python中正则表达式的使用详解(相当全面)
温馨提示:这篇文章已超过428天没有更新,请注意相关的内容是否还可用!
文章目录
- python中的正则表达式
- 正则表达式定义和作用
- 正则表达式 - 匹配单个字符
- (1) 预定义字符集
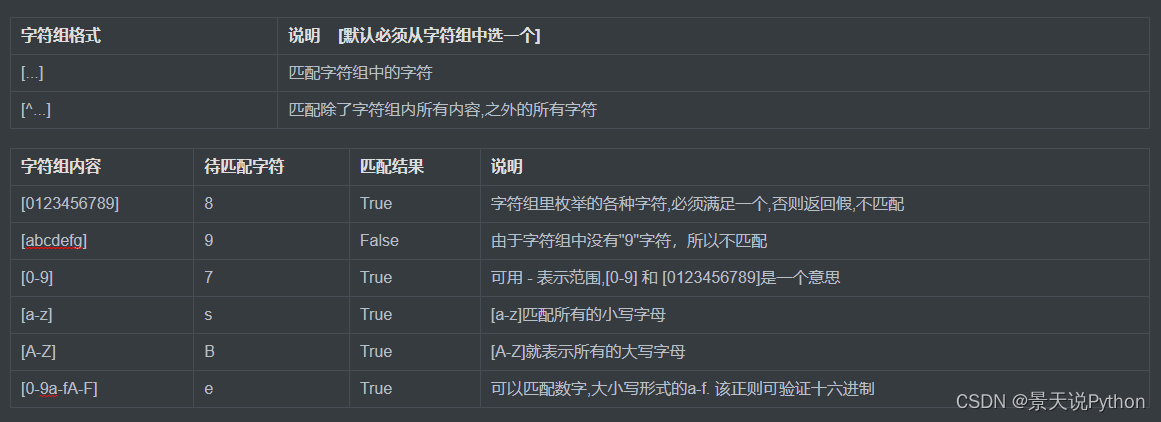
- (2) 字符组 [] 匹配出字符组当中列举的字符(从字符组里面挑一个)
- (3)匹配多个字符,量词放在要匹配的字符之后
- (4)匹配分组 ()表达整体
- (5)search反向引用
- (6)命名分组
- (7)正则函数
python中的正则表达式
正则表达式定义和作用
#正则表达式是什么?
它是约束字符串匹配某种形式的规则
#正则表达式有什么用?
1.检测某个字符串是否符合规则.比如:判断手机号,身份证号是否合法
2.提取网页字符串中想要的数据.比如:爬虫中,提取网站天气,信息,股票代码,星座运势等具体关键字
正则只能匹配字符串格式,不能判断逻辑,判断逻辑要通过代码去实现
#在线测试工具 http://tool.chinaz.com/regex/
该网站,可以在线验证正则表达式是否达到目的
正则表达式所包含的元素种类
#正则表达式由一些 [普通字符] 和一些 [元字符] 组成:
(1)普通字符包括大小写字母和数字
(2)元字符具有特殊含义,大体种类分为如下:
1.预定义字符集,字符组
2.量词
3.边界符
4.分组
正则表达式 - 匹配单个字符
导入模块
import re
“”“lst = re.findall(正则表达式,字符串)”“”
该方法返回的是个列表,把所有满足条件的字符放到列表,将列表返回
finditer返回的是迭代器,遍历打印出来的re.Match对象
. 匹配除了换行符外的任意单个字符
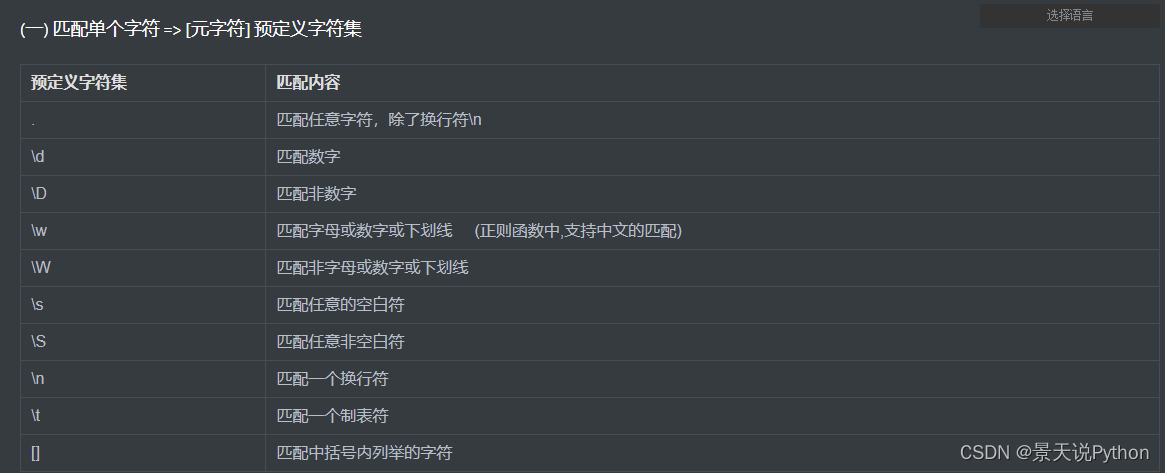
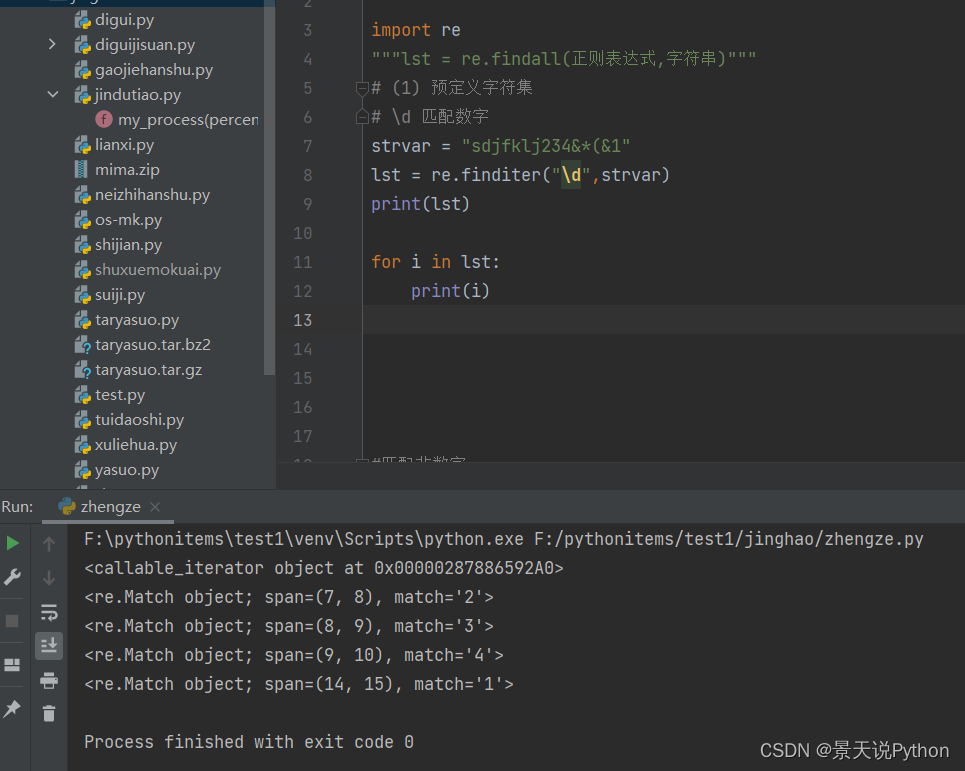
(1) 预定义字符集
#\d 匹配数字
strvar = “sdjfklj234&*(&1”
lst = re.findall(“\d”,strvar)
print(lst)
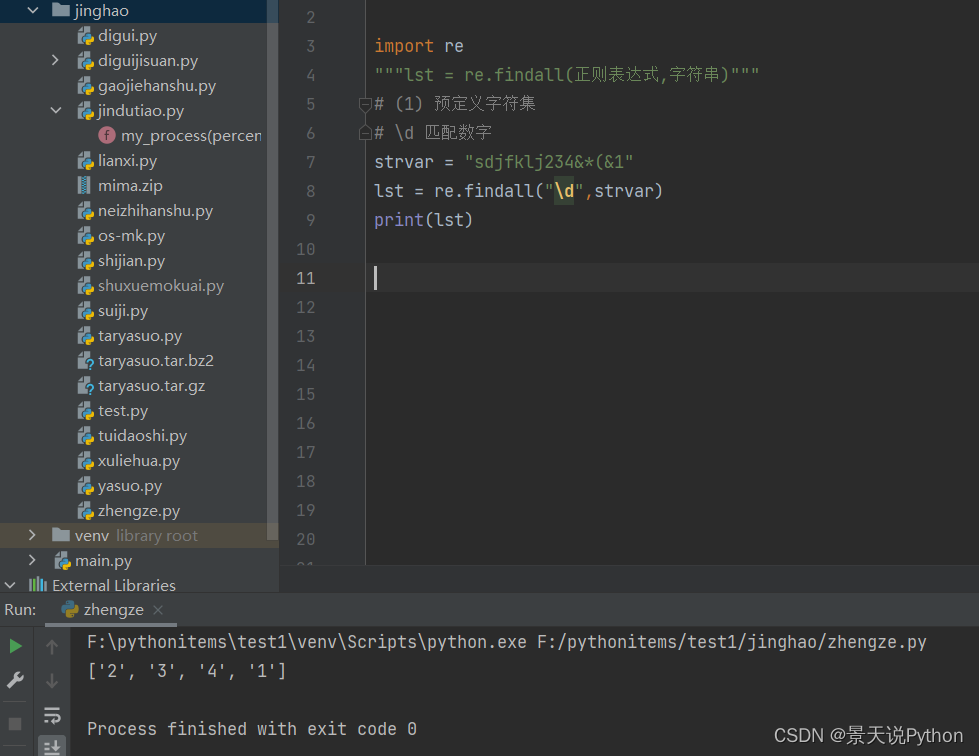
#\D 匹配非数字
strvar = “YWERsdf78_&”
lst = re.findall(“\D”,strvar)
print(lst)
#\w 匹配字母或数字或下划线,python这里包含中文,正则表达式网站这个匹配规则匹配不到中文 (正则函数中,支持中文的匹配)
strvar = “sadf234_^&*%KaTeX parse error: Expected group after '^' at position 1: ^̲%你好”
lst = re.findall(“\w”,strvar)
print(lst)
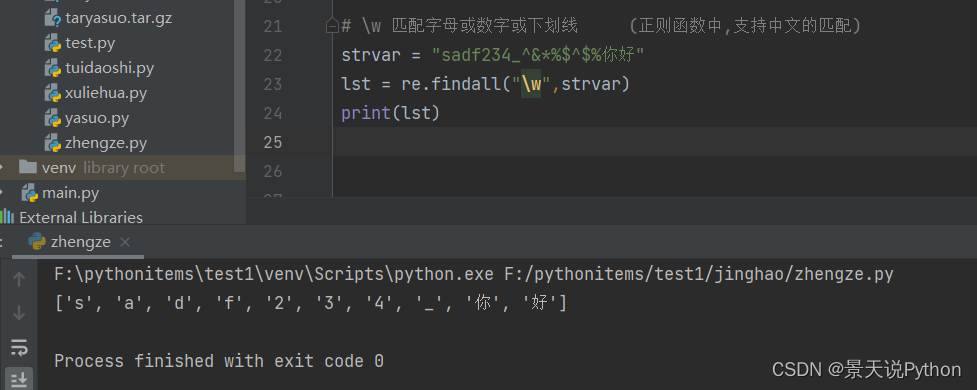
\w 在正则表达式网站匹配不到中文
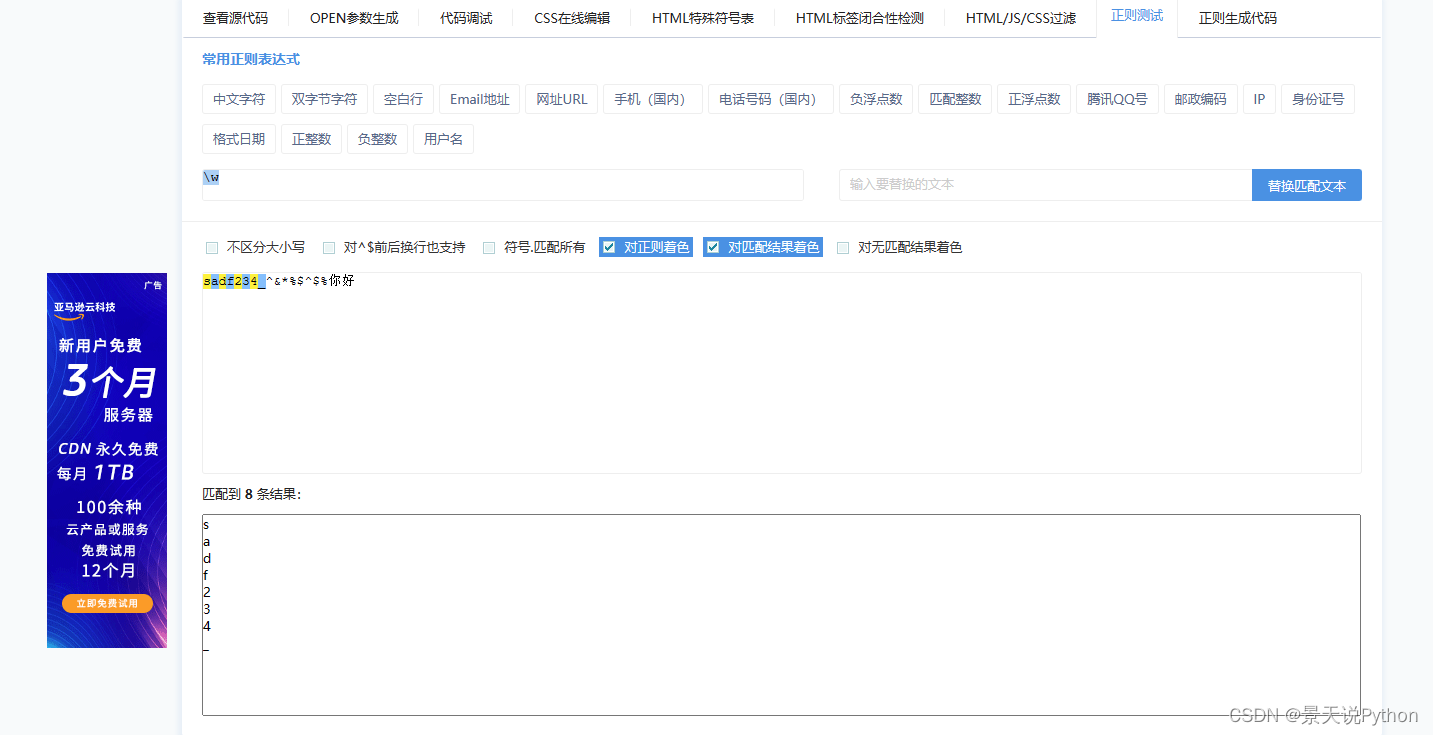
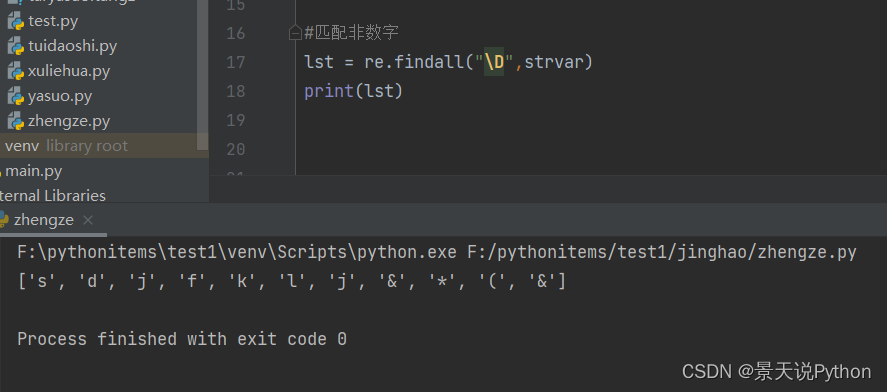
#\W 匹配非字母或数字或下划线
strvar = “sadf234_^&*%KaTeX parse error: Expected group after '^' at position 1: ^̲%你好”
lst = re.findall(“\W”,strvar)
print(lst)
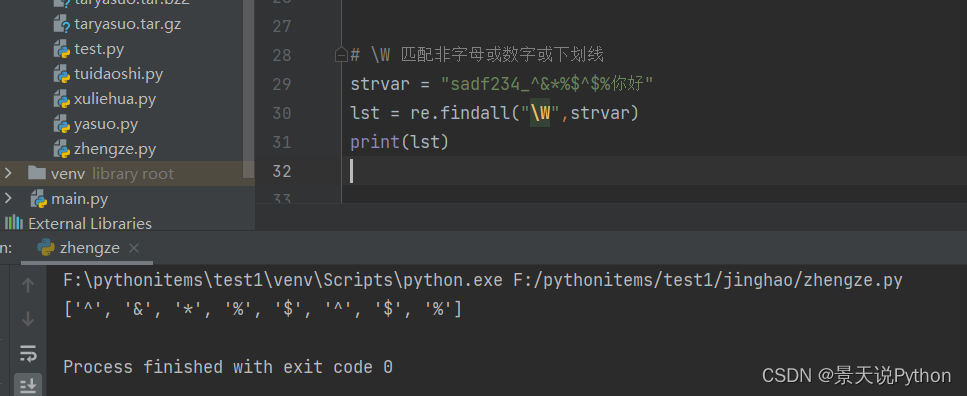
#\s 匹配任意的空白符 ( " " \t \n \r )
strvar = " \r "
lst = re.findall(“\s”,strvar)
print(lst)
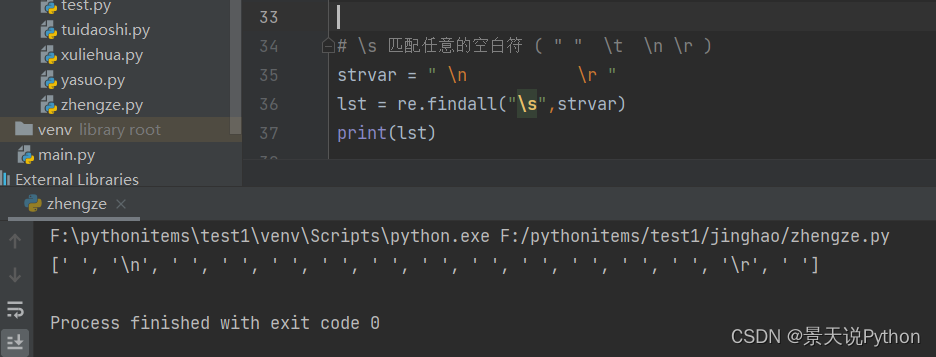
#\S 匹配任意非空白符
strvar = " \r 123_*("
lst = re.findall(“\S”,strvar)
print(lst)
#\n 匹配一个换行符
strvar = “”"
今天国庆假期结束了,兄弟们满载 而归,玩的 很困,尽 快调 整.
“”"
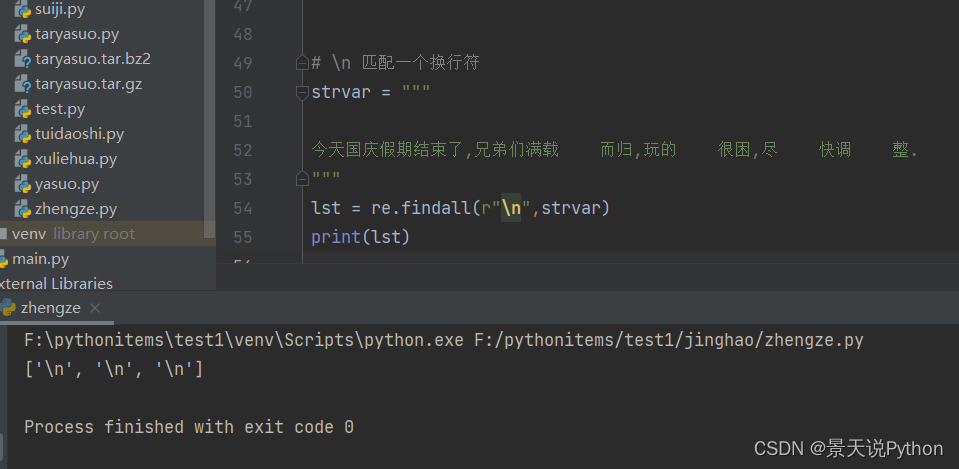
lst = re.findall(r"\n",strvar)
print(lst)
正则表达式前面无脑加r,基本不会有问题
不加转义也可以
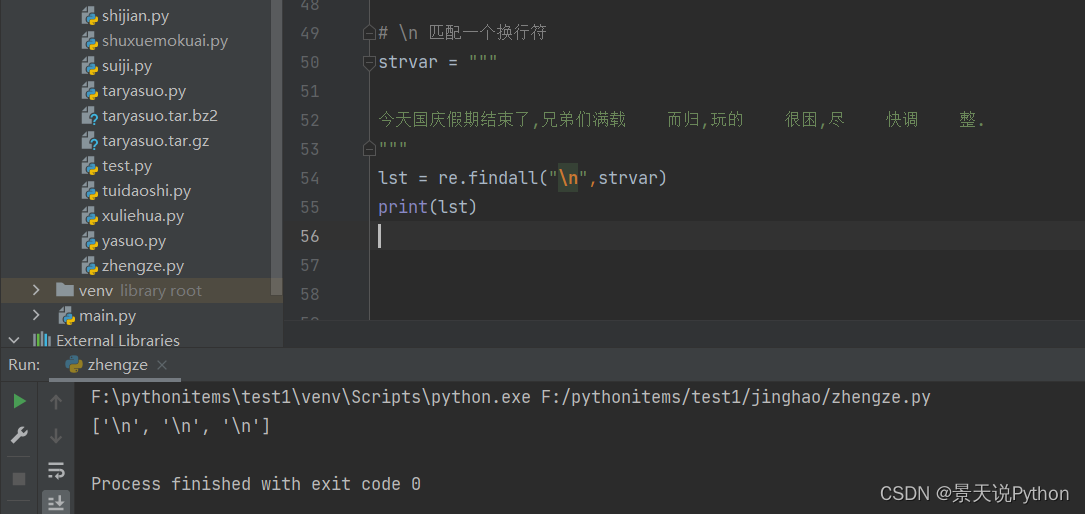
#\t 匹配一个制表符
lst = re.findall(r"\t",strvar)
print(lst)
(2) 字符组 [] 匹配出字符组当中列举的字符(从字符组里面挑一个)
逐个去匹配
#lst = re.findall(“[123]”,“a1b2c3d4”)
#print(lst)

print(re.findall('a[abc]b','aab abb acb adb')) # aab abb acb print(re.findall('a[0123456789]b','a1b a2b a3b acb ayb')) # a1b a2b a3b #优化写法 0123456789 => 0-9 不要随便加空格 print(re.findall('a[0-9]b','a1b a2b a3b acb ayb')) print(re.findall('a[abcdefg]b','a1b a2b a3b acb ayb adb')) # acb adb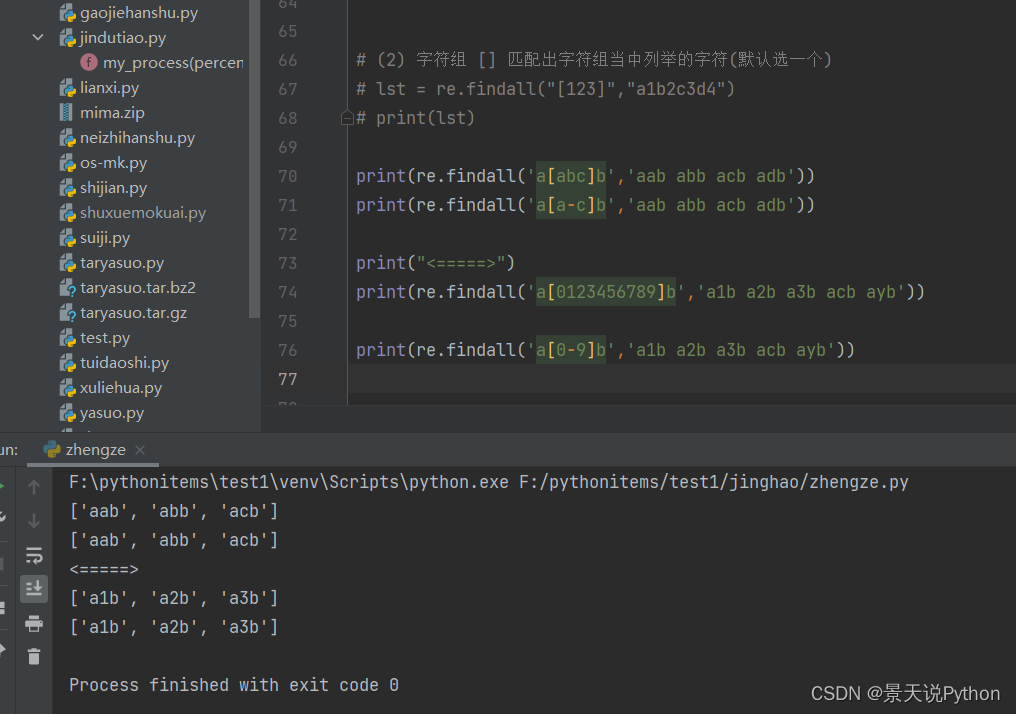
#优化写法 abcdefg => a-g 表达所有的小写字母 a-z print(re.findall('a[a-g]b','a1b a2b a3b acb ayb adb')) print(re.findall('a[a-z]b','a1b a2b a3b acb ayb adb')) # acb adb ayb print(re.findall('a[ABCDEFG]b','a1b a2b a3b aAb aDb aYb')) # aAb aDb #优化写法 ABCDEFG => A-G 表达所有的大写字母 A-Z print(re.findall('a[A-G]b','a1b a2b a3b aAb aDb aYb')) # aAb aDb print(re.findall('a[A-Z]b','a1b a2b a3b aAb aDb aYb')) # aAb aDb aYb #注意点: 不能直接写A-z 中间ascii编码中包含了特殊的符号 print(re.findall('a[A-z]b','a1b a2b a3b acb ayb adb a[b')) #匹配所有的字母和数字 不能随便加空格 print(re.findall('a[a-zA-Z0-9]b','a1b a2b a3b acb ayb adb a[b')) print(re.findall('a[0-9a-zA-Z]b','a-b aab aAb aWb aqba1b')) #aab aAb aWb aqb a1b print(re.findall('a[0-9][*#/]b','a1/b a2b a29b a56b a456b')) # a1/b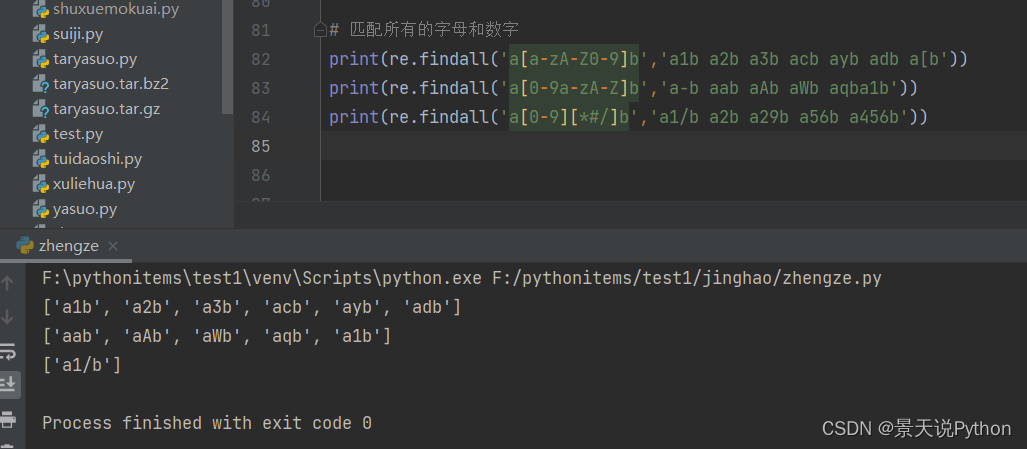
#^ 在字符组开头的位置出现代表 除了...的意思,非的意思 匹配[^字符]之外的任意字符 取反 ,不包含空行 ^[a-z] 表示以字母开头 print(re.findall('a[^-+*/]b',"a%b ccaa*bda&bd")) #a%b a&b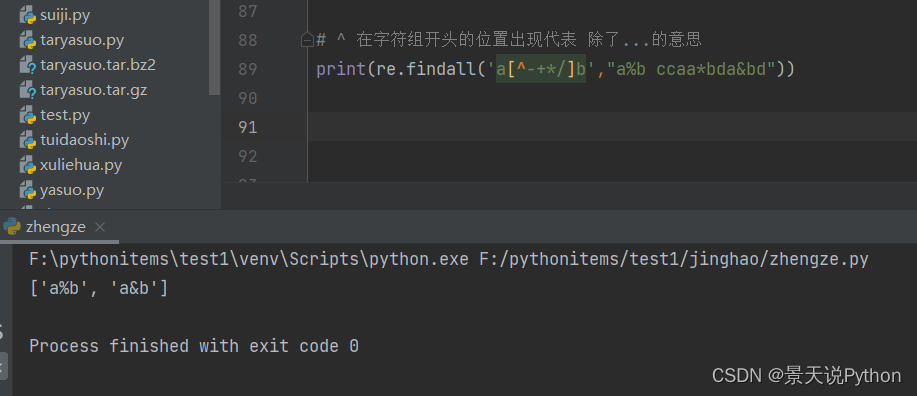
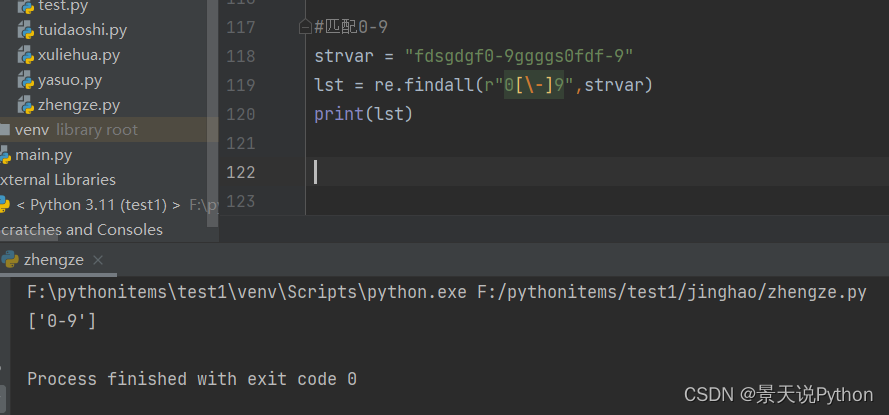
#匹配^-\等特殊字符时 ,需要前面加上\进行转义
strvar = “a^c a-c a\c”
lst = re.findall(r"a[^-\]c",strvar)
print(lst)
print(lst[-1])
不转义报错
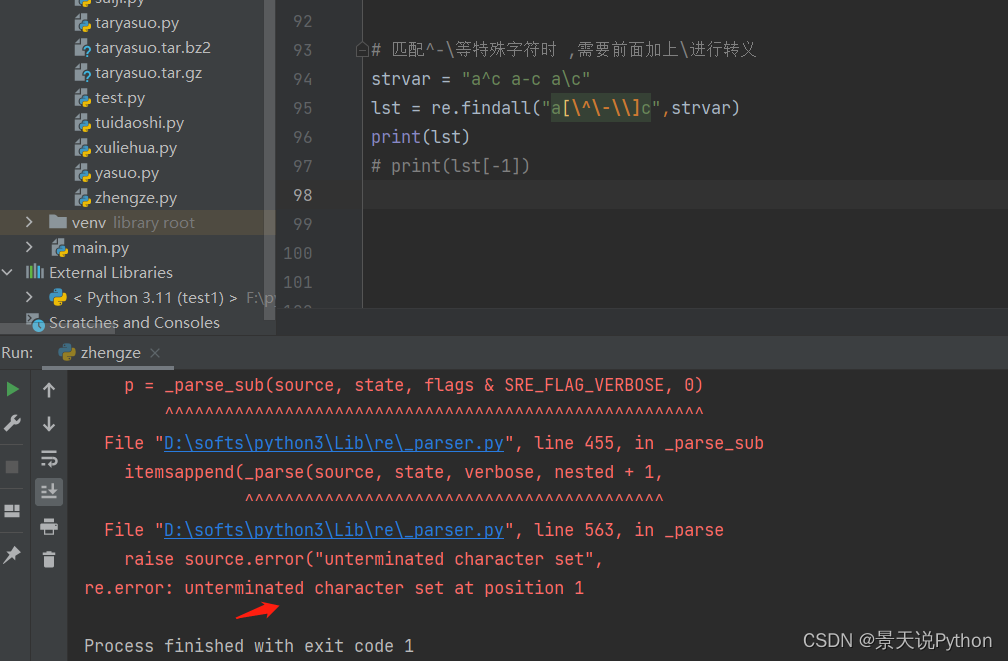
加转义正常

#注意点:为了防止转义,在正则表达式中或者要匹配的字符串中,无脑加r实现匹配
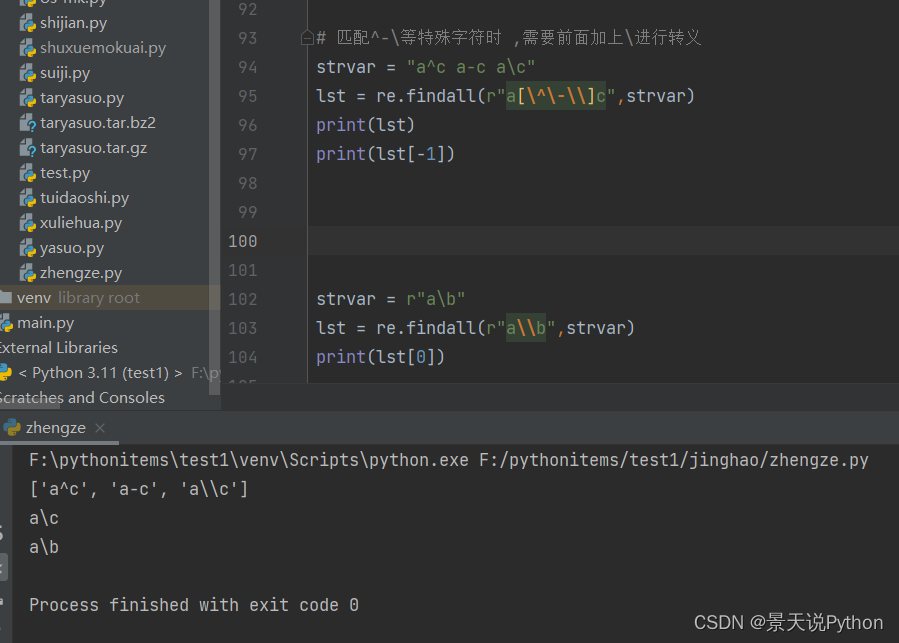
\b在正则里面表示边界符
strvar = r"a\b"
lst = re.findall(r"a\b",strvar)
print(lst[0])
列表中显示两个\。单独打印出来是一个
(3)匹配多个字符,量词放在要匹配的字符之后
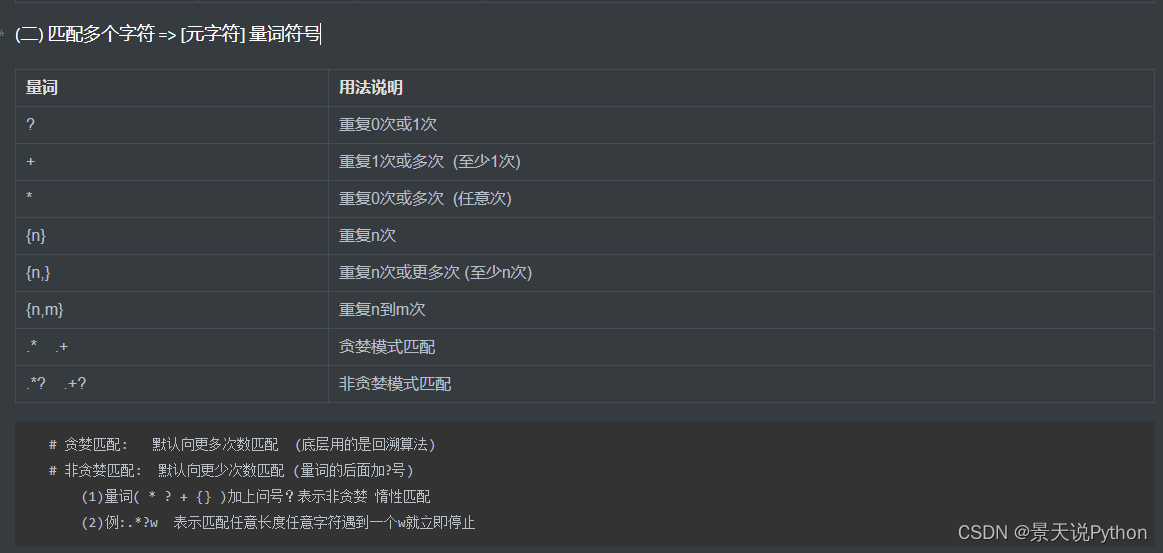
#(1) 量词 有? * + {n} {n,} {n,m} .* .+ .? 共九个
量词放在要匹配的词后面
import re
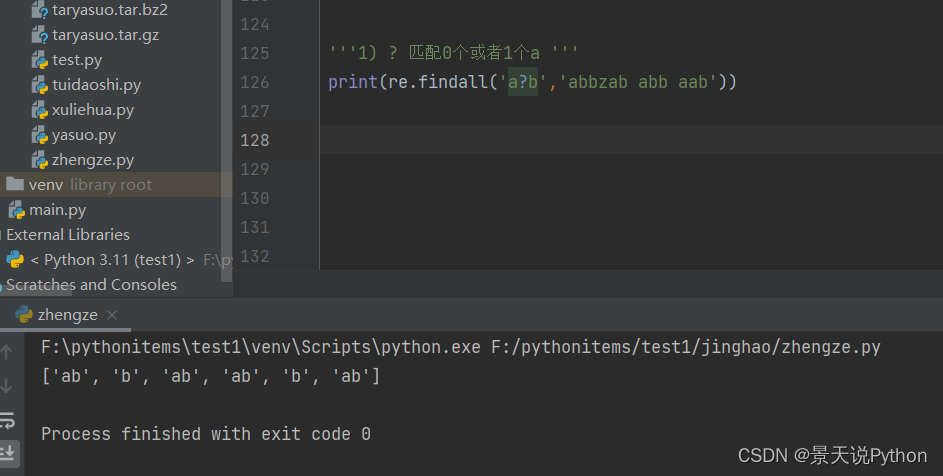
‘’‘1) ? 匹配0个或者1个a ‘’’
print(re.findall(‘a?b’,‘abbzab abb aab’)) # ab b ab ab b ab
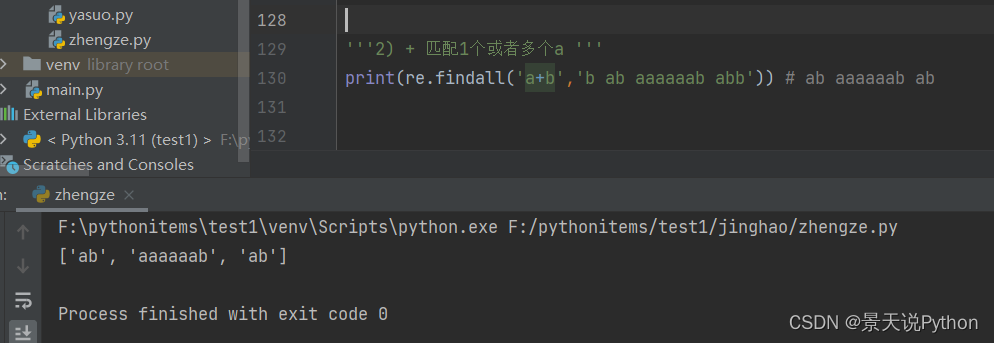
‘’‘2) + 匹配1个或者多个a ‘’’
print(re.findall(‘a+b’,‘b ab aaaaaab abb’)) # ab aaaaaab ab
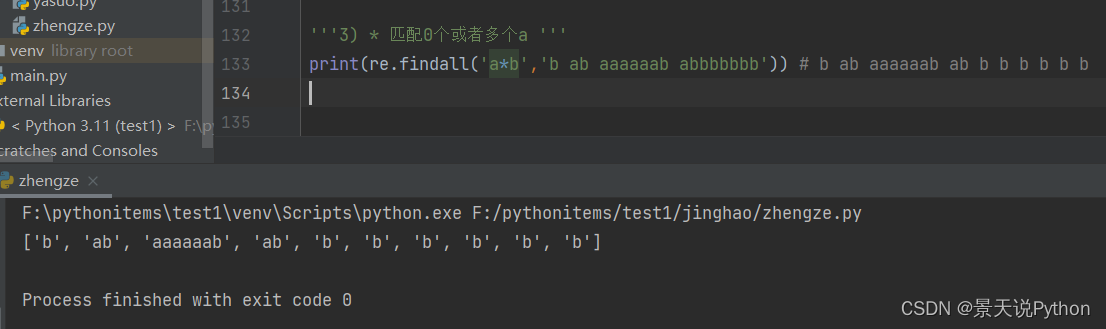
‘’‘3) * 匹配0个或者多个a ‘’’
print(re.findall(‘a*b’,‘b ab aaaaaab abbbbbbb’)) # b ab aaaaaab ab b b b b b b
‘’‘4) {m,n} 匹配m个至n个a 至少m个,至多n个 ‘’’
#1
import re
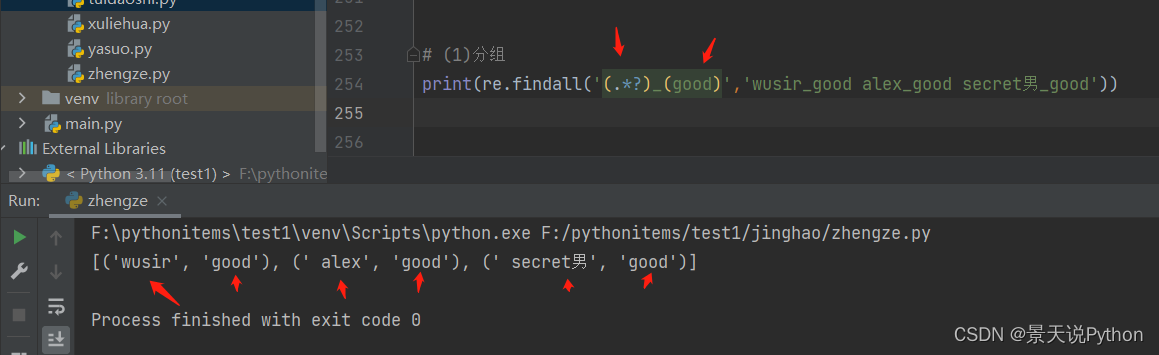
#(1)分组
print(re.findall(‘.?_good’,‘wusir_good alex_good secret男_good’))
print(re.findall('(.?)_good’,‘wusir_good alex_good secret男_good’)) #加个括号分组,默认只显示分组匹配到的内容,不显示全部内容
(?😃 代表不优先显示分组里面的内容,只是显示正常匹配到的内容
print(re.findall(‘(?:.*?)_good’,‘wusir_good alex_good secret男_good’))
如下,不加?: 打印只显示匹配到的分组(括号)里面的内容,没匹配到的数据不显示

多个分组时,以元组方式放到列表中
#(2) | 代表或 , a|b 匹配字符a 或者 匹配字符b .
strvar = "abceab" lst = re.findall("a|b",strvar) print(lst)
#注意点:把不容易匹配到的内容放到前面, 把容易匹配到的内容放到后面 更精确的放前面
strvar = "abcdeabc234f" lst = re.findall("abcd|abc",strvar) print(lst)
如果把更精确的放后面,则查不到
#(3) 练习
“”"
. 可以匹配任意的字符,除了\n
. 对.进行转义,表达.这个字符本身.
“”"
#匹配小数 strvar = "3.... ....4 .3 ...3 1.3 9.89 10" lst = re.findall(r"\d+\.\d+",strvar) print(lst)
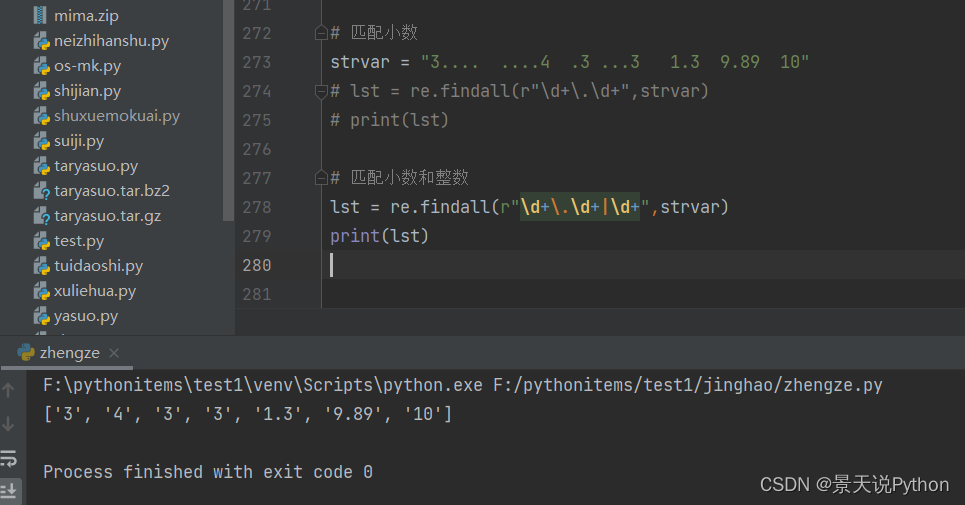
#匹配小数和整数
lst = re.findall(r"\d+.\d+|\d+",strvar)
print(lst)
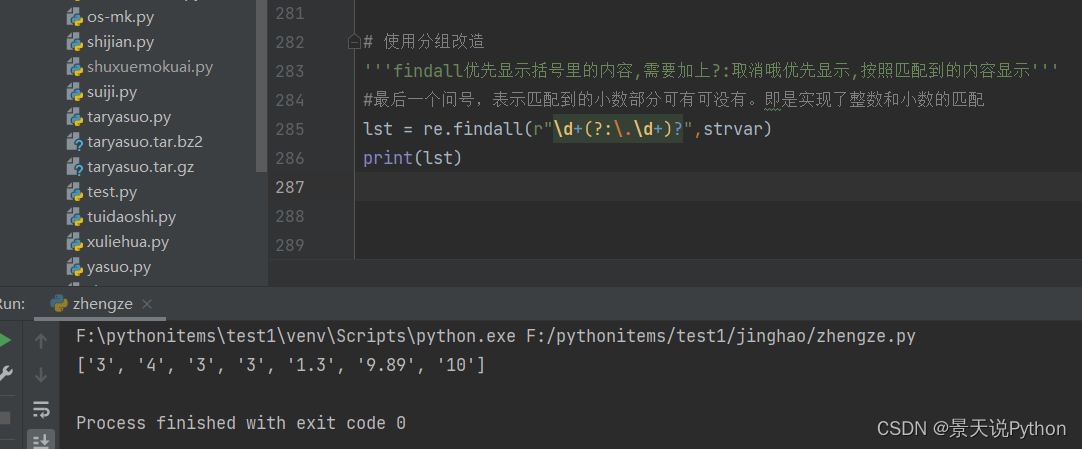
#使用分组改造
‘’‘findall优先显示括号里的内容,需要加上?:取消哦优先显示,按照匹配到的内容显示’‘’
lst = re.findall(r"\d+(?:.\d+)?",strvar)
print(lst)
#仅仅整数和小数才能被匹配
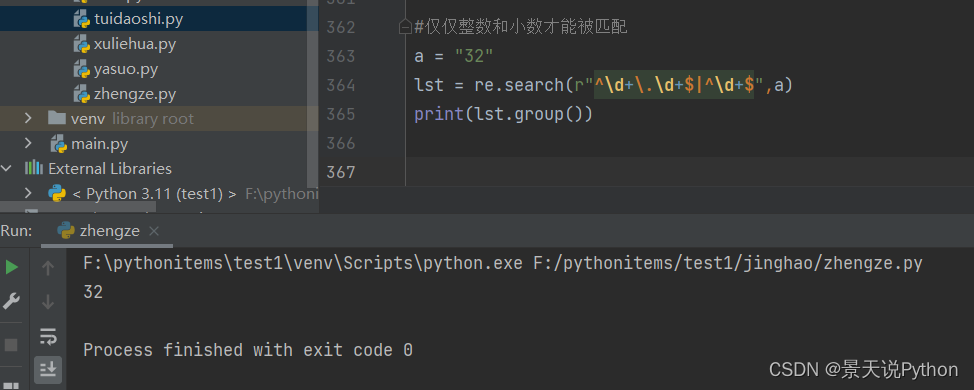
分组改造仅匹配整数或小数
re.search(r"^\d+KaTeX parse error: Undefined control sequence: \d at position 4: (\.\̲d̲+)?",num)
#匹配135或171的手机号 strvar = "13566668888 17366669999 17135178392" lst = re.findall(r"(?:135|171)\d{8}",strvar) print(lst)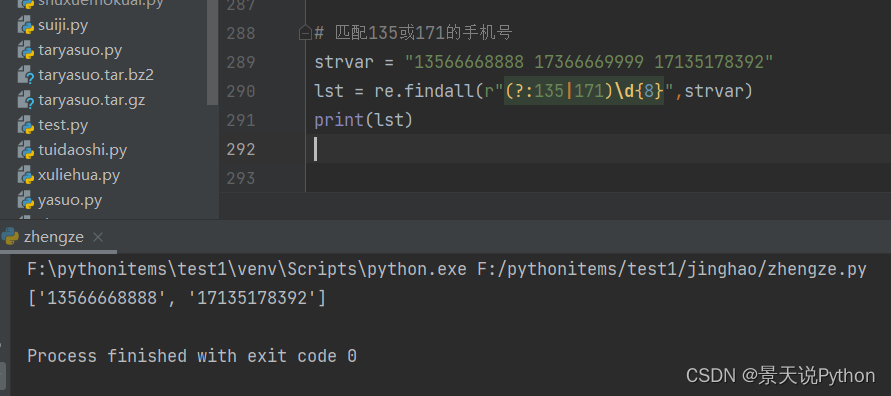
#优化,只能匹配出一个手机号
strvar = "13566668888" lst = re.findall(r"^(?:135|171)\d{8}$",strvar) print(lst) obj = re.search(r"^(135|171)\d{8}$",strvar) print(obj) print(obj.group()) print(obj.groups())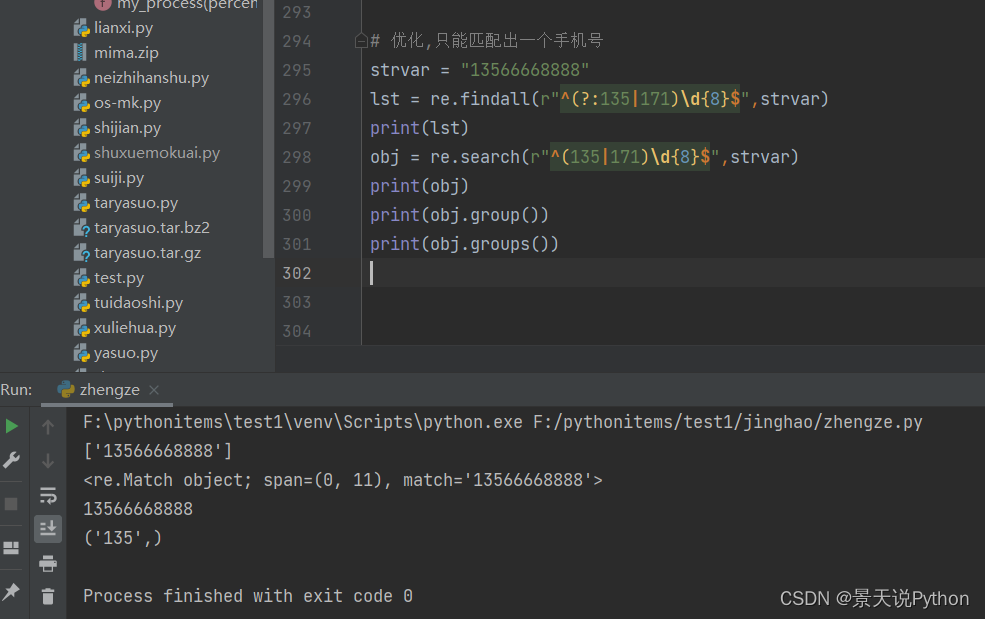
#匹配www.baidu.com 或者 www.oldboy.com
“”"
findall : 从左到右,匹配出所有的内容,返回到列表
问题是,匹配到的字符串和分组的内容不能同时显示;
search : 从左到右,匹配到第一组内容就直接返回,找到就不往下继续匹配。返回的是对象
优点是,可以让匹配到的内容和分组里的内容同时显示;
匹配不到内容时,返回的是None。None时,是不能调用group/groups方法的
obj.group() : 获取匹配到的内容
obj.groups(): 获取分组里面的内容,返回的是元祖
如果search匹配不到数据,再调用group/groups方法会报错
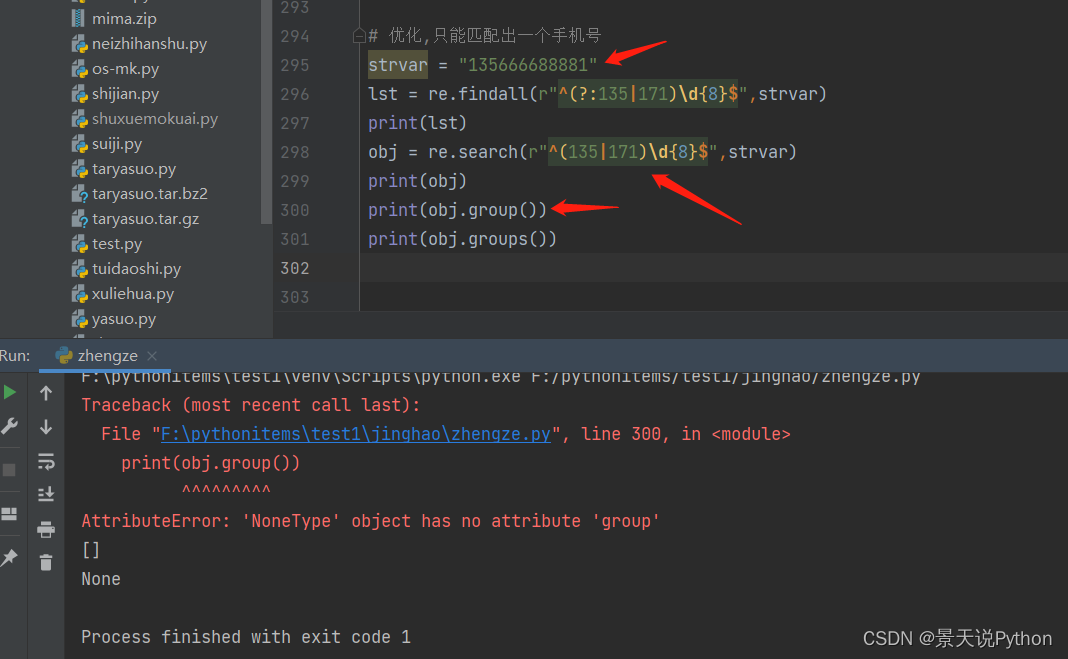
“”"
#findall
strvar = "www.baidu.com www.oldboy.com www.wangwen.com" lst = re.findall(r"(?:www)\.(?:baidu|oldboy)\.(?:com)",strvar) print(lst) #search search匹配分组,不需要加?:,是通过返回的对象.group()获取匹配到的内容 对象.groups()获取分组里面的内容 strvar = "www.baidu.com www.oldboy.com www.wangwen.com" obj = re.search(r"(www)\.(baidu|oldboy)\.(com)",strvar) print(obj) #获取匹配到的内容 print(obj.group()) #获取分组里面的内容 (推荐) 获得的是元祖 print(obj.groups()) #方法二,可以直接通过下标1来获取分组里面的第一个内容; print(obj.group(1)) print(obj.group(2)) print(obj.group(3))
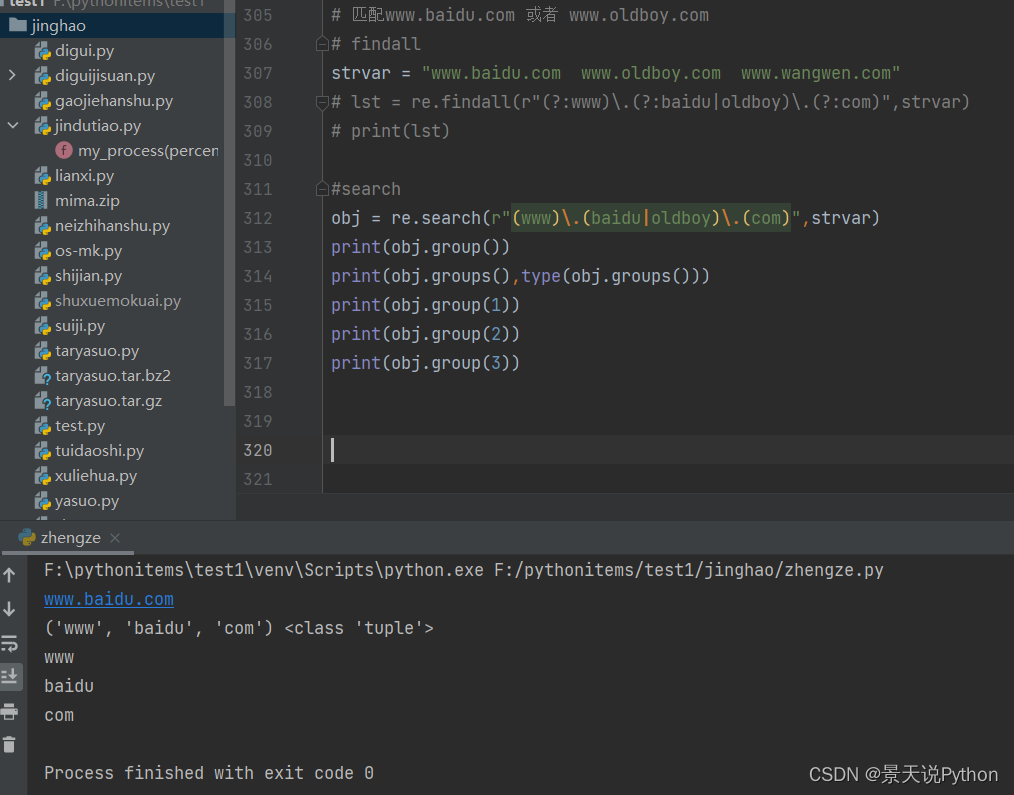
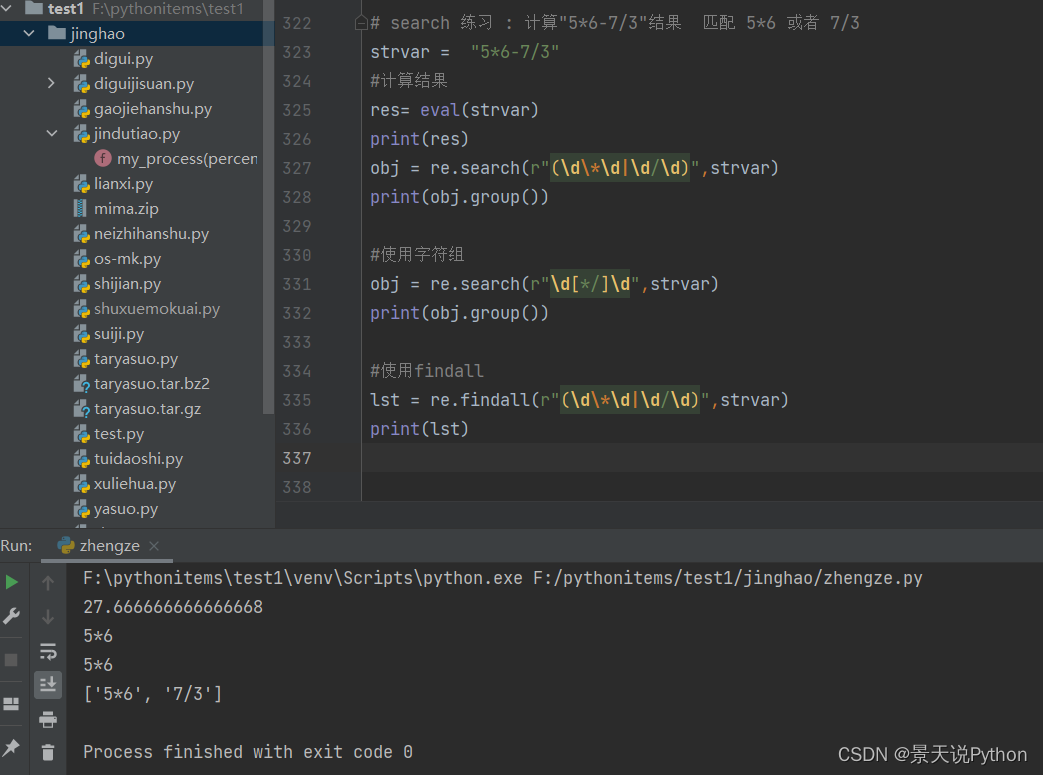
#search 练习 : 计算"56-7/3"结果 匹配 56 或者 7/3
strvar = "5*6-7/3" #strvar = "www.baidu.com www.oldboy.com www.wangwen.com" obj = re.search(r"\d+[*/]\d+",strvar) res1 = obj.group() print(res1 , type(res1)) # 5*6 #计算结果 a,b = res1.split("*") res2 = int(a) * int(b) print(res2) #把30替换回原来的字符串中 strvar = strvar.replace(res1,str(res2)) print(strvar)#以此类推 …
(5)search反向引用
import re strvar = "明天又要休息了" obj = re.search("(.*?)",strvar) print(obj)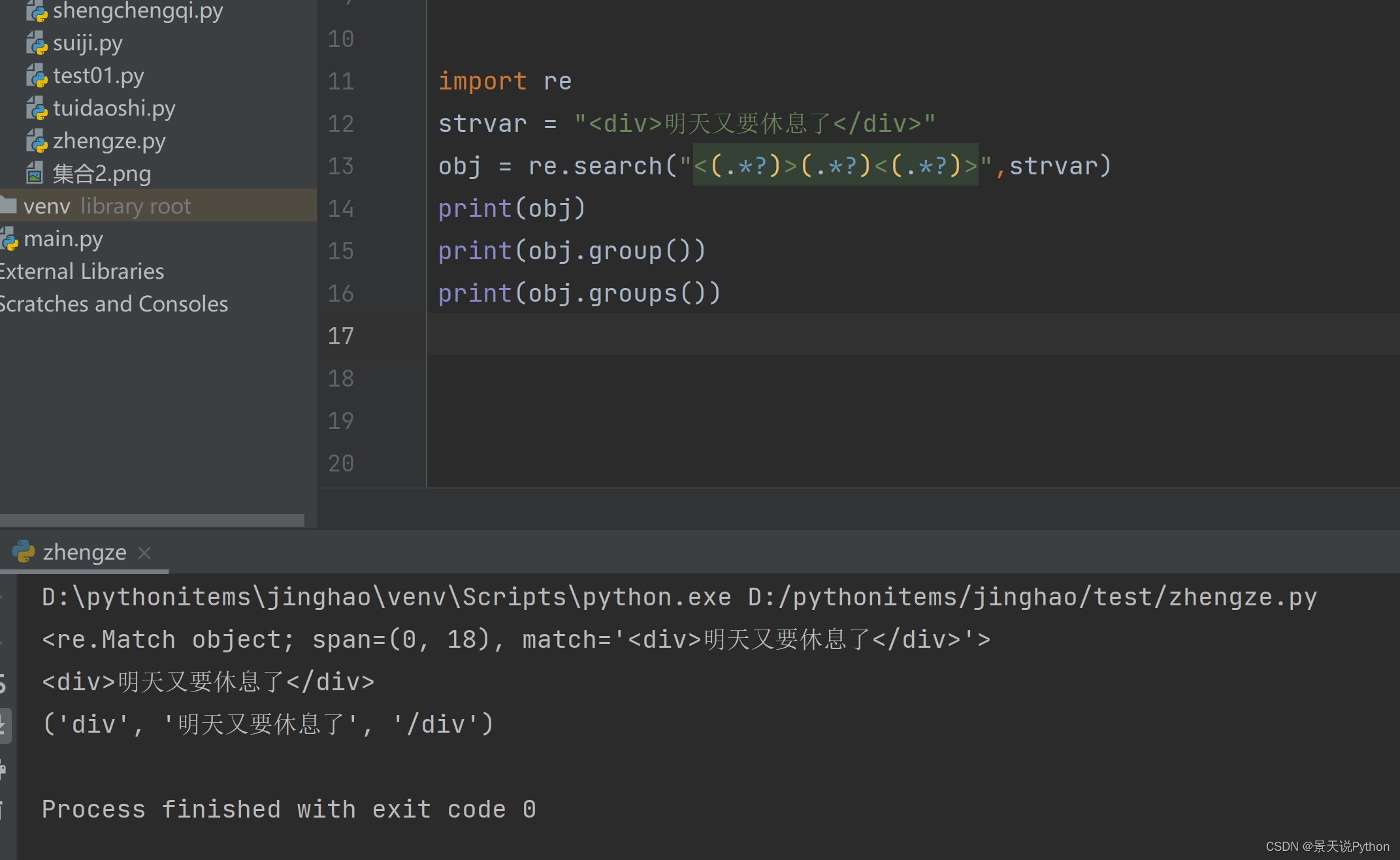
#获取匹配到的内容
res1 = obj.group()
print(res1)
#获取分组里的内容
res2 = obj.groups()
print(res2)
#如果左右两边括号里面的内容一致,可以使用反向引用的语法 \1把第一个括号里面匹配到的内容再引用一次。\1 \2等不是用来匹配的,只是将前面分组的内容拿过来放到该位置
也可以用\2 \3等等,分别表示第二、第三…个圆括号里面匹配的内容
如果\1 \2等位置的数据与前面分组匹配的内容不一致,则匹配不到数据
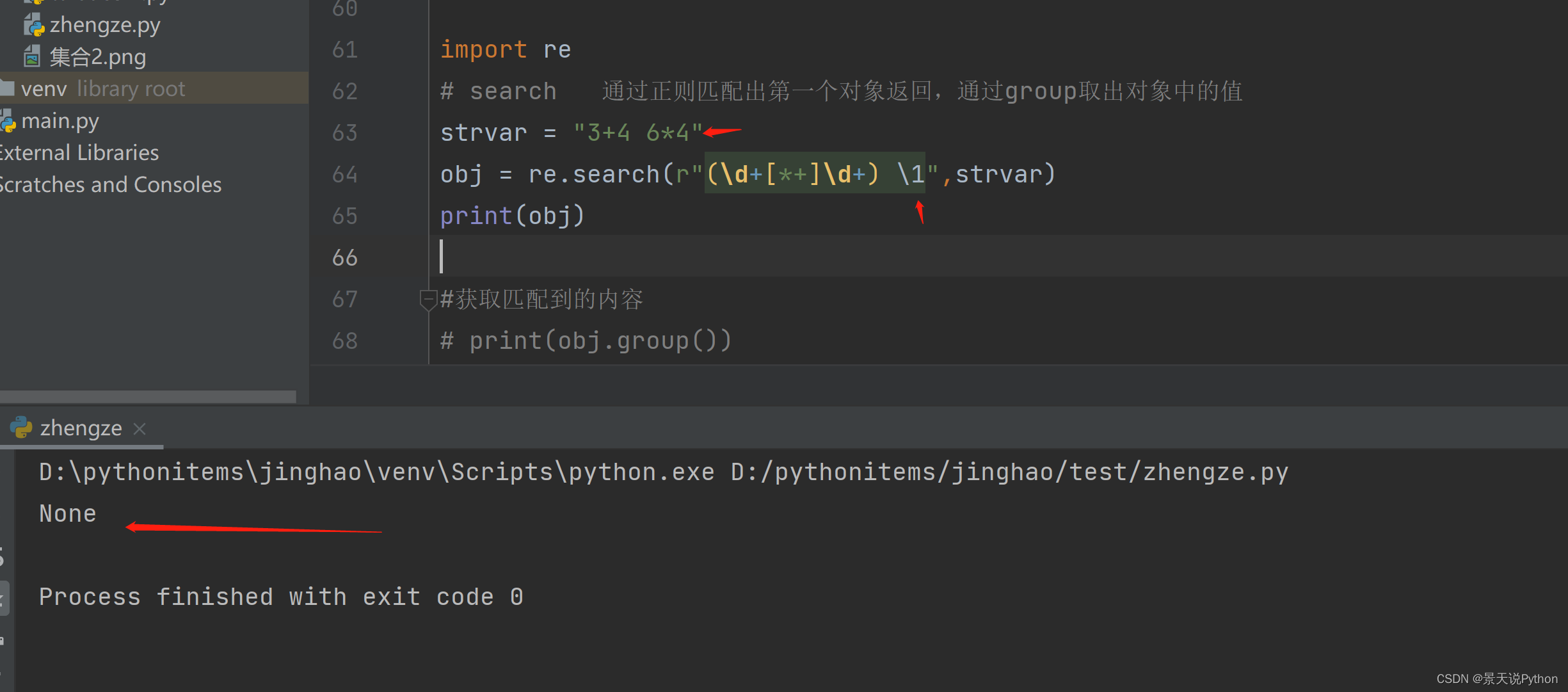
数据一模一样则可以反向引用
obj = re.search(r"(.*?)",strvar) print(obj) print(obj.group()) print(obj.groups())
使用反向引用,要加上元字符串输出r
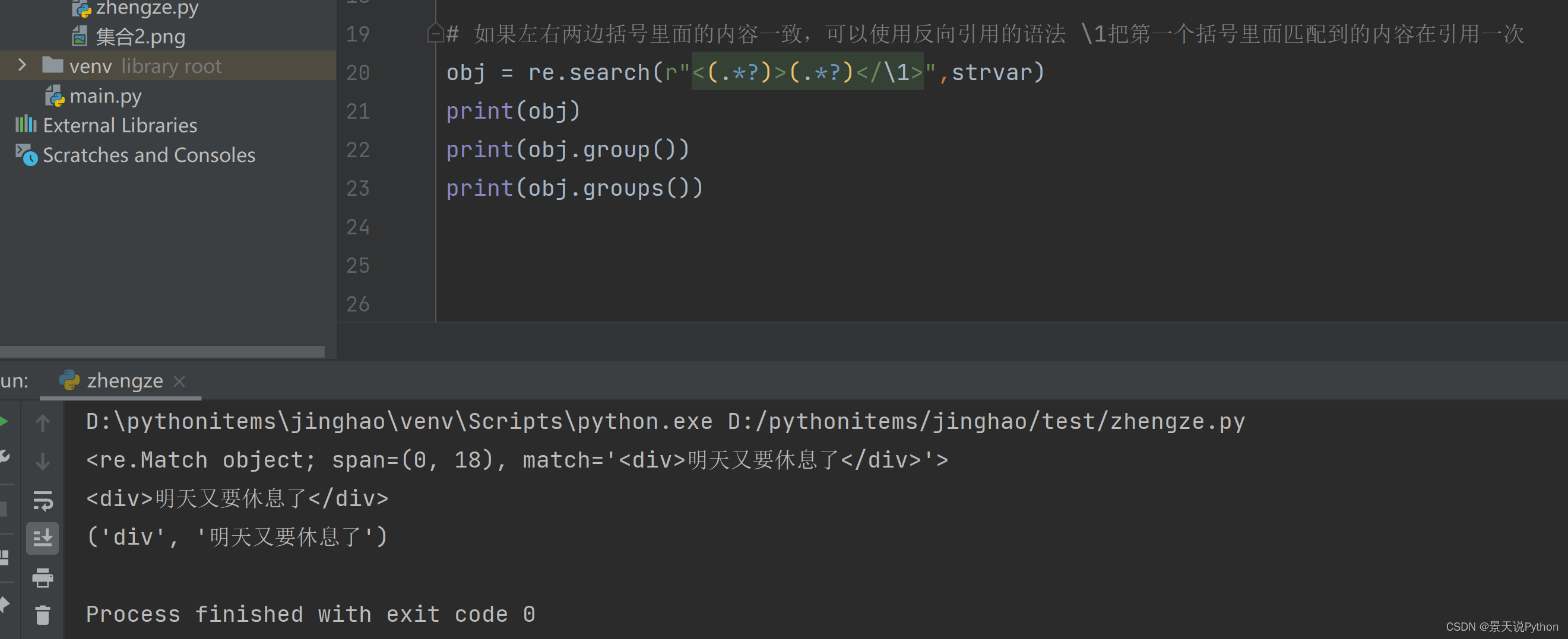
#\1表示第一个括号匹配的内容,\2表示第二个括号匹配的内容。引用到该位置
strvar = " z3d4pzd a1b2cab " obj = re.search(r"(.*?)\d(.*?)\d(.*?)\1\2",strvar) print(obj) print(obj.group()) print(obj.groups())
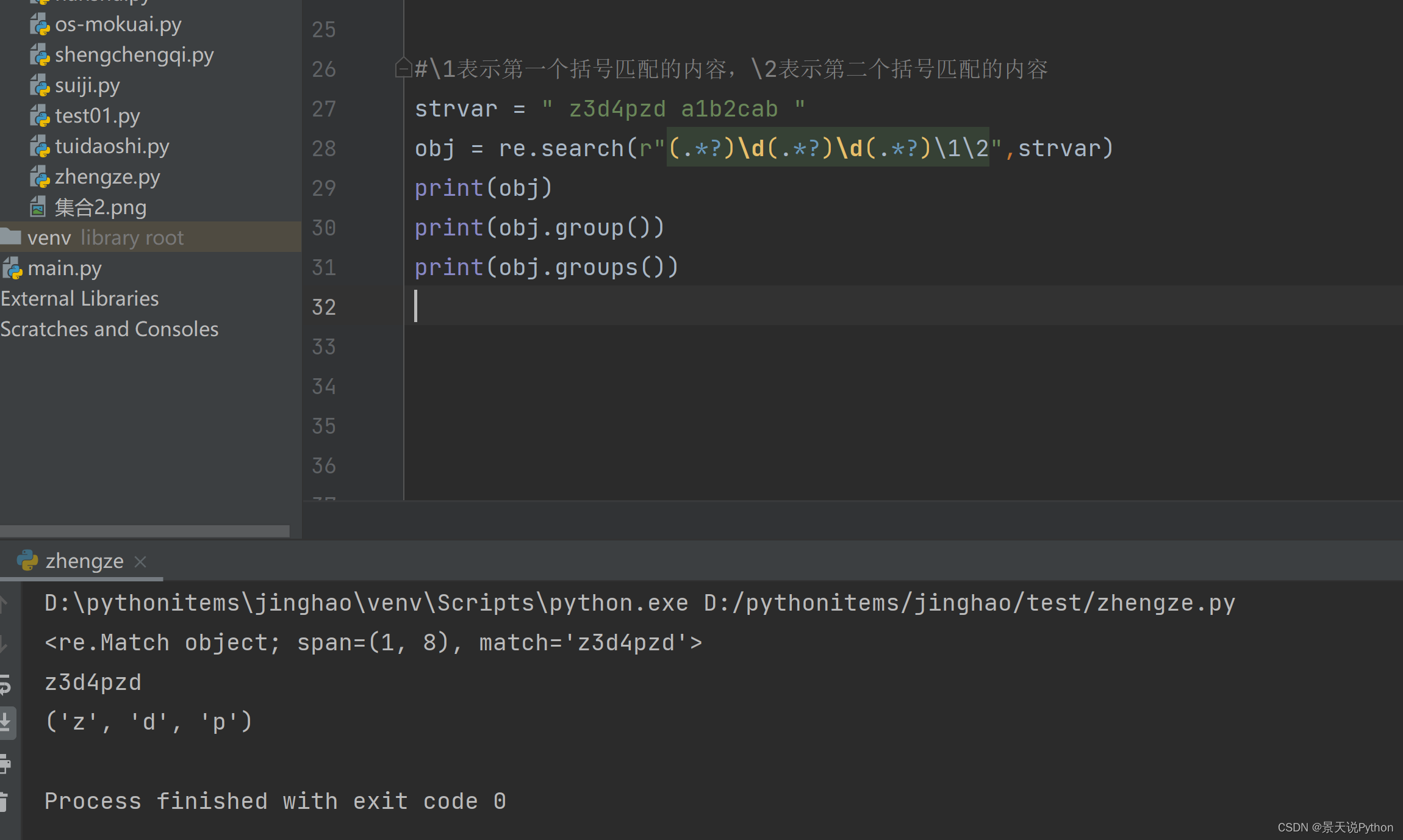
(6)命名分组
“”"
如果正则表达式比较长。使用\1 \2 \3容易数乱。所以用命名分组来引用
- (?P正则表达式) 给这个组起一个名字
- (?P=组名) 引用之前组的名字,把该组名匹配到的内容放到当前位置
“”"
#写法一
strvar = " z3d4pzd a1b2cab " obj = re.search(r"(?P.*?)\d(?P.*?)\d(?P.*?)\1\2",strvar) print(obj) print(obj.group())
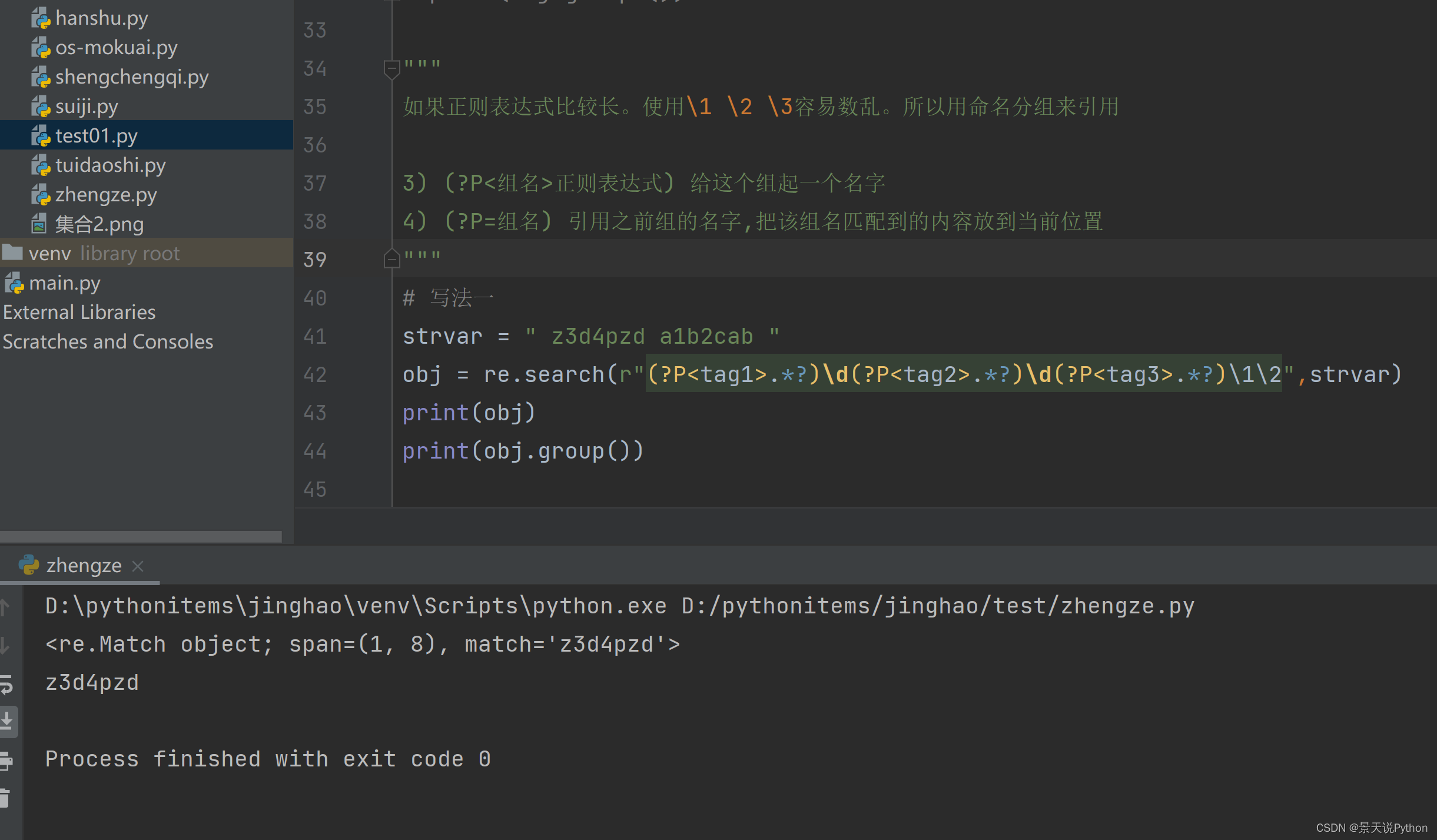
#写法二
strvar = " z3d4pzd a1b2cab " obj = re.search(r"(?P.*?)\d(?P.*?)\d(?P.*?)(?P=tag1)(?P=tag2)",strvar) print(obj) print(obj.group())
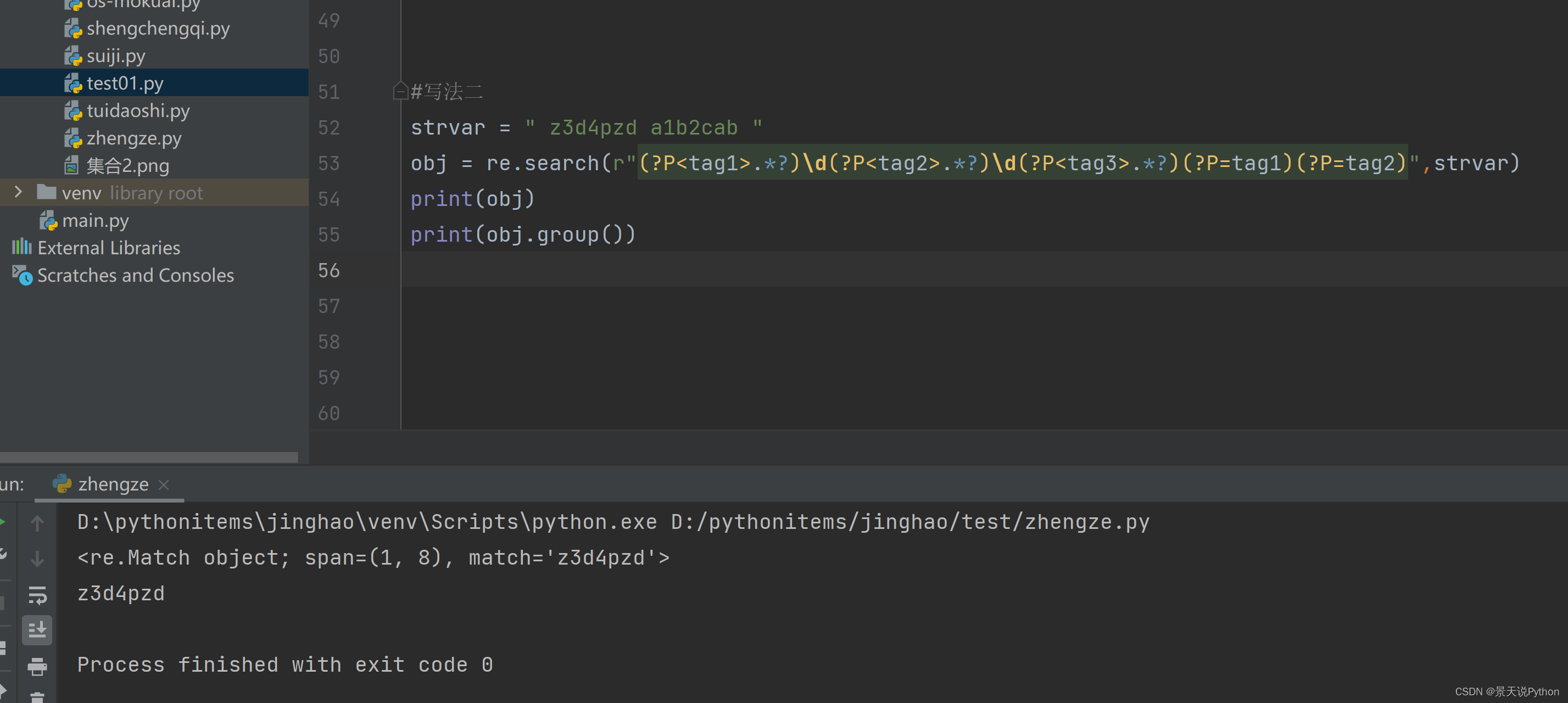
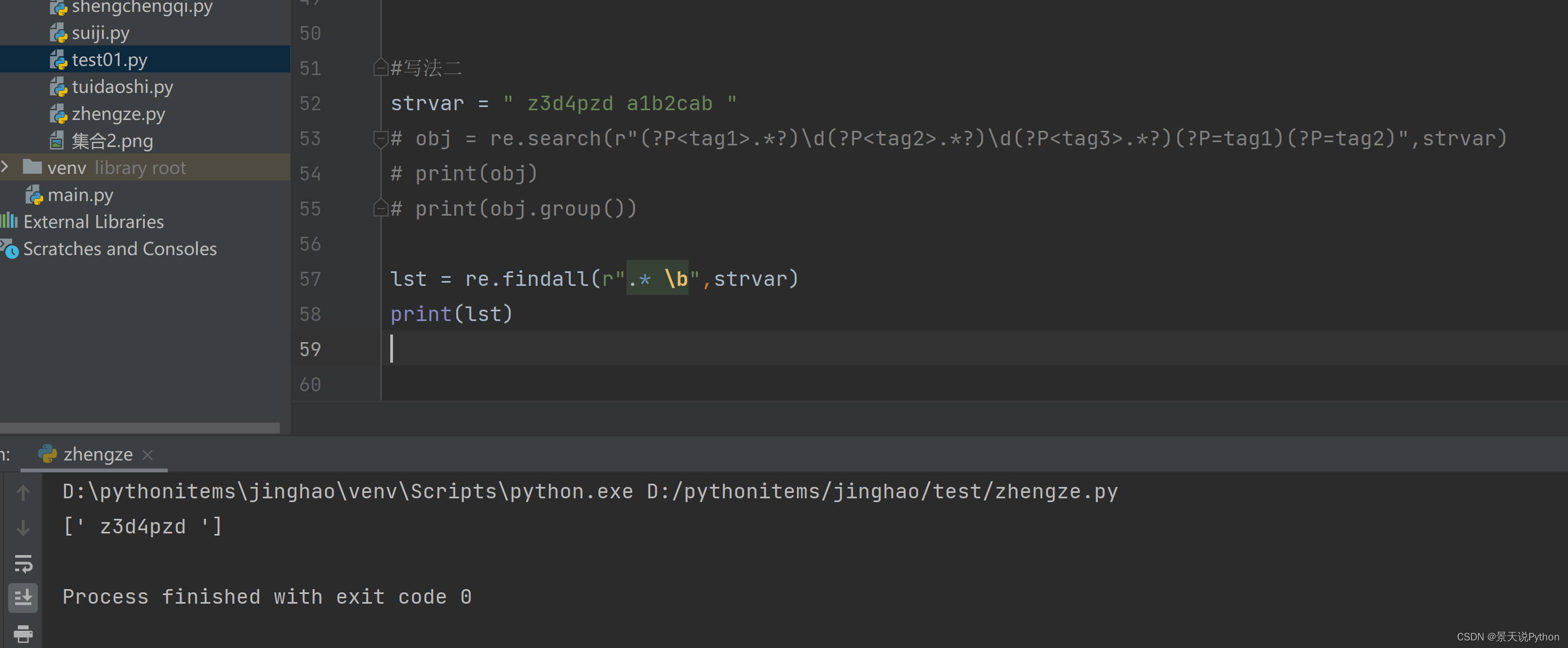
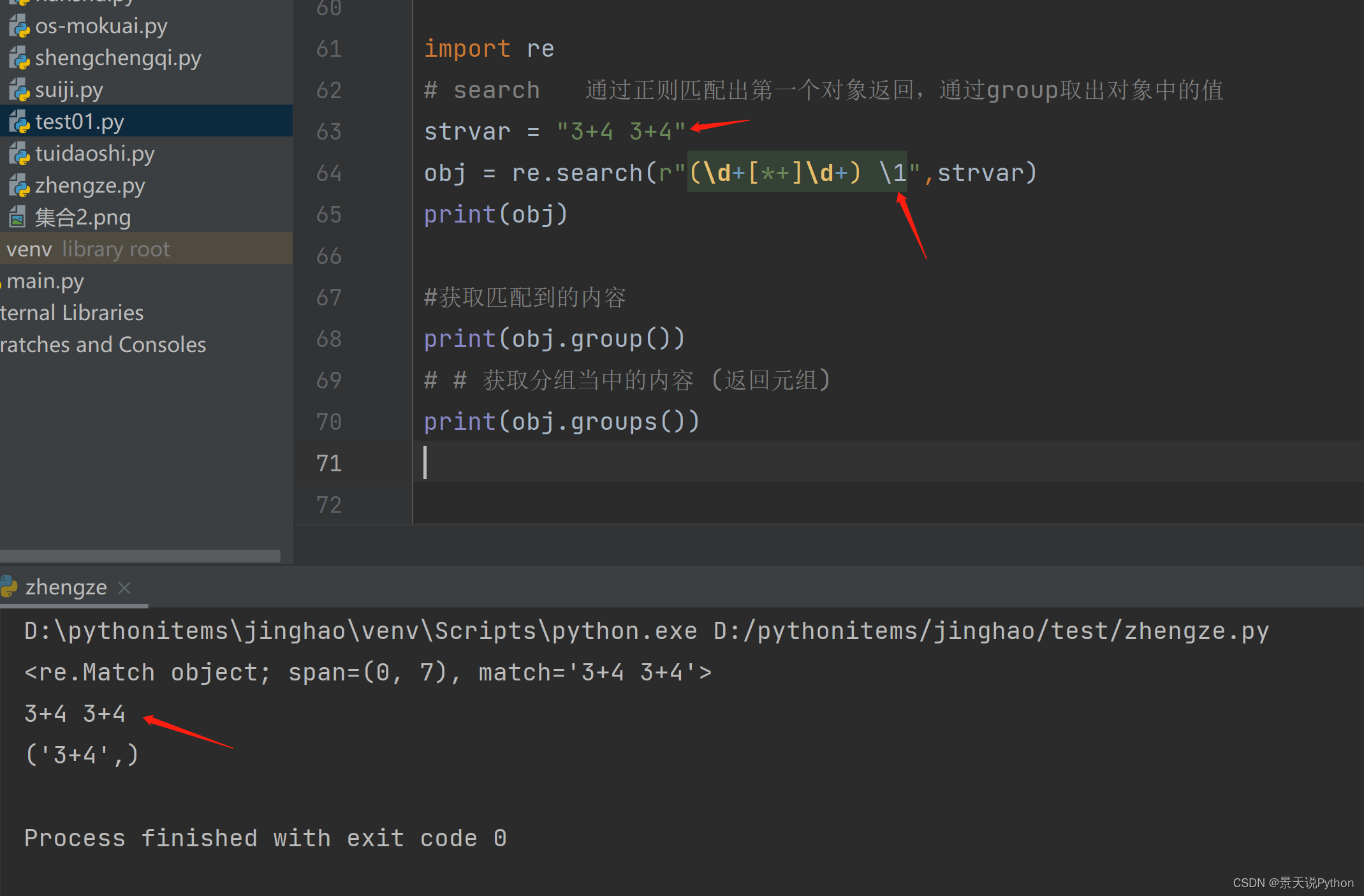
(7)正则函数
import re
#search 通过正则匹配出第一个对象返回,匹配到后,后面的就不配了。通过group取出对象中的值
strvar = “3+4 64"
obj = re.search(r"(\d+[+]\d+)”,strvar)
print(obj)
#获取匹配到的内容
print(obj.group())
#获取分组当中的内容 (返回元组)
print(obj.groups())
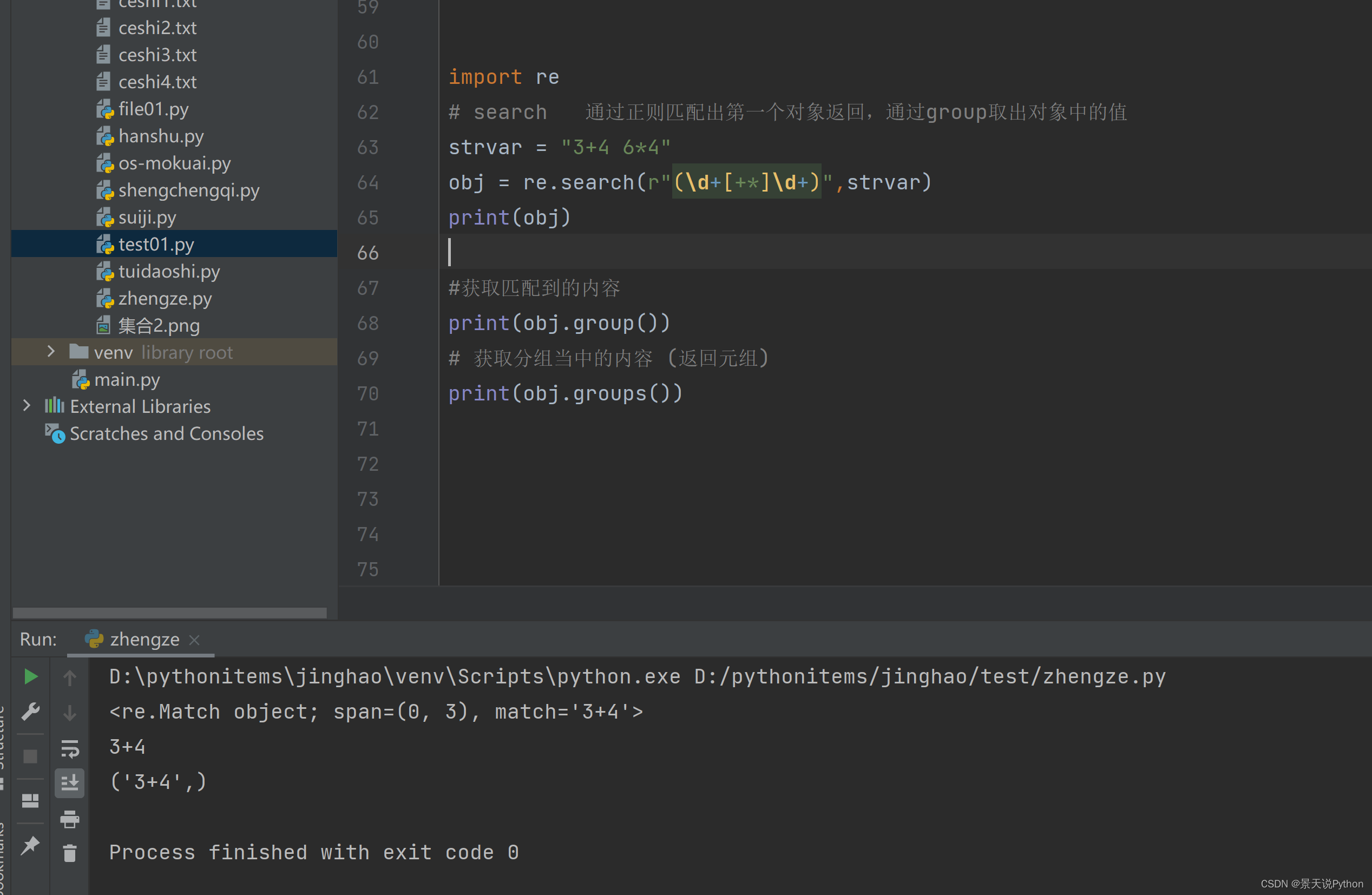
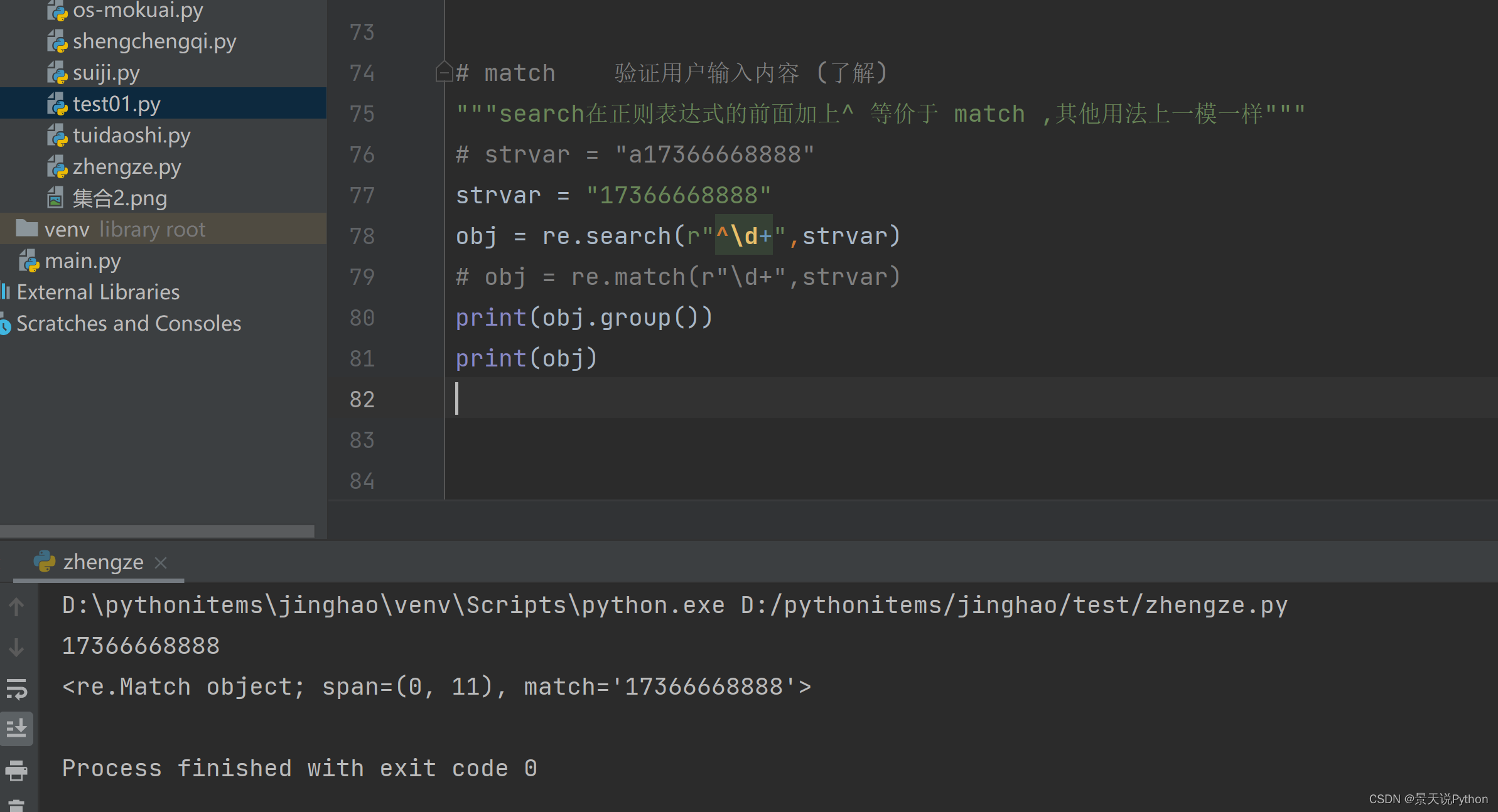
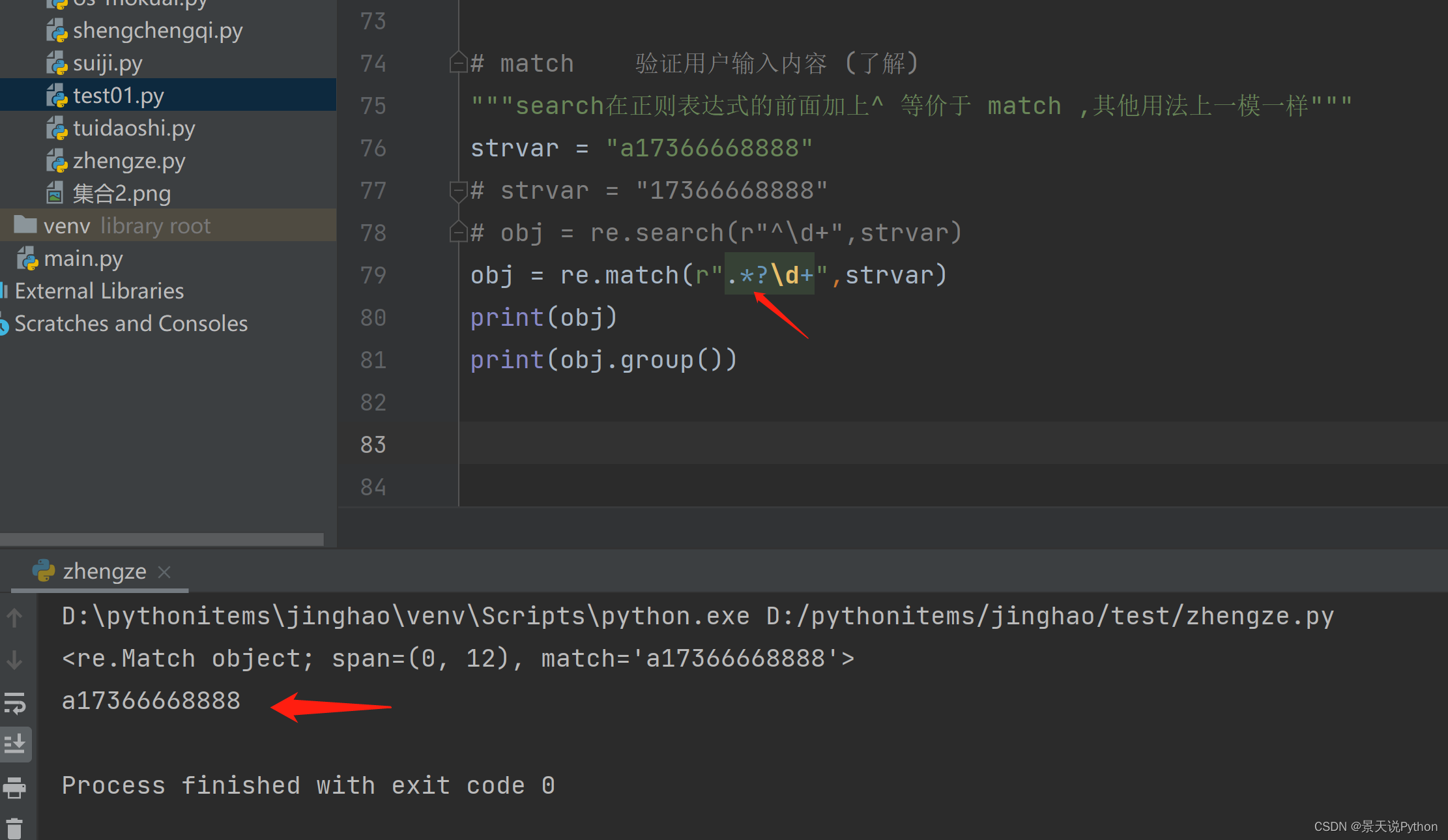
#match 验证用户输入内容 (了解) 匹配的值都是以什么开始,从起始位置开始验证与正则表达式是否匹配
"""search在正则表达式的前面加上^ 等价于 match ,其他用法上一模一样""" strvar = "a17366668888" strvar = "17366668888" #obj = re.search(r"^\d+",strvar) #obj = re.match(r"\d+",strvar) #print(obj.group()) print(obj) search匹配数据,也是从头开始,但是匹配不到的舍弃,后面的接着匹配
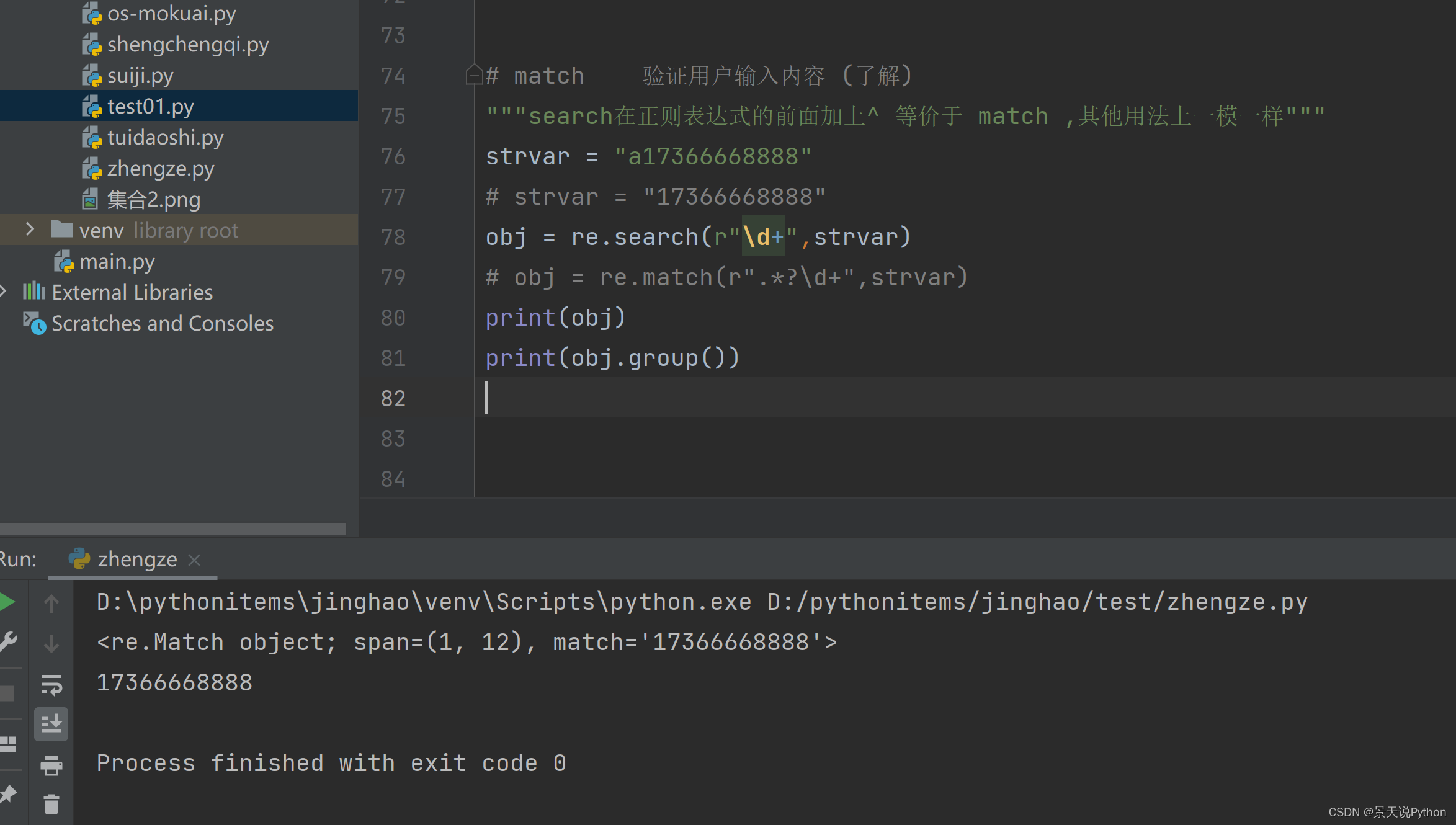
match开头若是匹配不到就匹配不到,不会往后接着匹配,最终匹配结果为空
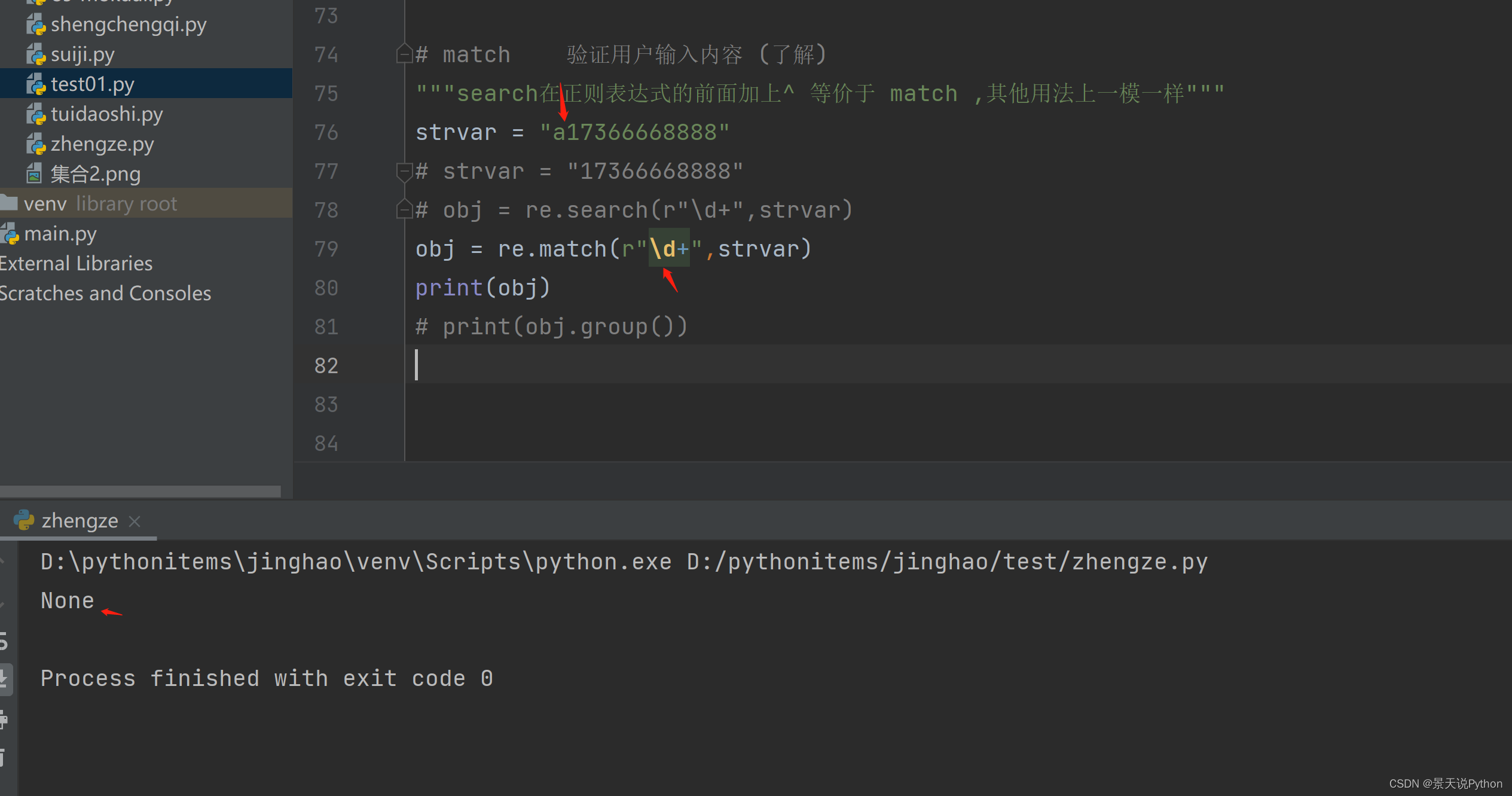
search加上^ 表达的效果就与match一样了
#split 切割 返回的是切割后的列表,可以指定切割次数
针对分隔符有多种的情况,特别好用
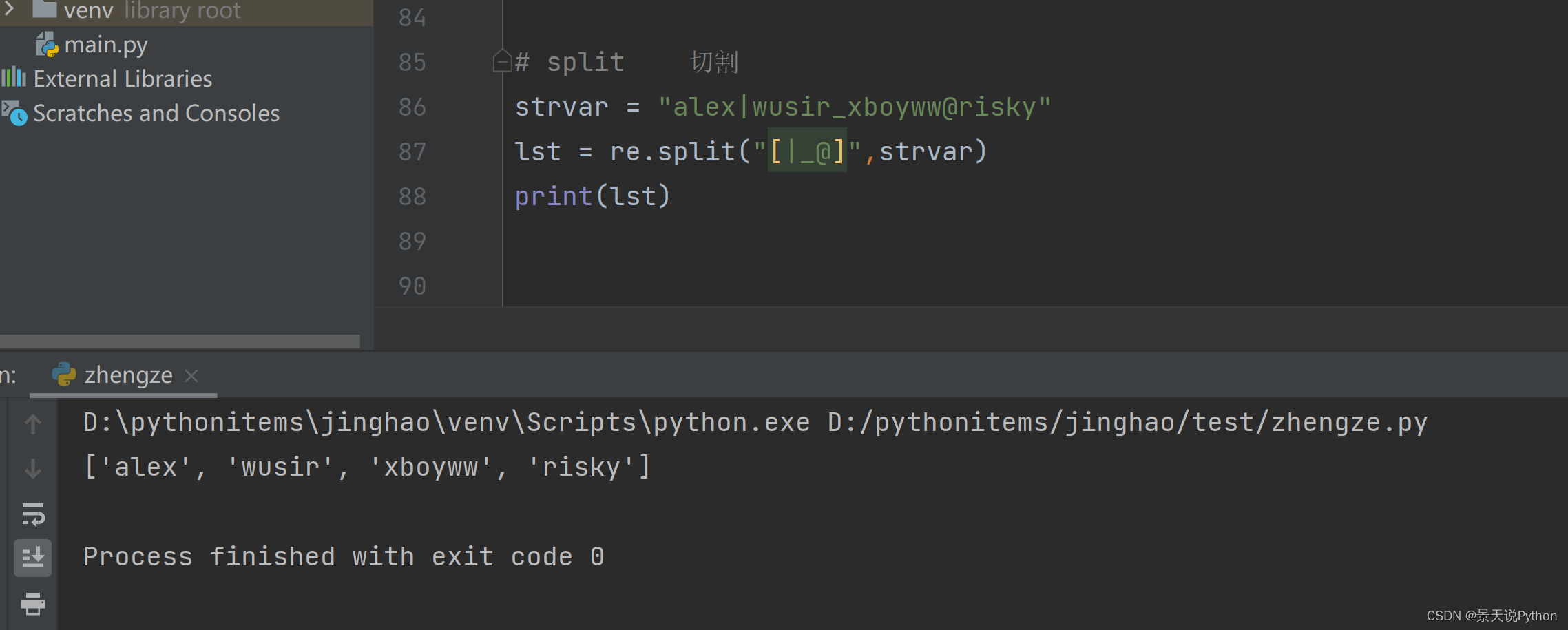
strvar = “alex|wusir_xboyww@risky”
lst = re.split(“[|_@]”,strvar)
print(lst)
以中括号里面的每个符号做切割。特别适合有多个分隔符做切割的情况
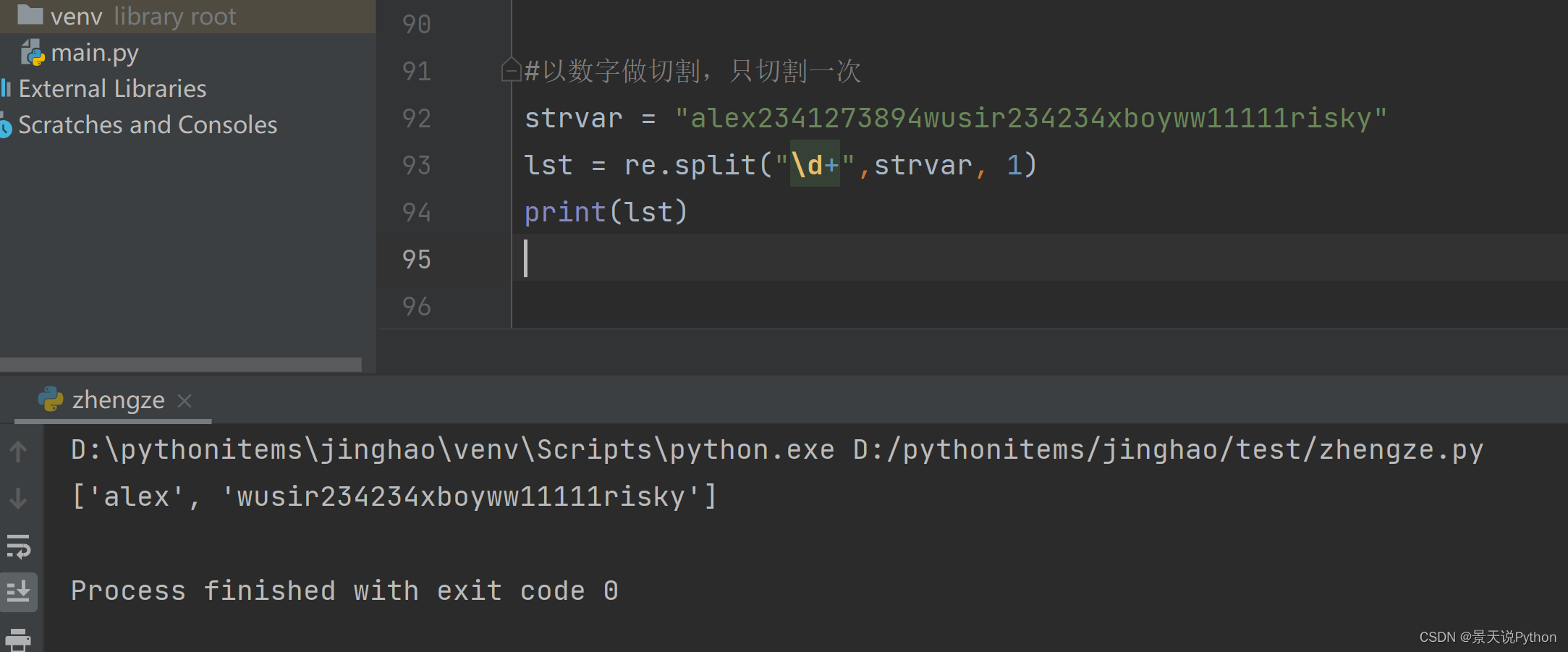
strvar = "alex2341273894wusir234234xboyww11111risky" lst = re.split("\d+",strvar) print(lst)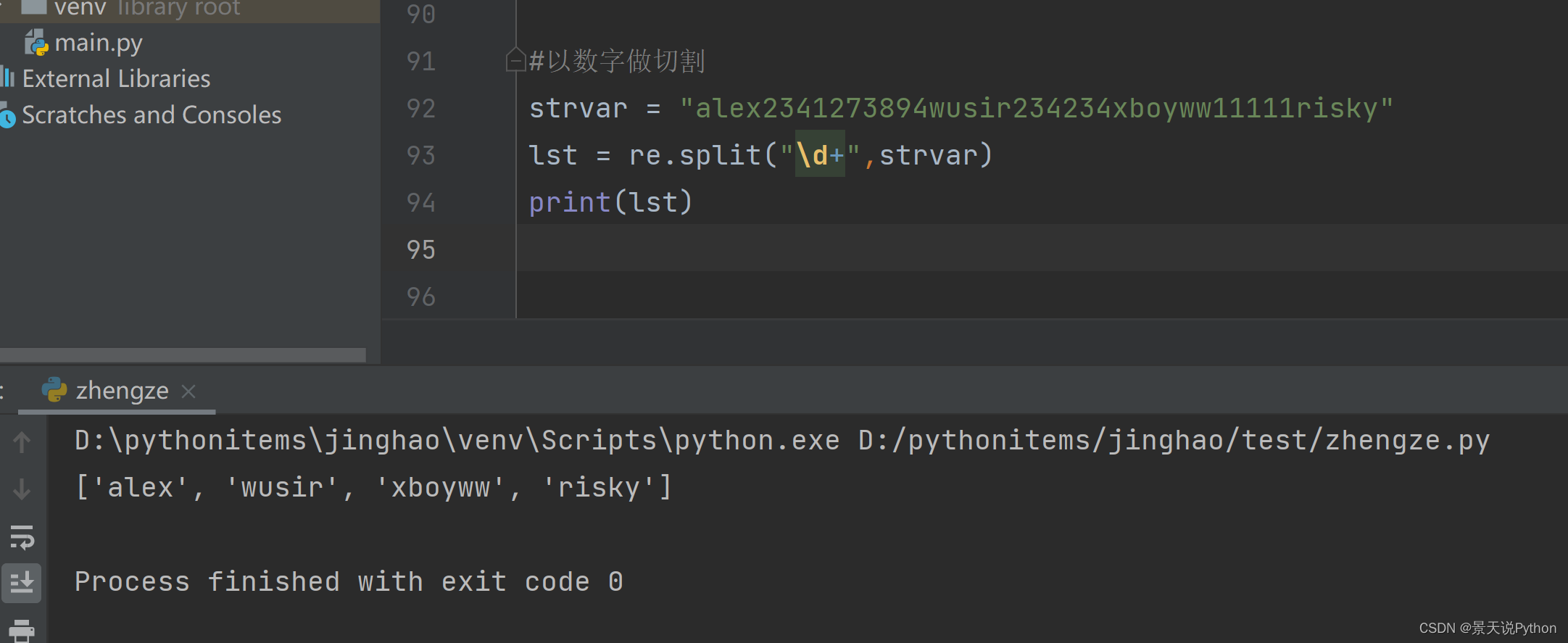

指定切割次数
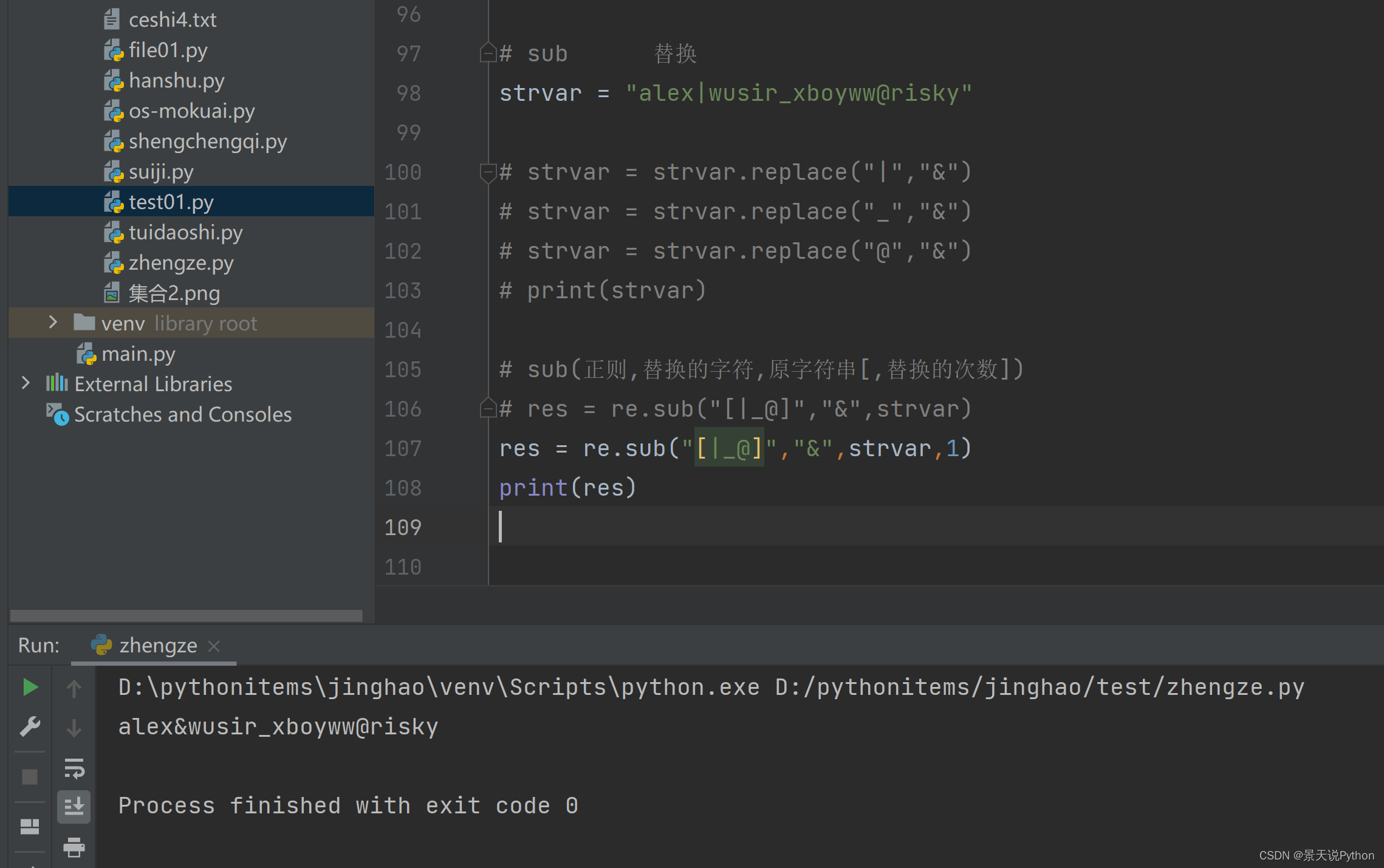
# sub 替换 。可以将多种字符同时替换,不指定替换次数,将全部替换。返回的是替换后的字符串 当要将多种字符批量替换成一种字符时,比replace高效 strvar = "alex|wusir_xboyww@risky" """ strvar = strvar.replace("|","&") strvar = strvar.replace("_","&") strvar = strvar.replace("@","&") print(strvar) """ # sub(正则,替换的字符,原字符串[,替换的次数]) res = re.sub("[|_@]","&",strvar) res = re.sub("[|_@]","&",strvar,1) print(res)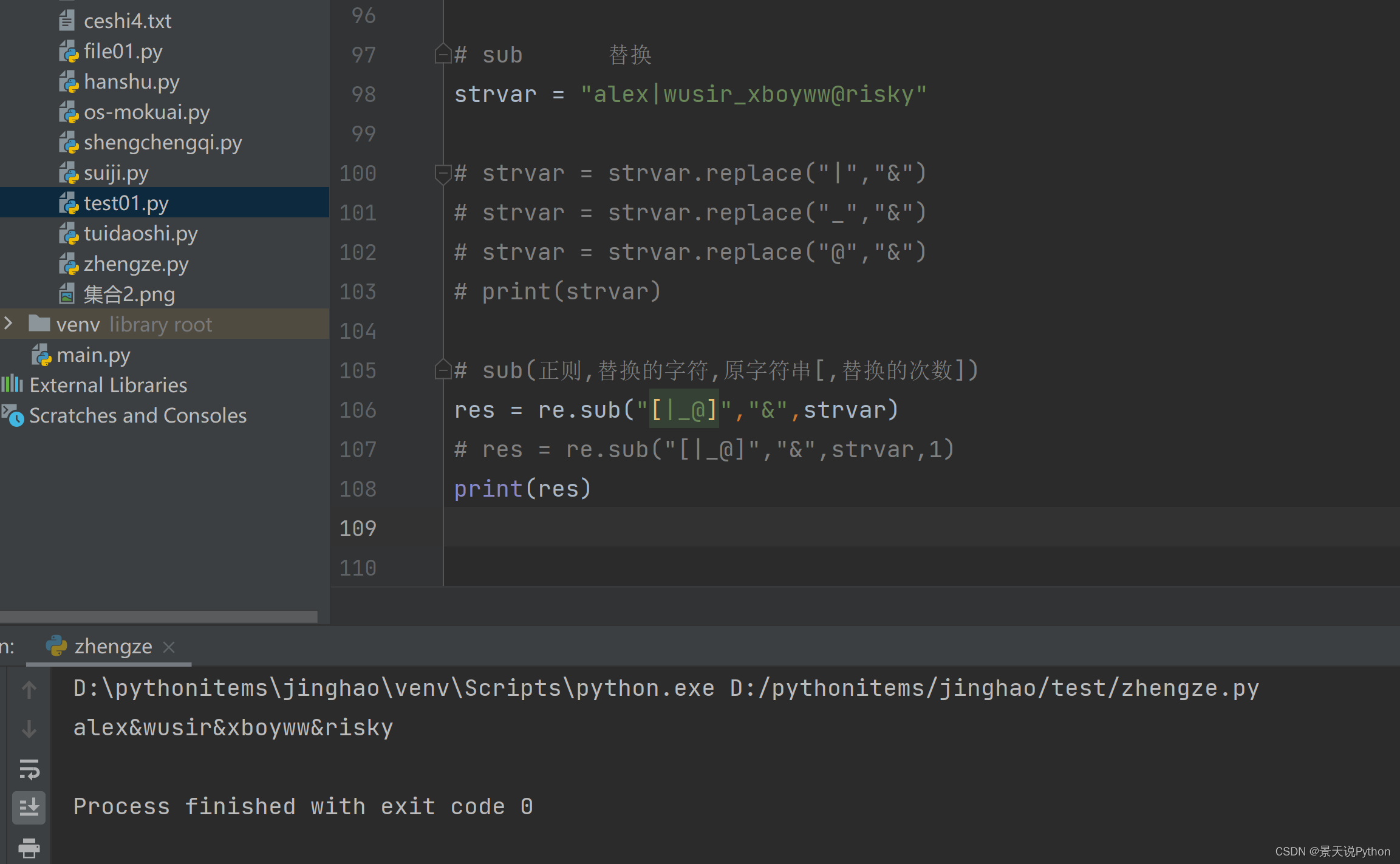
指定替换次数,替换一次,只将第一个替换
#compile 指定一个统一的匹配规则
“”"
正常情况下,正则表达式编译一次,执行一次。如果一条正则多处使用,则会造成系统资源浪费
为了避免反复编译,节省时间空间,可以使用compile统一规则
编译一次,终身受益
使用语法:
1、先编写正则规则patern = re.compile(“正则规则”)
在正则函数处调用:
pattern.正则函数(要匹配的字符串)
2、像原来使用方法一样,将规则放在正则函数的正则表达式处
re.findall(pattern,strvar)
“”"
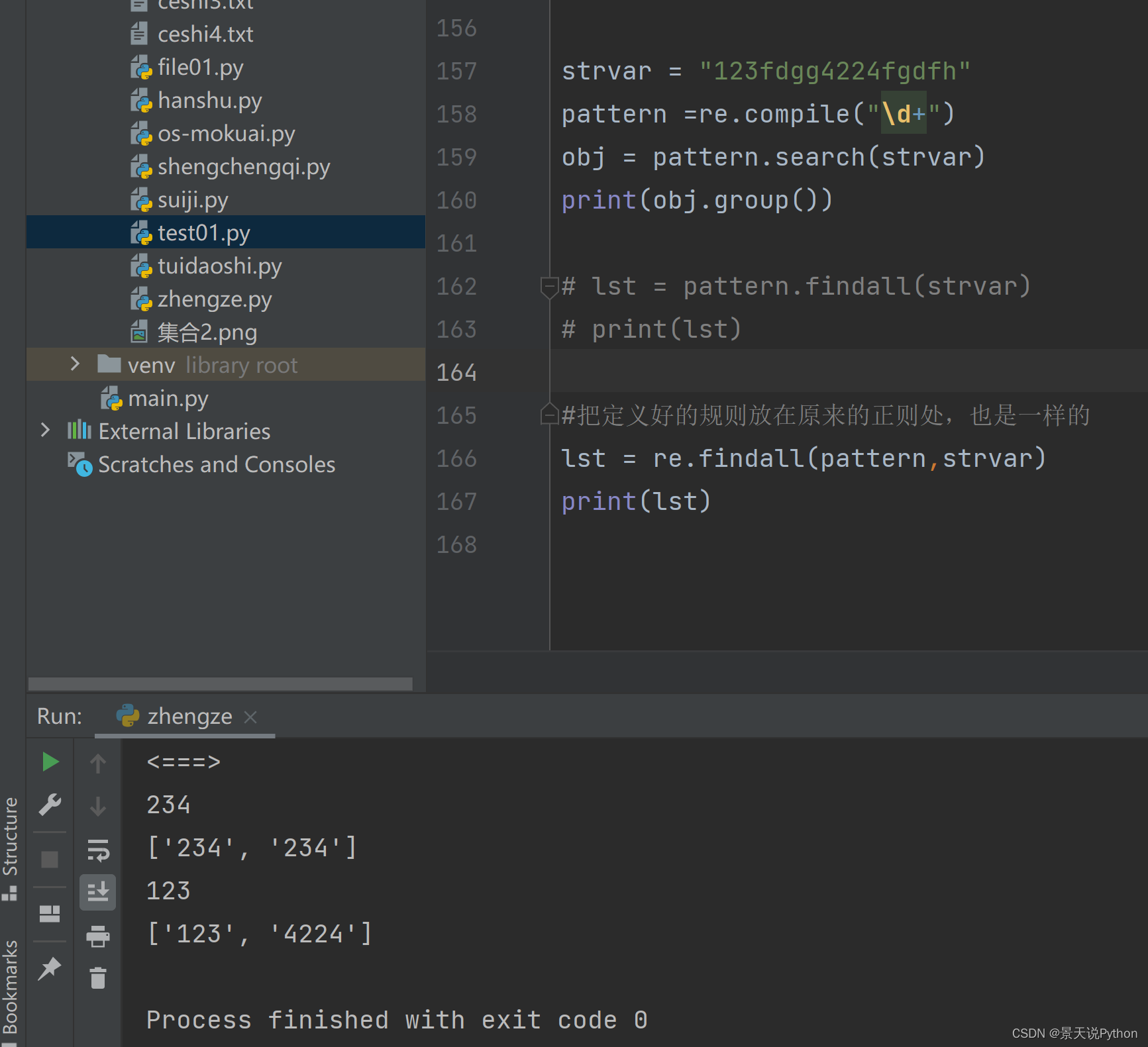
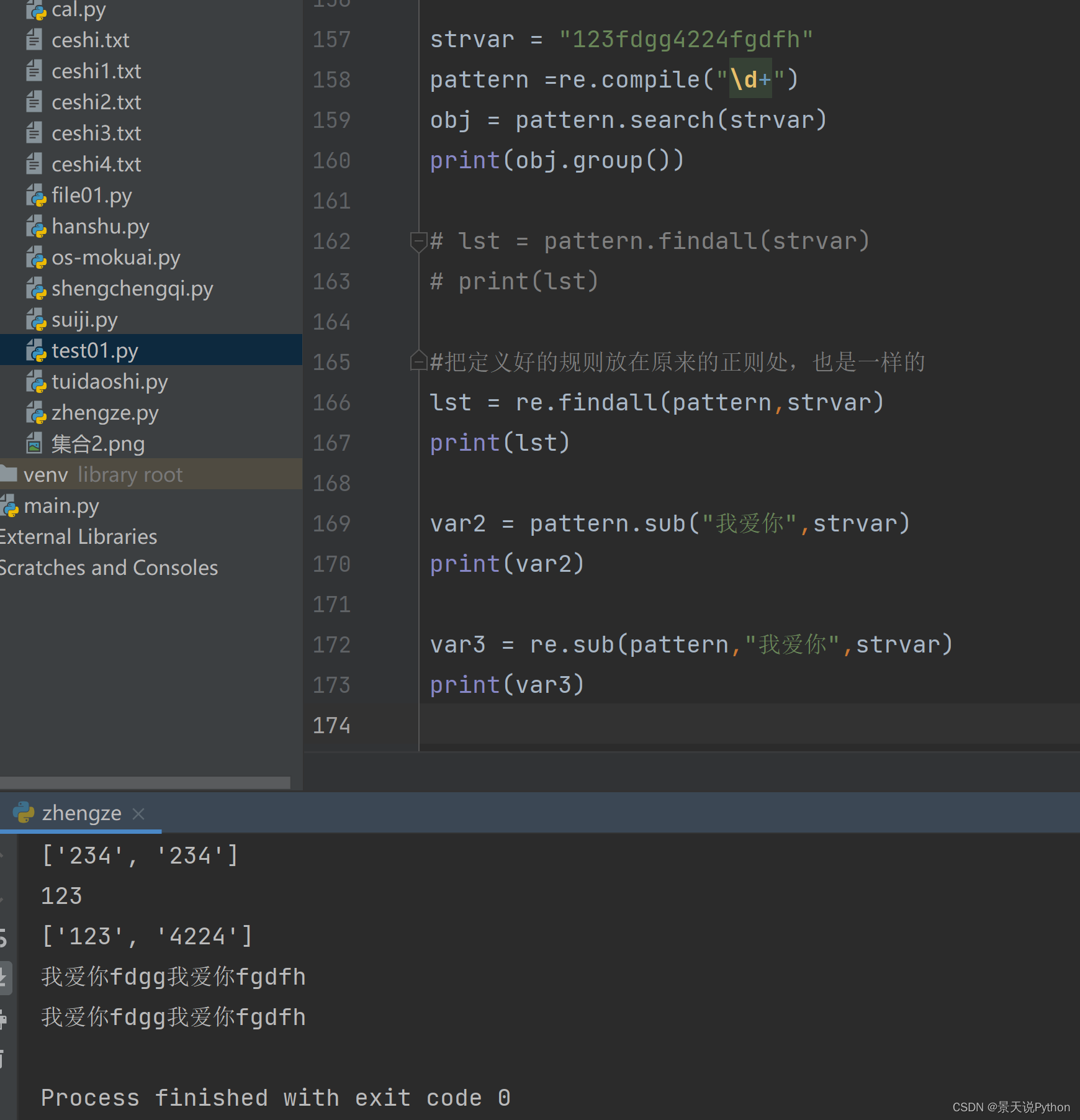
strvar = “asdfs234sdf234”
pattern = re.compile(“\d+”)
print(“”)
obj = pattern.search(strvar)
print(obj.group())
lst = pattern.findall(strvar)
print(lst)
语法2,正常语法