID', inplace=True) # 指定索引列,并替换原数据 student.to_excel(filePath) # 写入至 Excel print(student) # Name Age Grade # ID # 1 张三 18 90 # 2 李四 20 70 # 3 王五 21 80 # 4 赵六 19 902.2.2 index_col:索引列
import pandas as pd # 文件路径 filePath = r'C:\Users\Administrator\Desktop\Temp\1.xlsx' # 读取 Excel,不指定索引列(会默认新增一个索引列,从 0 开始) student = pd.read_excel(filePath) print(student) # ID Name Age Grade # 0 1 张三 18 90 # 1 2 李四 20 70 # 2 3 王五 21 80 # 3 4 赵六 19 90 # 读取 Excel,指定索引列 student = pd.read_excel(filePath, index_col='ID') print(student) # Name Age Grade # ID # 1 张三 18 90 # 2 李四 20 70 # 3 王五 21 80 # 4 赵六 19 90
索引相关:
import pandas as pd # 文件路径 filePath = r'C:\Users\Administrator\Desktop\Temp\1.xlsx' # 1.读取 excel,并指定索引列 student = pd.read_excel(filePath, index_col='ID')
2.2.3 dtype:数据类型
import pandas as pd # 文件路径 filePath = r'C:\Users\Administrator\Desktop\Temp\1.xlsx' # 1.读取 excel 并指定 数据类型 student = pd.read_excel(filePath, dtype={'ID': str, 'Name': str, 'Age': int, 'Grade': float}) print(student) # ID Name Age Grade # 0 1 张三 18 90.0 # 1 2 李四 20 70.0 # 2 3 王五 21 80.0 # 3 4 赵六 19 90.02.2.4 skiprows:跳过的行数
- 比如:Excel 中有空行,如下图
- 实际的数据是在第 3 行,所以要跳过前 2 行
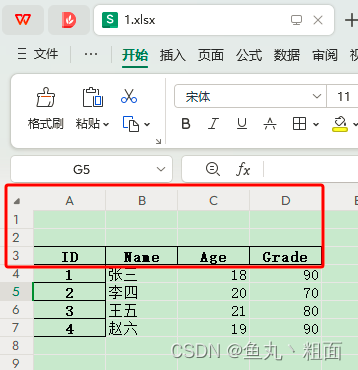
import pandas as pd # 文件路径 filePath = r'C:\Users\Administrator\Desktop\Temp\1.xlsx' student = pd.read_excel(filePath, skiprows=2) print(student) # ID Name Age Grade # 0 1 张三 18 90 # 1 2 李四 20 70 # 2 3 王五 21 80 # 3 4 赵六 19 90
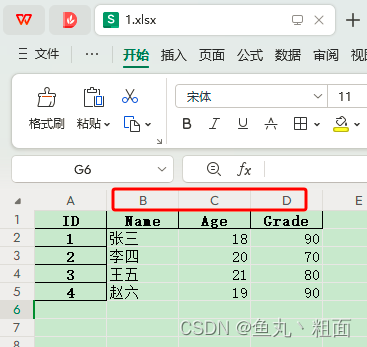
2.2.5 usercols:指定列数
import pandas as pd # 文件路径 filePath = r'C:\Users\Administrator\Desktop\Temp\1.xlsx' # 读取 Excel B - D 列(均包含) student = pd.read_excel(filePath, usecols='B:D') print(student) # Name Age Grade # 0 张三 18 90 # 1 李四 20 70 # 2 王五 21 80 # 3 赵六 19 90
2.2.6 head(n)、tail(n):读取前、后 n 行数据
- 有时候,excel 数据量很大,读取全部会很耗时,也没必要
- 咱测试时,仅读取部分行即可
import pandas as pd # 1.读取 excel student = pd.read_excel(r'C:\Users\Administrator\Desktop\Temp\1.xlsx') # 读取前 3 行数据(默认 5 行) print(student.head(3)) # 读取后 3 行数据(默认 5 行) print(student.tail(3))
2.3 读写数据
2.3.1 at():获取单元格
import pandas as pd # 文件路径 filePath = r'C:\Users\Administrator\Desktop\Temp\1.xlsx' # 1.读取 excel 并指定 索引 student = pd.read_excel(filePath, index_col=None) for i in person.index: # 读写单元格:ID列,i行 的数据 student['ID'].at[i] = i + 2 print(student)2.3.2 loc[]:数据筛选
import pandas as pd def age_18_to_20(age): return 18
- Python 中的 pandas 和 openpyxl 库,均可以处理 excel 文件,其中主要区别:
- 3.1 遍历 Excel
免责声明:我们致力于保护作者版权,注重分享,被刊用文章因无法核实真实出处,未能及时与作者取得联系,或有版权异议的,请联系管理员,我们会立即处理! 部分文章是来自自研大数据AI进行生成,内容摘自(百度百科,百度知道,头条百科,中国民法典,刑法,牛津词典,新华词典,汉语词典,国家院校,科普平台)等数据,内容仅供学习参考,不准确地方联系删除处理! 图片声明:本站部分配图来自人工智能系统AI生成,觅知网授权图片,PxHere摄影无版权图库和百度,360,搜狗等多加搜索引擎自动关键词搜索配图,如有侵权的图片,请第一时间联系我们,邮箱:ciyunidc@ciyunshuju.com。本站只作为美观性配图使用,无任何非法侵犯第三方意图,一切解释权归图片著作权方,本站不承担任何责任。如有恶意碰瓷者,必当奉陪到底严惩不贷!



